
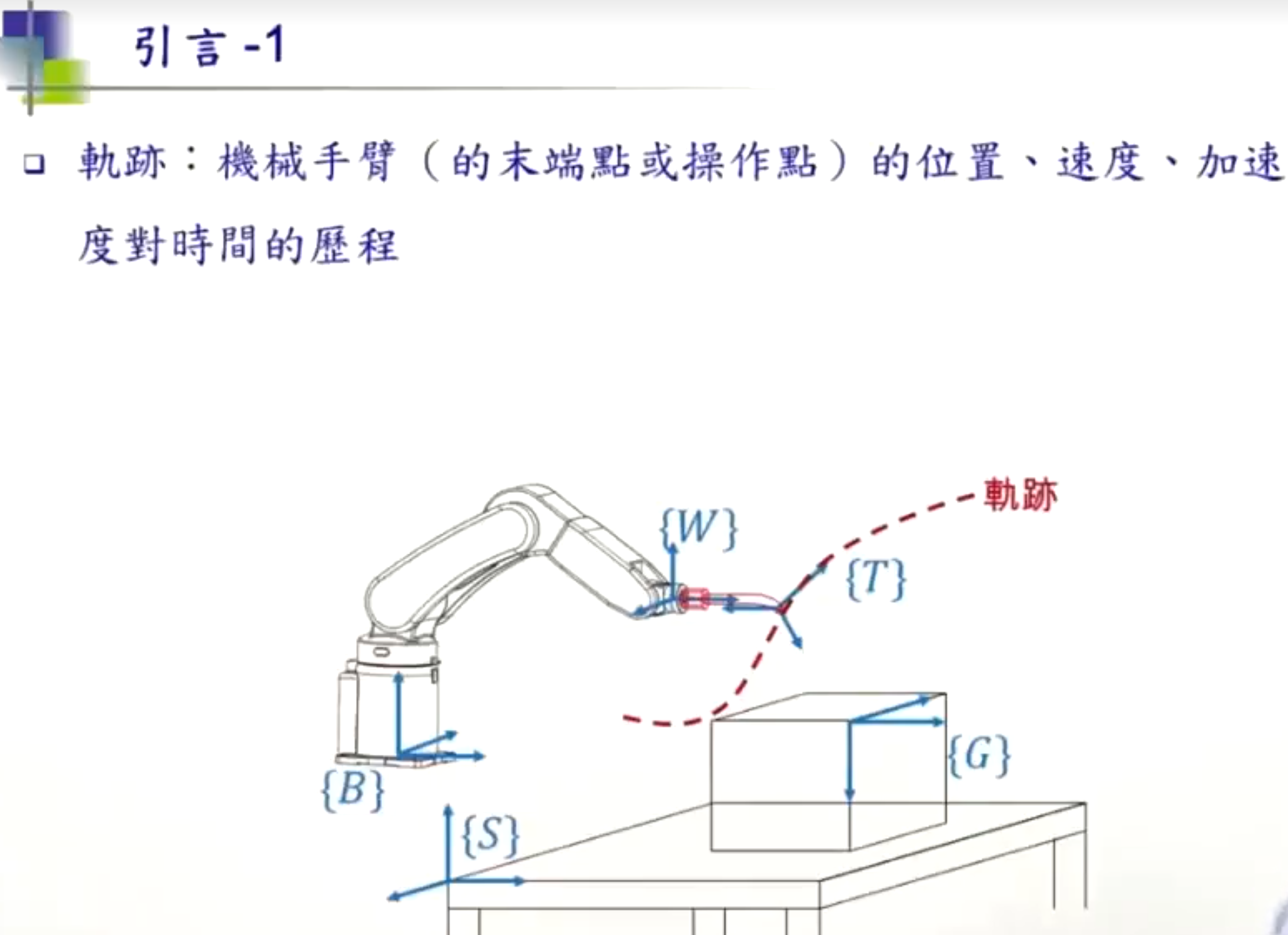
WARNING: To drag this element, first rotate the view so that the horizontal plane is clearly visible.
旋转到水平面上再shift+左键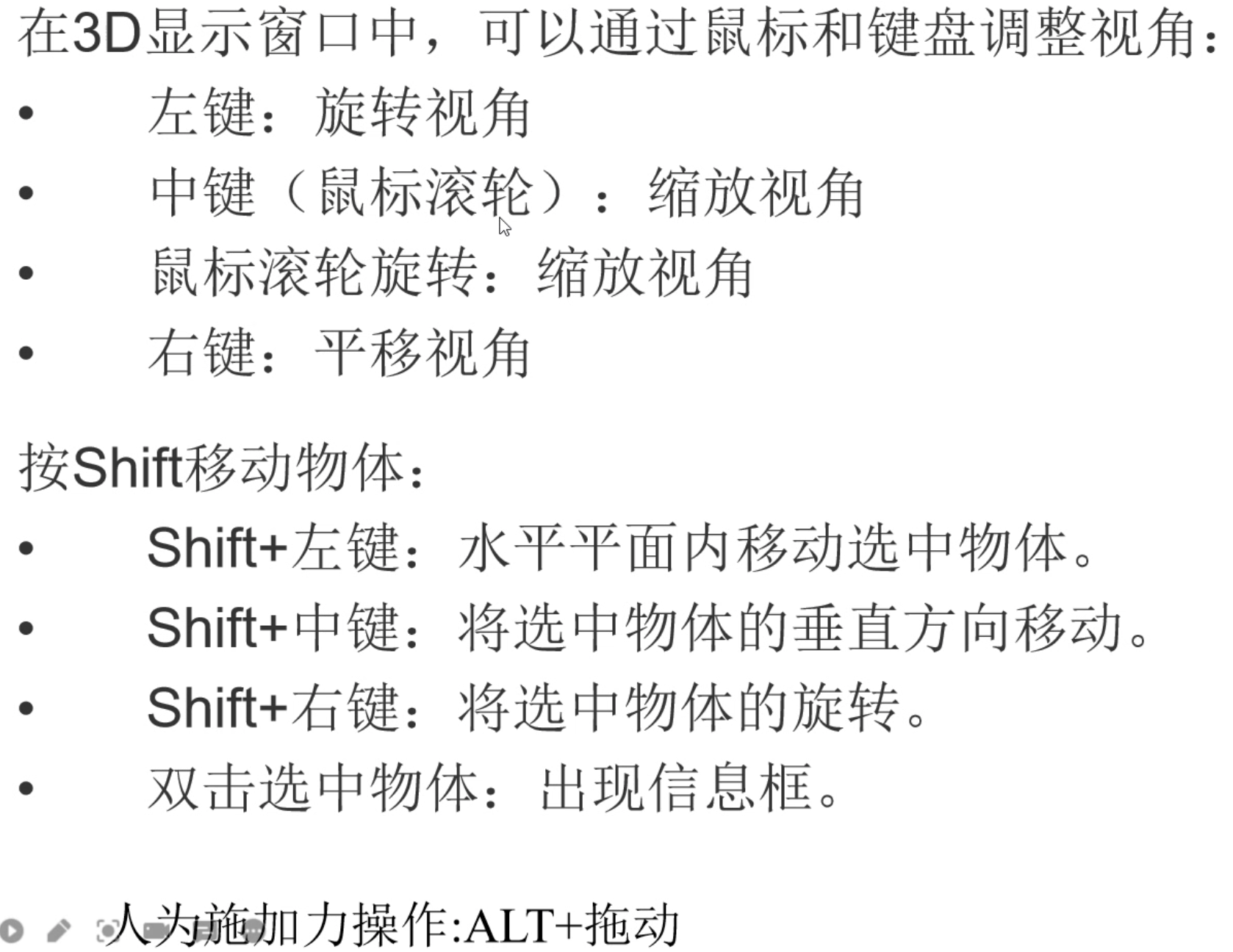
右键平移
保存:Ctrl shift s
向导:
1.新建项目目录向导(新建场景)
2.新建机器人控制器向导(新建控制器)
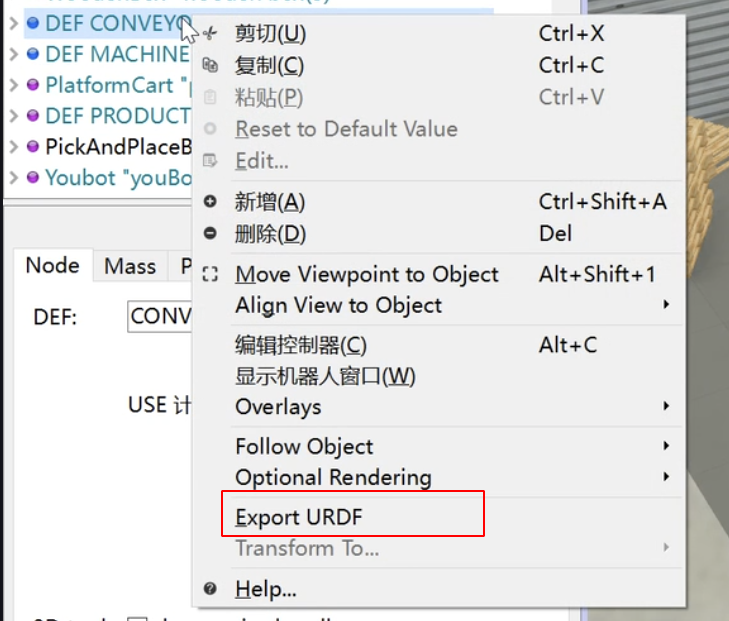
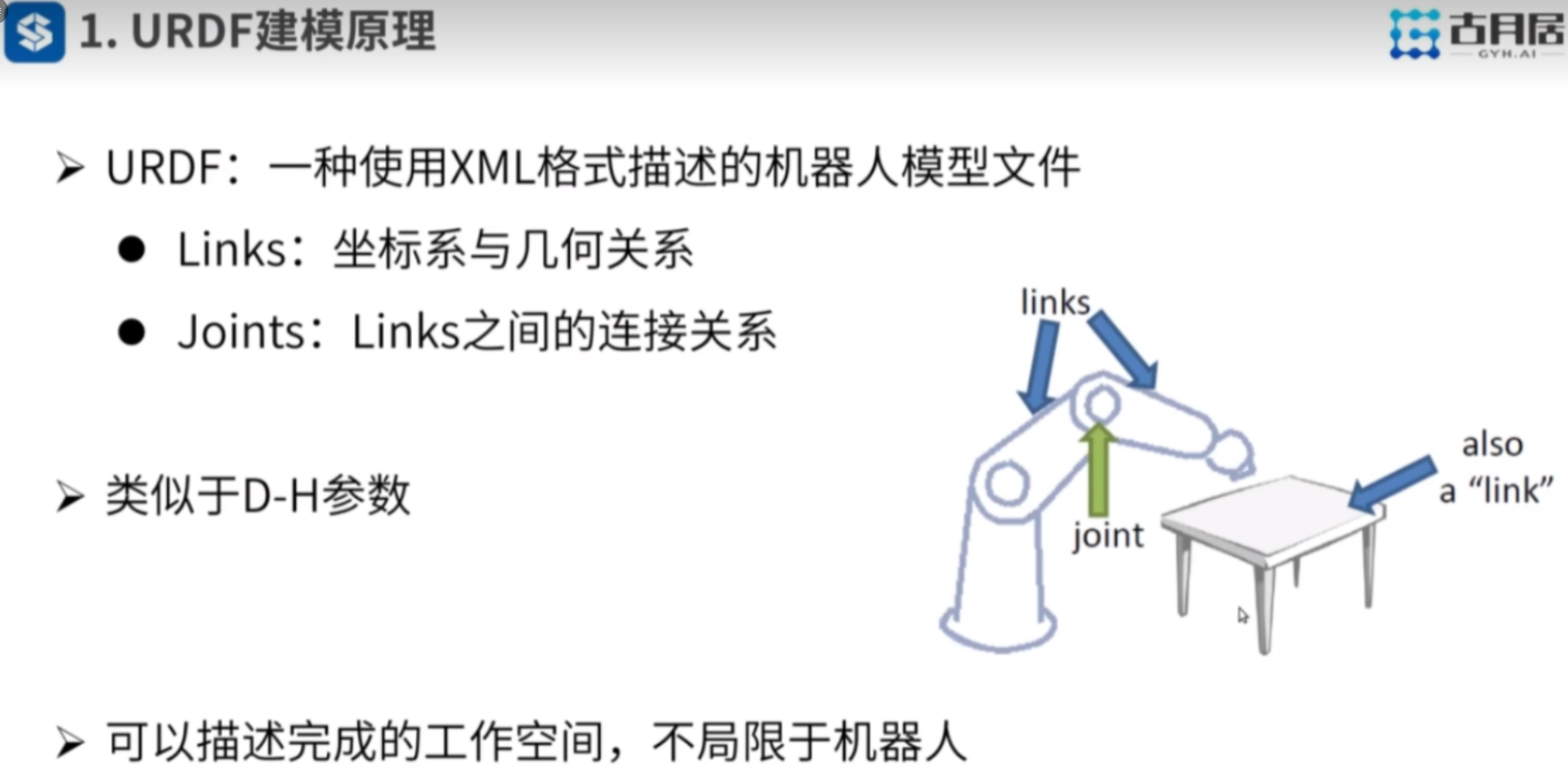
只有机器人节点才能导出urdf文件
转换完后的文件放到protos目录下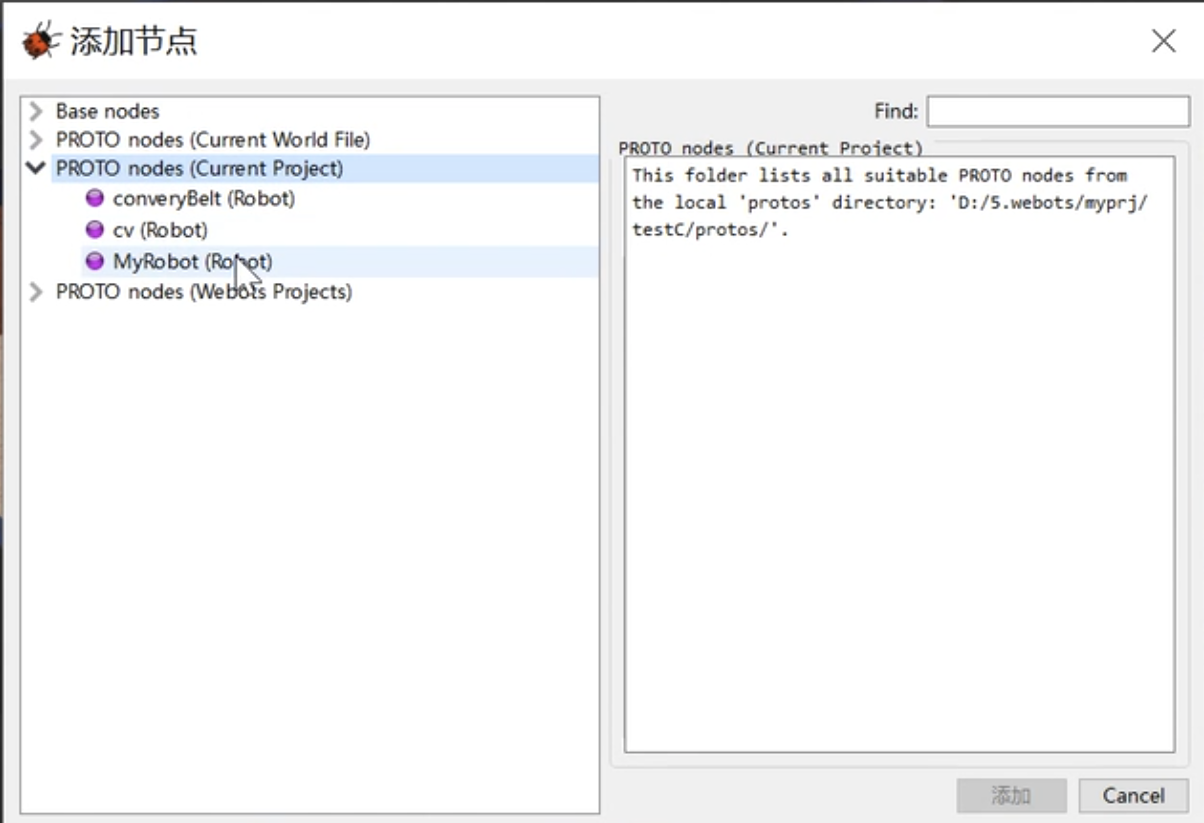
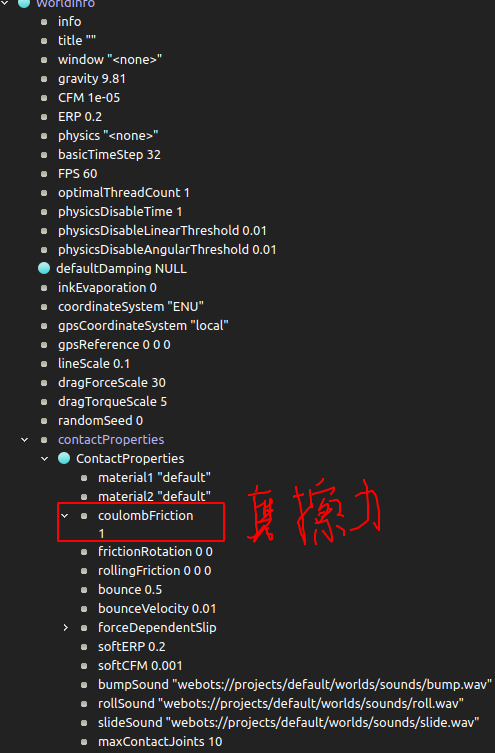
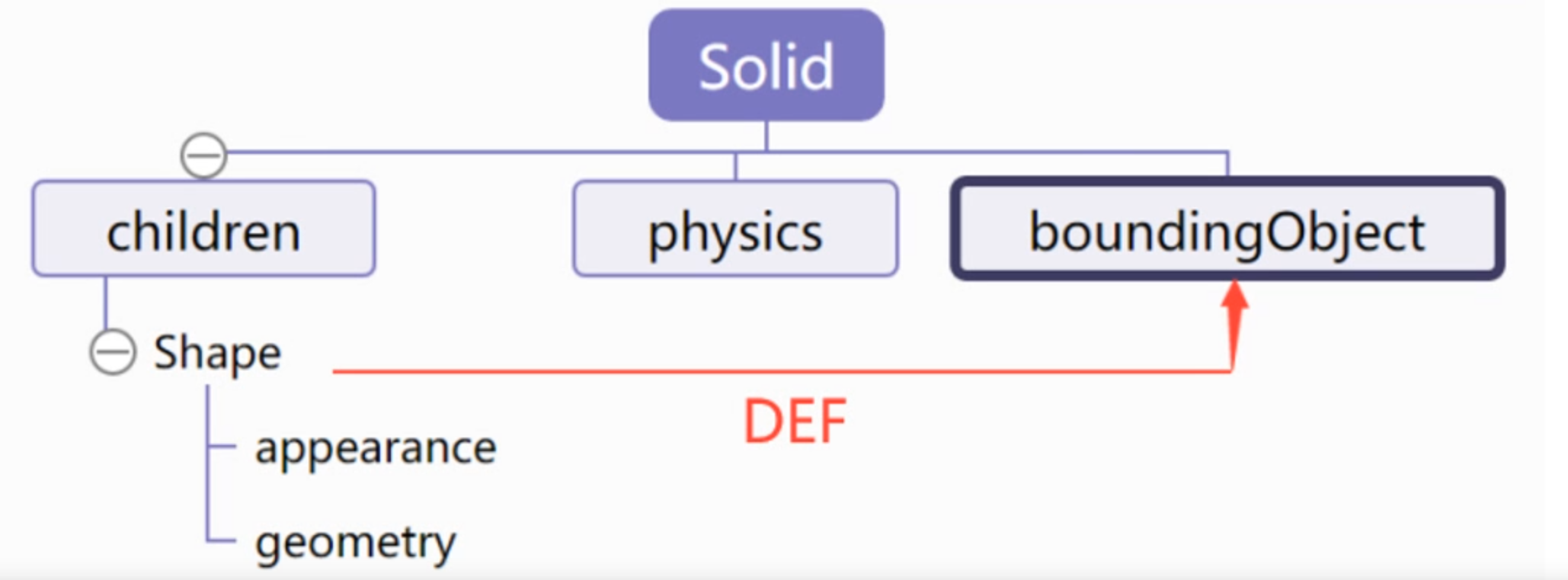
在 Webots 中,Solid 节点用于定义具有物理属性的物体,主要用于仿真中的动态交互。它包含了物理模拟所需的各种参数,如质量、摩擦力和弹性等。
在 Webots 中,Shape 节点用于定义物体的外观和几何形状。
Solid 节点通常与 Shape 节点结合使用,以创建既有外观又具物理特性的对象
写于2024-10-3-00:46
记录一次把ubnutu20.04de nvidia 驱动搞坏又修复,加上对ubuntu显卡驱动和独显/混显,lightdm/gdm3桌面管理器的理解。
由于webots仿真卡死崩溃,就找到一篇博客说:
glxinfo | grep OpenGL
确实opengl输出的是intel集显,使用
sudo prime-select nvidia
再次查看输出:
zgh@zgh-Legion-Y7000P-IAH7:~$ glxinfo | grep OpenGL
OpenGL vendor string: Mesa/X.org
OpenGL renderer string: llvmpipe (LLVM 12.0.0, 256 bits)
虽然不是nvidia,但好歹不是intel了,而且仿真不会卡死崩溃了
sudo systemctl restart gdm3
/etc/X11/xorg.conf
xrandr
glxinfo | grep OpenGL
nvidia-settings
####sudo nvidia-xconfig 不要用这个命令,它会生成什么Xorg的配置文件,把你之前能用的显示配置覆盖掉
/etc/X11/xorg.conf内容:
# nvidia-xconfig: X configuration file generated by nvidia-xconfig
# nvidia-xconfig: version 535.154.05
Section "ServerLayout"
Identifier "Layout0"
Screen 0 "Screen0" 0 0
InputDevice "Keyboard0" "CoreKeyboard"
InputDevice "Mouse0" "CorePointer"
EndSection
Section "Files"
EndSection
Section "InputDevice"
# generated from default
Identifier "Mouse0"
Driver "mouse"
Option "Protocol" "auto"
Option "Device" "/dev/psaux"
Option "Emulate3Buttons" "no"
Option "ZAxisMapping" "4 5"
EndSection
Section "InputDevice"
# generated from default
Identifier "Keyboard0"
Driver "kbd"
EndSection
Section "Monitor"
Identifier "Monitor0"
VendorName "Unknown"
ModelName "Unknown"
Option "DPMS"
EndSection
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BusID "PCI:1:0:0"
EndSection
Section "Screen"
Identifier "Screen0"
Device "Device0" #就是要用独立显卡启动
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Depth 24
EndSubSection
EndSection
如果这样写:
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BusID "PCI:1:0:0"
EndSection
Section "Screen"
Identifier "Screen0"
Device "Device1"
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Depth 24
EndSubSection
EndSection
Section "Device"
Identifier "Device1"
Driver "intel"
VendorName "Intel Corporation"
Option "TripleBuffer" "true"
Option "TearFree" "true"
Option "DRI" "false" #这三条都是为了防止集显显示桌面的时候画面割裂
BusID "PCI:0:2:0"
EndSection
是以Intel集显启动,确实有用
但是此时bios里设置的混合显示,只会使用集显,nvidia-settings内容错误,只能显示笔记本屏幕,无法连接外接显示器。
然后又换lightdm试一试,发现还是只能显示一个,甚至只能显示外接屏幕,拔去外接屏幕,笔记本屏幕也不会亮。
最后又换回了dgm3
##总结:
2024-10-3-14:44
这样确实可以用,但是独显功耗太大,而且不知道为什么webots非常卡,看来还是不对
bios混显模式+删除xorg.conf
先修改xorg.conf,把GPU,Intel标清,然后用Intel显示,进入桌面,看到nvidia-settings能选择这三种模式了(这是还不是很对,左面只有一个PRIME Profiles)
重启
在tty里把xorg.conf文件rm掉,
直接reboot
就一切正常了,看一下:

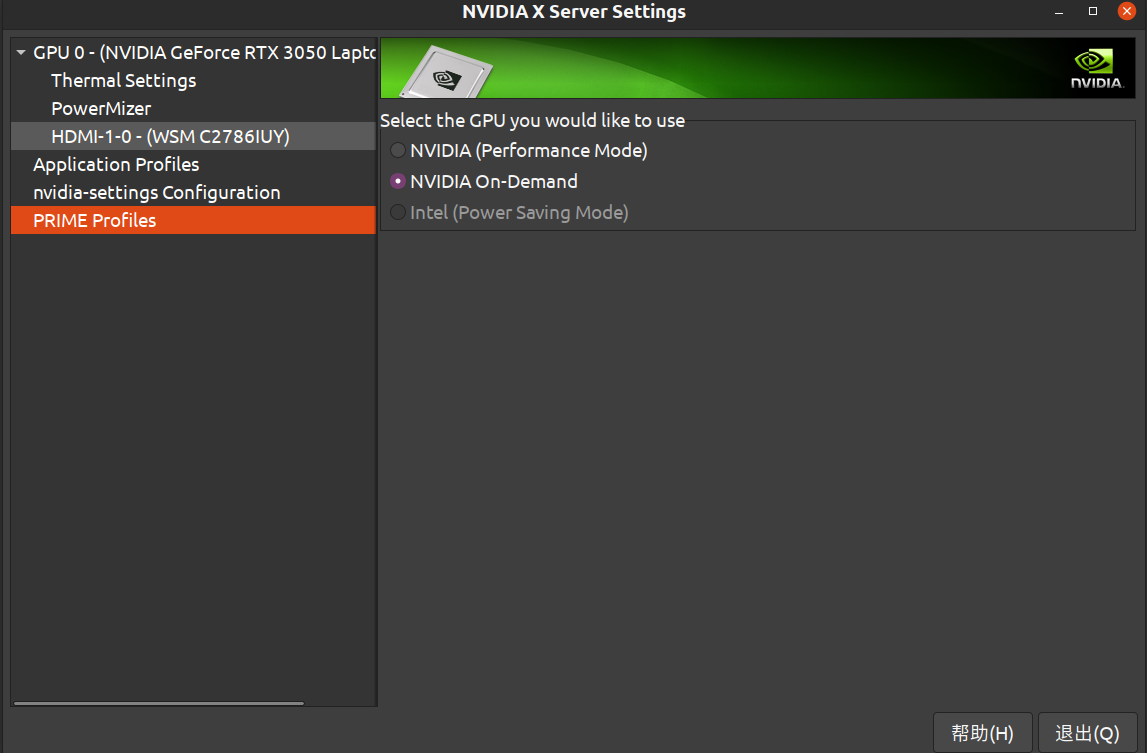
nvidia-smi也正常了
2024-10-4-10:29
zgh@zgh-Legion-Y7000P-IAH7:~$ __NV_PRIME_RENDER_OFFLOAD=1 vkcube
zgh@zgh-Legion-Y7000P-IAH7:~$ __NV_PRIME_RENDER_OFFLOAD=1 zed
这个是nvidia gpu的详细官方文档primerenderoffload
对于on-demand模式无法正常切换的,可以通过命令手动切换,上面的zed就是例子,zed需要用nvidia gpu的vulkan,
这里面有vulkan.opengl等等
###这个文档真的很有用
Conky闪烁:
conky -b -q -c /home/zgh/.config/conky/TC-100/TC-100/tc100-green
//conky --double-buffer
-b | --double-buffer Use double buffering (eliminates "flicker"). Only available with build flag BUILD_X11 enabled.
启用双缓冲后,Conky 的更新会显得更加平滑,尤其是在你频繁更新数据或显示动态内容时,减少闪烁或图形重绘带来的不适感。
zgh@zgh-Legion-Y7000P-IAH7:~/.config/conky/Shelyak-Dark$ killall conky

legged_control
基于OCS2和ros-controls的非线性MPC 1与WBC框架
Ubuntu 20.04
ROS noetic
catkin
OCS2 是一个针对切换系统优化控制的 C++ 工具箱,适用于机器人任务,包括路径约束处理和 URDF 模型支持。它提供了高效算法如 SLQ、iLQR 和 SQP,并具有 ROS 接口。工具箱包含自动微分工具,确保在有限计算能力的机器人应用中实现数值稳定和高效控制。
OCS2是一个大型单库项目;请不要尝试编译整个仓库。
URDF文件和YAML文件通常在 ROS 启动文件中被调用。具体步骤如下:
URDF 文件:
.launch)中使用 <param> 标签将 URDF 文件加载到参数服务器:<param name="robot_description" command="$(find xacro)/xacro $(find your_package)/urdf/your_robot.urdf.xacro"/>
YAML 文件:
<rosparam> 标签加载 YAML 文件:<rosparam file="$(find your_package)/config/your_config.yaml" command="load"/>
节点中访问:
ros::param::get() 或 ros::NodeHandle 来访问这些参数。这样,URDF 和 YAML 文件就能在你的 ROS 项目中被有效地调用和使用。
<geometry> <!--几何形状-->
<inertial> <!--惯性属性-->
<joint name="world_to_slideBar" type="fixed"> <!--这个关节用于将 slideBar 固定在世界坐标系中的特定位置,使得它在仿真中保持稳定,提供支撑作用。-->
<parent link="world"/>
<child link="slideBar"/>
<origin xyz="0.0 0.0 2.0"/>
</joint>
<gazebo reference="slideBar">
<mass value="0.1"/>
<origin> 位置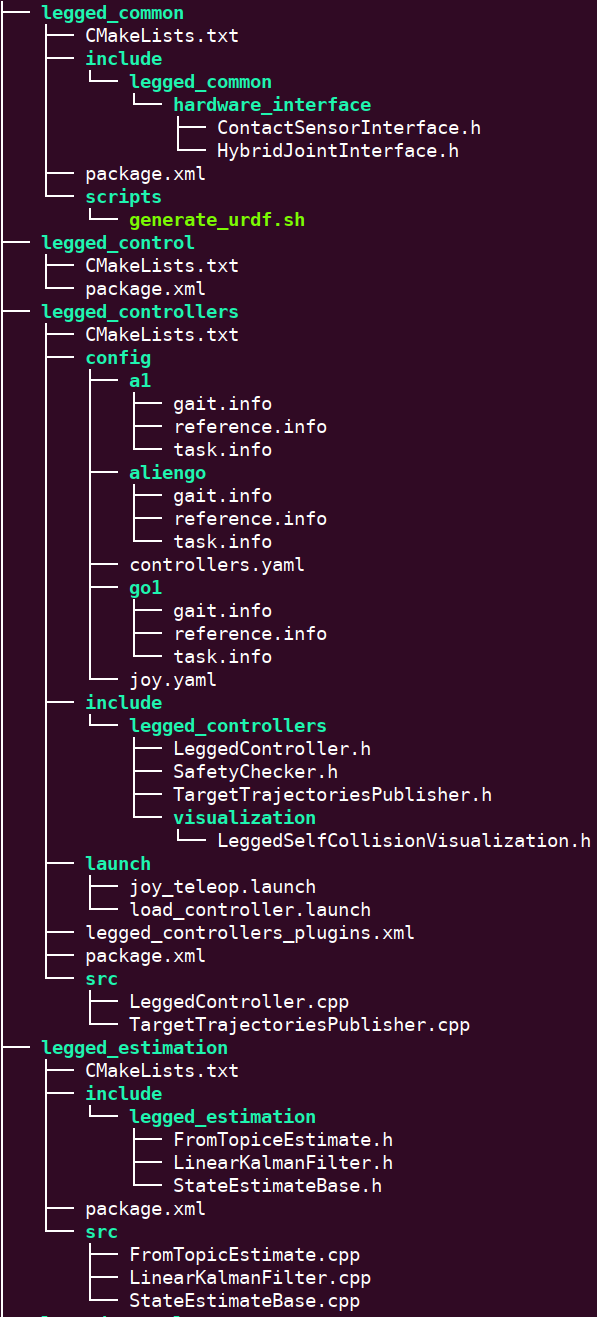
自由度通俗的讲就是为了唯一确定一个机构的运动状态所必须的独立变量的个数

c12=cos(seta1+seta2 )



<joint name="base_to_plat" type="prismatic">
<axis xyz="1 0 0"/>
<origin xyz="0.0 0.0 0.0"/>
<parent link="slideBar"/>
<child link="cart"/>
<limit effort="100000.0" lower="-15" upper="15" velocity="100"/>
<dynamics damping="0.0" friction="0.0"/>
</joint>
是什么意思
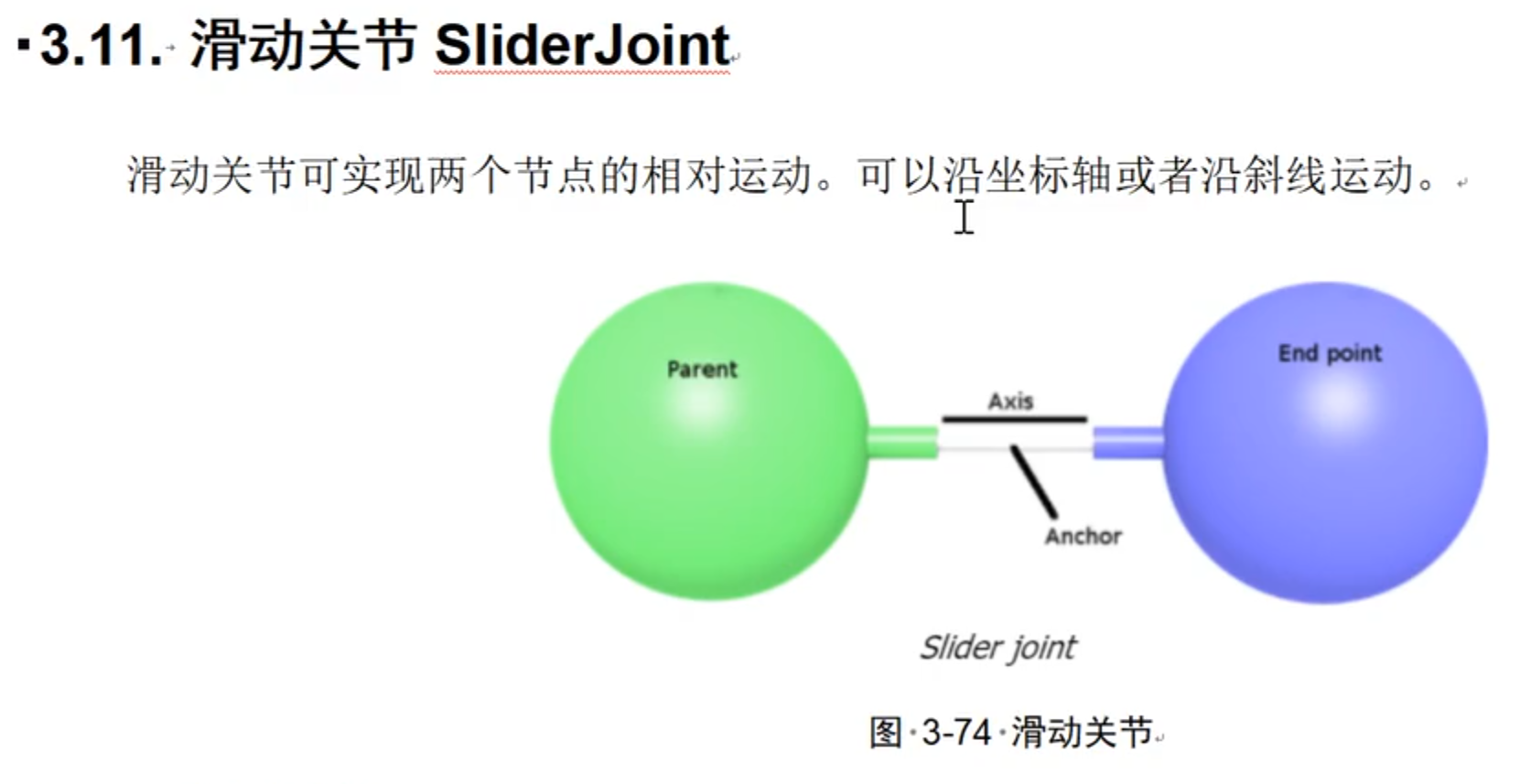
这段代码定义了一个名为 base_to_plat 的滑动关节(prismatic joint),其主要功能是让 cart 在 slideBar 上进行线性滑动。以下是对每个部分的详细解释:
<joint name="base_to_plat" type="prismatic">name="base_to_plat": 该关节的名称是 base_to_plat。type="prismatic": 关节类型为滑动关节,允许连接的部分沿一个轴线性移动。<axis xyz="1 0 0"/>xyz="1 0 0": 表示滑动关节的运动轴为 X 轴。1 表示在 X 方向上有运动,而 Y 和 Z 方向上没有运动。<origin xyz="0.0 0.0 0.0"/>xyz="0.0 0.0 0.0": 该关节的原点位置设置在 (0, 0, 0),通常是关节的中心点。<parent link="slideBar"/>link="slideBar": 指定 slideBar 是该关节的父链接。也就是说,cart 相对于 slideBar 移动。<child link="cart"/>link="cart": 指定 cart 是该关节的子链接。表示 cart 将通过该关节的运动影响到。<limit effort="100000.0" lower="-15" upper="15" velocity="100"/>effort="100000.0": 该关节能够承受的最大力为 100,000(单位通常为牛顿)。lower="-15": 关节的最小位置限制为 -15(单位通常为米),表示 cart 可以向后滑动的最大距离。upper="15": 关节的最大位置限制为 15(单位通常为米),表示 cart 可以向前滑动的最大距离。velocity="100": 关节的最大速度为 100(单位通常为米/秒),表示 cart 的移动速度限制。<dynamics damping="0.0" friction="0.0"/>damping="0.0": 阻尼系数为 0,表示没有额外的阻力影响滑动。friction="0.0": 摩擦系数为 0,表示在滑动过程中没有摩擦力。这段代码的主要目的是定义一个滑动关节,使得 cart 可以在 X 轴上滑动,受到的限制和动力学特性被明确设定。这在机器人和机械模拟中是非常重要的,可以精确控制其运动行为。
<transmission name="tran2">
<type>transmission_interface/SimpleTransmission</type>
<joint name="base_to_plat">
<hardwareInterface>hardware_interface/EffortJointInterface</hardwareInterface>
</joint>
<actuator name="planar_motor_2">
<hardwareInterface>hardware_interface/EffortJointInterface</hardwareInterface>
<mechanicalReduction>1</mechanicalReduction>
</actuator>
</transmission>
是什么意思
这段代码定义了一个名为 tran2 的传动系统,主要用于连接一个滑动关节和一个执行器。以下是各部分的解释:
<transmission name="tran2">tran2。<type>transmission_interface/SimpleTransmission</type><joint name="base_to_plat">base_to_plat。<hardwareInterface>hardware_interface/EffortJointInterface</hardwareInterface><actuator name="planar_motor_2">planar_motor_2。<mechanicalReduction>1</mechanicalReduction>整体上,这段代码用于定义一个简单的传动系统,将滑动关节和电机连接起来,以便通过施加力来控制滑动运动。
JointState 消息内容JointState 消息通常包含以下字段:
name: 存储关节名称的字符串数组。position: 存储每个关节当前角度或位置的浮点数数组。velocity: 存储每个关节当前速度的浮点数数组。effort: 存储每个关节当前力矩或用力程度的浮点数数组。
LQR(线性二次调节器,Linear Quadratic Regulator)是一种用于控制系统的优化方法。它旨在通过最小化某个代价函数来设计控制器,通常用于线性动态系统。
假设有一个线性系统描述为:
$ \dot{x} = Ax + Bu $
其中:
LQR 通过最小化以下代价函数来设计控制器:
$ J = \int_0^{\infty} (x^T Q x + u^T R u) , dt $
其中:
通过求解代价函数的最小值,可以得到最优控制律:
$ u = -Kx $
其中 $K $是增益矩阵,通过以下公式计算:
$K = R^{-1} B^T P $
而$ P $ 是 Riccati 方程的解:
$A^T P + PA - PBR^{-1}B^T P + Q = 0 $
LQR 方法通过设计一个控制器,最小化系统状态和控制输入的加权平方和,从而实现对线性系统的有效控制。它广泛应用于工程、自动控制、机器人等领域。
在你提供的代码中,LQR控制器的设计过程主要包含以下几个步骤:
逆矩阵计算:
Eigen::Matrix<double, 1, 1> R_inv = R_.inverse();
这里计算了控制输入权重矩阵 (R) 的逆。
计算 BRB 项:
Eigen::Matrix<double, 4, 4> BRB = B_ * R_inv(0, 0) * B_.transpose();
这一步计算了 $BR^{-1}B^T$项,用于构建哈密尔顿矩阵。
构造哈密尔顿矩阵:
Eigen::Matrix<do uble, 8, 8> H;
H.topLeftCorner(4, 4) = A_;
H.topRightCorner(4, 4) = -BRB;
H.bottomLeftCorner(4, 4) = -Q_;
H.bottomRightCorner(4, 4) = -A_.transpose();
哈密尔顿矩阵 (H) 是 LQR 解的核心部分,它结合了系统的动态矩阵 (A)、控制输入矩阵 (B) 和权重矩阵 (Q) 和 (R)。
特征值和特征向量计算:
Eigen::ComplexEigenSolver<Eigen::Matrix<double, 8, 8>> ces;
ces.compute(H);
通过计算哈密尔顿矩阵的特征值和特征向量来获取系统的稳定性信息。
选择稳定特征向量:
for (int i = 0; i < 8; ++i)
{
if (eigenvalues(i).real() < 0 && index < 4)
{
Vs.col(index) = eigenvectors.col(i);
++index;
}
}
选择具有负实部的特征值对应的特征向量,以确保系统的稳定性。
解Ricatti方程:
Eigen::MatrixXcd P_c = Vs2 * Vs1.inverse();
Eigen::Matrix4d P = P_c.real(); // Take the real part
通过特征向量计算 Riccati 方程的解 (P),这是 LQR 控制中的关键步骤。
计算 LQR 增益矩阵:
Eigen::Matrix<double, 1, 4> K_temp = R_inv(0, 0) * B_.transpose() * P;
return K_temp.transpose();
最后计算控制增益矩阵 (K),该矩阵用于生成控制输入。
LQR 控制器的实现通过构造哈密尔顿矩阵,计算其特征值和特征向量,求解 Riccati 方程,最终得到一个最优控制增益 (K)。通过这种方式,LQR 能够有效地平衡系统的性能和控制输入,以保证系统的稳定性和响应速度。
Eigen::MatrixXd 和 Eigen::Matrix4d 是 Eigen 库中用于表示矩阵的两种不同类型。它们的主要区别如下:
Eigen::MatrixXd:Eigen::Matrix4d:Eigen::MatrixXd:Eigen::Matrix4d:Eigen::MatrixXd:Eigen::Matrix4d:###ubuntu上ros与anaconda冲突的最好解决办法:
catkin_make -DPYTHON_EXECUTABLE=/usr/bin/python3
下次再安装ros时,在anaconda环境里安装,要不然python混乱太搞了
现在有更好的方法:
export PATH="/usr/bin:$PATH"
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ which python
/usr/local/anaconda3/bin/python
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ which python3
/usr/local/anaconda3/bin/python3
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ sudo vim ~/.bashrc
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ source ~/.bashrc
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ which python3
/usr/bin/python3
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ which python
/usr/bin/python
zgh@zgh-Legion-Y7000P-IAH7:~/ROS_Projects/dog_gazebo$ python -V
Python 3.8.10
完美解決
[ERROR] [1728964010.917743989]: [registerPublisher] Failed to contact master at [localhost:11311]. Retrying…
只是roscore没开
在 MoveIt! 的 moveit_setup_assistant 中,配置规划组时的 Base Link 和 Tip Link 是指机器人模型中关节链的起始和结束部分。具体来说:
以一个机械臂为例:
在 MoveIt! 的设置中,您提到的参数具有特定的含义和功能。以下是每个参数的解释:
arm 表示该规划组控制的是机器人的手臂。KDLKinematicsPlugin 是基于 Kinematics and Dynamics Library (KDL) 的运动学求解插件。在配置机械臂的末端执行器(End Effector)时,需要填写一些参数
gripper。grasping_frame,这可能是机械臂的一个特定链接,用于抓取物体。roslaunch moveit_setup_assistant setup_assistant.launch
要在source ./devel/setup.bash的终端使用
学长您好,我看您的【ROS-Moveit!】机械臂控制探索学机械臂联合仿真,但是您开源的代码为啥在运行:
roslaunch pigot_moveit_config moveit_planning_execution.launch
后,rviz显示出错呀,

 1.
1. <visual>
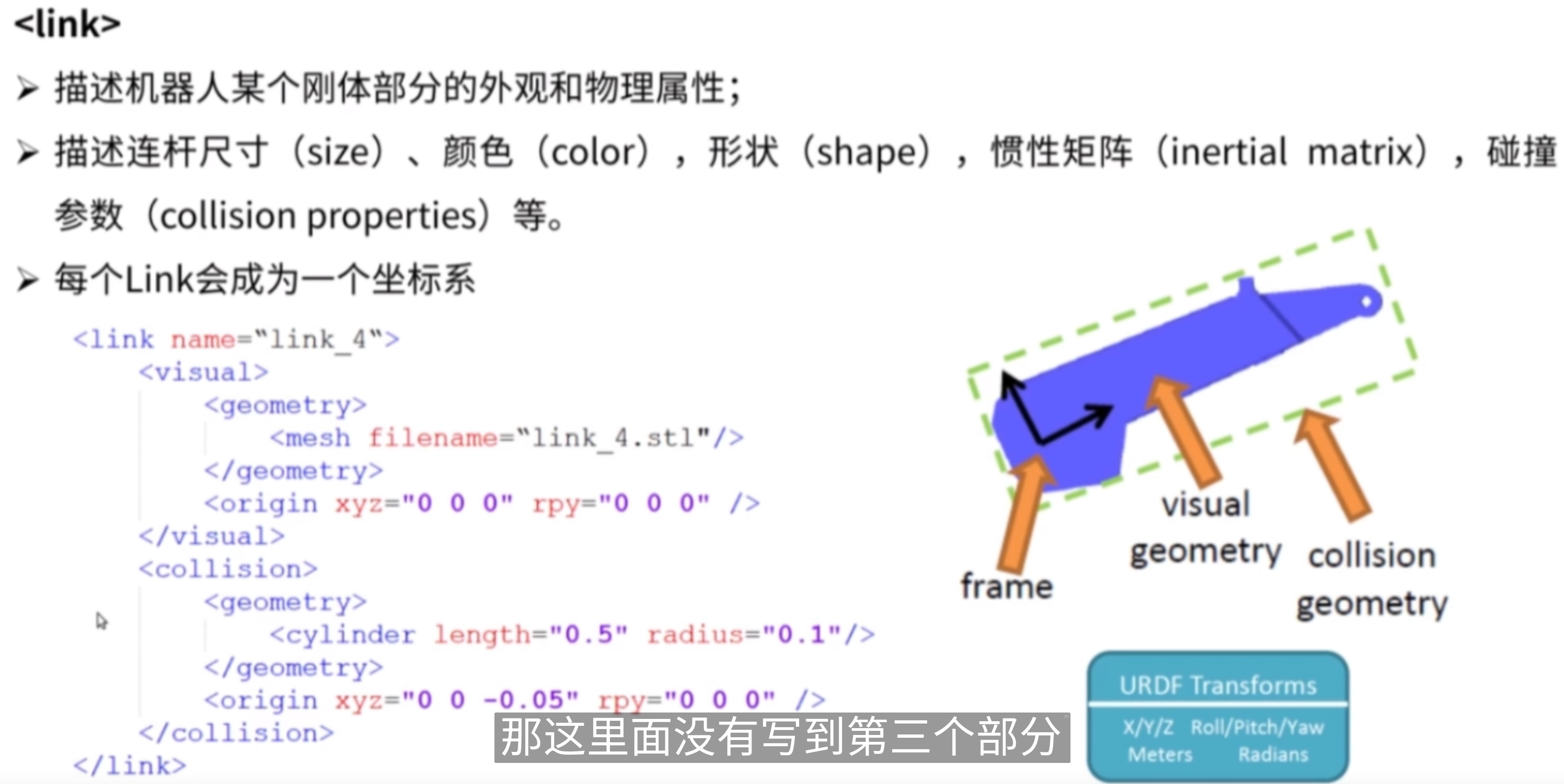
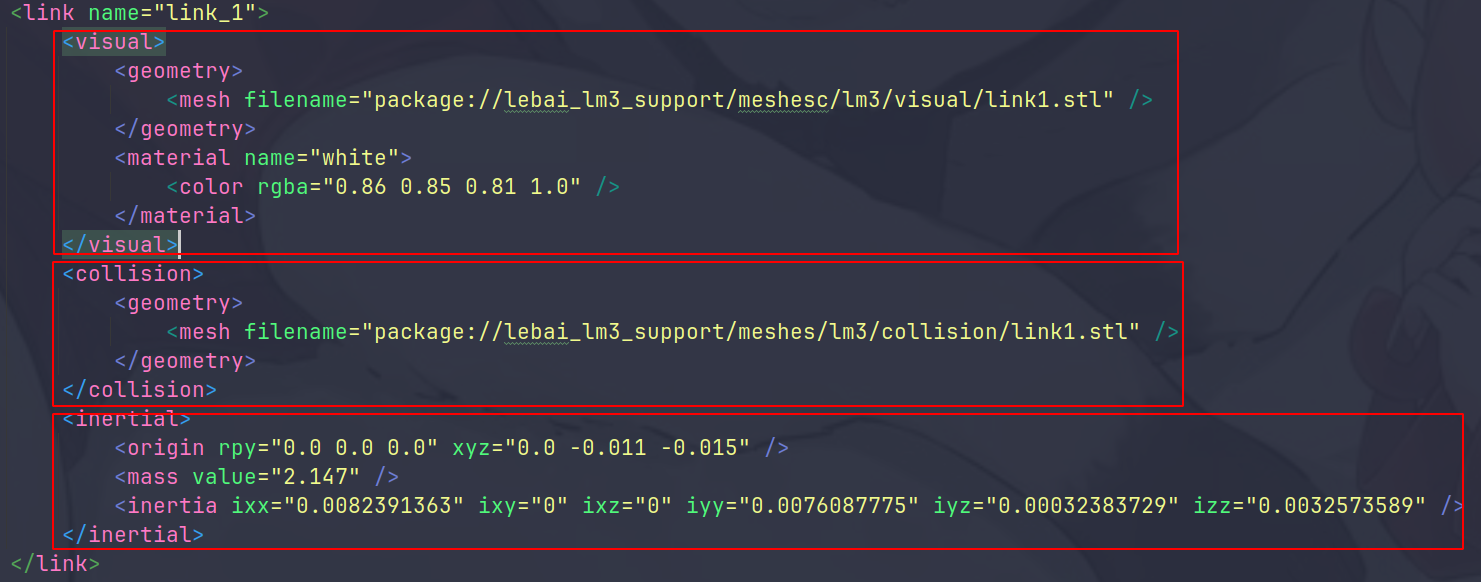
定义机器人的可视化外观,主要包括几何形状和材质。
<geometry>: 指定连接的几何形状。在这个示例中,使用了一个网格文件(STL格式)来定义 link_1 的形状。该文件的路径是:
Copy Codepackage://lebai_lm3_support/meshesc/lm3/visual/link1.stl
<material>: 定义连接的材质和颜色。在此示例中,材质名为 white,并且设置了RGBA颜色值(红、绿、蓝、透明度)为 (0.86, 0.85, 0.81, 1.0)。这意味着连接的颜色为一种淡灰色,完全不透明。
<collision>这一部分描述连接的碰撞模型,它与可视化模型通常是不同的。碰撞模型用于物理仿真,确保机器人在模拟环境中与其他物体进行碰撞检测。
<geometry>
: 这里也使用了一个网格文件,但它的路径是:
Copy Codepackage://lebai_lm3_support/meshes/lm3/collision/link1.stl
通常,碰撞模型会比可视化模型简单,以提高仿真性能。
<inertial>这一部分定义了连接的惯性属性,包括质量和转动惯量。惯性属性在机器人运动学和动力学计算中至关重要。
<origin>: 定义了惯性参考点的位置和方向。rpy 指的是绕X、Y、Z轴的滚转(roll)、俯仰(pitch)、偏航(yaw)角度,这里均为 0.0,表示没有旋转。xyz 指的是惯性参考点相对于链接坐标系的位置,这里是 (0.0, -0.011, -0.015)。<mass>: 定义连接的质量,这里为 2.147 kg。<inertia>: 定义连接的转动惯量矩阵。ixx、iyy 和 izz 分别表示绕X、Y、Z轴的转动惯量,而 ixy、ixz 和 iyz 是关于这些轴的耦合项


下次淘宝下单不要付款,先放弃付款,然后再付款的时候有几率跳出“付款再减XX元”,应该是后台店铺给的,香!!!










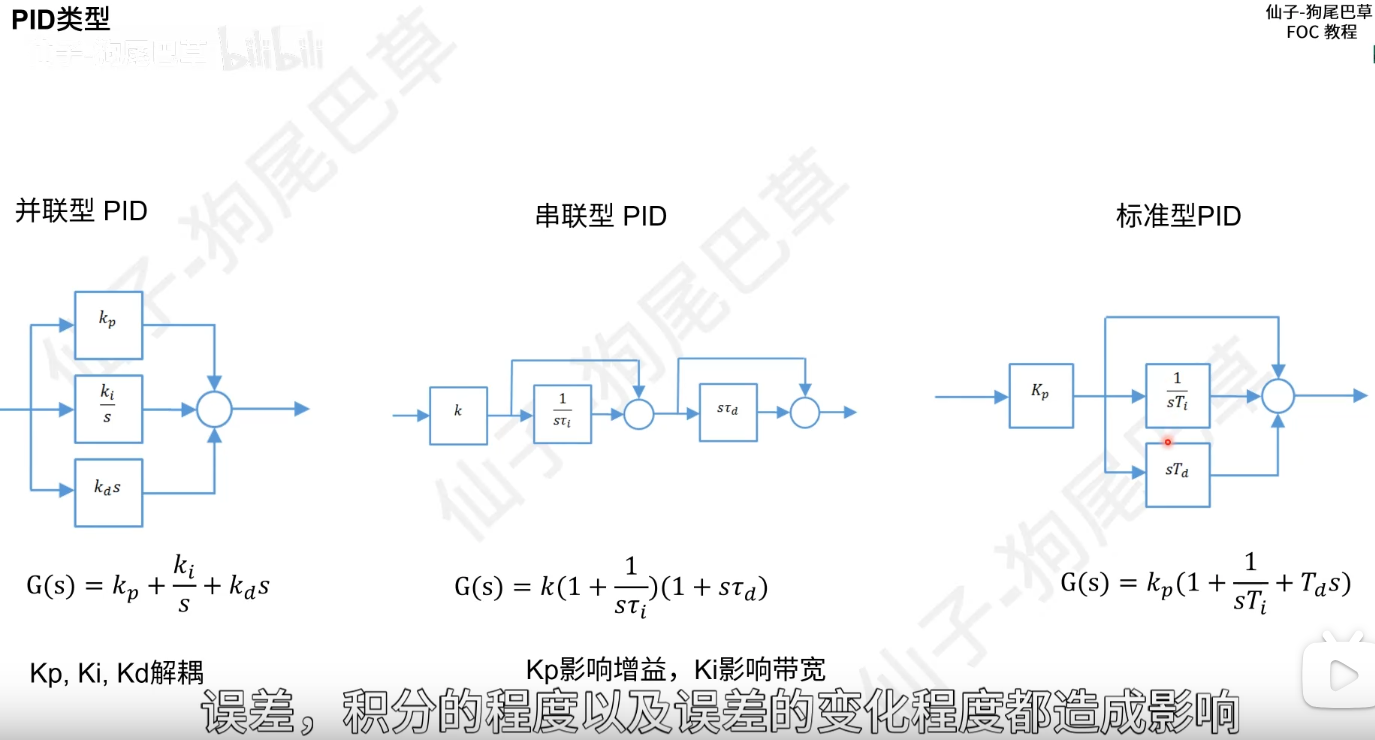
pid校正可以看成迟后超前的特例

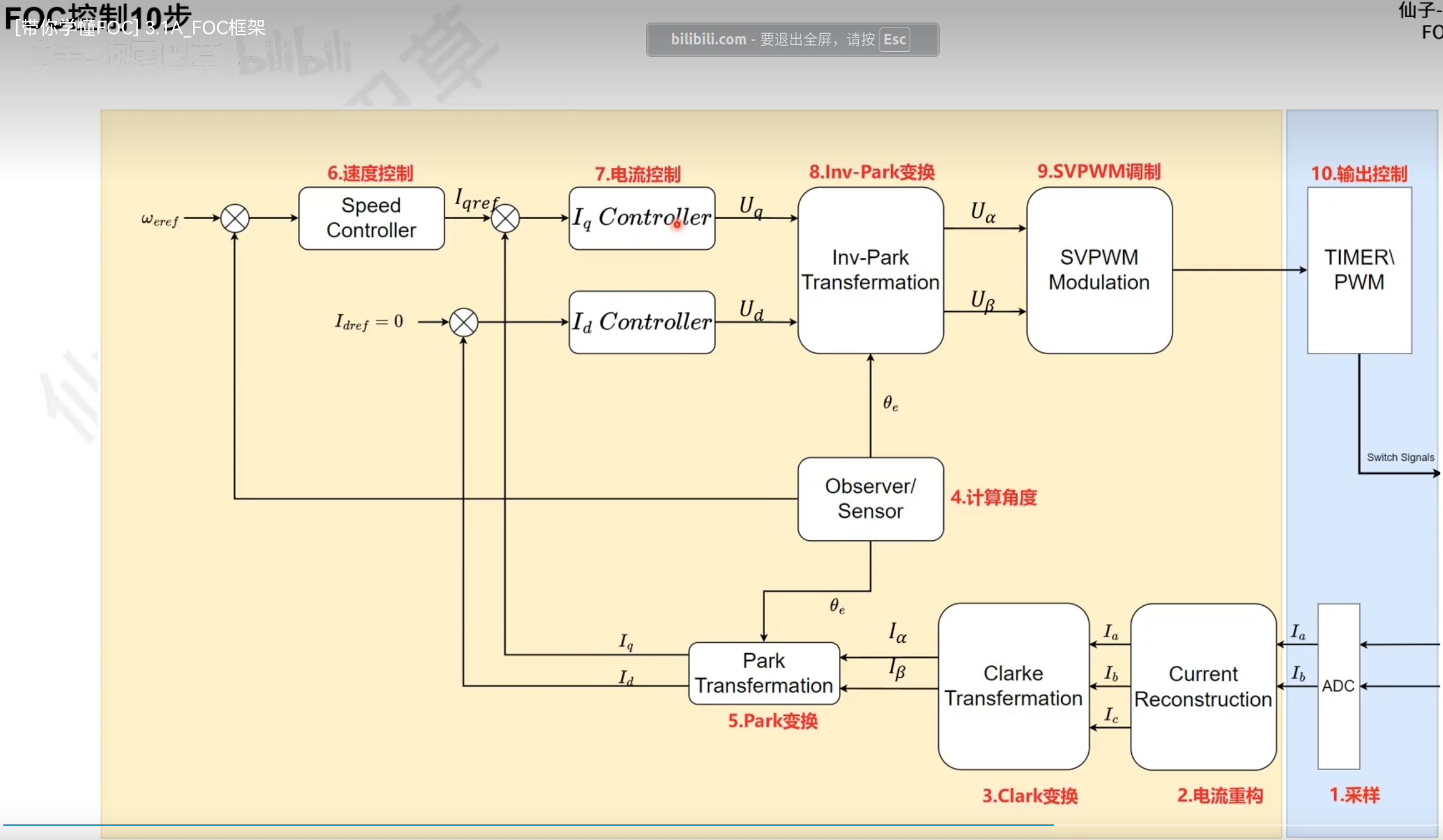
共有PWM模块、ADC电流采集、定时器编码器配置、SVPWM模块、FOC核心、PID模块、电压限幅模块,其实有了PWM与SVPWM以及一些必要的数学变换,我们就可以开环使电机转起来了,加入电角度与电流采集作为反馈后,我们就能做到电流闭环,再加入速度PID就可以做到速度闭环,其他的模块只是这些目的的辅助手段罢了
一、编码器的分类
按工作原理的不同可分为增量型和绝对值型。
(1) 增量型 (增量式可以理解为信号即位移的增加,需要参考量)
增量式编码器的原理是将位移转换成周期性的电信号,再把这个电信号转变成计数脉冲,用脉冲的个数表示位移的大小。增量式编码器转轴旋转时,有相应的脉冲输出,其旋转方向的判别和脉冲数量的增减借助后部的判向电路和计数器来实现。其计数起点任意设定,可实现多圈无限累加和测量。还可以把每转发出一个脉冲的Z信号,作为参考机械零位。编码器轴转一圈会输出固定的脉冲,脉冲数由编码器光栅的线数决定。需要提高分辨率时,可利用 90 度相位差的 A、B两路信号对原脉冲数进行倍频,或者更换高分辨率编码器。
简单来说,增量型编码器总共有三种相线输出,A相、B相、Z相。其中电机每转过一定的角度,A相和B相就输出一个脉冲,且A相和B相相互延迟1/4周期,电机的正反转就是根据A相和B相的延迟关系判断的。Z相为单圈脉冲,即每转一圈输出一个脉冲,可以作为参考机械零位。
(2) 绝对型(直接输出数字量的传感器,不需要参考量)
绝对编码器光码盘上有许多道光通道刻线,每道刻线依次以2线、4线、8线、16线编排,这样,在编码器的每一个位置,通过读取每道刻线的通、暗,获得一组从2的零次方到2的n-1次方的唯一的2进制编码(格雷码),这就称为n位绝对编码器。这样的编码器是由光电码盘进行记忆的。
简单来说,就是对应一圈,电机的每个角度都有一个与该角度对应二进制的数值,且这个数值不会改变,所以称为绝对型编码器。二、不同编码器的优缺点及其对应应用范围
增量型:
增量式编码器十分合适测速度,可无限累加丈量
是存在零点累计差错,抗干扰较差,接纳设备的停机需断电回忆
增量式编码器的一般应用测速,测转动方向,测移动角度、距离(相对)。
绝对型:
发生电源故障也不丢失轴位置
绝对式编码器十分适合测量位置,可直接输出
绝对编码器一般能够以 8 到 12位输出 360 °更精确,但也更昂贵
高级定时器主要用于产生6路互补的PWM来驱动MOS管,加入死区防止电源导通,本文未使用刹车引脚。高级定时器1通道1、2、3用于产生PWM,通道4用于触发ADC电流采样,根据扇区的位置,灵活设置PWM占空比,进而选择合理的触发点,避免在噪声点采样。引脚配置与PWM极性请根据自己的硬件合理配置,如IR2101是高电平有效,而IR2103则是低端低有效,高端高有效。
定时器从0开始向上计数 当0-t1段,定时器计数器TIMx_CNT值小于CCRx值,输出低电平 t1-t2段,定时器计数器TIMx_CNT值大于CCRx值,输出高电平 当TIMx_CNT值达到ARR时,定时器溢出,重新向上计数…循环此过程 至此一个PWM周期完成
TIMx_ARR寄存器确定PWM频率,
TIMx_CCRx寄存器确定占空比
LED等推挽输出



使用opencv进行颜色识别时受光照影响很大怎么办?
1.白平衡算法
2.对于图像数据受到光照度不足或者曝光引起的对比度太小的情况,在图像处理中一般是图像直方图均衡化的方法来处理。直方图均衡化是通过拉伸像素强度分布范围来增强图像对比度的一种方法。例如,更亮的图像将所有像素限制在高值。但是一个好的图像会有来自图像所有区域的像素。因此,我们需要将这个直方图扩展到两端,而这就是直方图均衡化所做的事情(用简单的话来说)。这通常会改善图像的对比度。
全局直方图均衡化,自适应局部直方图均衡化
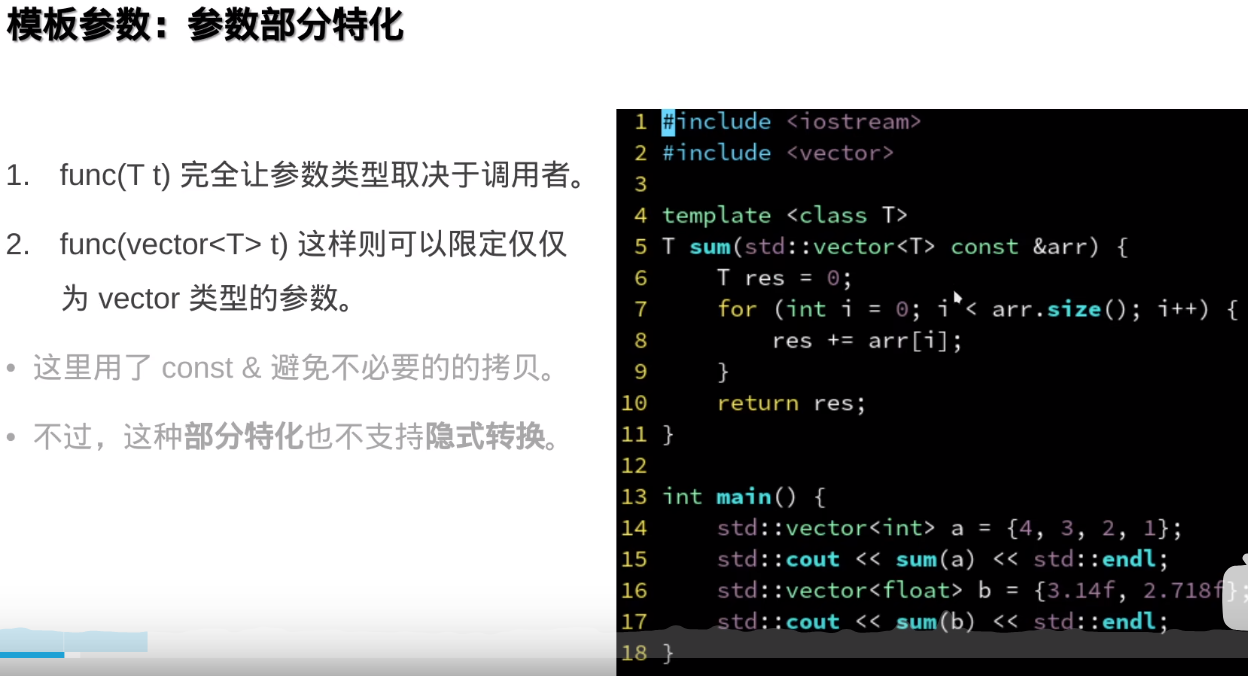
-

template


std::enable_if 是 C++ 标准库中的一个模板工具,通常用于实现 SFINAE(Substitution Failure Is Not An Error)技术。它位于 <type_traits> 头文件中,用于在模板编程中根据条件启用或禁用模板的实例化。
std::enable_if 的基本结构如下:
template <bool B, typename T = void>
struct enable_if {
using type = T;
};
template <typename T>
struct enable_if<false, T> {
// 这个结构体是未定义的
};
std::enable_if 主要有两个模板参数:
B:一个布尔值(通常是编译时常量表达式),用于决定 type 成员是否有效。T:一个默认类型(默认为 void),当 B 为真时,type 成员将定义为 T。当 B 为真时,std::enable_if 的 type 成员被定义为 T。这意味着我们可以使用 std::enable_if 的 type 来在模板中进行条件判断。
当 B 为假时,std::enable_if 的 type 成员没有定义。尝试使用这种情况下的 type 成员会导致编译错误,从而使得该模板实例化失败。这样可以用来控制模板的选择和重载。
以下是一个使用 std::enable_if 的示例,演示如何根据类型的特性来启用或禁用函数模板:
#include <iostream>
#include <type_traits>
// 用于启用整数类型的模板函数
template<typename T>
typename std::enable_if<std::is_integral<T>::value, void>::type
printType() {
std::cout << "Integral type\n";
}
// 用于启用非整数类型的模板函数
template<typename T>
typename std::enable_if<!std::is_integral<T>::value, void>::type
printType() {
std::cout << "Non-integral type\n";
}
int main() {
printType<int>(); // 输出: Integral type
printType<double>(); // 输出: Non-integral type
return 0;
}
在这个示例中:
printType<int>() 会选择第一个模板版本,因为 int 是整数类型。
printType<double>() 会选择第二个模板版本,因为 double 不是整数类型。
编译时替换:std::enable_if 根据布尔表达式 B 的值来决定是否定义 type 成员。
条件启用:在模板参数中使用 std::enable_if 可以有效地启用或禁用某些模板实例化。
SFINAE:如果 B 为假,type 成员未定义,尝试实例化使用 type 的模板将导致编译错误,从而引发 SFINAE 机制。
通过这种方式,std::enable_if 可以帮助实现条件模板选择,使得模板编程更加灵活和强大。

模板的参数可以作为编译器常量,可以自动优化

N变一次,编译器就会重新实例化一遍模版函数,编译就变慢
模版函数必须定义在同一个文件里才能使用(必须是内联的或者在头文件里的),所以模板函数的定义和实现无法分离,因此除非特殊手段,模板函数的定义和实现必须放到头文件里。
模板函数太多会导致头文件非常大。
模板函数内联要加static
 {:height 34, :width 232}
{:height 34, :width 232}



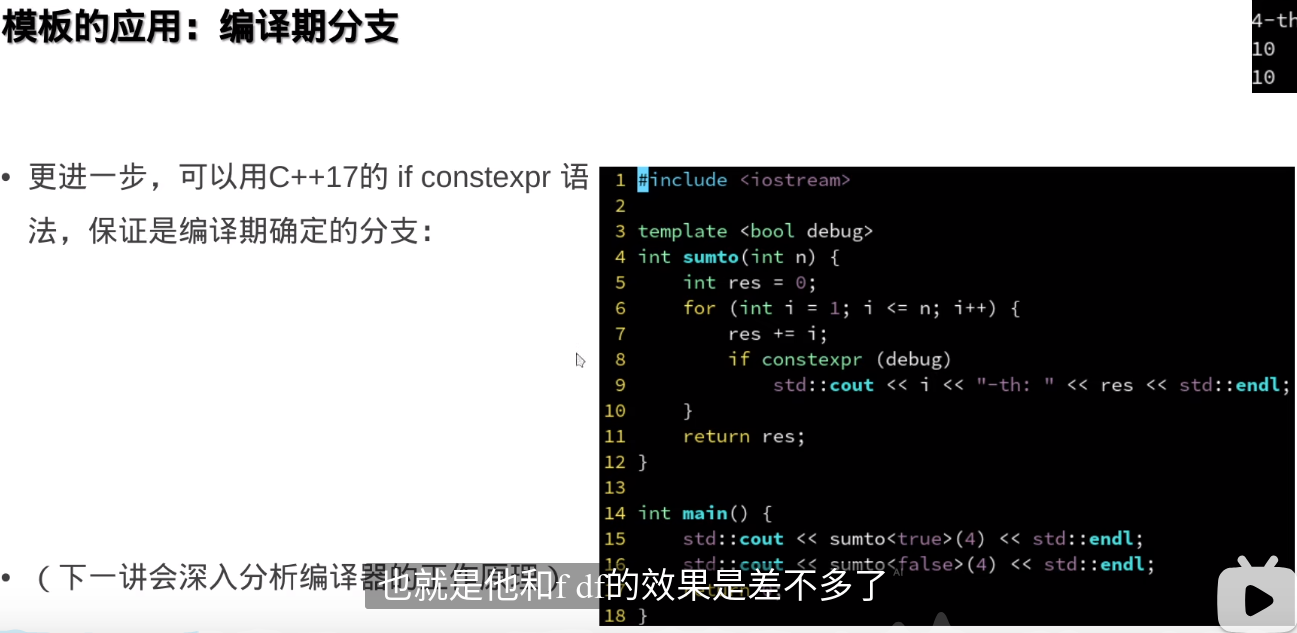
if constexpr 是 C++17 中引入的一种编译时条件语句。它允许在编译时根据条件选择代码路径,从而避免在运行时进行条件判断。与传统的 if 语句不同,if constexpr 在编译时会根据条件是否为 true 来决定是否编译相应的代码块。
举个例子:
#include <iostream>
#include <type_traits>
template <typename T>
void print_type() {
if constexpr (std::is_integral<T>::value) {
std::cout << "Integral type" << std::endl;
} else {
std::cout << "Non-integral type" << std::endl;
}
}
int main() {
print_type<int>(); // 输出 "Integral type"
print_type<double>(); // 输出 "Non-integral type"
}
在这个例子中,if constexpr 会在编译时检查 std::is_integral<T>::value 是否为 true,然后编译对应的代码块。这使得 print_type 函数的行为在编译时就被确定下来,从而避免了在运行时的类型检查。
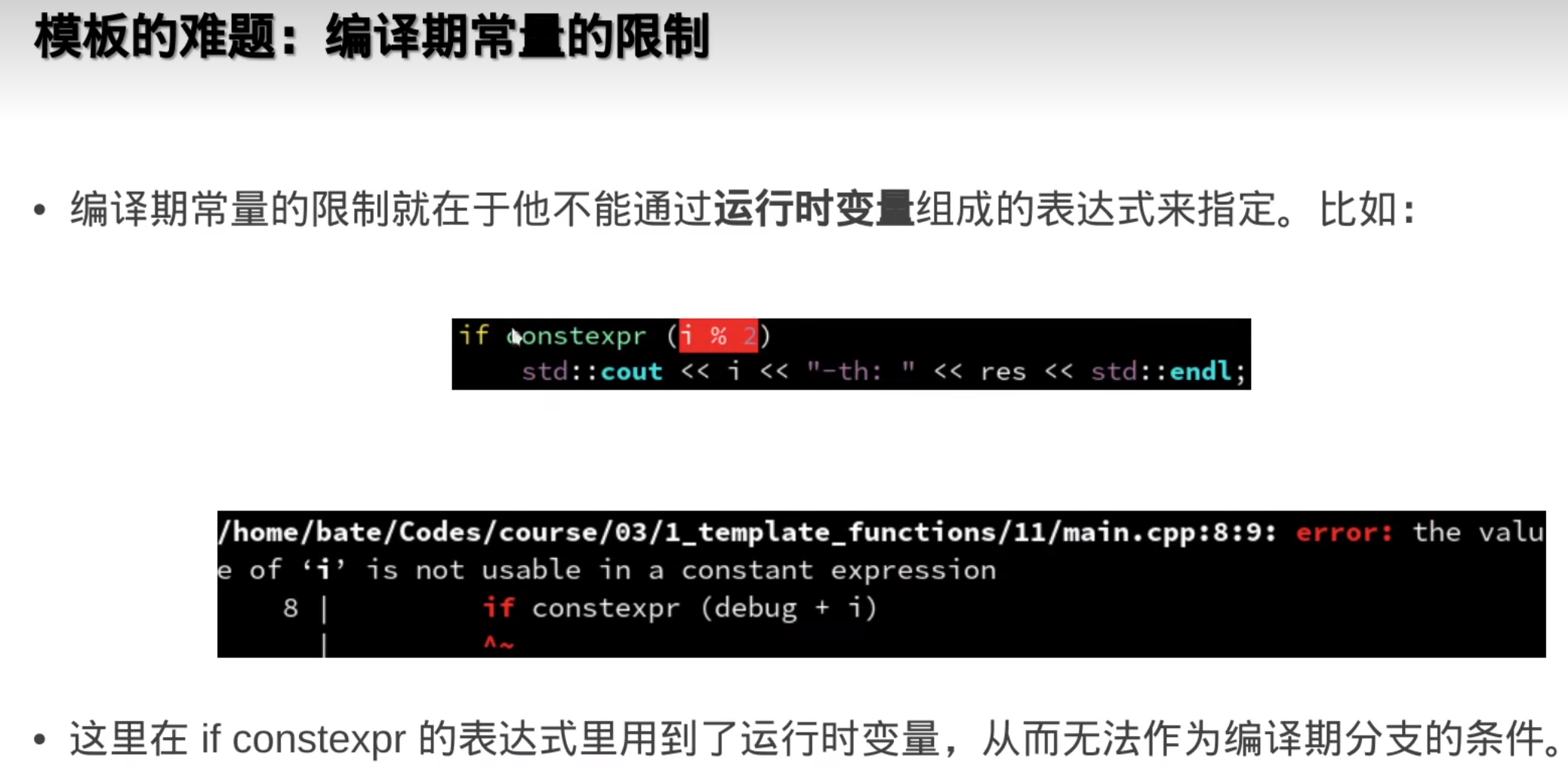
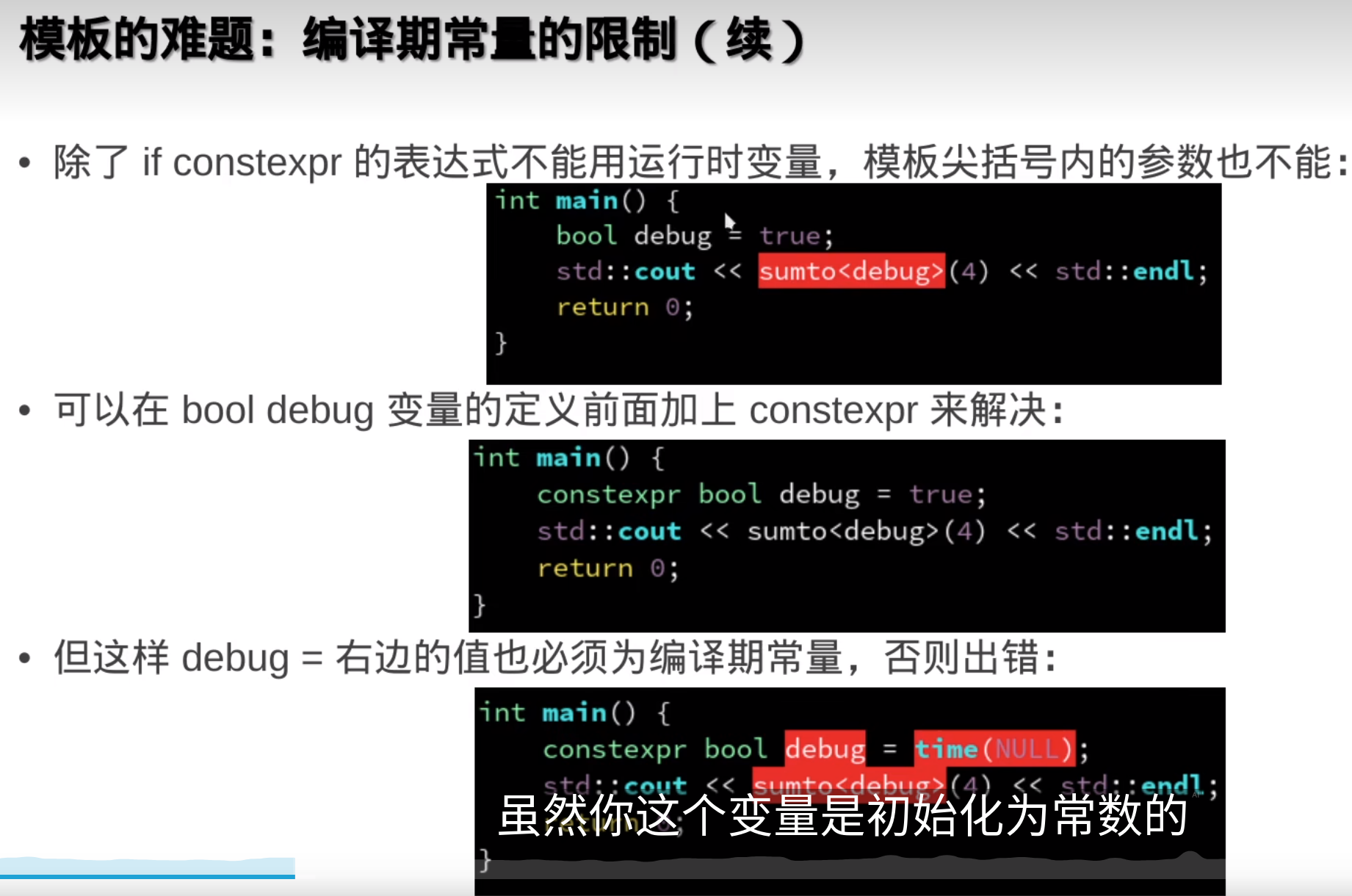

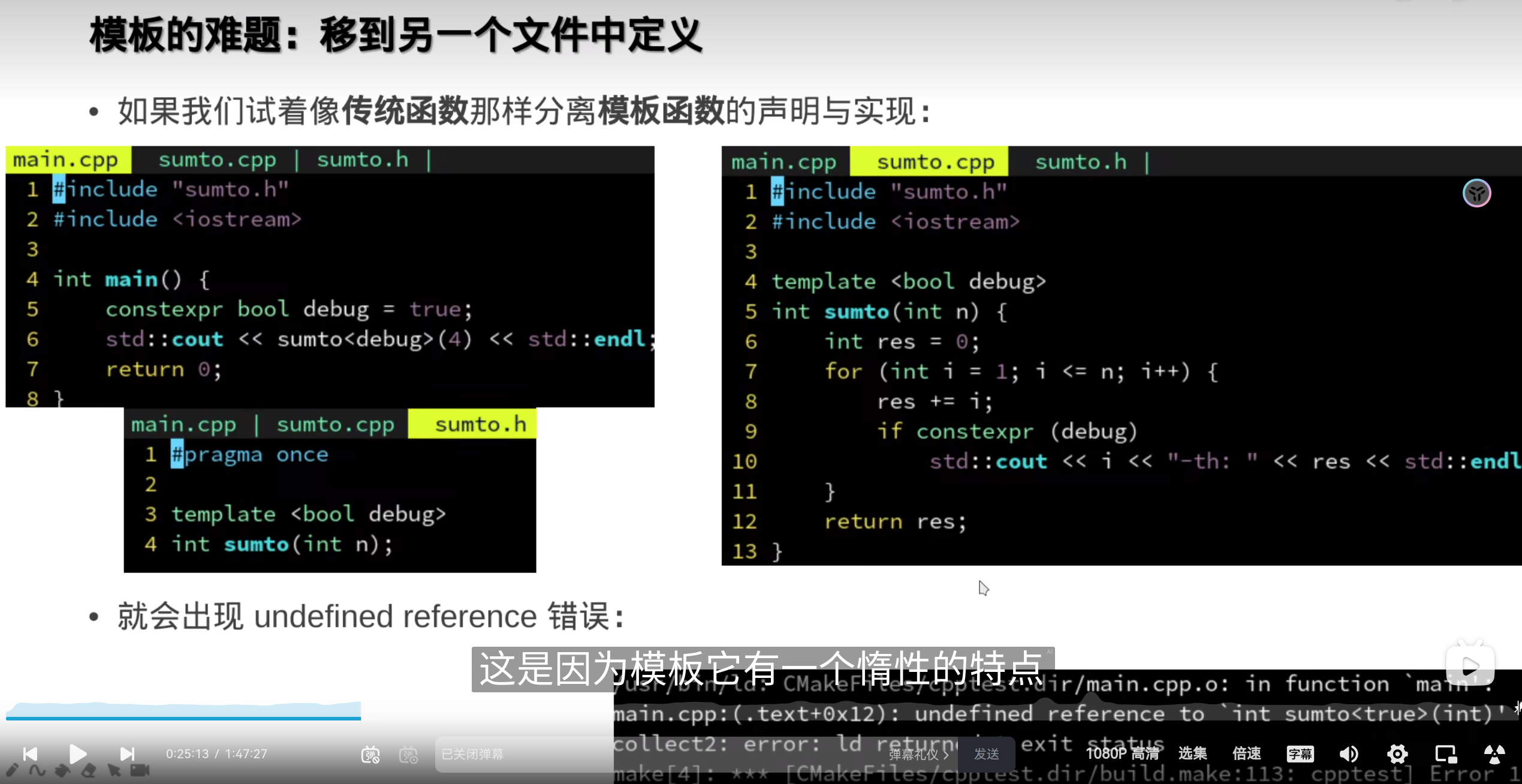
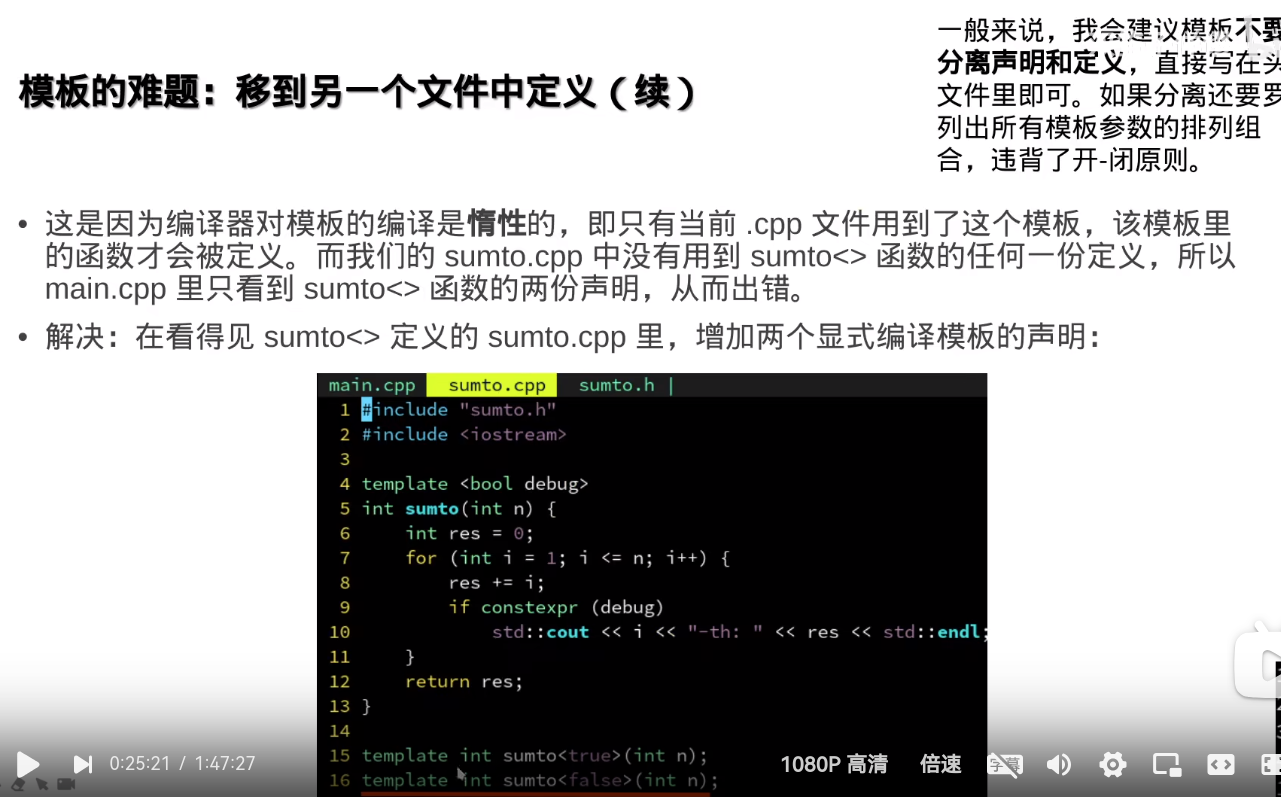 但是这样要把模板实例化的,每一种 情况都声明
但是这样要把模板实例化的,每一种 情况都声明
所以,尽量不要把模板分离
 延迟编译:当一个函数定义在头文件里,可能用不到,可以在前面加 template
延迟编译:当一个函数定义在头文件里,可能用不到,可以在前面加 template
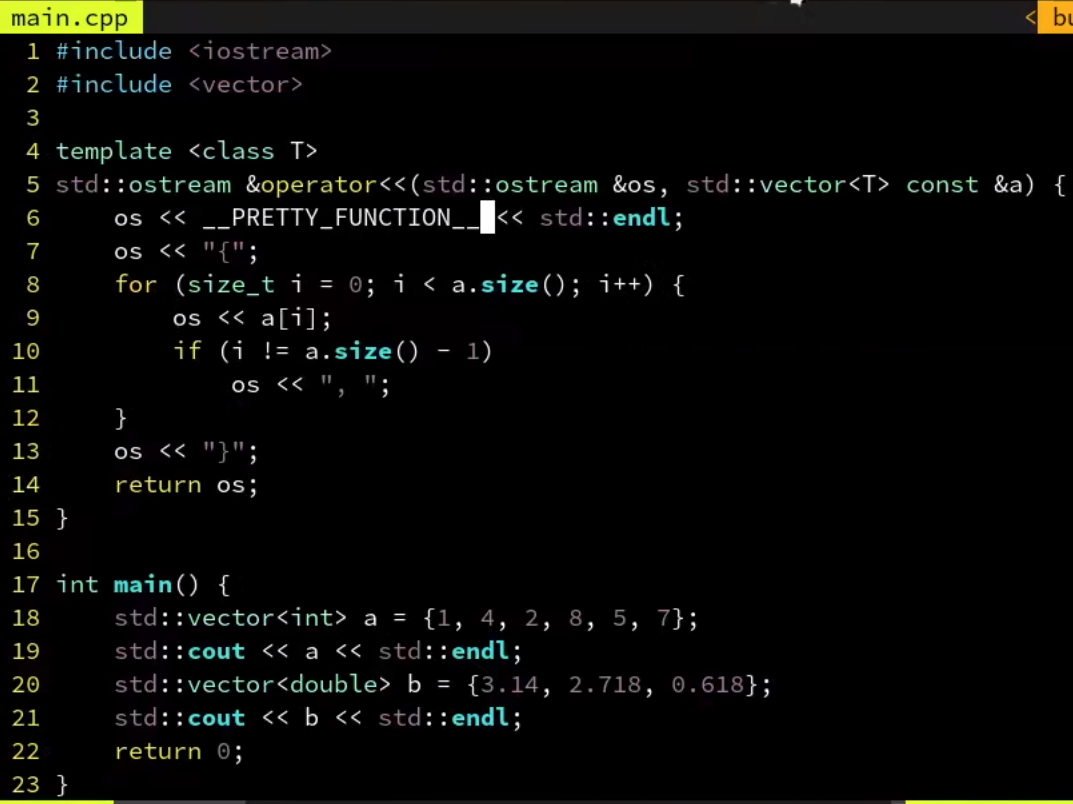
可以把函数的信息打印出来
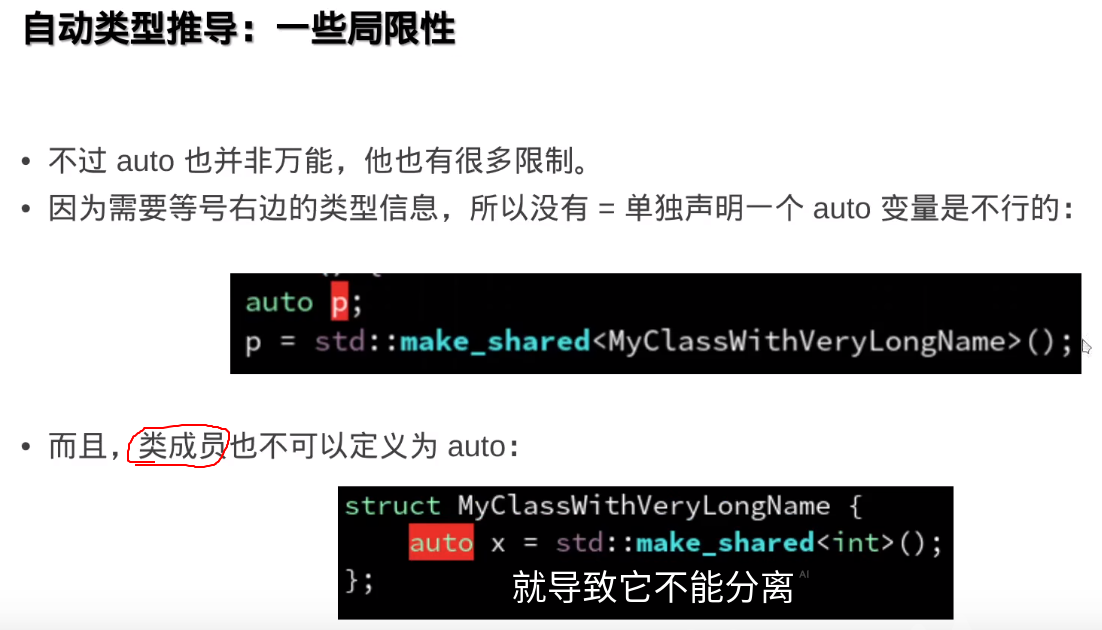

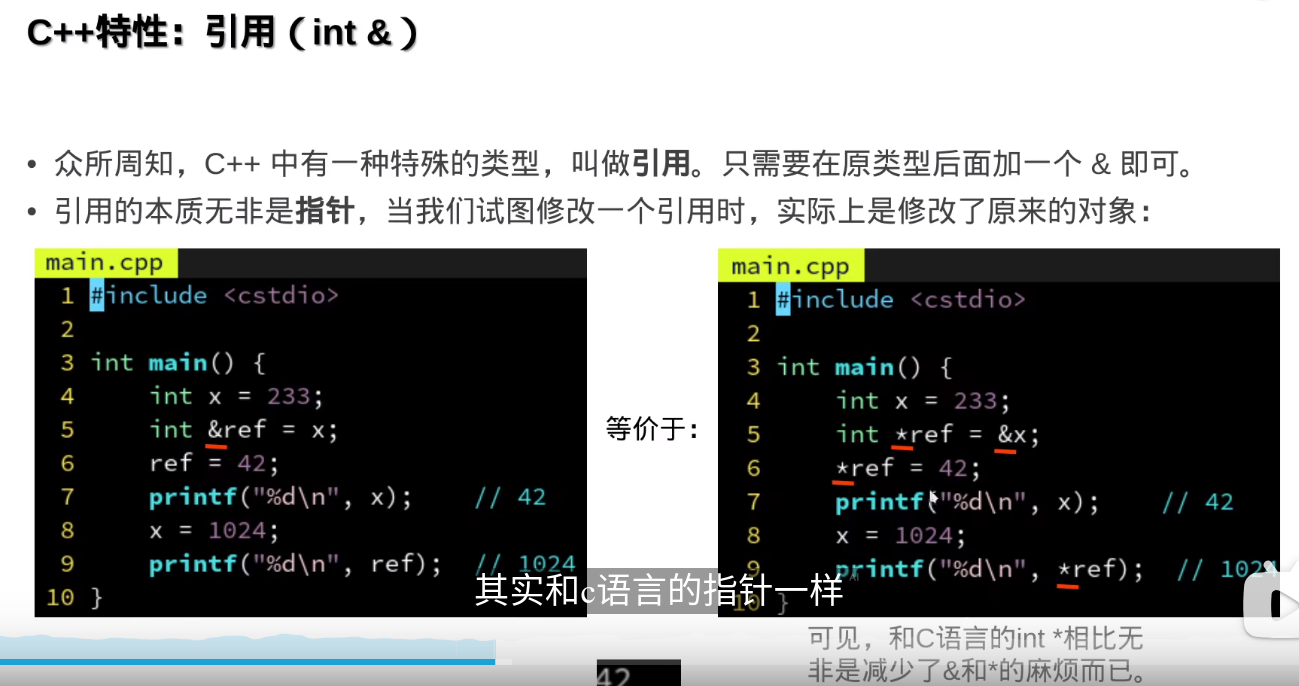
c++里的引用(int &)相当于C里面的指针(int*)
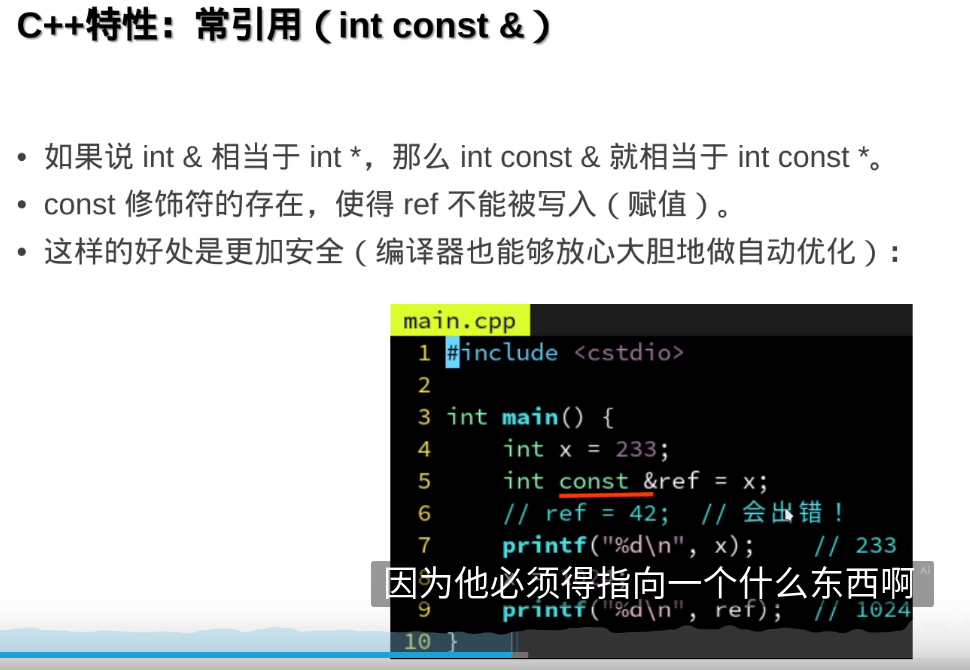 引用没有空,指针可以空
引用没有空,指针可以空
auto & auto const & 也可
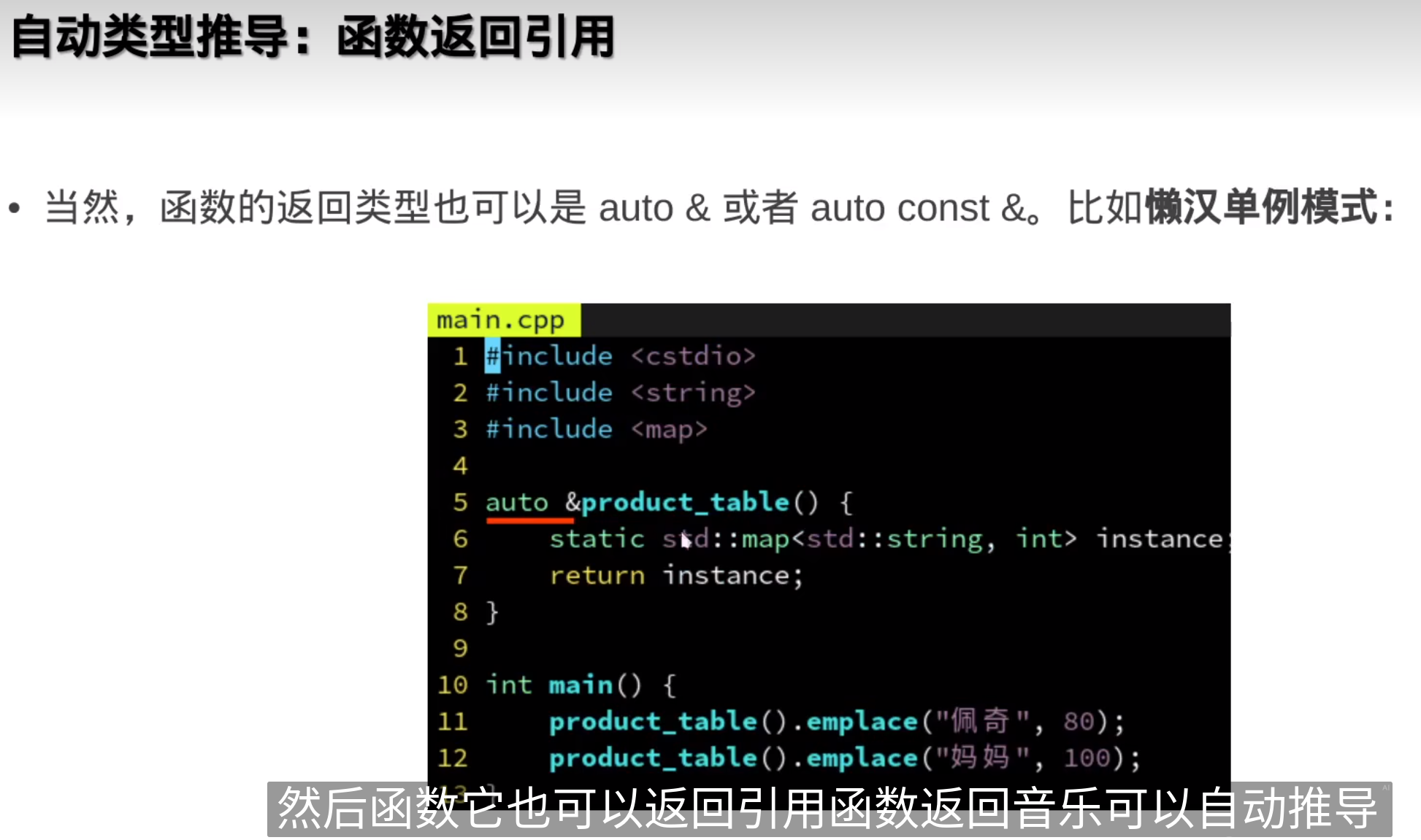
懒汉单例模式(Lazy Singleton)是一种设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。与饿汉单例模式不同,懒汉单例模式会在需要实例时才进行初始化,因此被称为“懒汉”模式。
下面是一个基本的懒汉单例模式的实现示例(不考虑线程安全):
class Singleton {
public:
// 获取单例实例的静态方法
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
// 禁止拷贝构造函数和赋值操作符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
// 私有构造函数
Singleton() {}
// 静态成员变量,用于存储唯一的实例
static Singleton* instance;
};
// 静态成员变量的初始化
Singleton* Singleton::instance = nullptr;
在多线程环境下,上述实现可能会导致线程安全问题,因此需要对其进行改进。可以使用互斥锁(mutex)来确保线程安全:
#include <mutex>
class Singleton {
public:
// 获取单例实例的静态方法
static Singleton* getInstance() {
if (instance == nullptr) {
std::lock_guard<std::mutex> lock(mutex);
if (instance == nullptr) {
instance = new Singleton();
}
}
return instance;
}
// 禁止拷贝构造函数和赋值操作符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
// 私有构造函数
Singleton() {}
// 静态成员变量,用于存储唯一的实例
static Singleton* instance;
// 互斥锁,用于保证线程安全
static std::mutex mutex;
};
// 静态成员变量的初始化
Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mutex;
在C++11及以后的标准中,可以使用std::call_once来确保实例的唯一性,并提高线程安全性:
#include <mutex>
class Singleton {
public:
// 获取单例实例的静态方法
static Singleton* getInstance() {
std::call_once(flag, []() {
instance.reset(new Singleton());
});
return instance.get();
}
// 禁止拷贝构造函数和赋值操作符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
private:
// 私有构造函数
Singleton() {}
// 静态成员变量,用于存储唯一的实例
static std::unique_ptr<Singleton> instance;
// 静态变量,用于确保单例实例只创建一次
static std::once_flag flag;
};
// 静态成员变量的初始化
std::unique_ptr<Singleton> Singleton::instance;
std::once_flag Singleton::flag;
在这个实现中,std::call_once 和 std::once_flag 确保了即使在多线程环境中,单例对象也只会被创建一次。std::unique_ptr 自动管理内存,避免了手动释放内存的麻烦。
使用互斥锁(mutex)来确保线程安全时为什么只有锁:std::lock_guardstd::mutex lock(mutex); 没有解锁?
在使用 std::lock_guard<std::mutex> 时,解锁是由 std::lock_guard 自动处理的,而不需要显式地调用解锁操作。这是因为 std::lock_guard 是一个RAII(Resource Acquisition Is Initialization)风格的类,它的设计目的是简化互斥锁的管理并自动释放资源。
std::lock_guardRAII 是一种编程习惯,确保资源(如内存、文件句柄、互斥锁等)的生命周期由对象的生命周期来管理。std::lock_guard 利用 RAII 原则来管理互斥锁的锁定和解锁:
std::lock_guard 对象被创建时,它会在构造函数中自动锁定传递给它的 std::mutex 对象。std::lock_guard 对象被销毁(即其作用域结束时),它的析构函数会自动释放(解锁)互斥锁。这种设计使得你不需要显式地编写解锁代码,降低了因为遗漏解锁操作而导致的潜在错误。
std::lock_guard<std::mutex> lock(mutex);
:
lock 对象会在构造函数中自动锁定 mutex。lock 对象超出作用域(例如,getInstance 方法的执行结束时),lock 的析构函数会被调用,从而自动解锁 mutex。自动解锁:减少了因为忘记解锁导致的死锁问题。
简化代码:不需要显式地管理锁的释放,使代码更加简洁和易于维护。
异常安全:即使在 getInstance 方法中发生异常,std::lock_guard 也会确保互斥锁在 lock 对象被销毁时正确解锁,从而避免死锁。
通过 std::lock_guard 或其他类似的 RAII 风格的工具,C++ 提供了一种简洁而安全的方式来管理互斥锁,帮助程序员编写更健壮的多线程代码。



decltype(auto)和auto的区别
decltype(auto) 和 auto 都用于类型推导,但它们有不同的行为:
auto:
auto 根据表达式的值推导类型,不会保留表达式的引用性(即 auto 不会推导出引用类型,除非显式指定)。auto x = 5; 中,x 的类型是 int。decltype(auto):
decltype 和 auto 的特性。它推导出表达式的类型,包括引用(decltype 会保留表达式的原始类型)。decltype(auto) y = (5); 中,y 的类型是 int&,因为 (5) 是一个左值引用。总结:
auto 时,结果类型是值类型。decltype(auto) 时,结果类型保持原表达式的类型,包括引用。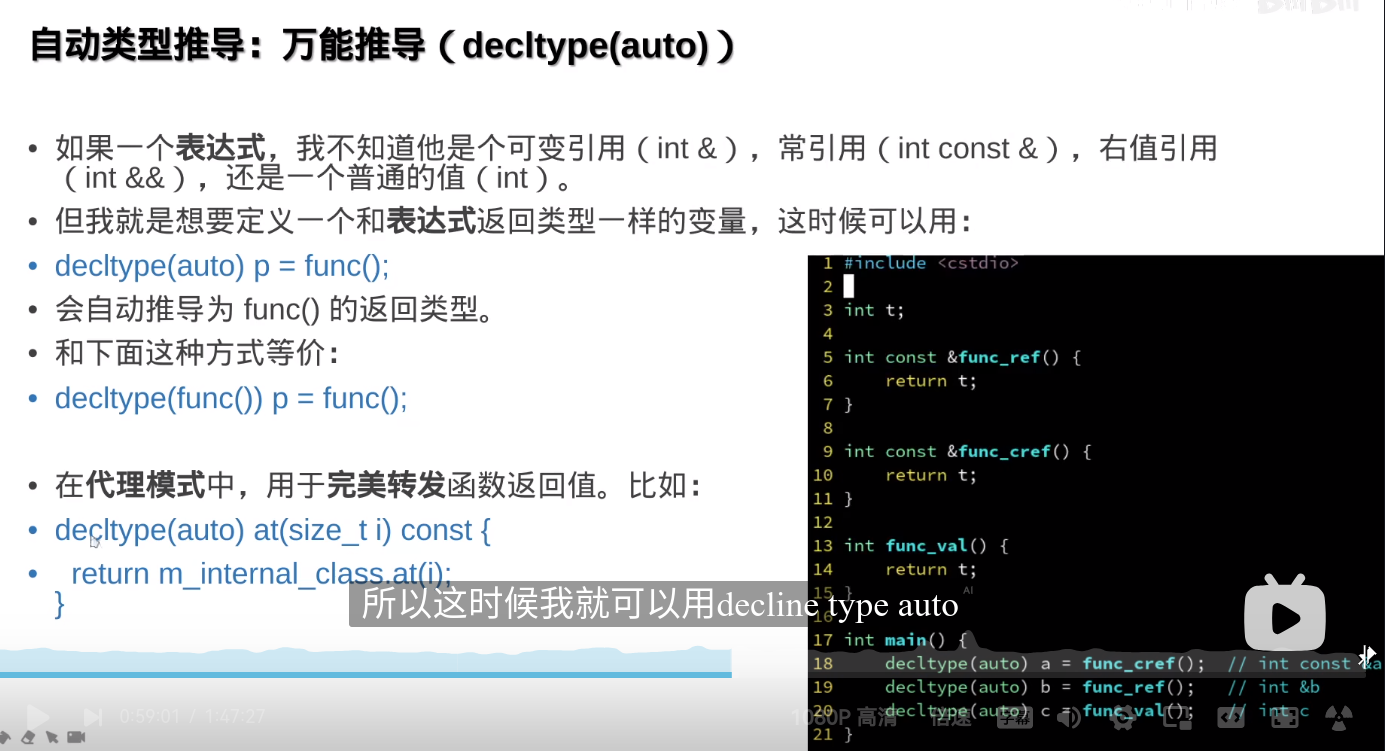

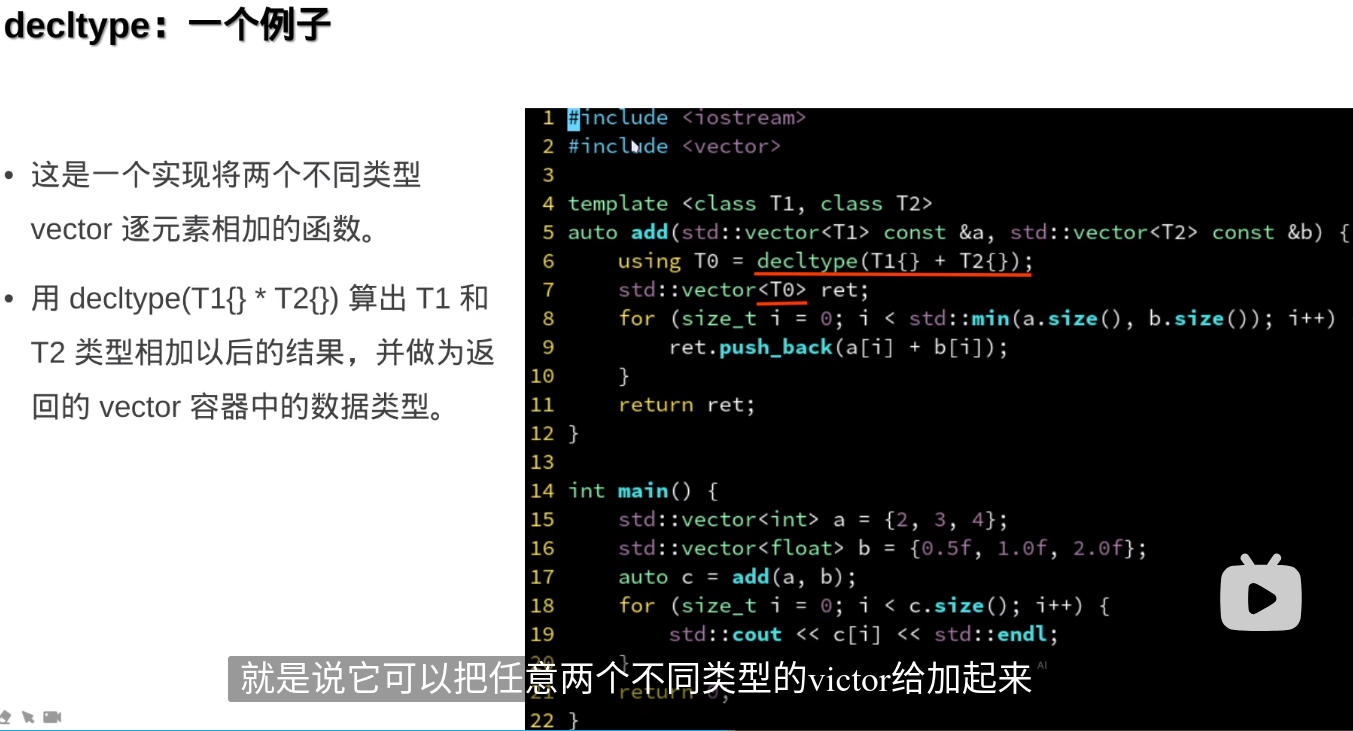 T1{}创建一个T1的对象
T1{}创建一个T1的对象

函数作为参数传入另一个函数,实际传的是这个函数的起始地址

确实相当于函数指针
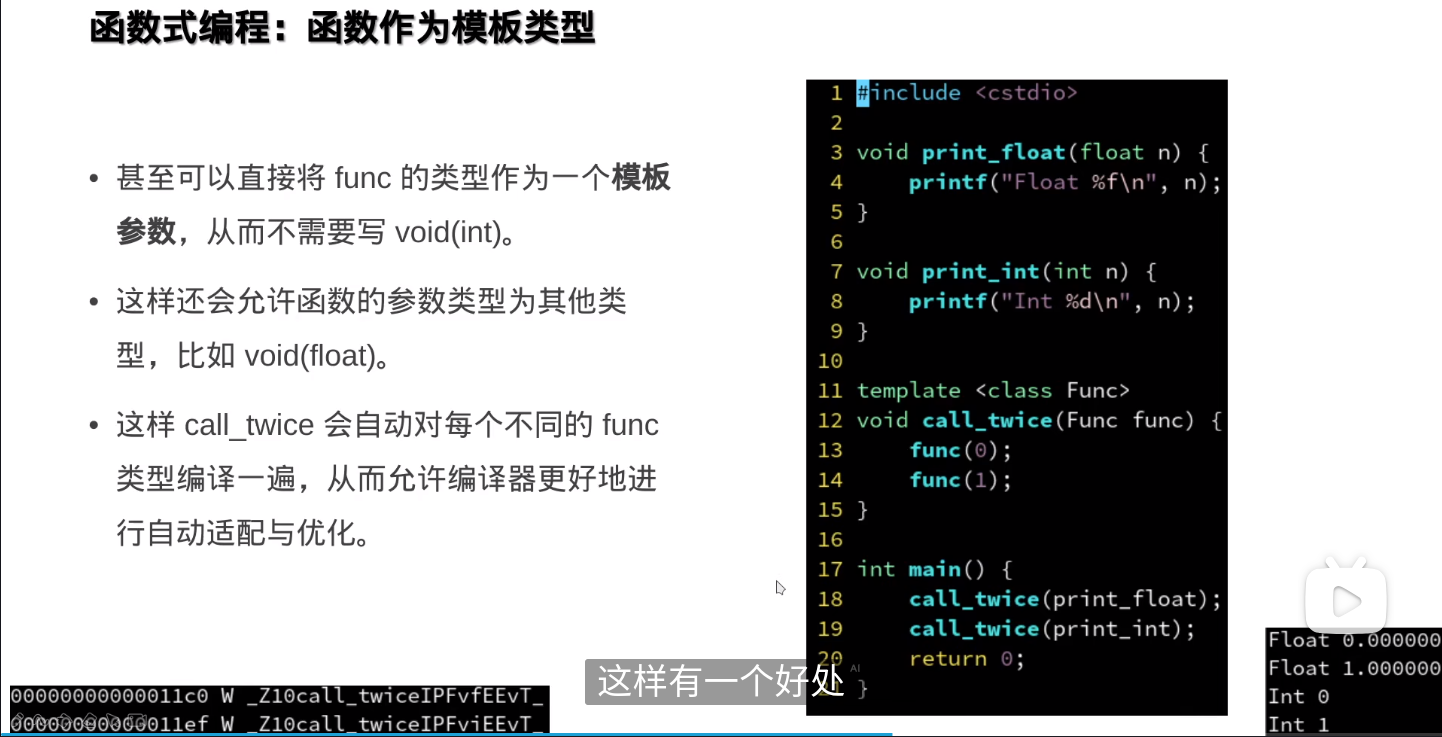
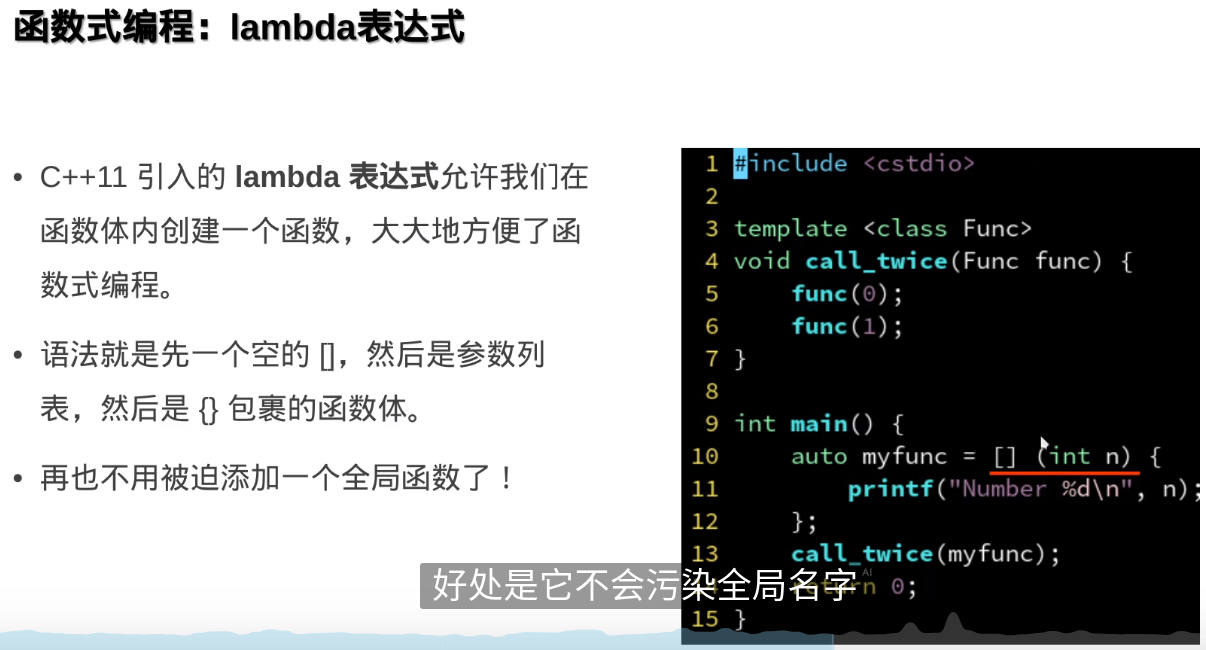
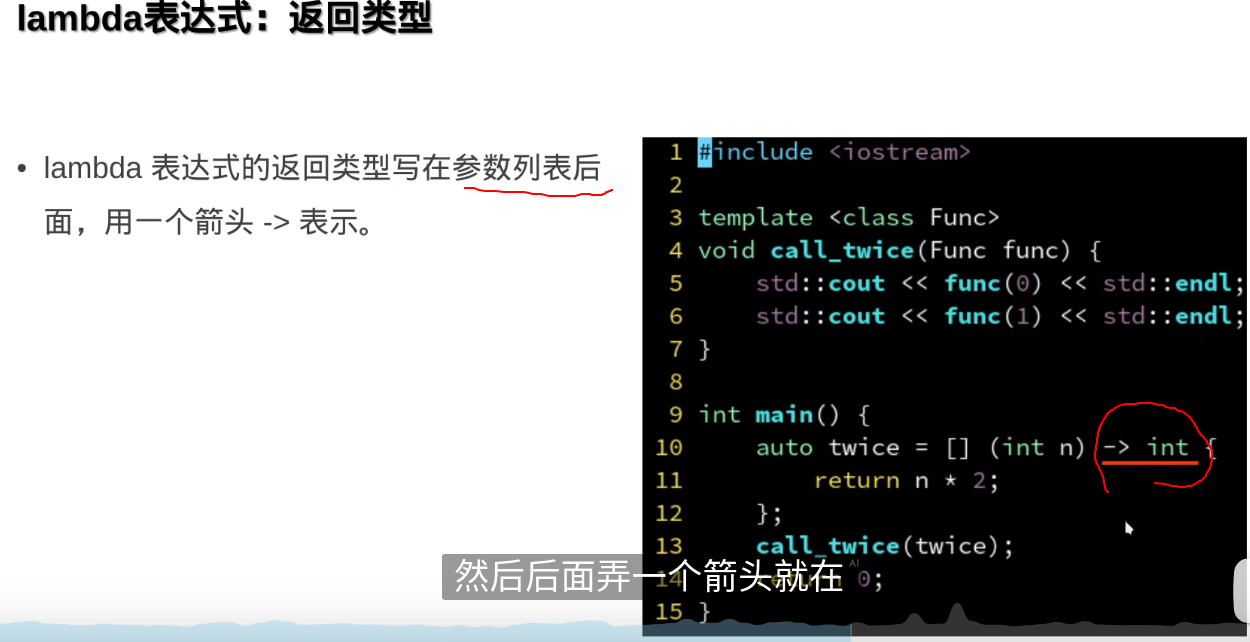



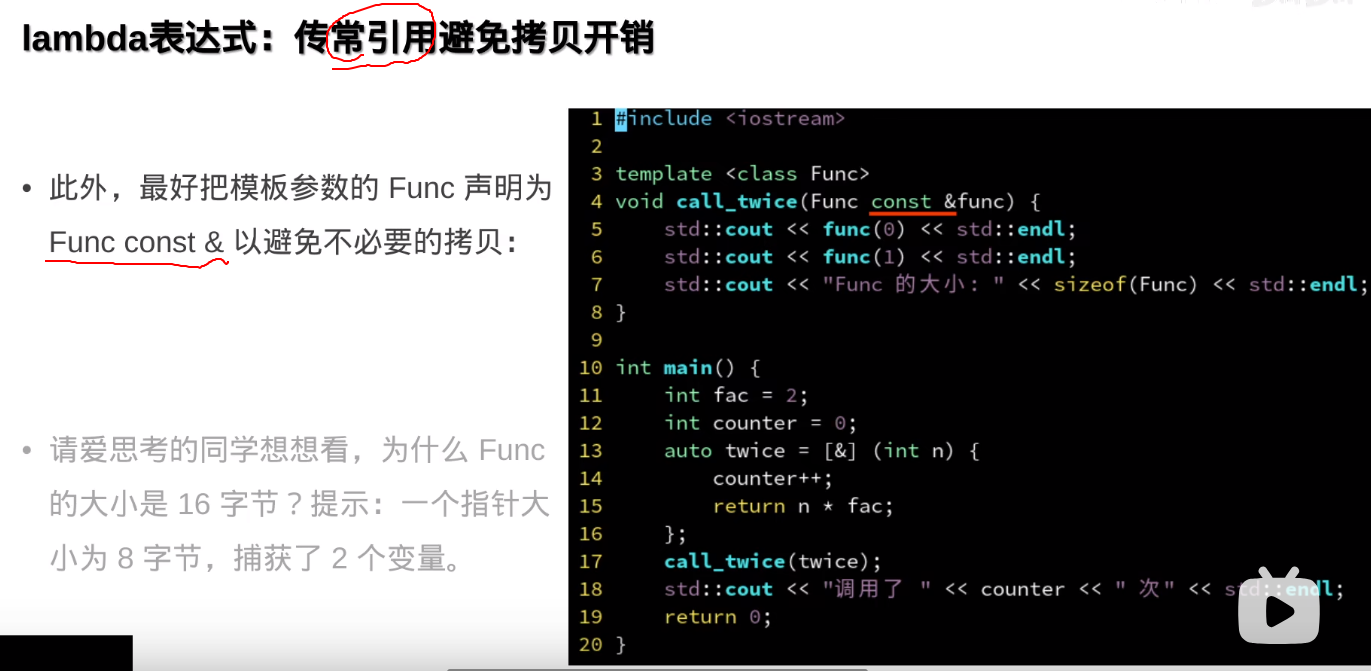



###避免使用模板参数
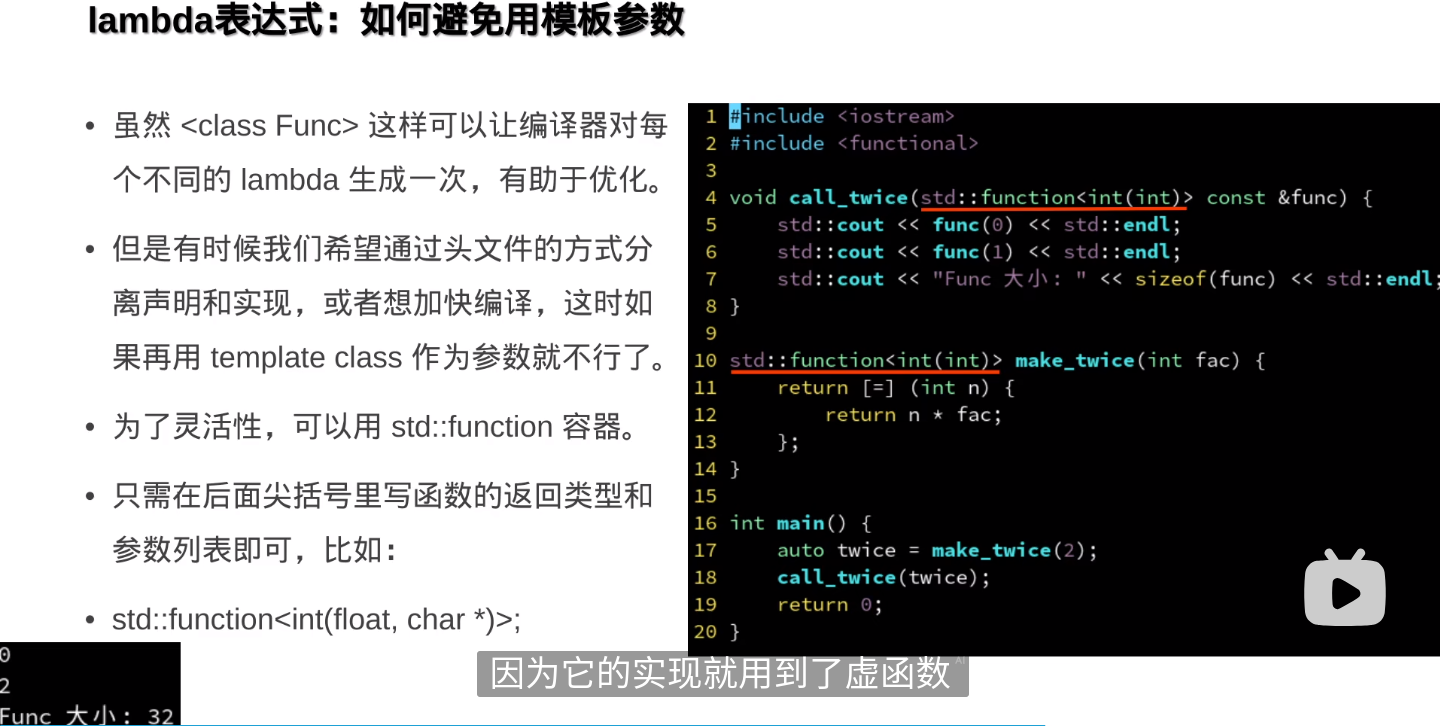
类型擦除技术:std::function容器

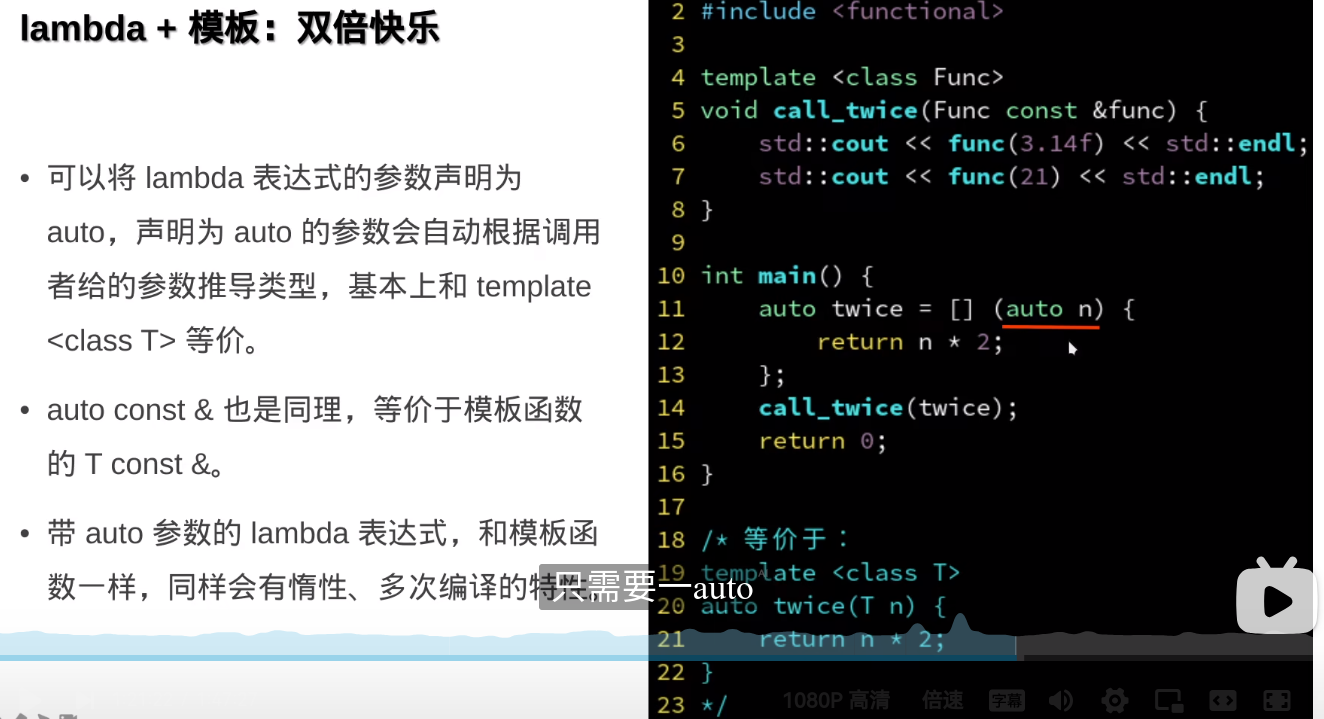 但是没办法做部分特例化
但是没办法做部分特例化

立即调用 Lambda:在 lambda 表达式的定义后面加上 (),立即调用这个匿名函数。 lambda 表达式的返回值可以用于初始化变量或进行其他操作。

可以利用return自带的break效果既实现break又赋值的效果





左值持久,右值短暂,左值有持久的状态,而右值要么是字面常量,要么是在表达式求值过程中创建的临时对象(将要被销毁的对象)。
右值引用的好处是减少右值作为参数传递时的复制开销
使用std::move可以获得绑定到一个左值的右值引用
int intValue = 10;
int &&intValue3 = std::move(intValue);
decltype(auto) 是 C++11 引入的一种类型推断工具,它结合了 decltype 和 auto 的特性,用于在声明变量时推断其类型。与 auto 不同,decltype(auto) 更精确地推断变量的类型,包括引用性。
用法:decltype(auto) 在声明变量时,会推断出表达式的确切类型,包括是否是引用类型。
int x = 10;
int& ref = x;
decltype(auto) y = ref; // y 是 int&,与 ref 类型相同
区别:auto 只推断值类型,而 decltype(auto) 会保持原有的引用类型或常量性。
auto a = x; // a 是 int
decltype(auto) b = x; // b 是 int,b 不是引用
decltype(auto) c = ref; // c 是 int&,与 ref 类型相同
总结:decltype(auto) 在需要精确类型推断,包括引用时非常有用。
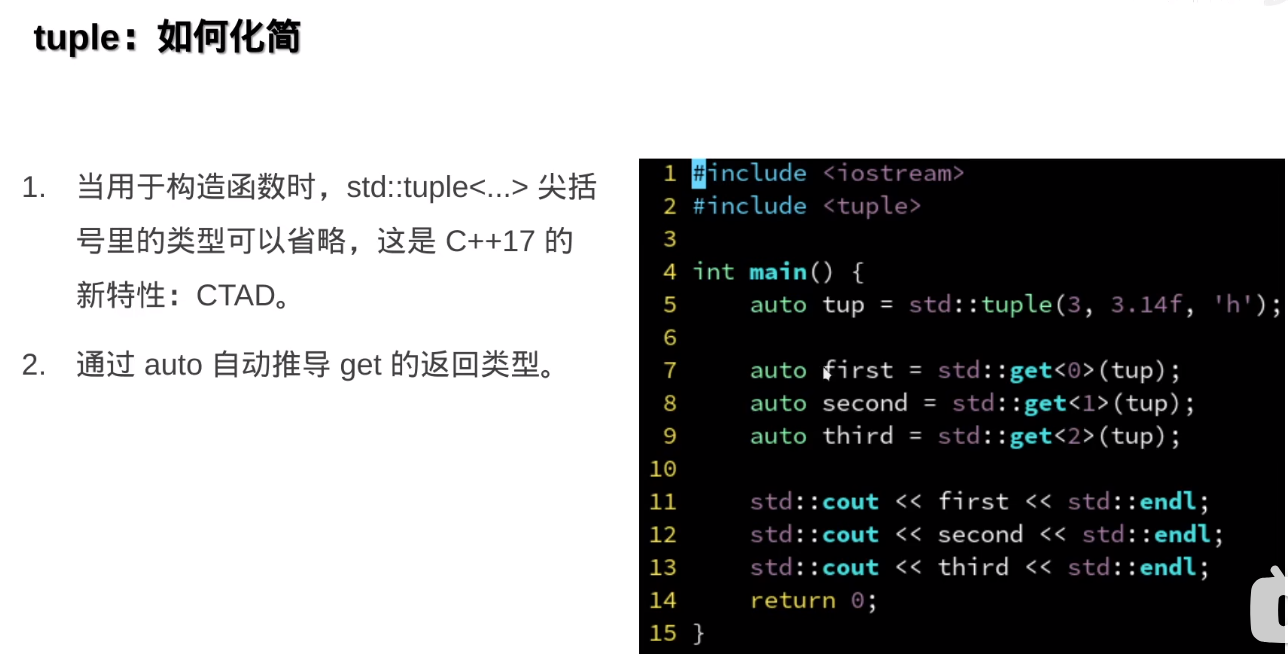
但是tuple容器的万能推导由于历史原因,不是decltype(auto),而是auto &&
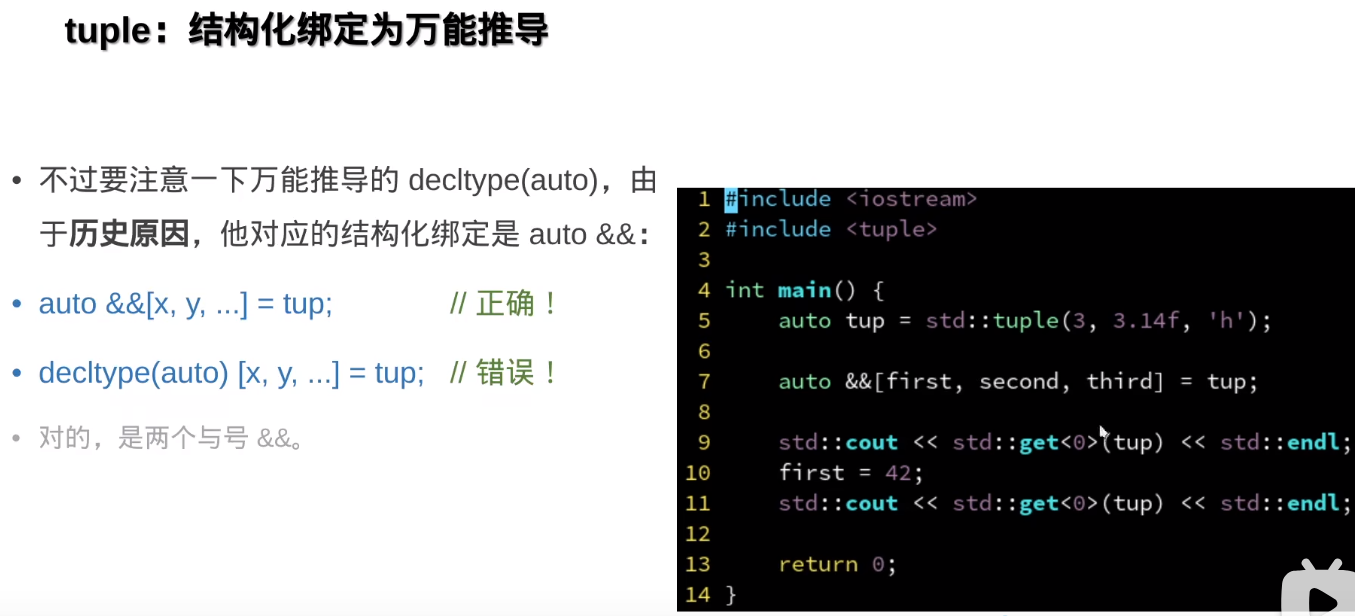
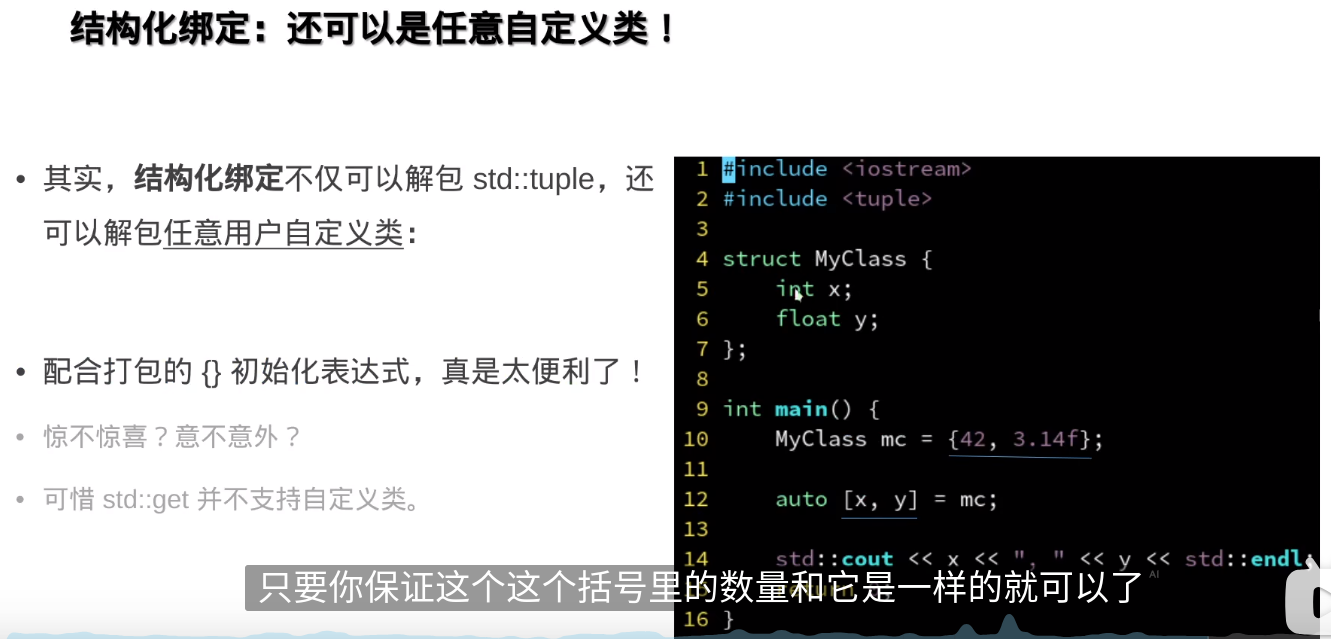
结构化绑定的基本语法如下:
auto [var1, var2, var3] = expression;
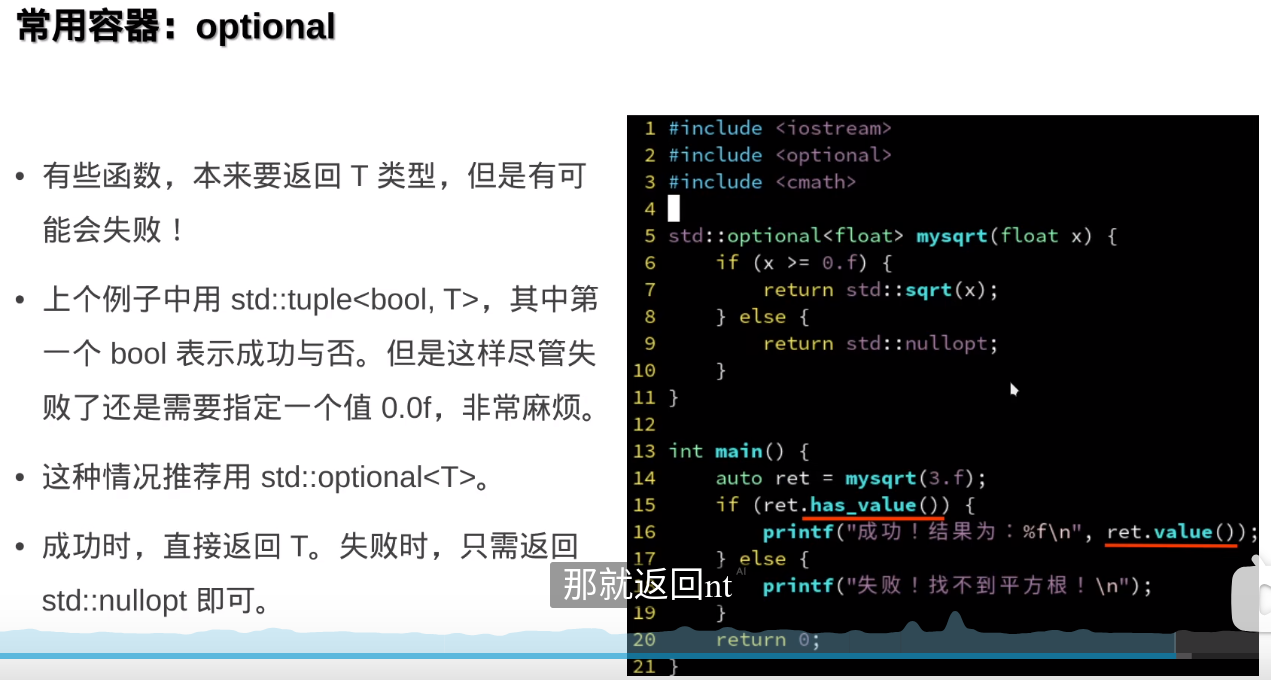
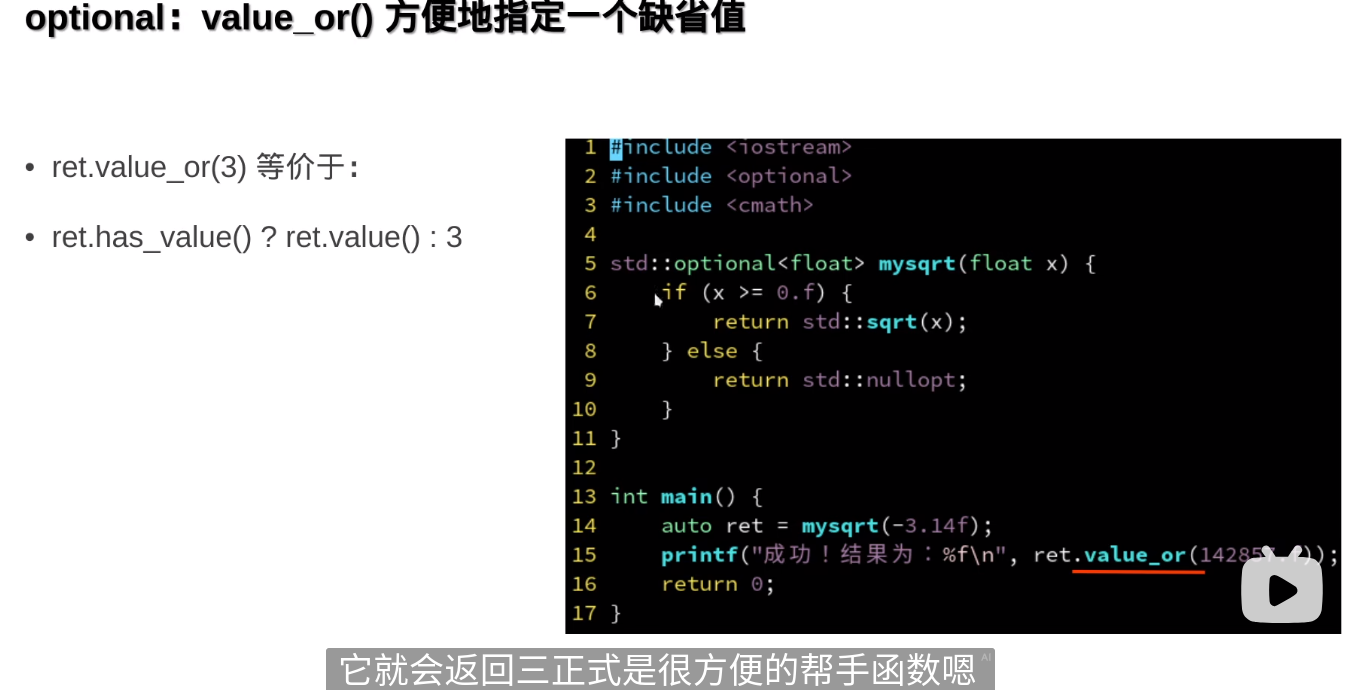

 optional就像一个更安全的指针
optional就像一个更安全的指针
在 C++ 中,union 是一种数据结构,它允许在同一内存位置存储不同的数据类型。union 的所有成员共享同一块内存区域,这意味着在任何给定时刻,union 只能存储一个成员的数据。使用 union 可以节省内存,特别是在需要存储多种不同类型但从不同时存储这些类型时。
union 的基本语法union UnionName {
type1 member1;
type2 member2;
type3 member3;
// more members
};
内存共享:
union 中的所有成员共享同一块内存。因此,union 的大小由其最大成员的大小决定。只能存储一个成员:
union 可以定义多个成员,但在任何时刻只能存储一个成员的数据。写入一个成员会覆盖掉之前写入的成员的数据。节省内存:
union 可以节省内存,尤其是在只需要存储其中一个成员的数据时。#include <iostream>
union Data {
int intValue;
float floatValue;
char charValue;
};
int main() {
Data data;
data.intValue = 5;
std::cout << "intValue: " << data.intValue << std::endl;
data.floatValue = 3.14;
std::cout << "floatValue: " << data.floatValue << std::endl;
data.charValue = 'A';
std::cout << "charValue: " << data.charValue << std::endl;
// 访问数据会输出不确定的结果,因为各个成员共享同一内存
std::cout << "intValue (after modifying to charValue): " << data.intValue << std::endl;
return 0;
}
在上面的示例中,union Data 可以存储 int, float, 和 char 三种数据类型,但它们共享同一块内存。当写入 floatValue 后,之前存储的 intValue 的数据会被覆盖,读取 intValue 会得到不可预测的结果。
类型安全:
union 时要注意类型安全。读取当前未写入的成员数据可能会导致未定义的行为。构造和析构:
union 允许只有一个成员的构造和析构。C++11 之后,union 可以包含具有非平凡构造函数、析构函数或拷贝/移动操作符的成员,但这些操作必须在使用 union 的情况下正确处理。std::variant 替代:
std::variant,这是一个更安全的替代 union,提供了类型安全的联合体和更丰富的功能。总的来说,union 是一个低级数据结构,用于内存优化和处理不同类型的数据,但在实际编程中需谨慎使用。




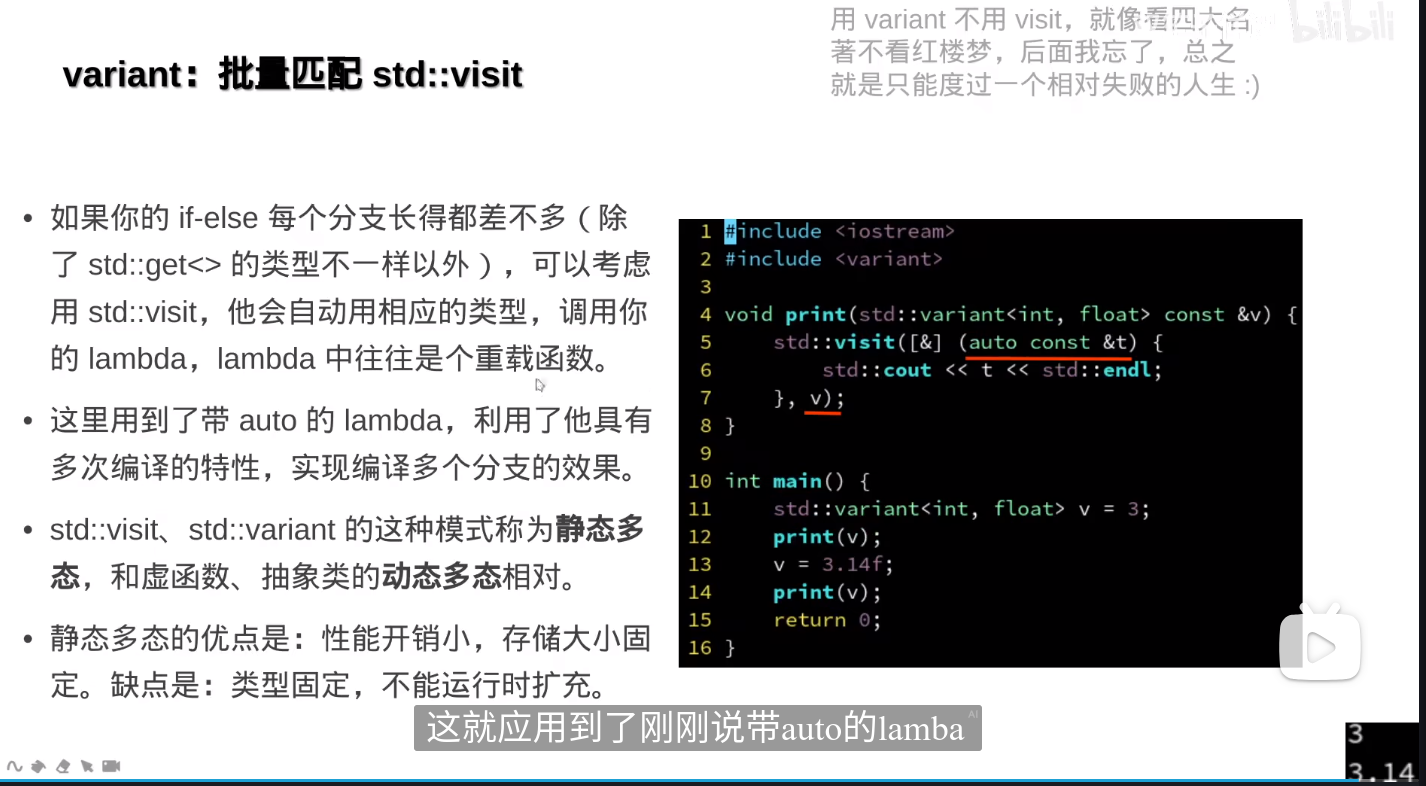
auto 作为参数类型实际上利用了 C++ 的模板机制,因为 auto 类型推断相当于模板类型参数的自动推导。虽然 lambda 本身不是一个模板,但它的参数使用 auto 实际上是利用了模板的类型推断机制。[&] (auto const &t){} 使用了模板特性中的类型推断机制,通过 auto 使得 lambda 表达式能够处理多种不同类型的参数。这个功能在 C++11 及其后续版本中成为了更灵活、强大的工具,使得代码更加简洁和通用。
编译器是从源代码生成汇编语言

RIP是当前执行的代码的地址
MMX,XMM,YMM都是用于储存浮点数的寄存器
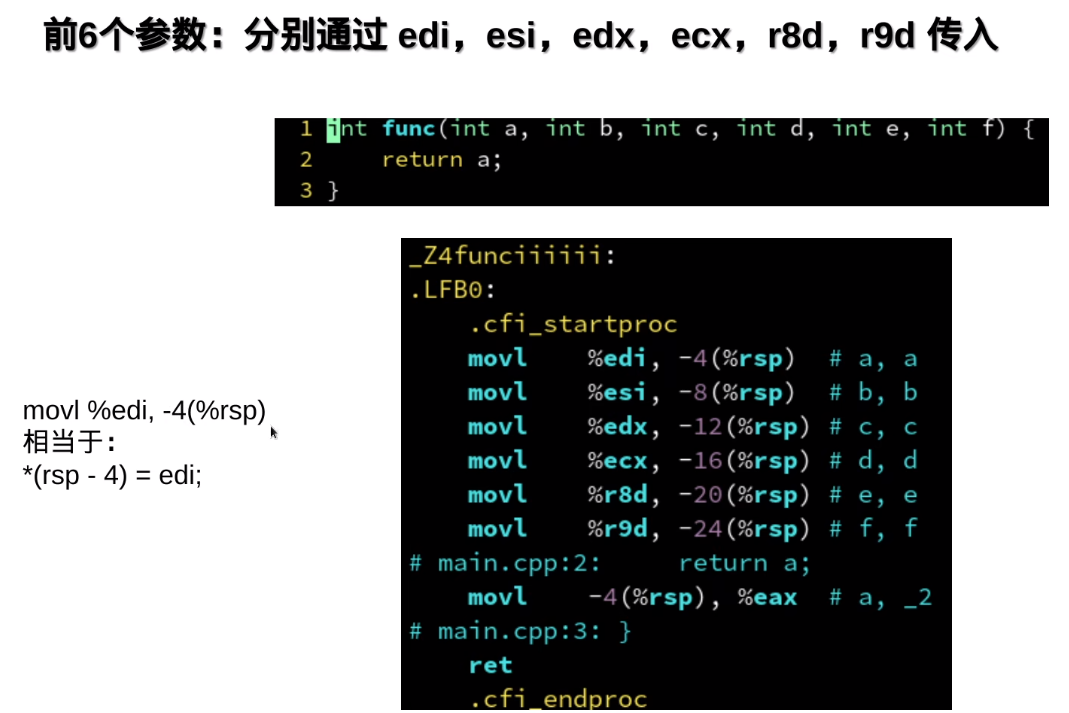
把局部变量放入寄存器,读写就更快了
rsp代表堆栈: -4(%rsp)其中-代表是堆栈上的某一个地址


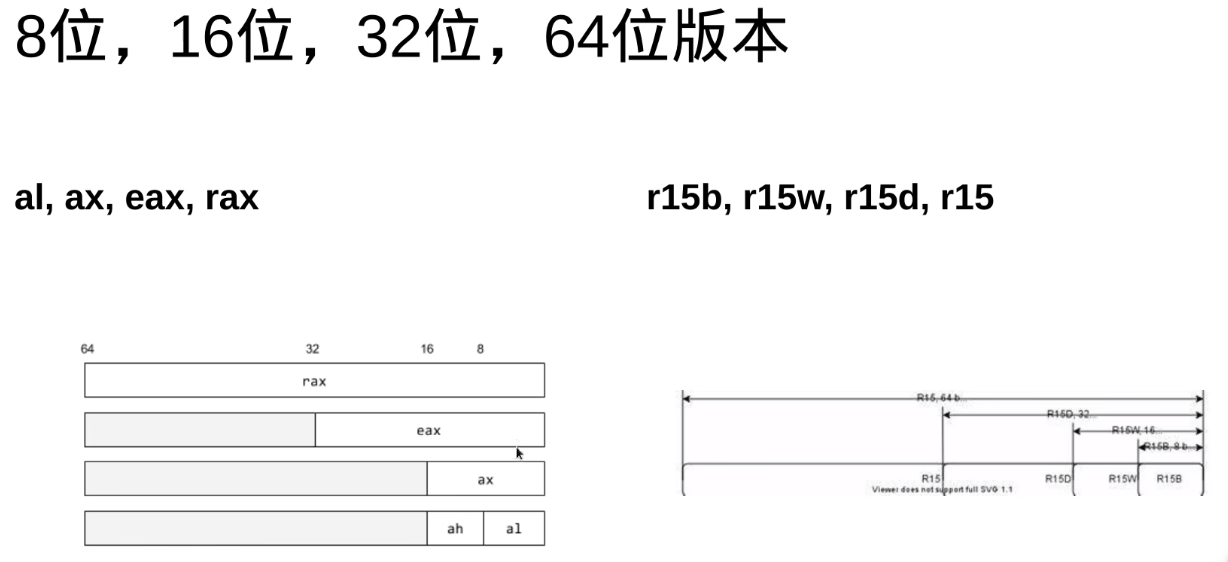
eax与rax的低32位是共用的
ax与eax的低16位是通用的
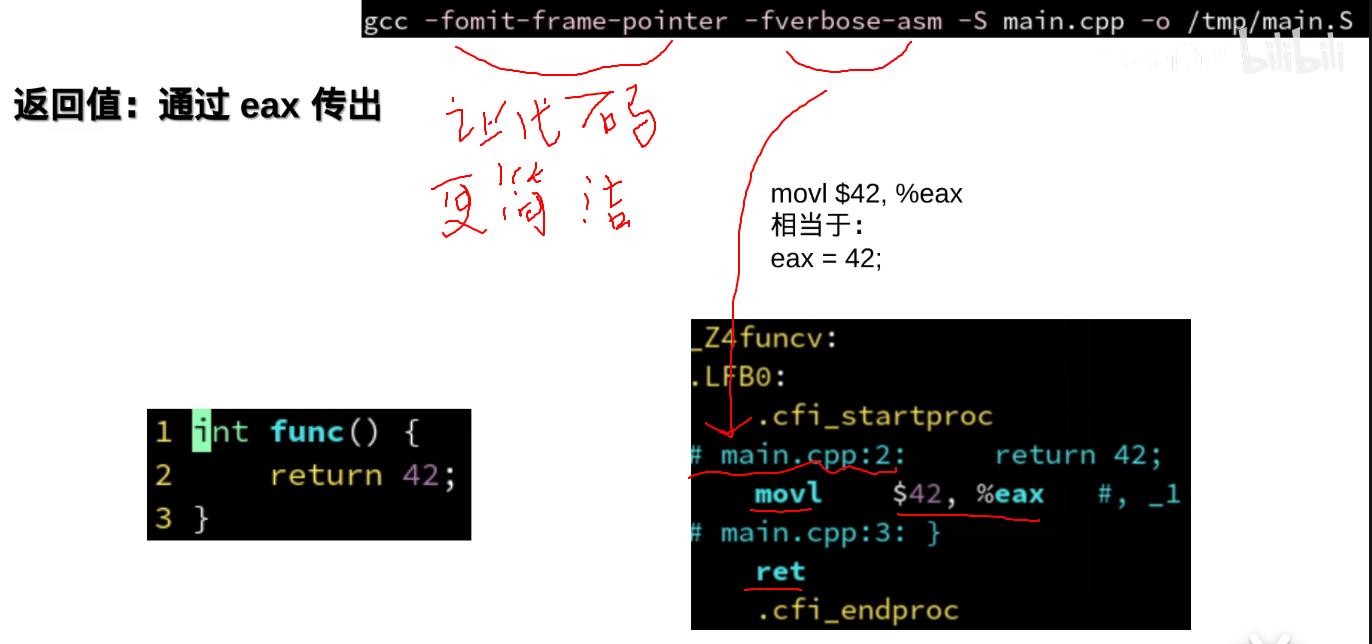 %eax :返回值
%eax :返回值
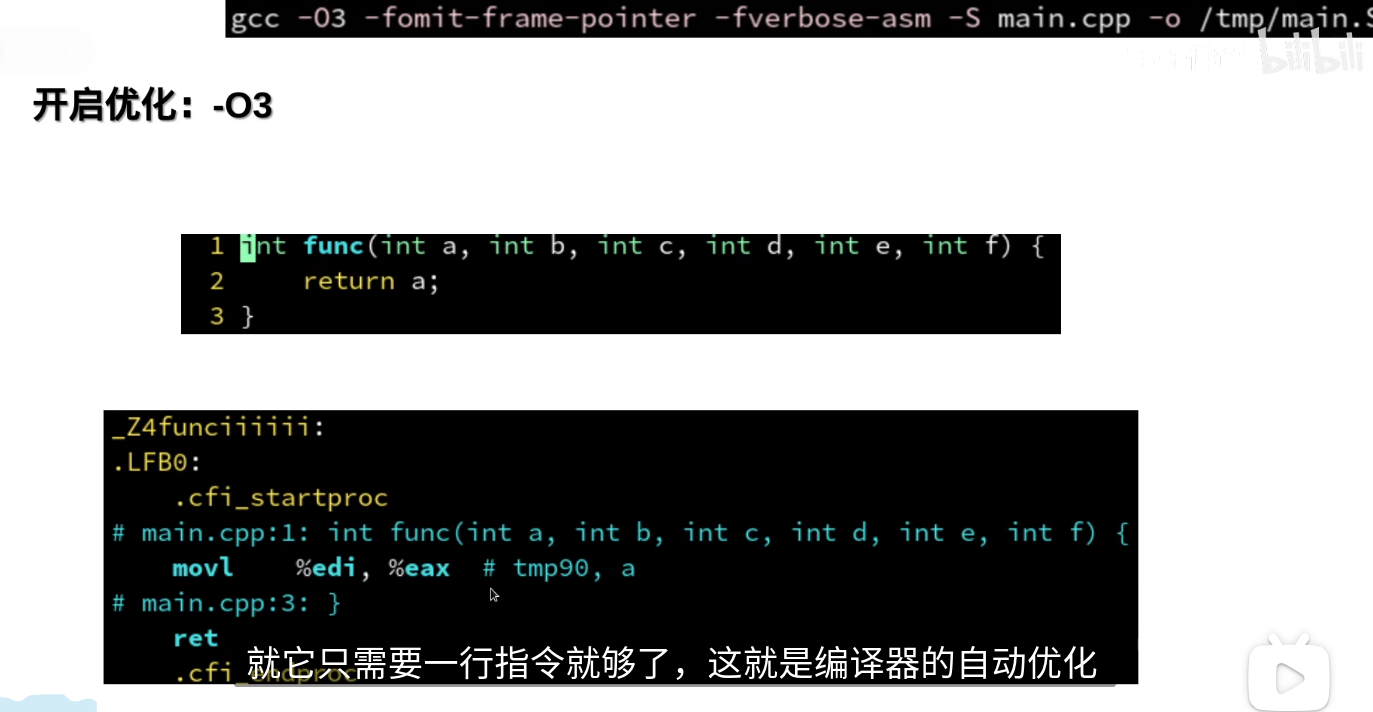

l代表32位,q代表64位


在 C++ 中,ThreadPool threadPool {}; 和 ThreadPool threadPool ; 是两种不同的初始化方式,它们对 ThreadPool 对象的初始化有所不同。
ThreadPool threadPool {};这是 直接初始化(Direct Initialization) 的一种方式,使用了 统一初始化语法(Uniform Initialization Syntax)。具体来说,这种写法会调用 ThreadPool 的默认构造函数,并且初始化所有成员变量为默认值:
ThreadPool 有默认构造函数,它将被调用来创建对象。ThreadPool 的构造函数没有显式初始化某些成员变量,它们会被自动初始化为其类型的默认值。对于基本数据类型(如 int),这意味着它们会被初始化为 0。对于指针类型,它们会被初始化为 nullptr。ThreadPool threadPool ;这是 默认初始化(Default Initialization) 的一种方式。在这种情况下,ThreadPool 对象的初始化行为依赖于以下几种情况:
ThreadPool 有默认构造函数,它将被调用来创建对象。ThreadPool 的构造函数没有显式初始化某些成员变量,那么这些成员变量的初始化方式依赖于它们的类型和是否有默认构造函数。基本数据类型(如 int)不会被初始化到任何特定值(它们会是未定义的),指针类型也不会自动初始化(它们的值是不确定的)。ThreadPool threadPool {};**:使用统一初始化语法,所有成员变量被初始化为其类型的默认值,较为安全。ThreadPool threadPool ;:默认初始化,成员变量的初始值依赖于其类型和构造函数,可能会导致未定义行为(对于基本数据类型)。在实践中,推荐使用 ThreadPool threadPool {}; 以确保对象的成员变量被正确地初始化,避免潜在的未定义行为。
在对象构造时,std::lock_guard 会自动锁定传入的互斥锁,而在对象析构时,它会自动释放锁
std::lock_guard<std::mutex> guard(lock);
当执行 std::lock_guard<std::mutex> guard(lock); 时:
guard 对象在创建时会自动调用 lock() 方法来锁定传入的互斥锁(lock)。guard 对象的作用域结束(例如,离开当前的代码块或函数)时,它的析构函数会自动调用 unlock() 方法来解锁互斥锁要理解 subset 中的这行数据,我们可以将其拆解成几部分来分析:
[[ 0. 1. 2. 3. 4. 5.
6. 7. 8. -1. -1. 9.
-1. -1. 10. 11. 12. -1.
21.50975911 13. ]]
[0, 1, 2, 3, 4, 5, 6, 7, 8, -1, -1, 9, -1, -1, 10, 11, 12, -1] 代表了关键点的索引。-1 表示该位置没有对应的关键点。21.50975911 是这个组合的总评分。这个评分是所有有效关键点的评分之和或某种加权评分的结果。13 是这个组合中的有效关键点数量。这里 13 表示在该组合中共有 13 个有效的关键点索引。这个 subset 行数据表示一个关键点组合,其中包含 13 个有效的关键点,所有这些关键点的索引被列出。组合的总评分为 21.50975911。通过这些信息,你可以了解该组合的结构以及它在某种评分机制下的表现。
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],总共 13 个。-1 的位置表示这些位置没有有效的关键点。21.50975911 可能是根据这些有效关键点的某些特性(如评分、置信度等)计算出来的。这样的 subset 数据通常用于在处理关键点检测任务中,选择或评估最佳的关键点组合。
这个是candidate: [[2.19000000e+02 1.18000000e+02 9.45192695e-01 0.00000000e+00] [1.96000000e+02 2.63000000e+02 9.28416848e-01 1.00000000e+00] [8.70000000e+01 2.89000000e+02 8.54923248e-01 2.00000000e+00] [6.60000000e+01 4.49000000e+02 8.24636817e-01 3.00000000e+00] [1.20000000e+02 5.07000000e+02 7.98071980e-01 4.00000000e+00] [3.07000000e+02 2.38000000e+02 8.55016530e-01 5.00000000e+00] [3.64000000e+02 3.76000000e+02 7.69826353e-01 6.00000000e+00] [2.81000000e+02 4.45000000e+02 8.87847126e-01 7.00000000e+00] [1.68000000e+02 5.42000000e+02 4.70188409e-01 8.00000000e+00] [2.98000000e+02 5.27000000e+02 4.78751719e-01 9.00000000e+00] [1.94000000e+02 1.03000000e+02 9.33498561e-01 1.00000000e+01] [2.30000000e+02 1.02000000e+02 9.27351594e-01 1.10000000e+01] [1.35000000e+02 1.22000000e+02 8.83832693e-01 1.20000000e+01]] 这个是subset: [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. -1. -1. 9. -1. -1. 10. 11. 12. -1. 21.50975911 13. ]]
“Stack underflow”和“stack overflow”都是与栈(stack)数据结构相关的错误,但它们的含义和发生的情况不同:
NULL 是一个预处理宏,通常被定义为 0 或 ((void*)0)。它在类型上是一个整数,因此可能导致类型不安全的情况。
nullptr 是 C++11 引入的一个关键字,表示空指针。它是一个特定的类型 std::nullptr_t,能更好地支持类型安全。
OpenGL 上下文:OpenGL 上下文是一个包含了所有 OpenGL 状态的信息的环境。每个窗口通常会有一个自己的上下文。
gcc -E main.cpp | tail -n 15 是什么意思
gcc -E main.cpp | tail -n 15 是一个命令行指令,具体含义如下:
gcc:GNU 编译器集合,用于编译 C 和 C++ 程序。-E:该选项告诉 gcc 只进行预处理,即处理源代码中的宏和包含文件,但不进行编译。main.cpp:要处理的源文件。|:管道符,用于将前一个命令的输出传递给后一个命令。tail -n 15:该命令输出前一个命令的最后 15 行。因此,整个命令的作用是预处理 main.cpp 文件,并显示预处理后的结果的最后 15 行。这通常用于调试宏和包含的头文件。
constexpr
编译时常量
在编译时计算
结合 if constexpr 根据条件选择性编译代码
__attribute__((inline)) 是 GCC 和 Clang 编译器中的一个扩展,用于建议编译器将某个函数内联。内联函数的目的是减少函数调用的开销,通过将函数代码直接插入到调用处来提高性能。
inline 属性,编译器仍然可以选择不内联,具体取决于优化策略和函数的复杂性。把std::string opengl_errno_name(int err)改成static const char *opengl_errno_name(int err)的好处
将 std::string opengl_errno_name(int err) 改为 static const char *opengl_errno_name(int err) 的好处包括:
const char* 可以减少内存分配和拷贝操作,提高性能,尤其在频繁调用的情况下。const char* 不需要动态分配内存,避免了内存泄漏的风险,使用起来更加安全。const char* 更加兼容。#include <GL/gl.h> 和 #include <GL/glu.h> 是 OpenGL 的头文件,它们用于图形编程。具体来说:
<GL/gl.h>**:<GL/glu.h>**:#include <GLFW/glfw3.h> 是用于包含 GLFW 库的头文件,GLFW 是一个开源的跨平台库,主要用于创建窗口、处理用户输入以及管理 OpenGL 上下文。具体功能包括:
#include <glm/glm.hpp> 和 #include <glm/ext.hpp> 是用于包含 GLM(OpenGL Mathematics)库的头文件。具体功能如下:
<glm/glm.hpp>**:<glm/ext.hpp>**:GLM 常用于 OpenGL 应用程序中,以简化数学计算和数据管理。
❥ 基本
jk / kj /
q / :wq / ZZ 保存并退出
Q 记录宏
gl / $ 移动到行末尾
gh / ^ 移动到行开头(不包括空格)
3gl / $2l 移动到行末尾倒数第 3 个字符
3gh / ^2h 移动到行开头倒数第 3 个字符
❥ 跳转
gd 跳转到定义
gD 跳转到声明
gy 跳转到变量类型的定义
gY 跳转到虚函数实现
go 头文件和源文件来回跳转
gr 寻找符号引用
gz 罗列所有相关信息(定义、引用等)
gf 打开光标下的文件名
gF 打开光标下的文件名并跳到右侧指定的行号
gx 打开光标下的网页链接
❥ 重构
gcc 注释/取消注释当前选中的代码/行
gn 重命名变量
gw 尝试自动修复问题
g= 自动格式化当前代码
❥ 预览
K 悬浮窗查看文档
gsf 预览函数定义
gsc 预览类定义
gsd 预览语法错误
❥ 开关
gso 打开大纲
gsg 打开 Git 面板
gsp 打开项目文件树
gss 查看所有静态语法错误
gsl 查看所有编译器报错
gsi 开关 Inlay Hint
❥ 标签页
g
❥ 文本查找
,, 当前文件中模糊查找
,k 当前项目中正则表达式查找
,l 当前项目中的所有文件
,b 当前 Vim 已打开文件
,o 最近打开过的历史文件
,i 当前所有加入 Git 仓库的文件
,p 当前 Git 有未提交修改的文件
,c 所有 Git 提交历史
,v 所有 Git 分支
❥ 选择
vac 选中当前类
vic 选中当前类体内
vaf 选中当前函数
vif 选中当前函数体
vab 选中当前块
vib 选中当前块中内容
vai 选中当前函数调用语句
vii 选中当前函数调用语句的参数列表
vap 选中当前参数(包括逗号)
vip 选中当前参数(不包括逗号)
vin 选中当前数字
vat 选中当前注释块
ALT+shift+左右箭头 跳转
pendulum:
joint_state_controller:
publish_rate: 100
type: joint_state_controller/JointStateController
x_controller:
joint: base_to_plat
type: effort_controllers/JointEffortController
其中joint_state_controller和x_controller是什么意思 这个文件的作用是什么
joint_state_controller/JointStateController 是一个标准的控制器类型,用于处理关节状态的更新。joint_state_controller 是用于发布所有关节状态信息的控制器。它会收集机器人的所有关节(如位置、速度和加速度)的状态,并将这些信息发布到 ROS 主题上,通常是 /joint_states 主题。base_to_plat 的关节的努力(力或扭矩)。通常用于执行某种运动控制任务,比如驱动一个关节以实现预期的动态行为。effort_controllers/JointEffortController 是一个控制器类型,专注于控制关节施加的力或扭矩。这个文件主要是用于配置 ROS 控制器管理器,定义机器人各个关节的控制方式及其参数。通过这个配置,您可以在启动时自动加载和初始化这些控制器,使得机器人能够实时进行关节状态的监测和控制。
joint_state_controller 负责关节状态的信息发布。x_controller 则用于具体关节的力量控制。##并发
###0.时间 time

###1.线程 thread

join汇合加入,把子线程加到主线程里,这样主线程只有在子线程结束后才会退出

当想要对线程进行封装时,会发现线程会随着封装函数执行过去而被销毁(因为thread的析构函数):

使用detach(),还是不行(因为没用join,主线程不会等子线程):
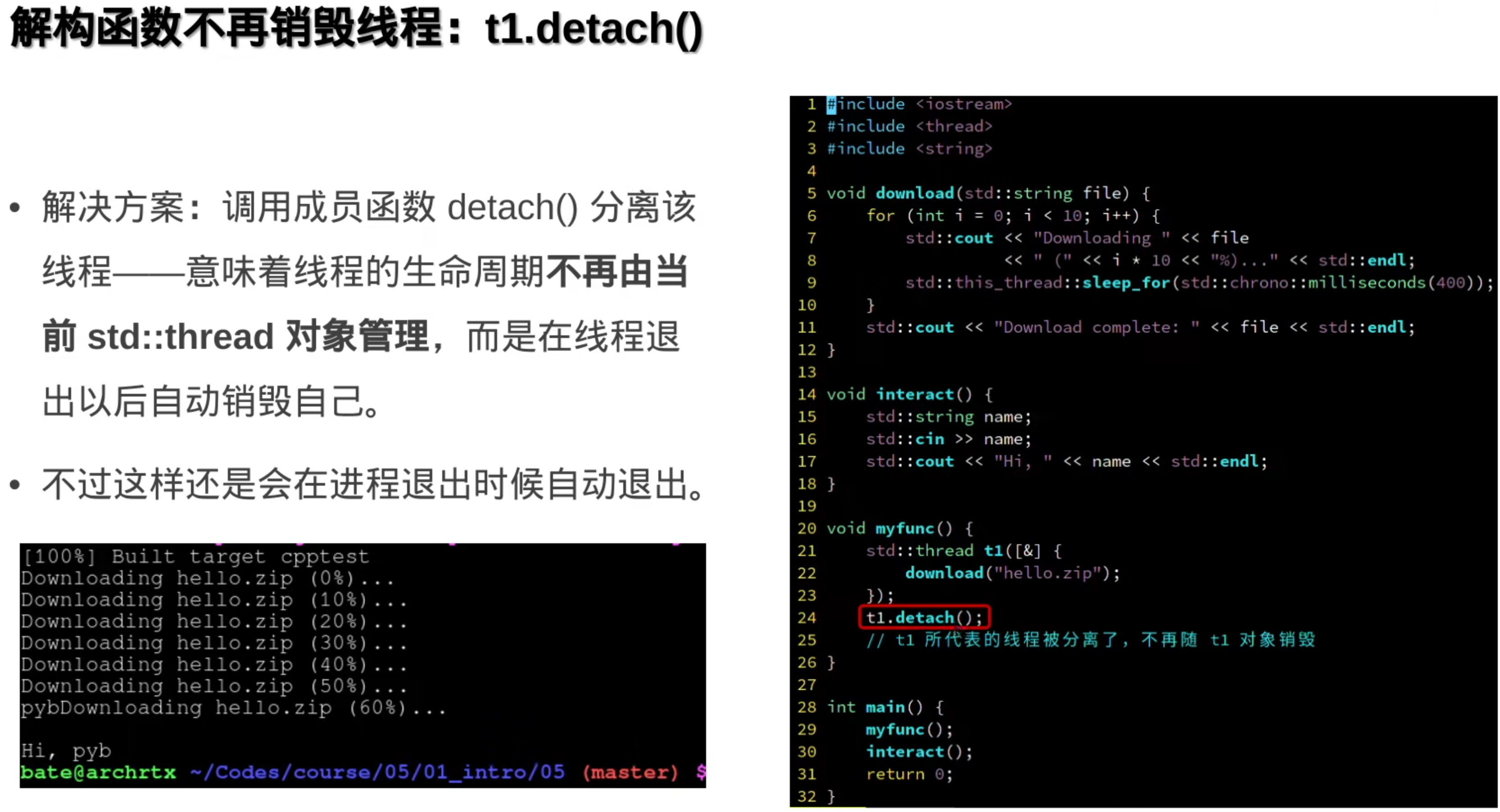
全局变量,生命周期会大于封装函数,join,等待子线程: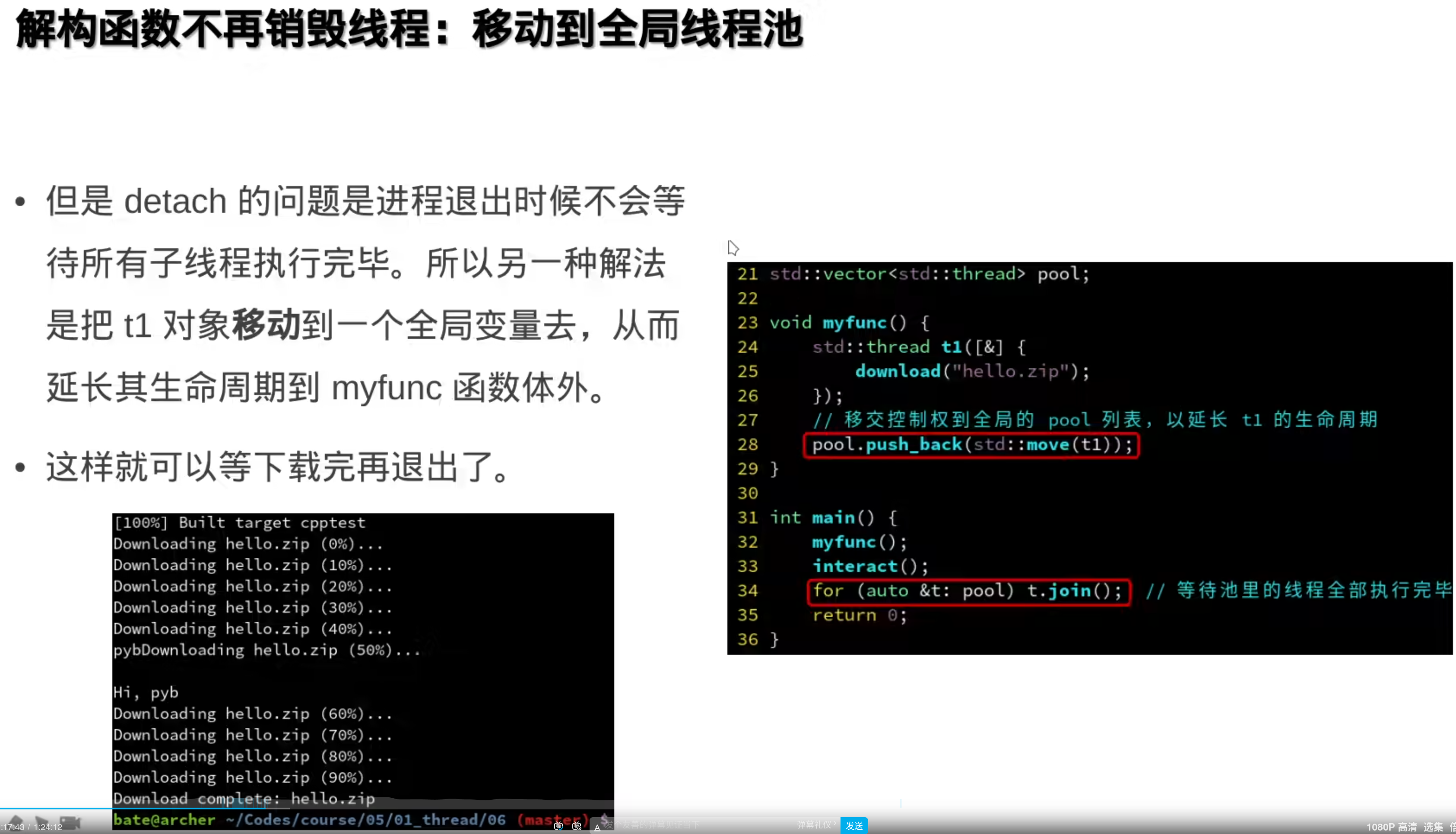
利用析构函数简化: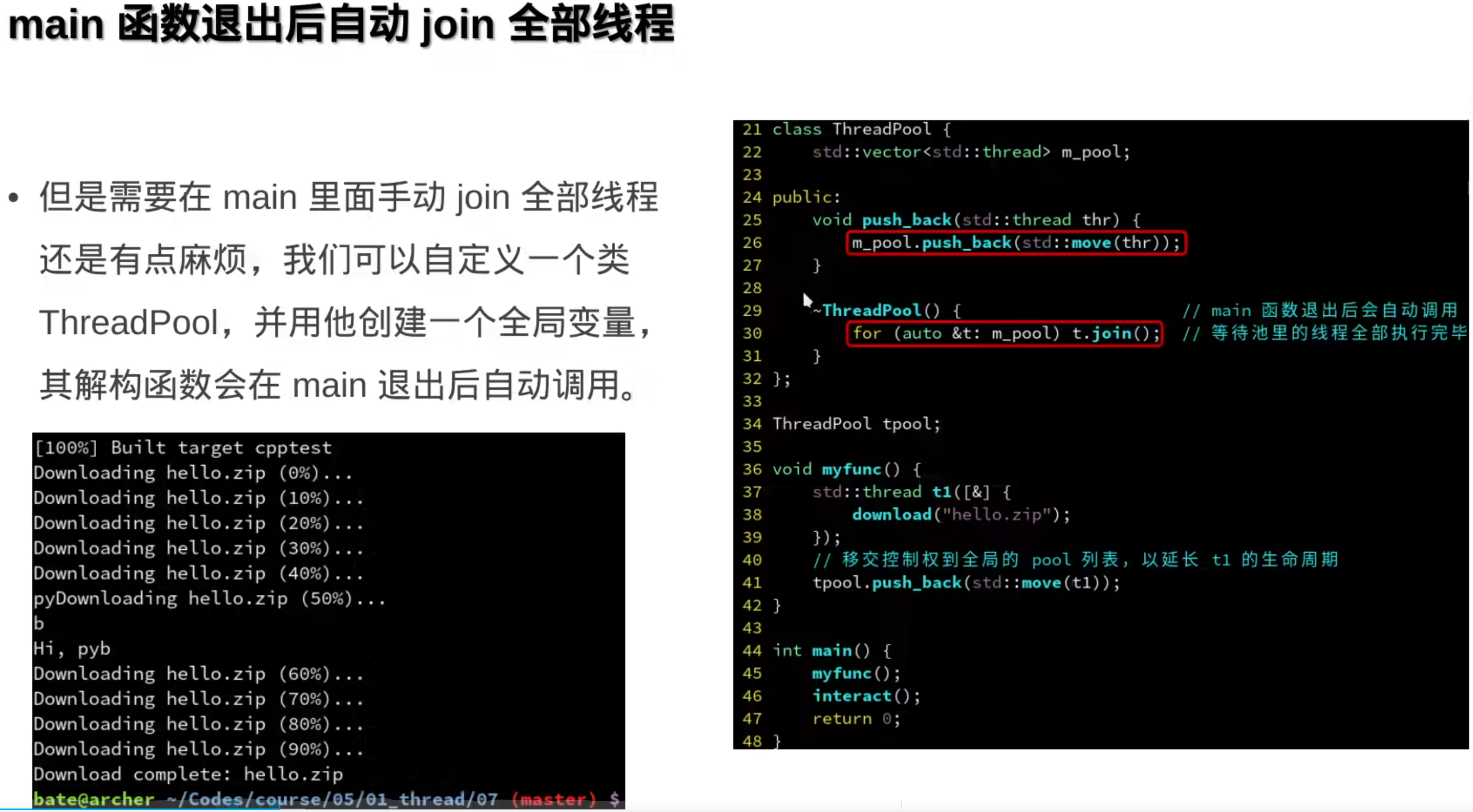
再简化,标准函数帮你把析构函数写了:

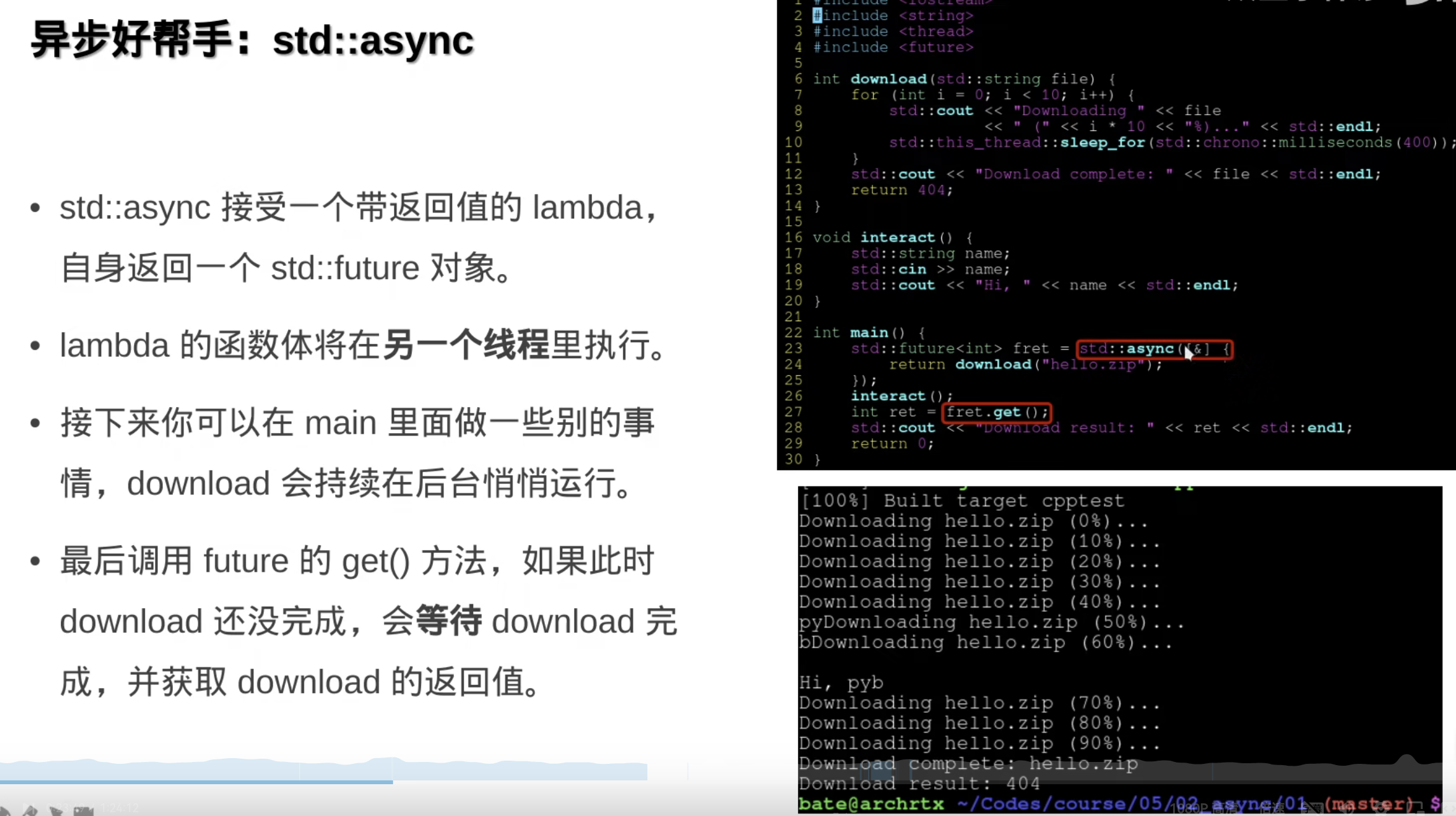
异步相当于thread的帮手函数,专注于任务本身而不是底层的线程管理,不用那么底层了,使用简单了,但是能力也就下降了。
std::async 和 std::thread 都是 C++11 引入的用于处理并发和多线程编程的工具,但它们在设计目的、使用方式和抽象级别上存在一些关键的关系与区别。以下是它们之间的详细比较:
std::async 中使用 std::thread,或者在创建线程时使用 std::async 来管理结果。| 特性 | std::thread |
std::async |
|---|---|---|
| 抽象级别 | 更低级别的线程管理 | 更高层次的异步任务管理 |
| 线程控制 | 开发者需要手动管理线程的生命周期(启动、加入、分离) | 自动管理线程的生命周期,返回 std::future |
| 执行策略 | 一般立即启动新线程 | 可选择立即执行或延迟执行(std::launch::async 或 std::launch::deferred) |
| 结果处理 | 返回值需要通过共享数据或其他同步机制来获取 | 通过 std::future 对象直接获取结果 |
| 异常处理 | 异常不会传播到主线程,需要手动管理 | 异常会被捕获并在调用 future.get() 时重新抛出 |
| 适用场景 | 需要细致控制线程行为的场景,如实时系统、服务器等 | 简单的异步任务、并行计算、提高程序响应性 |
std::thread 的示例:#include <iostream>
#include <thread>
void task() {
std::cout << "Task is running in a separate thread.\n";
}
int main() {
std::thread t(task);
t.join(); // 等待线程完成
return 0;
}
std::async 的示例:#include <iostream>
#include <future>
int task() {
return 42; // 返回结果
}
int main() {
std::future<int> result = std::async(task);
std::cout << "Result from async task: " << result.get() << '\n'; // 获取结果
return 0;
}
std::thread**:当你需要更细粒度的线程控制,或者需要实现复杂的线程交互时。std::async**:当你希望简化异步任务的管理,并专注于任务本身而不是底层的线程管理时。根据具体的需求和场景,开发者可以灵活选择这两者中的一种或结合使用。

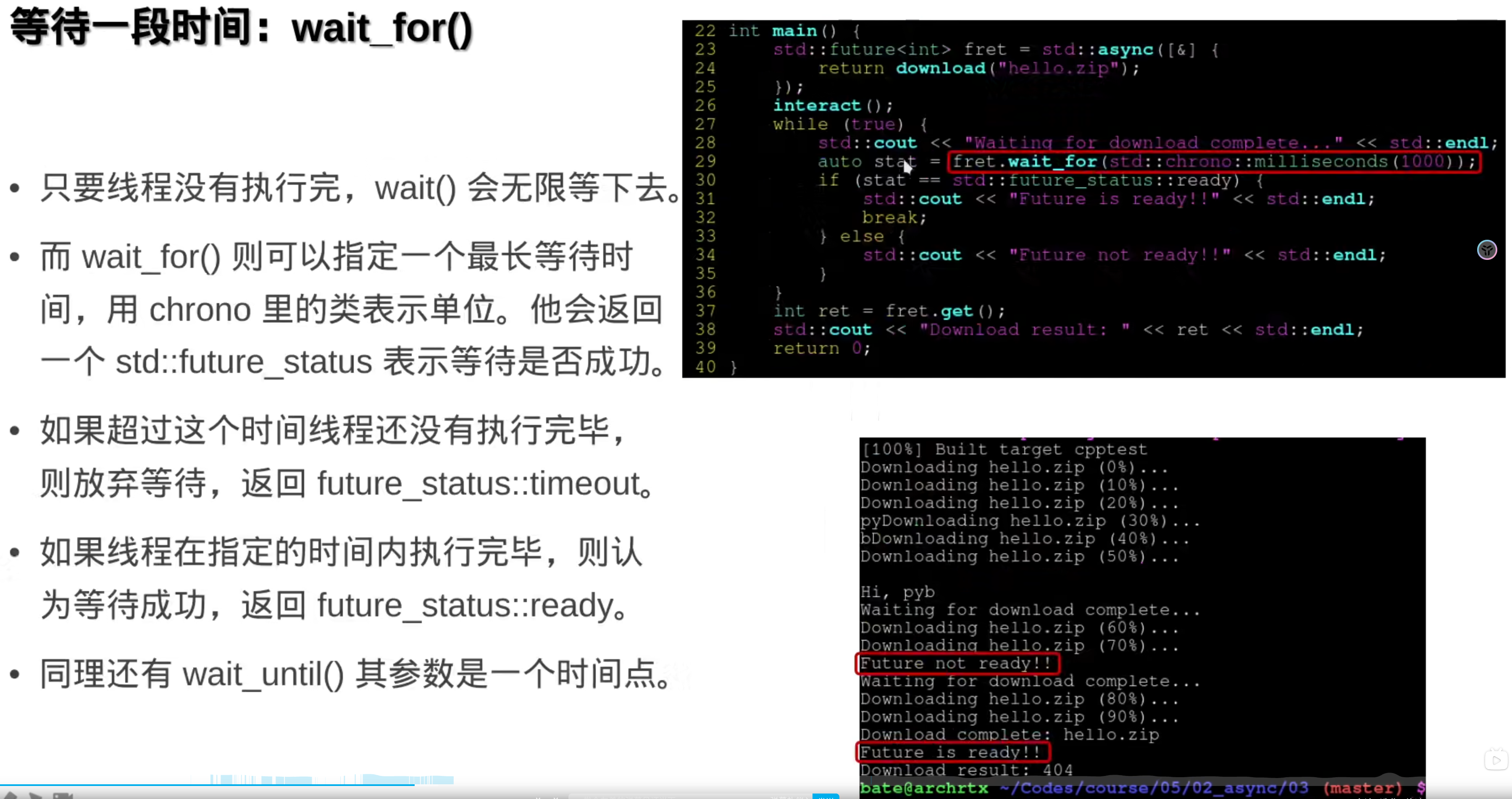
std::async相当于在后台开一个线程偷偷执行,如果不想用线程的话,可以用假线程:

std::async的底层实现:(应该用不到吧)


std::lock_guard grd(mtx); // 创建 lock_guard 对象 grd,锁定 mtx
这个有个弊端:不能提前unlock,可以用std::unique_lock:

如果你即想使用unique_lock的自动解锁,又想手动lock:

这个是已经上锁了,又想使用自动解锁:
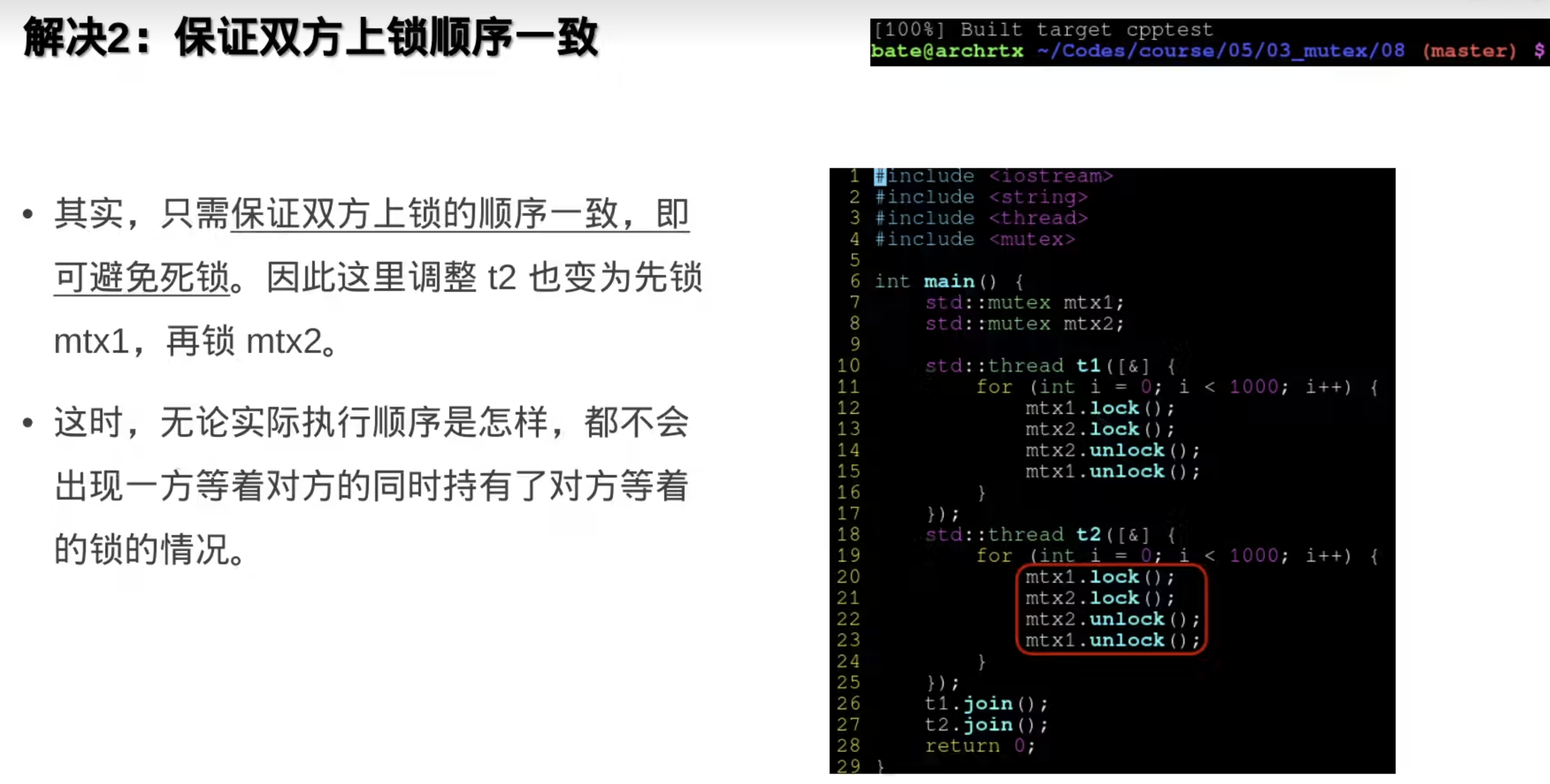
问题一:

不要同时锁两个
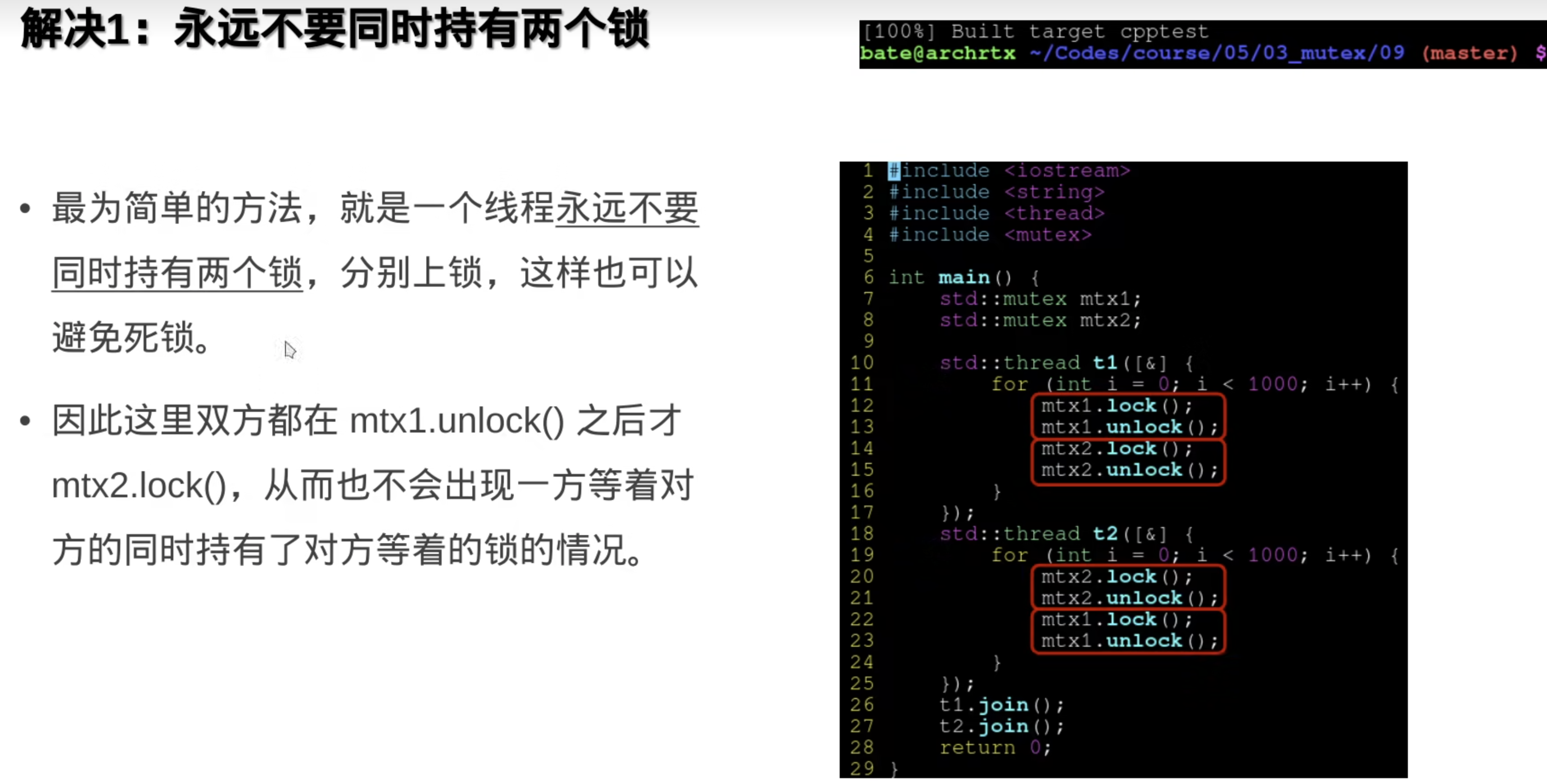
保证线程里上锁的顺序一样
使用标准库里的std::lock

同样,为了避免忘记解锁,有了一个RALL版本的std::lock
问题二:

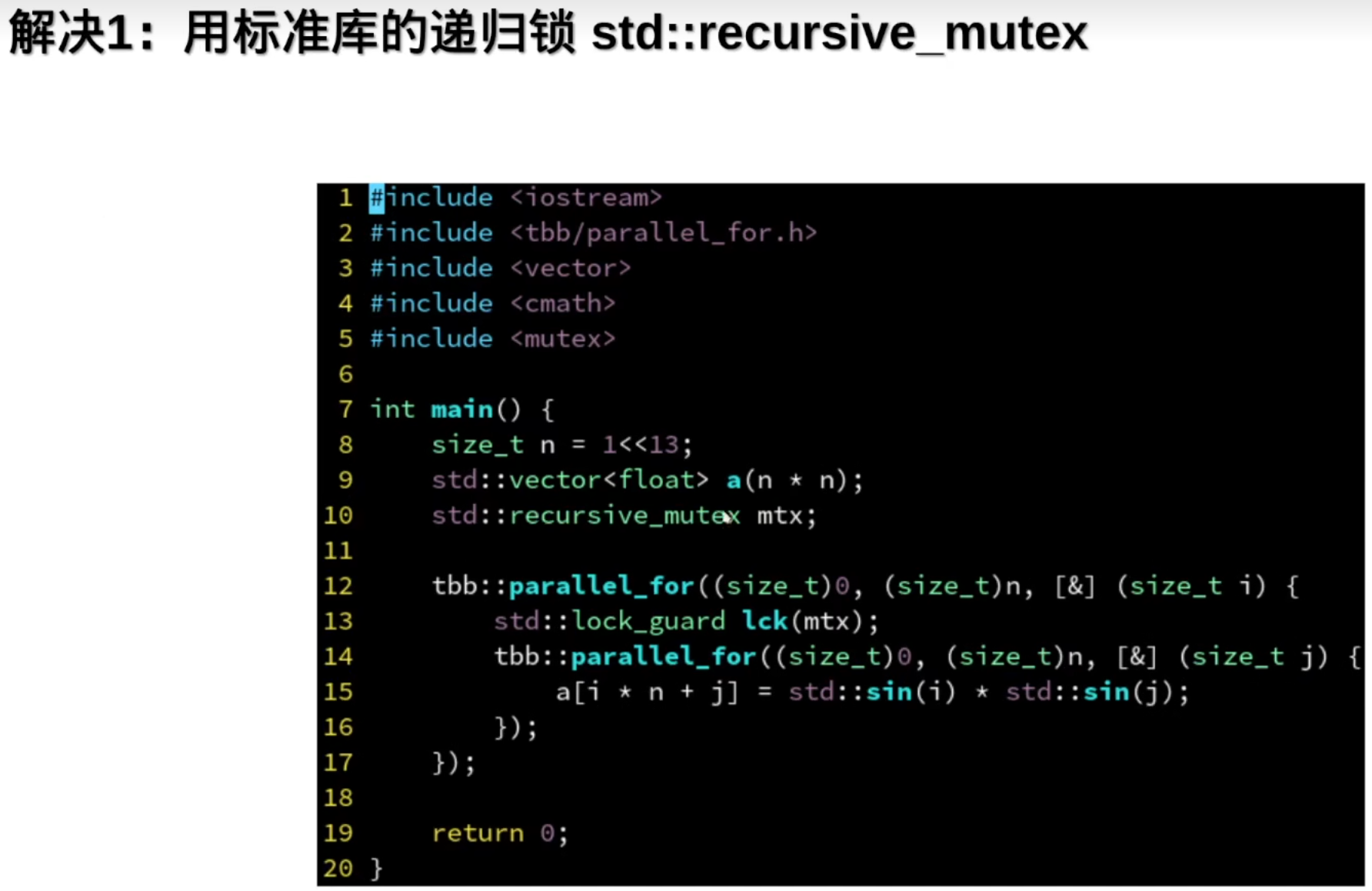
std::recursive_mutex


封装一下:
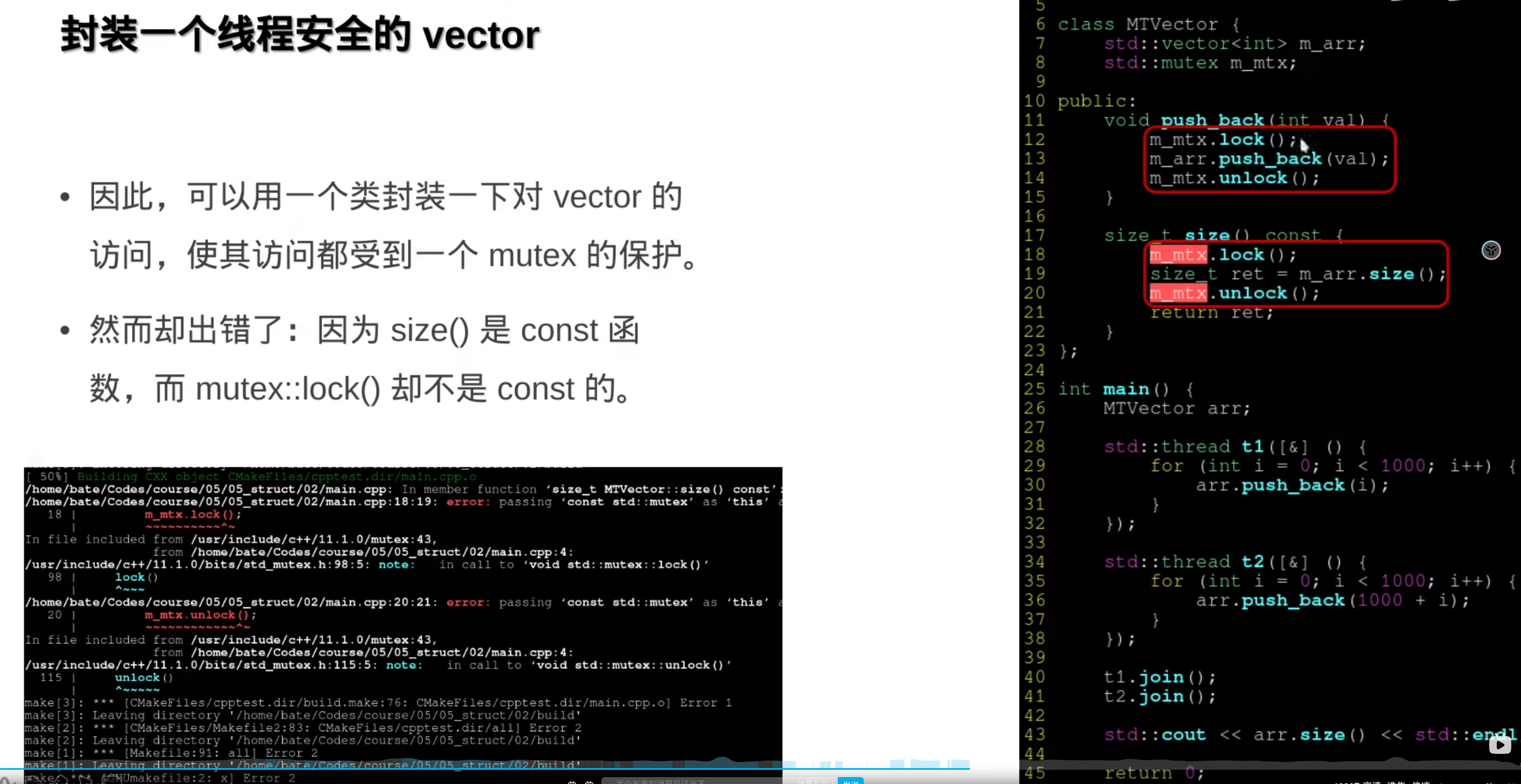
因为mutex::lock()不是const的 ,那么使用mutable修饰一下:

####读写锁:

std::shared_mutex
lock()的RAII是std::unique_lock
lock_shared()的RAII是std::shared_lock


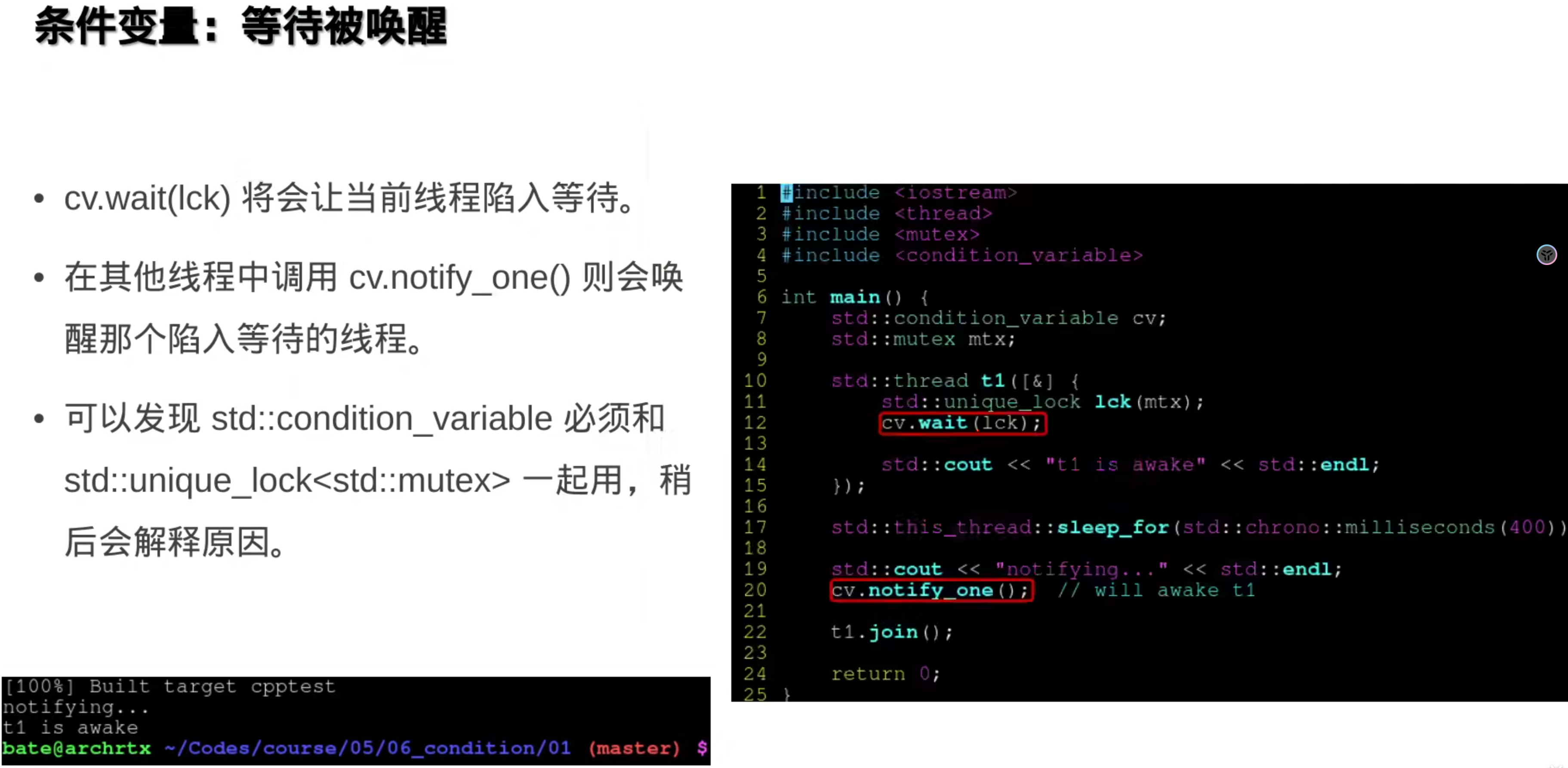


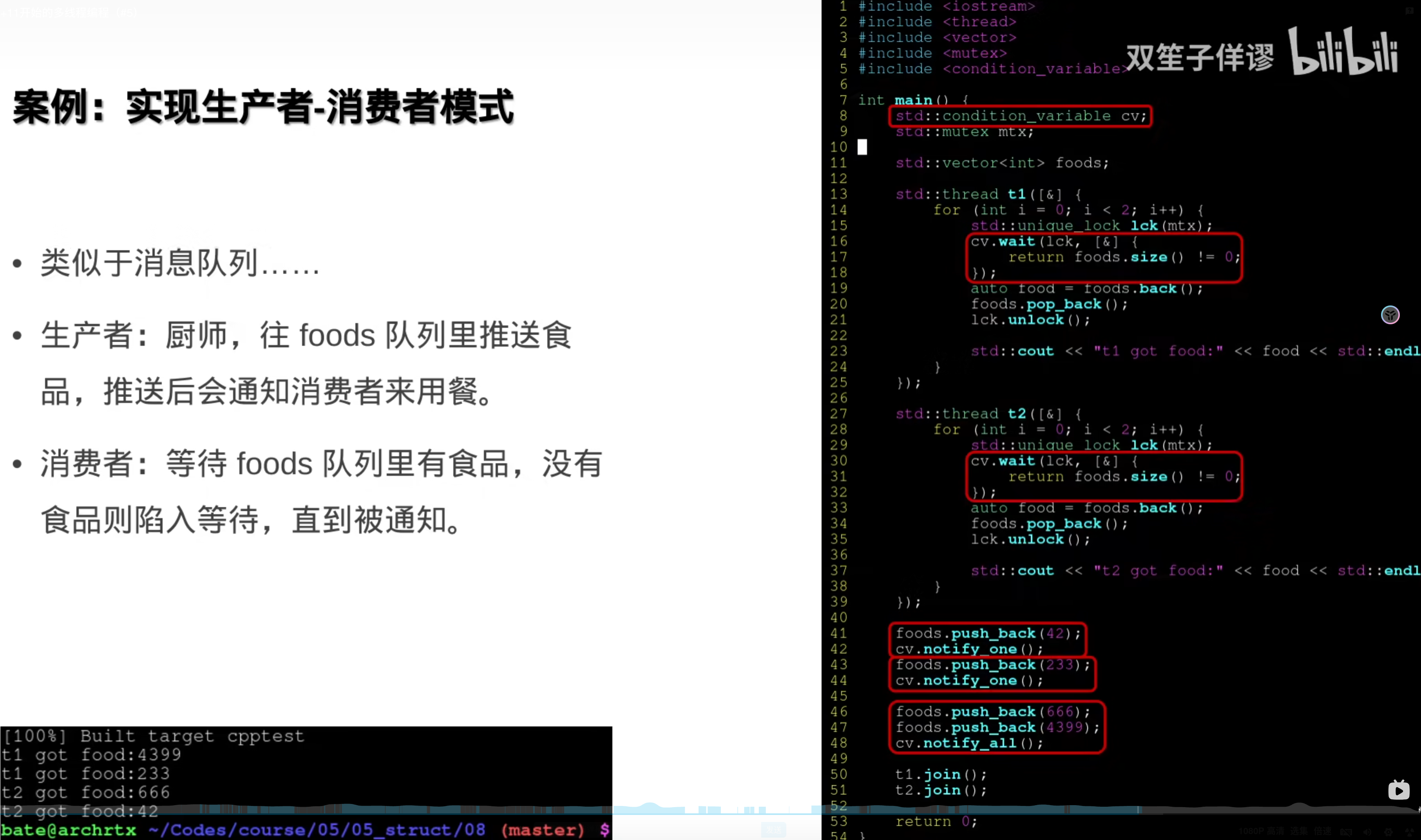


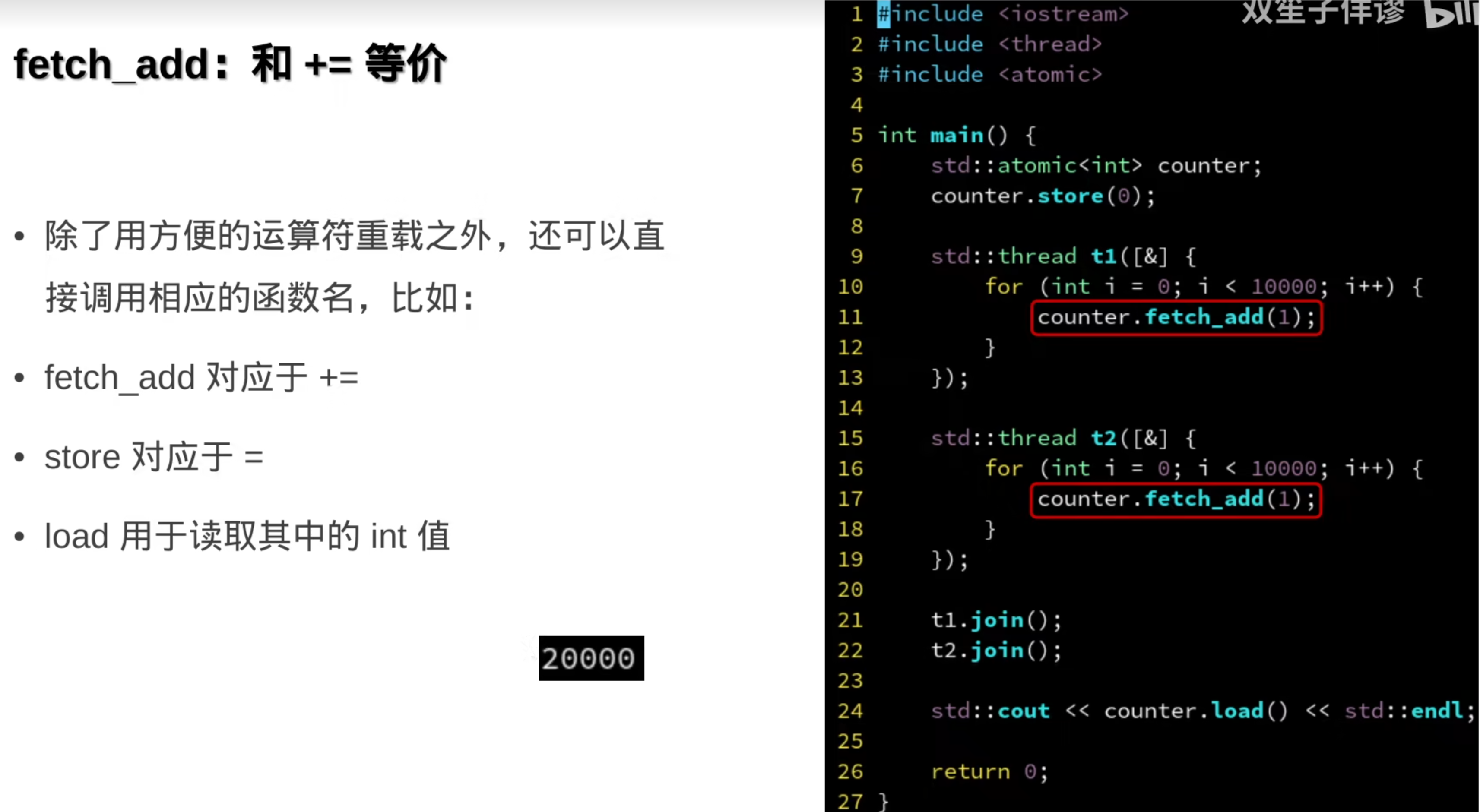
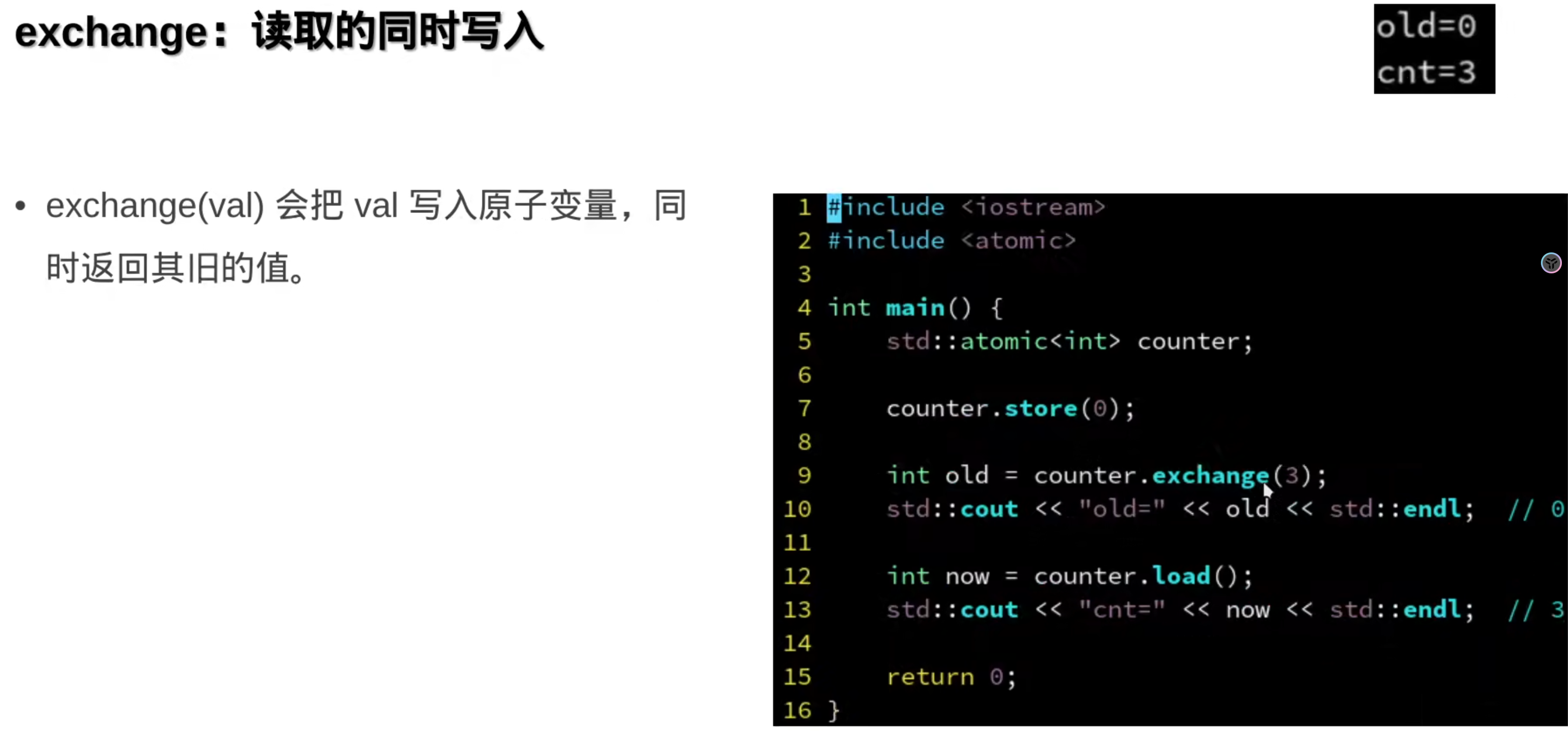
###7.原子操作(硬件层面)
前面的都是操作系统层面的
硬件解释:


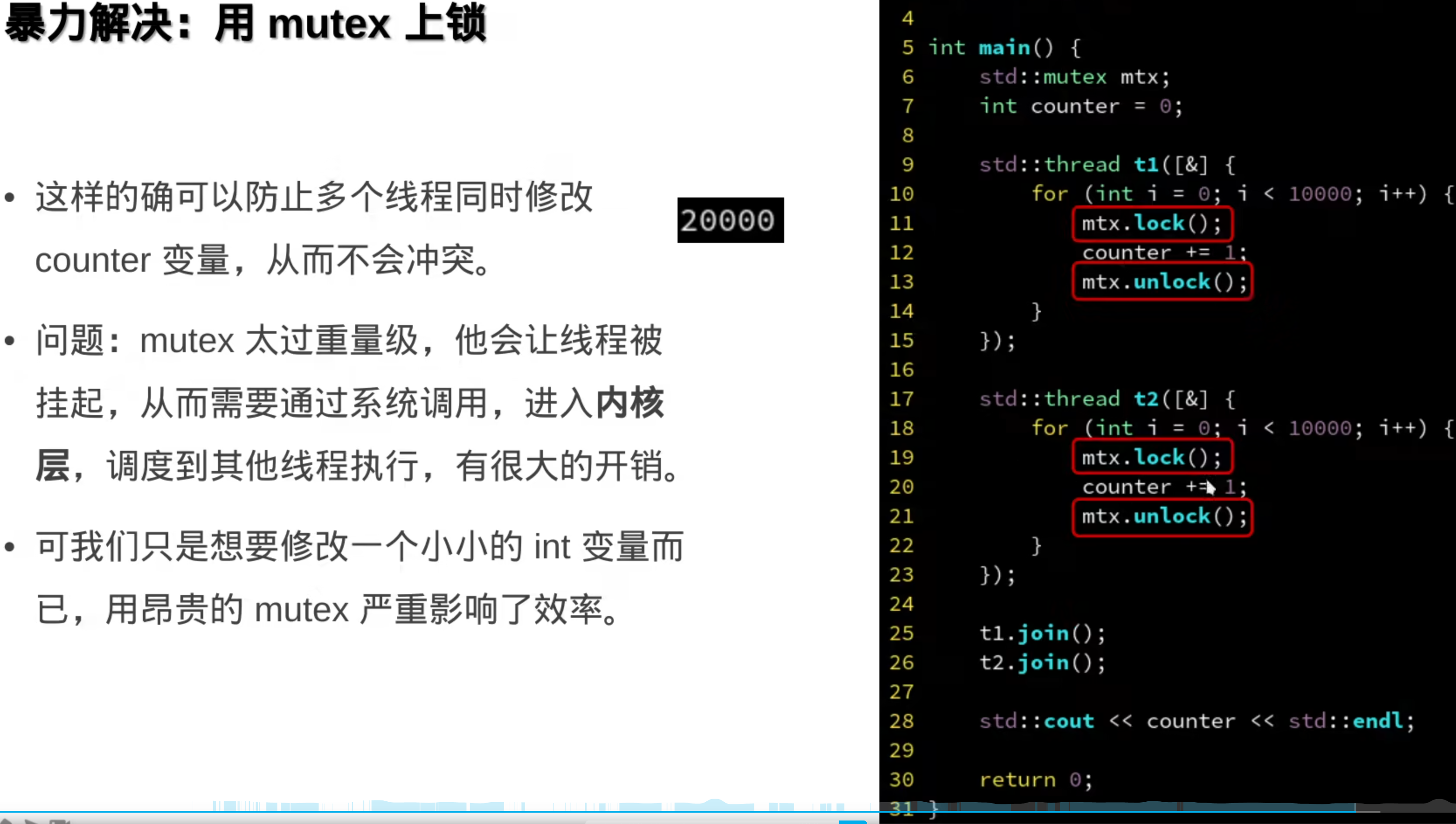
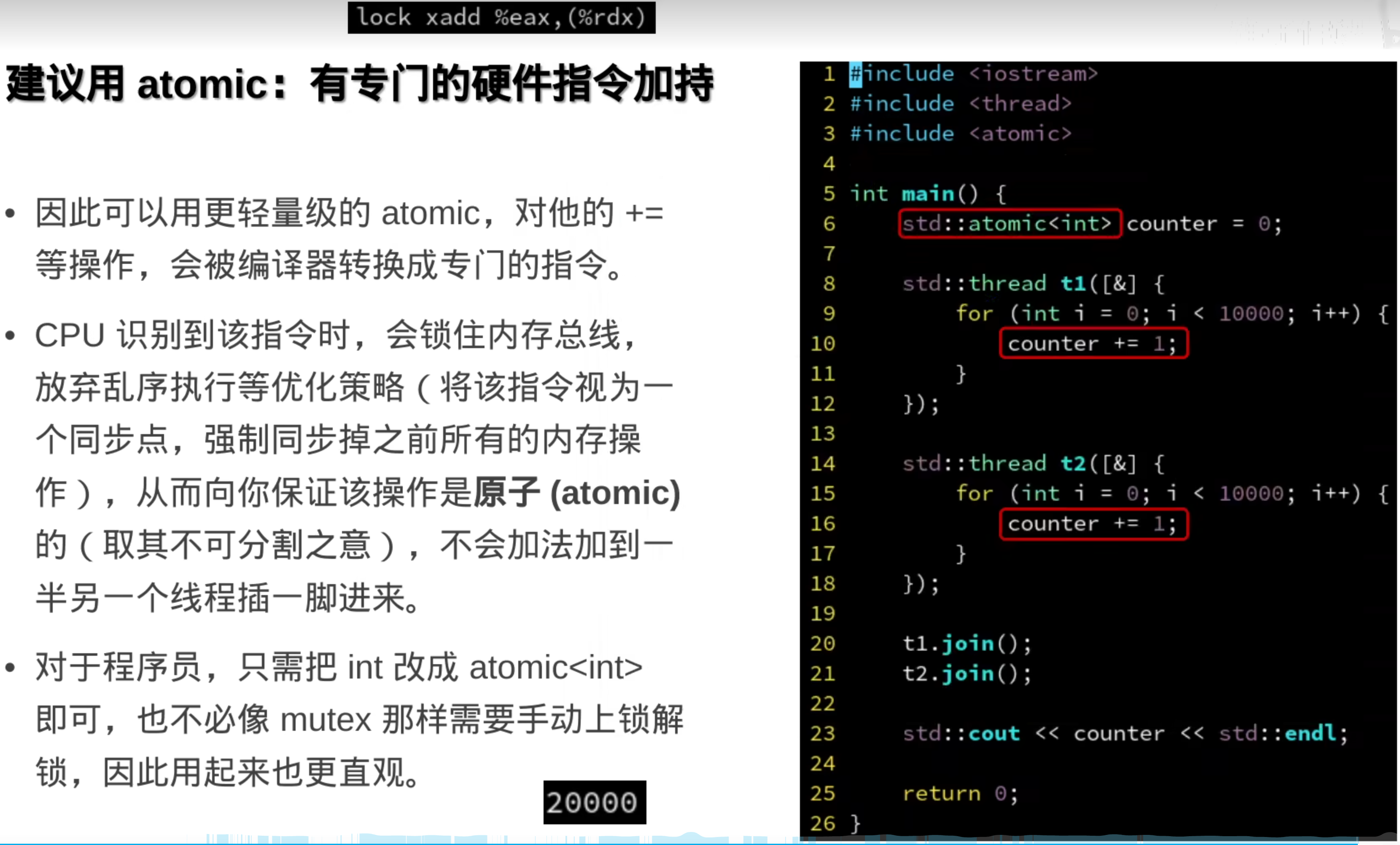
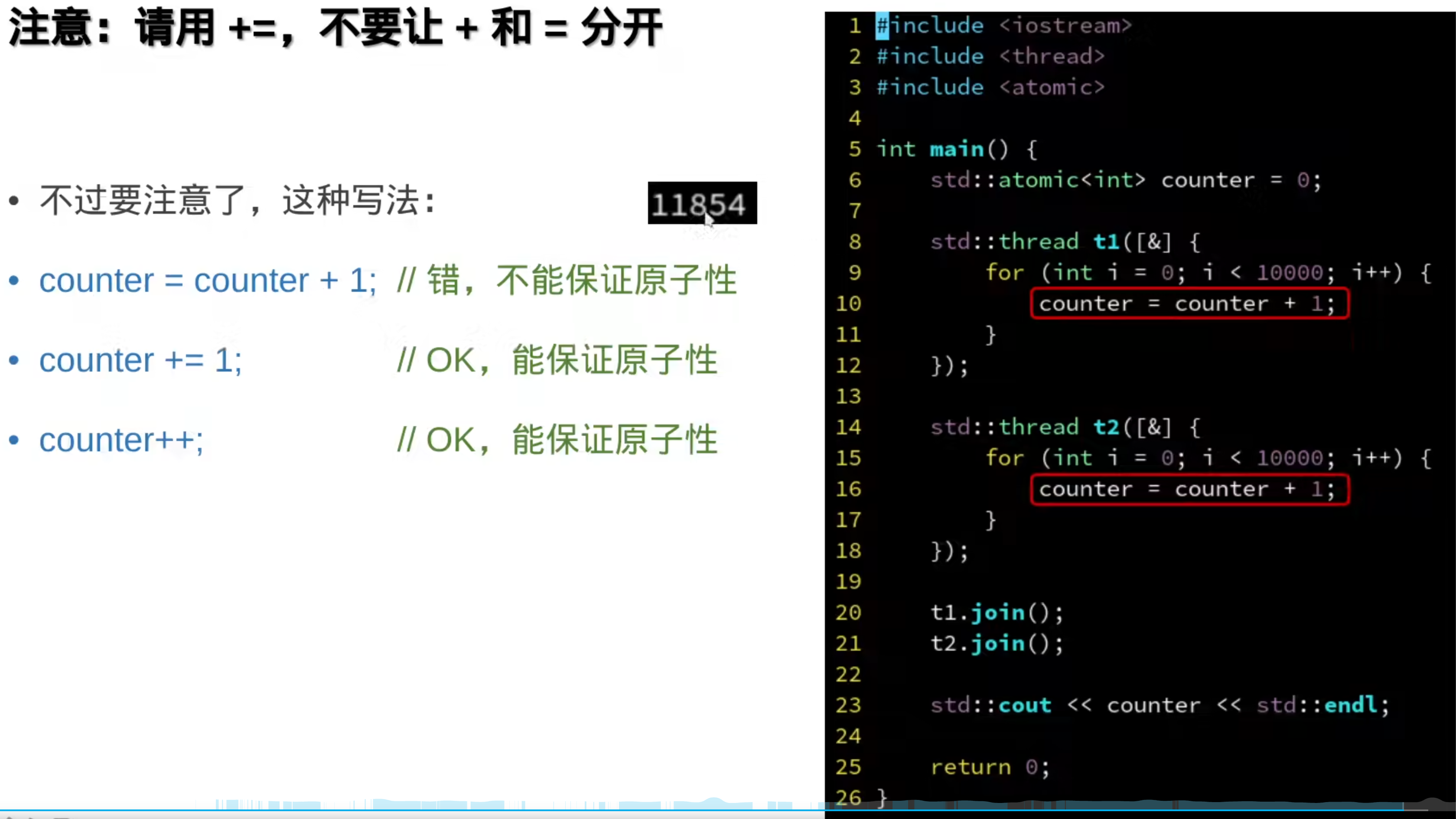
原子变量:


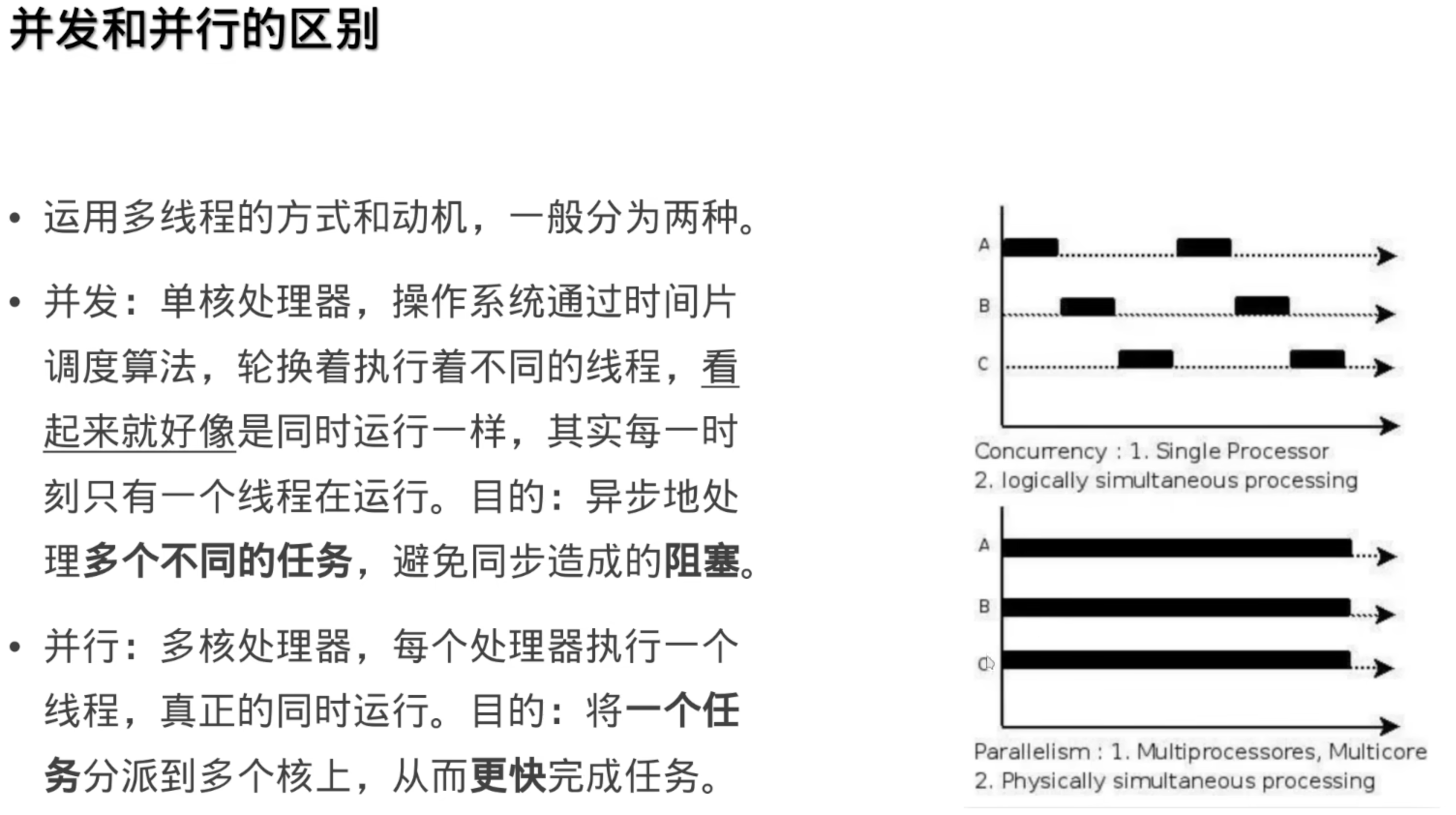
###——TBB开启的并行编程之旅(Intel TBB并行编程框架)
###0.从并发到并行


不需要手动创建线程池:

std::thread是操作系统意义上的线程,TBB的一个任务不一定代表一个线程,把任务分配到线程上去, TBB可视为一个高效调度器
ubuntu20.04蓝牙耳机连上了,但是声音还是输出在内置扬声器上,使用 pactl load-module module-bluetooth-discover 时遇到“模块初始化失败”的错误.
检查 Bluetooth 服务:
确保 Bluetooth 服务正在运行。可以使用以下命令启动服务:
sudo systemctl start bluetooth
安装必要的包:
确保已安装 PulseAudio 和 Bluetooth 支持。运行以下命令安装相关组件:
sudo apt install pulseaudio pulseaudio-module-bluetooth pavucontrol
重启 PulseAudio:
有时重启 PulseAudio 可以解决问题。可以使用以下命令:
pulseaudio -k
pulseaudio --start
当然可以。根据你提供的代码,系统的状态空间方程可以表示为以下形式:
状态方程:
$$[
\begin{align*}
\dot{x}_1 &= x_2 \
\dot{x}_2 &= \frac{-b \cdot (I + m \cdot l^2)}{P} \cdot x_2 + \frac{m \cdot m \cdot g \cdot l^2}{P} \cdot x_3 \
\dot{x}_3 &= x_4 \
\dot{x}_4 &= \frac{-b \cdot m \cdot l}{P} \cdot x_2 + \frac{m \cdot g \cdot l \cdot (M + m)}{P} \cdot x_3 + \frac{1}{P} \cdot u
\end{align*}
]$$
其中,( x_1 ) 和 ( x_2 ) 可能表示倒立摆的位移和速度,而 ( x_3 ) 和 ( x_4 ) 可能表示摆角和角速度。控制输入 ( u ) 是作用在倒立摆上的力。
输入方程:
$$[
u = 0 \cdot x_1 + \frac{(I + m \cdot l^2)}{P} \cdot x_2 + 0 \cdot x_3 + \frac{m \cdot l}{P} \cdot x_4
]$$
但实际上,控制输入 ( u ) 是由控制器决定的,所以输入方程应该表示控制律,而不是状态变量直接映射到控制输入。
根据你的代码,状态空间方程的矩阵形式是:
$$[
\begin{align*}
\dot{\mathbf{x}} &= \mathbf{A} \mathbf{x} + \mathbf{B} u \
y &= \mathbf{C} \mathbf{x} + \mathbf{D} u
\end{align*}
]$$
其中,(\mathbf{x}) 是状态向量,(u) 是控制输入,(y) 是系统输出。在你的代码中,并没有明确给出输出矩阵 (\mathbf{C}) 和直接馈通矩阵 (\mathbf{D}),所以我们假设它们是:
$$[
\mathbf{C} = \begin{bmatrix}
1 & 0 & 0 & 0 \
0 & 1 & 0 & 0
\end{bmatrix}, \quad
\mathbf{D} = \begin{bmatrix}
0 \
0
\end{bmatrix}
]$$
这意味着系统的输出是状态向量 (\mathbf{x}) 的前两个元素。
因此,状态空间方程的矩阵形式为:
$[
\mathbf{A} = \begin{bmatrix}
0 & 1 & 0 & 0 \
0 & -\frac{b \cdot (I + m \cdot l^2)}{P} & \frac{m \cdot m \cdot g \cdot l^2}{P} & 0 \
0 & 0 & 0 & 1 \
0 & -\frac{b \cdot m \cdot l}{P} & \frac{m \cdot g \cdot l \cdot (M + m)}{P} & 0
\end{bmatrix}
]$
$$[
\mathbf{B} = \begin{bmatrix}
0 \
\frac{(I + m \cdot l^2)}{P} \
0 \
\frac{m \cdot l}{P}
\end{bmatrix}
]$$
请注意,这里的 $(\mathbf{A})$ 和 $(\mathbf{B})$ 矩阵与你代码中定义的矩阵相匹配,但是根据你的系统定义,你可能需要调整 $(\mathbf{C})$ 和 $(\mathbf{D}) $矩阵以反映实际的系统输出。

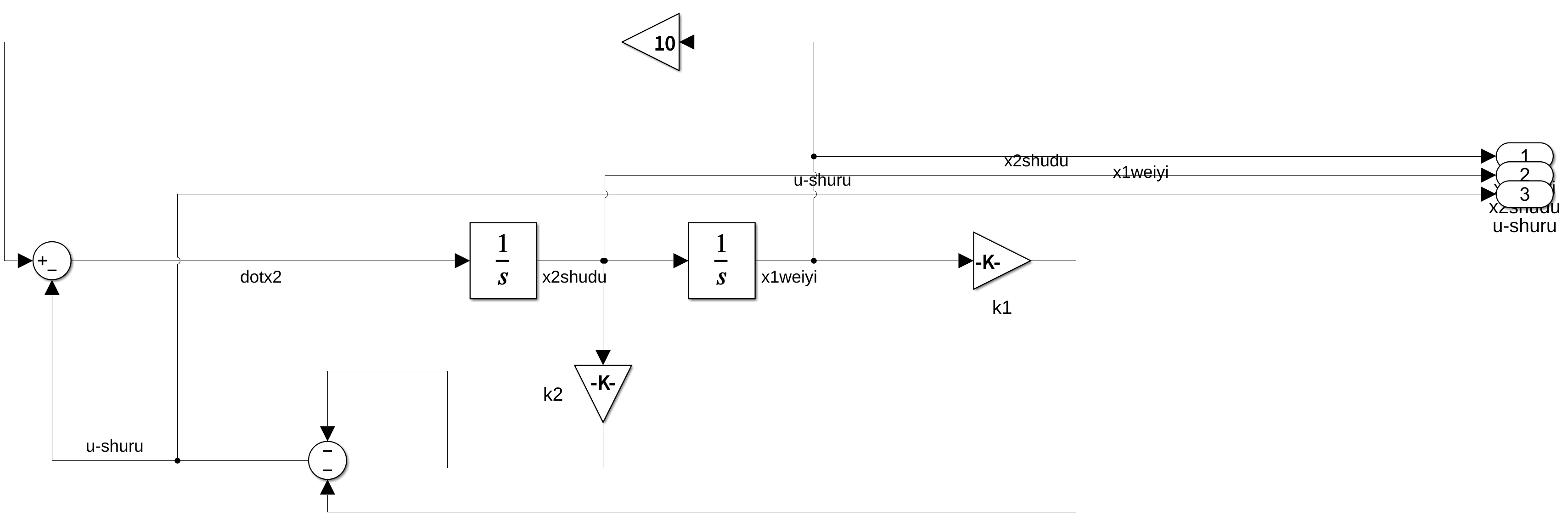
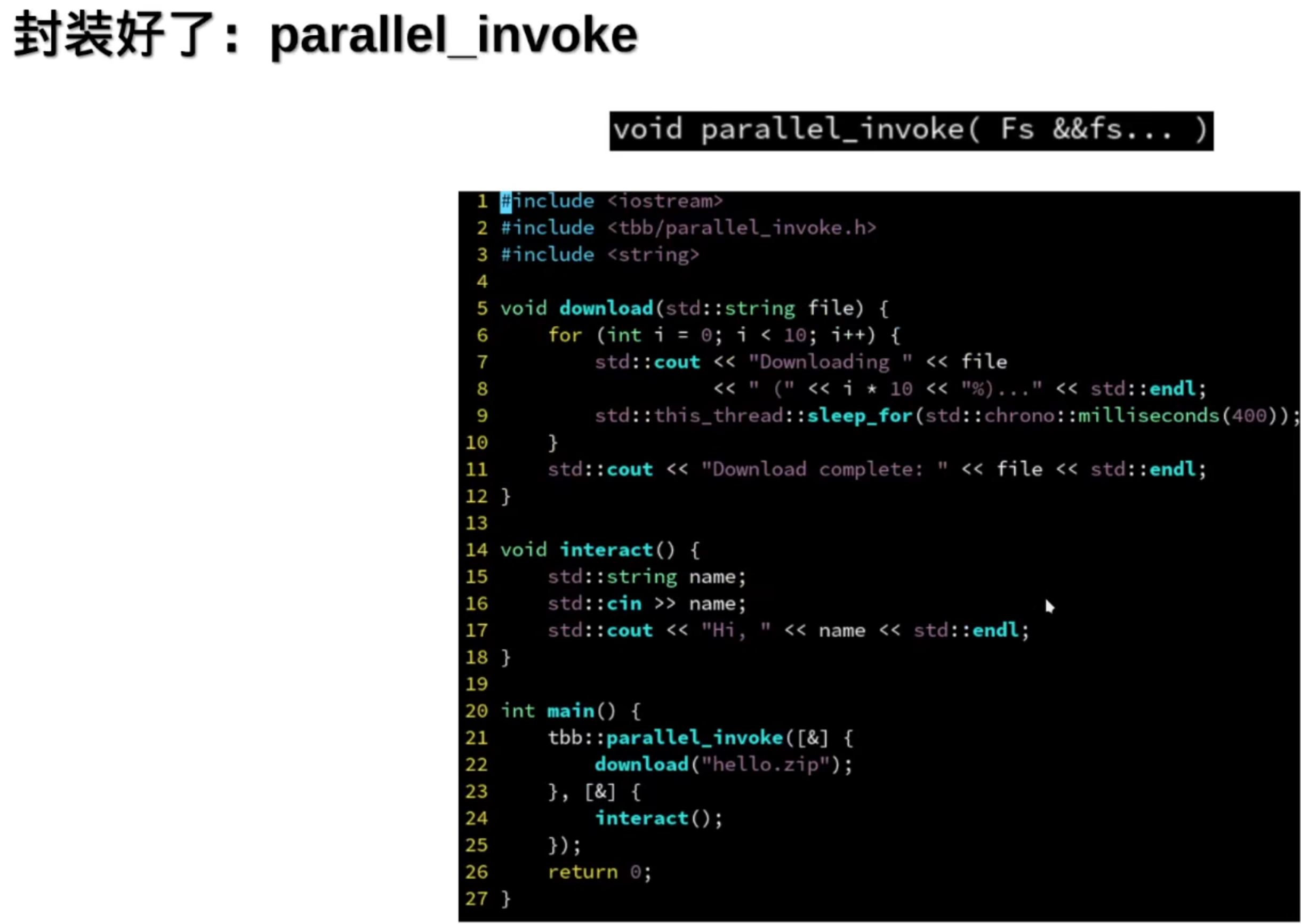
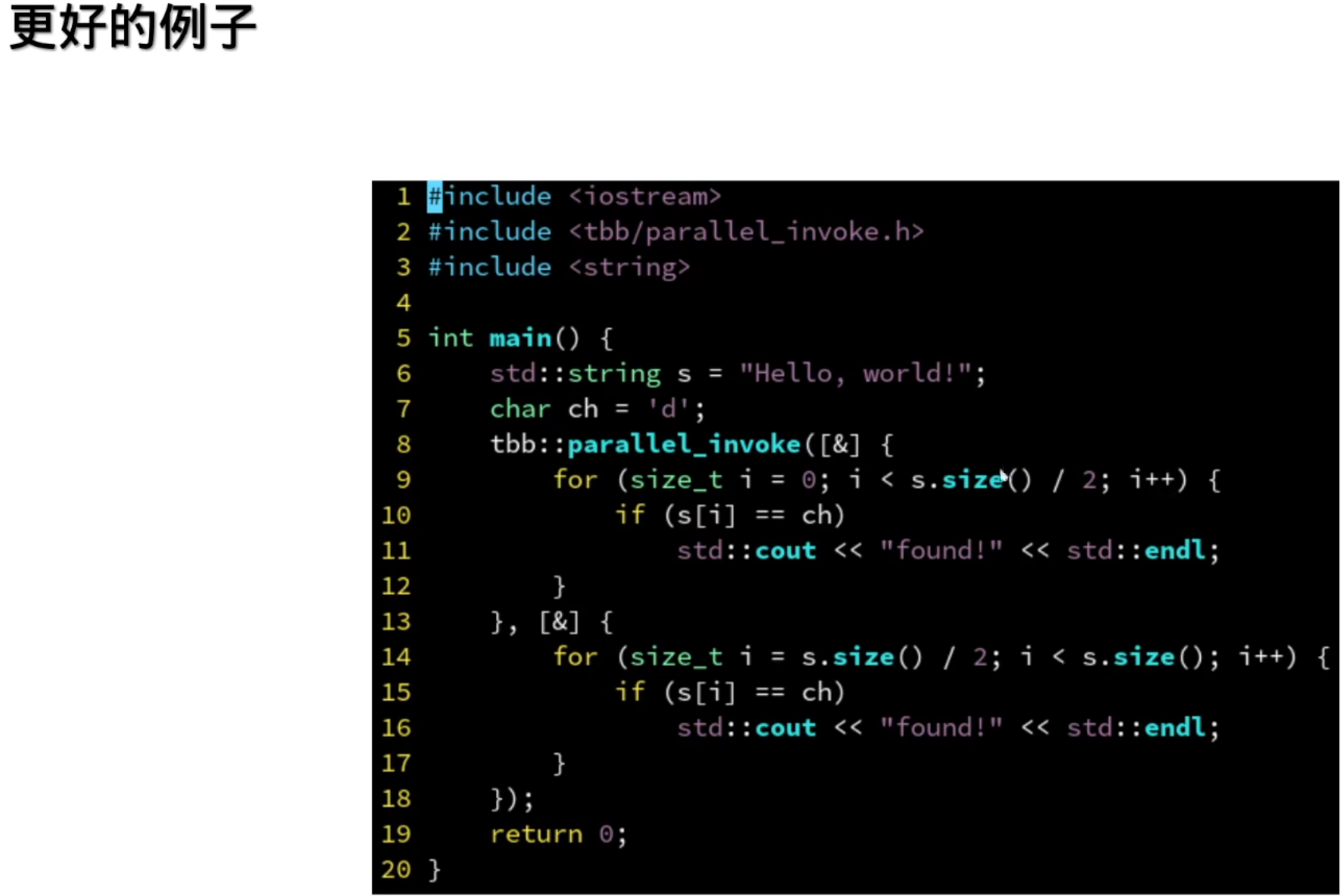
并行的for循环 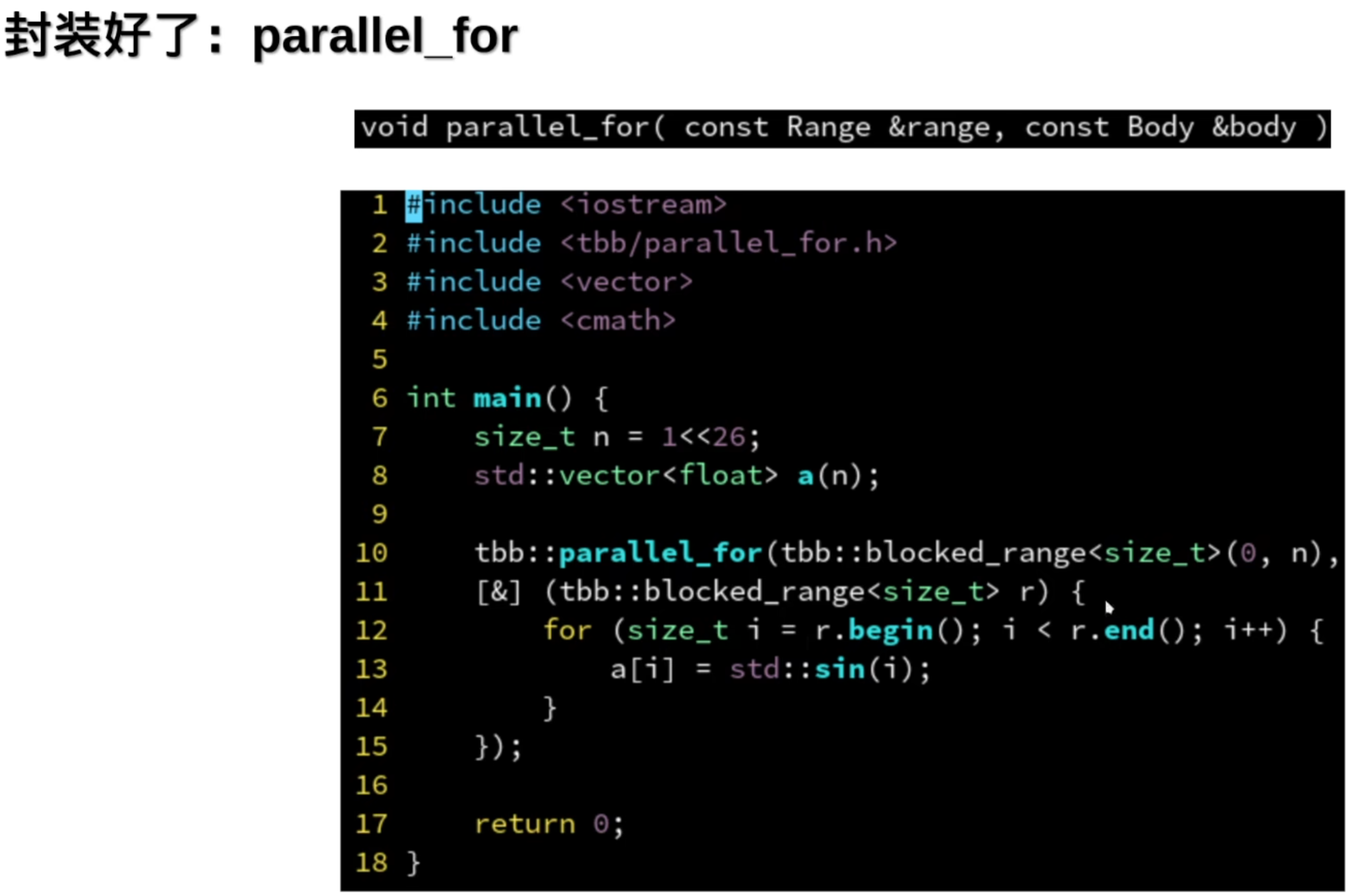
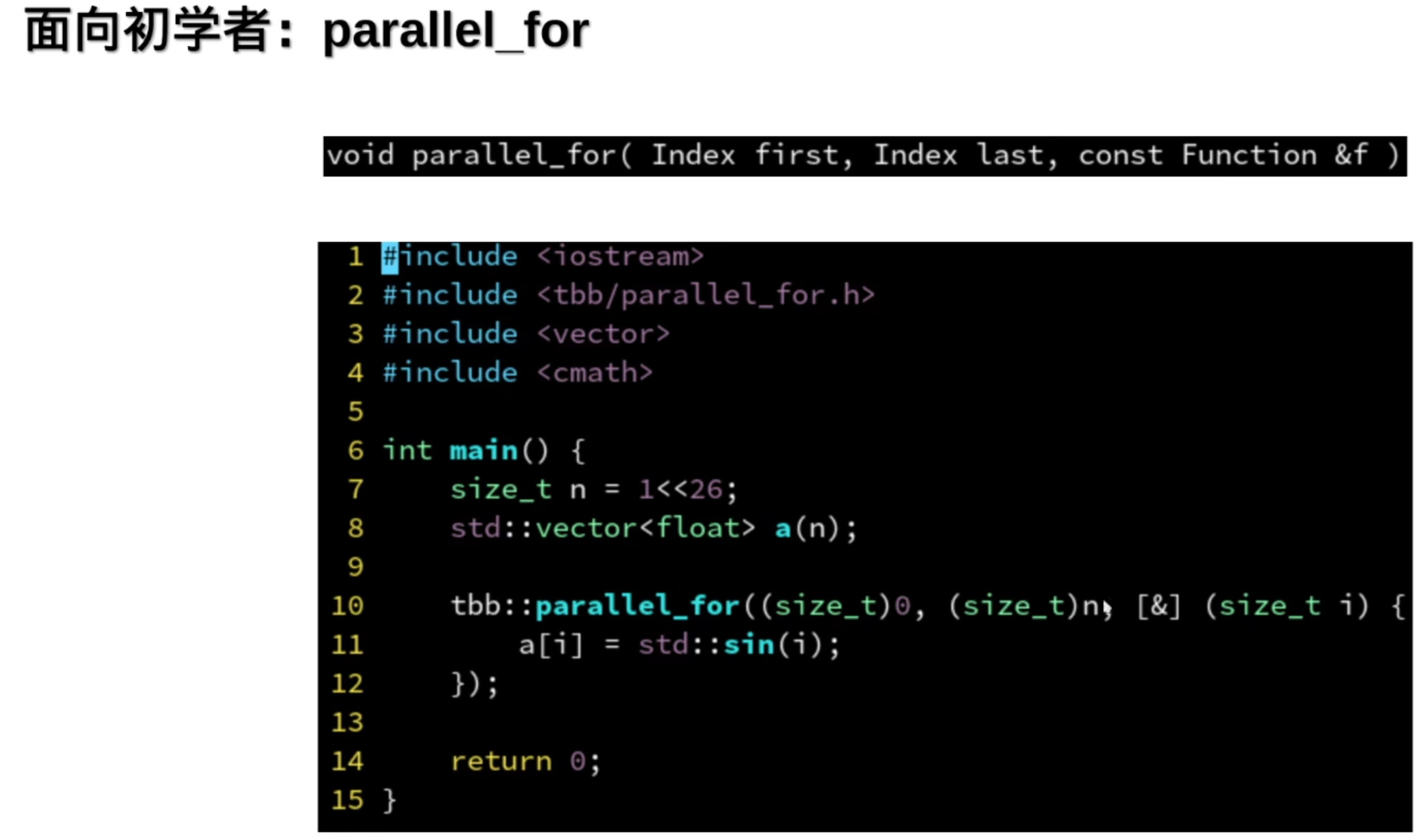
简单,但是有代价,无法被编译器优化了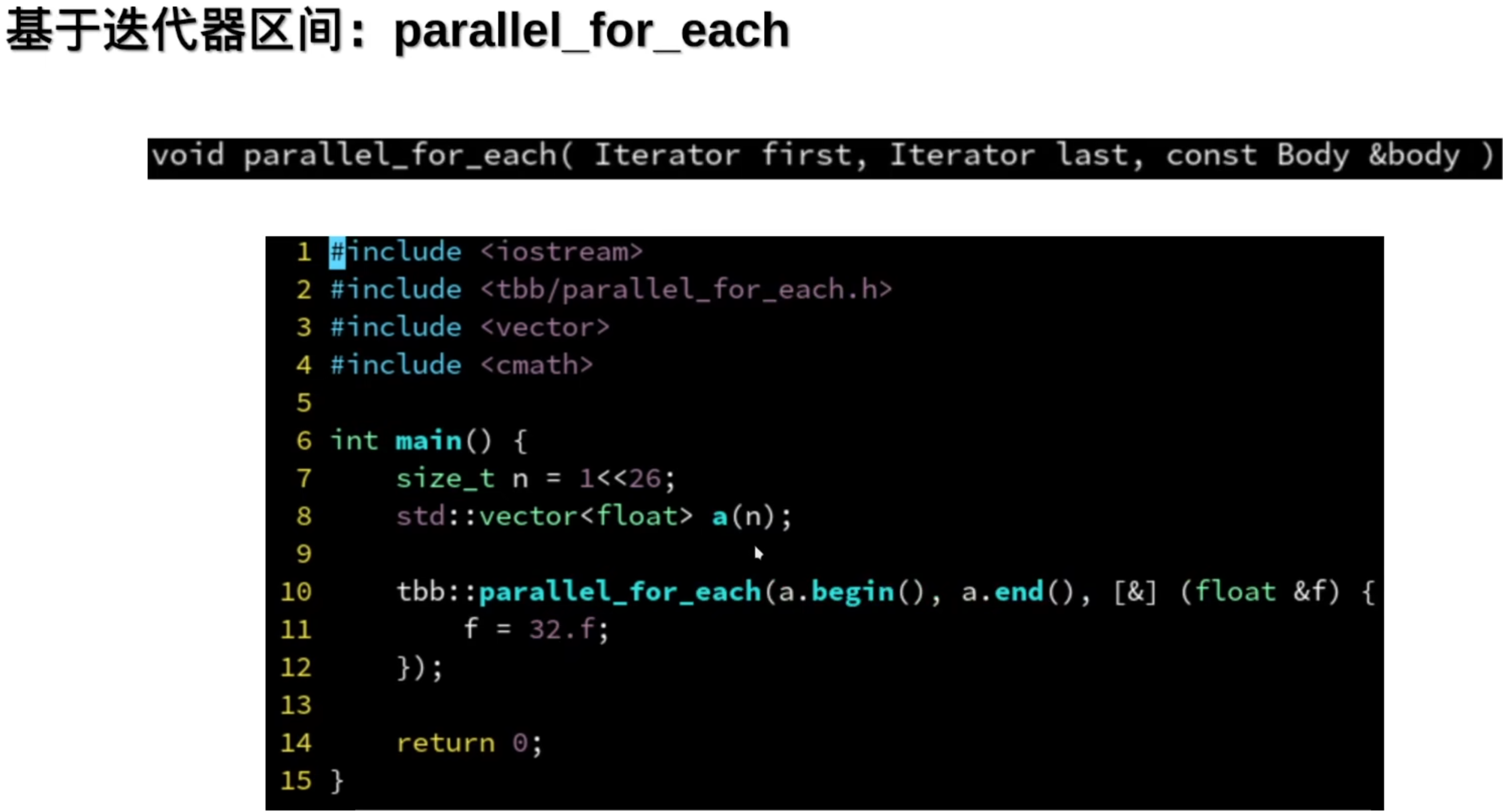
这个是不需要索引的时候可以用
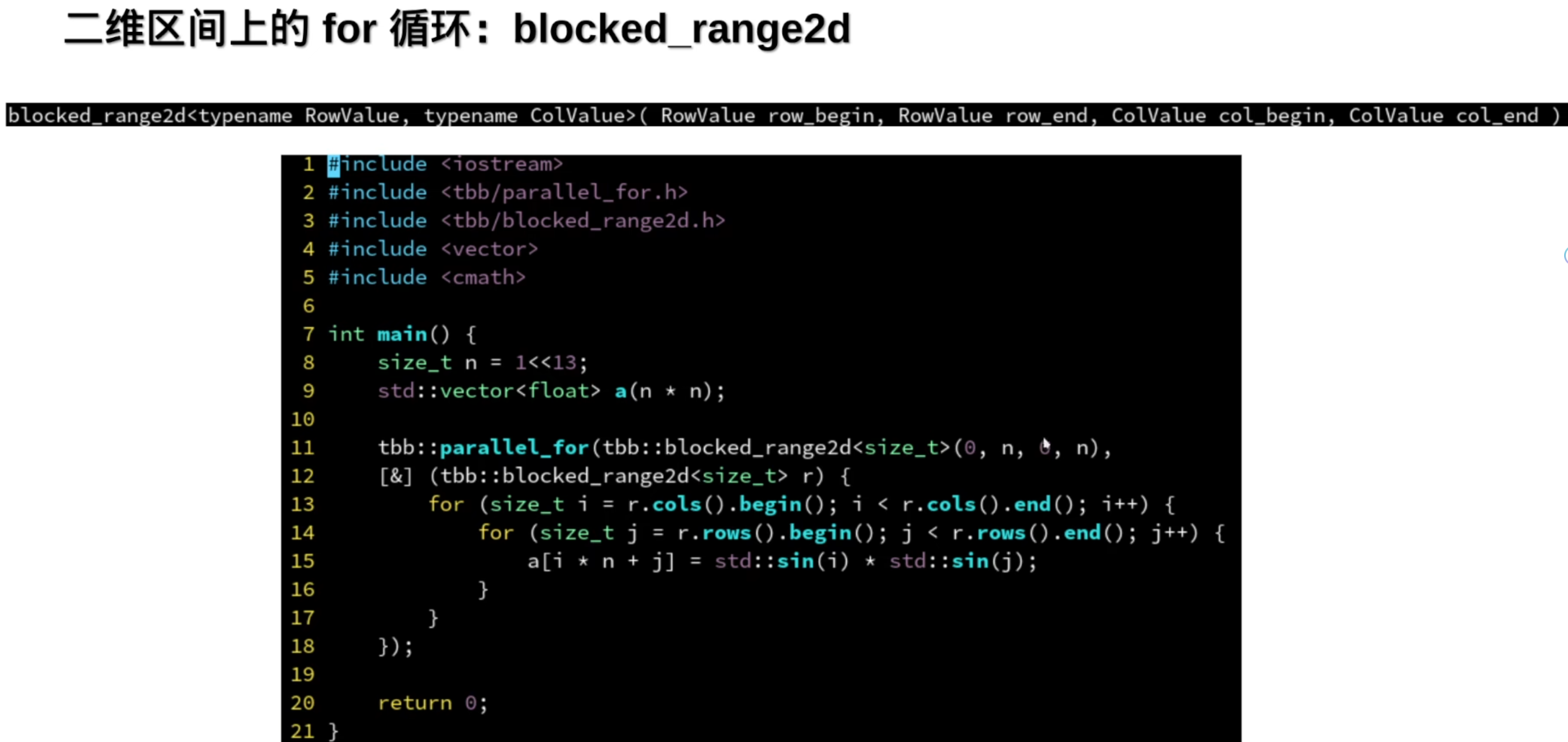
二维
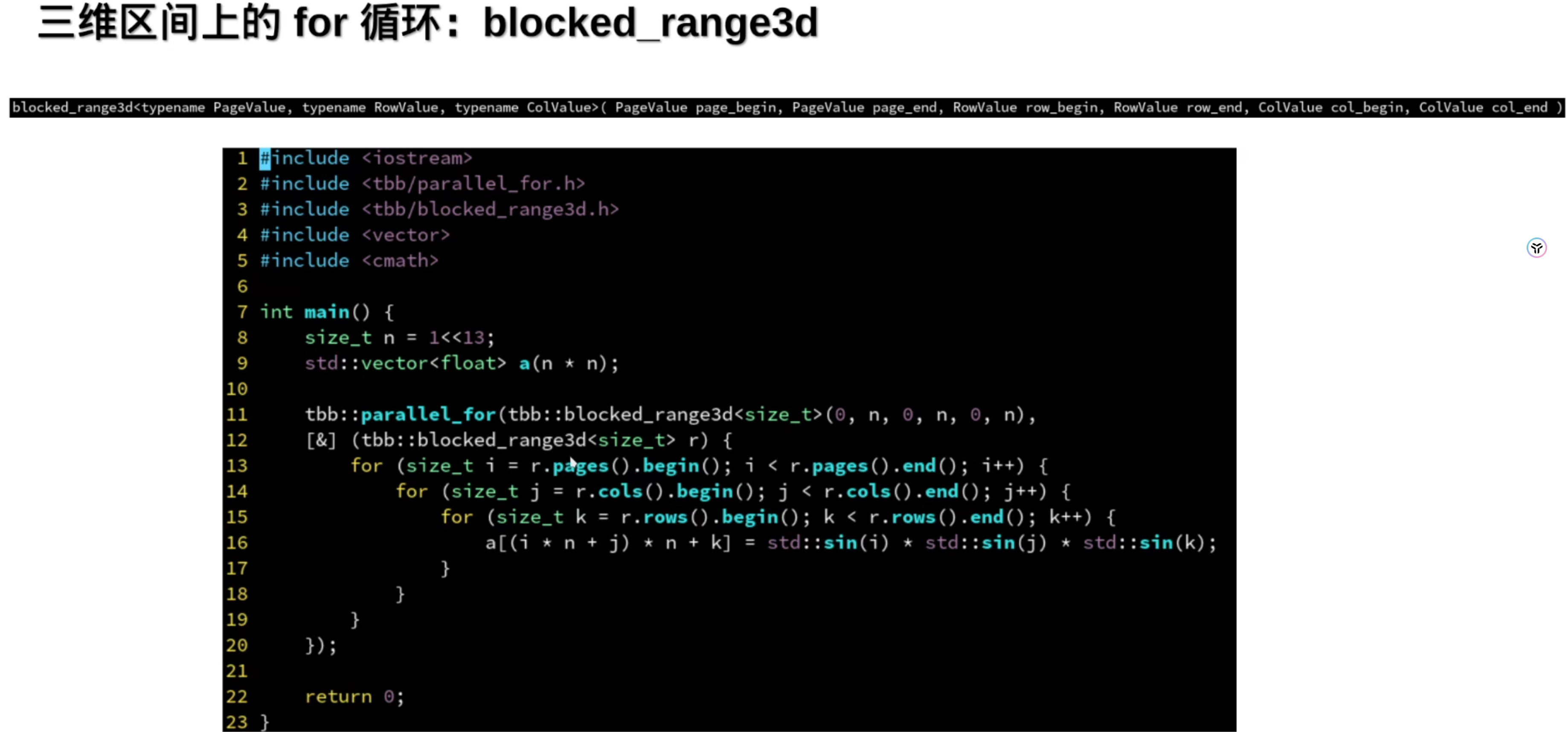
三维
并行缩并
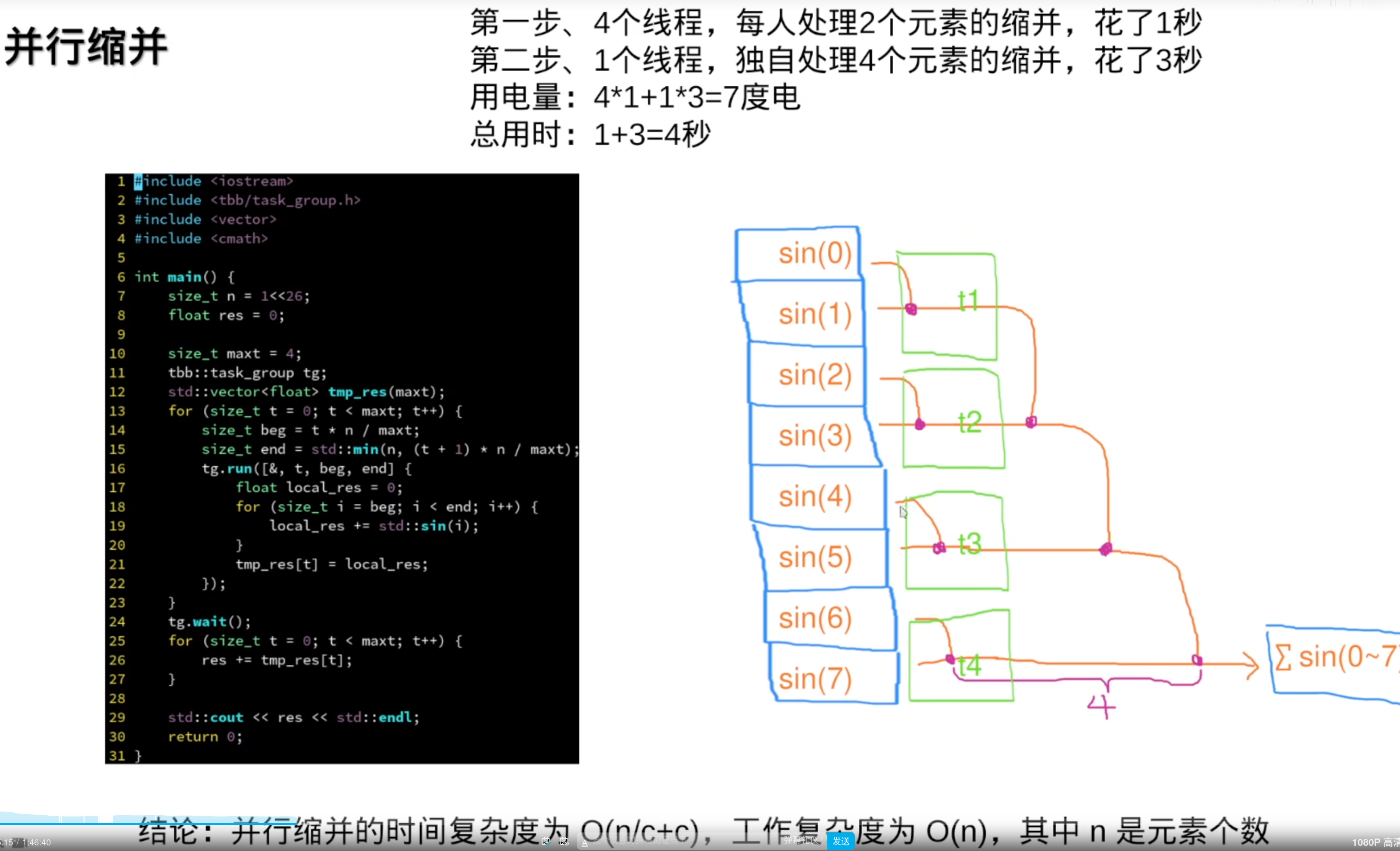
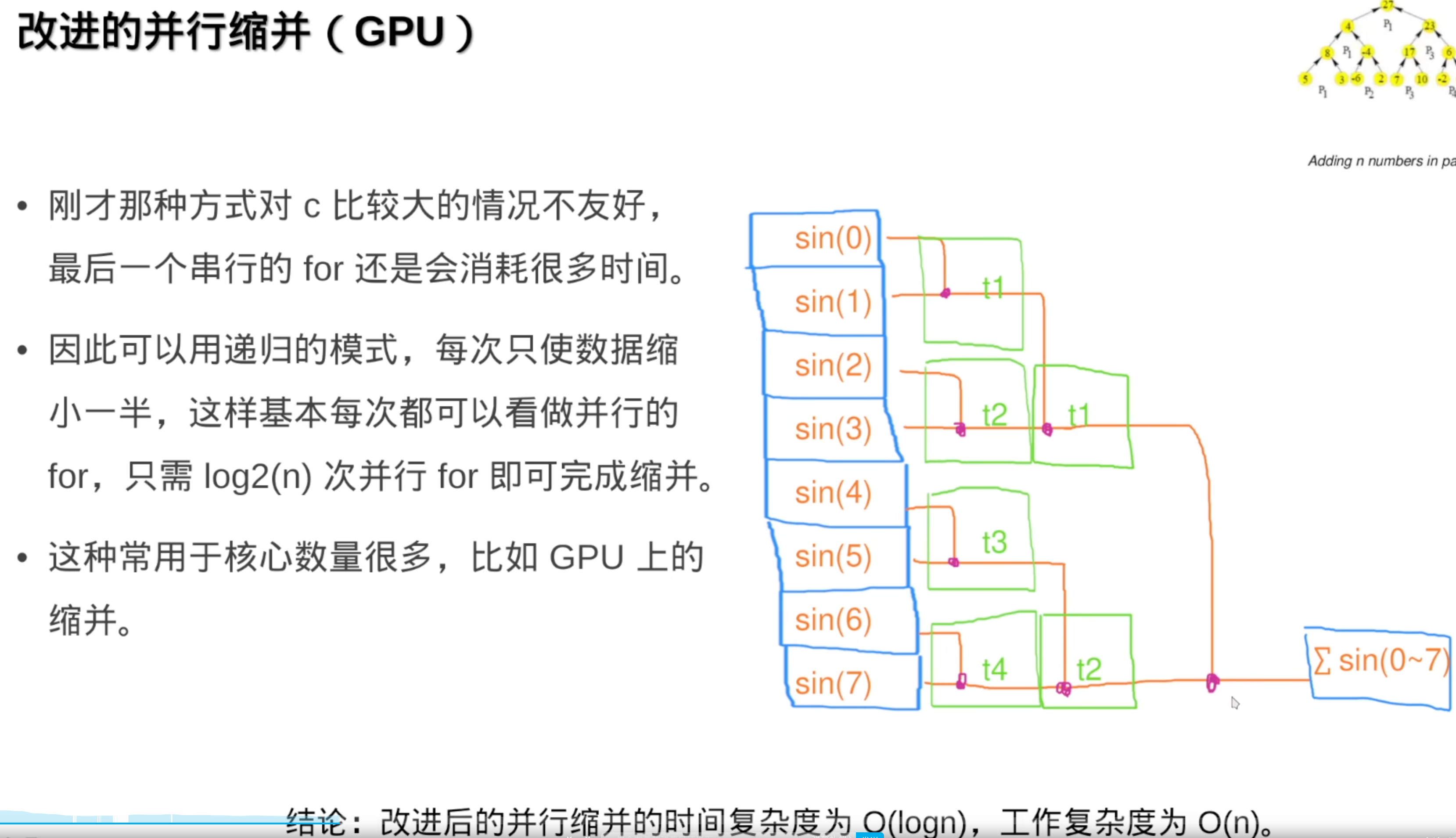

但是,任务是动态分配到线程上,也就是range会变化,精度就会变,为了性能结果会有不同。所以:

并行缩并的好处,相比于普通的串行缩并:

串行相加,很大的e指数加上一个很小的float数,误差很大(浮点数不能大加小(等于没加))
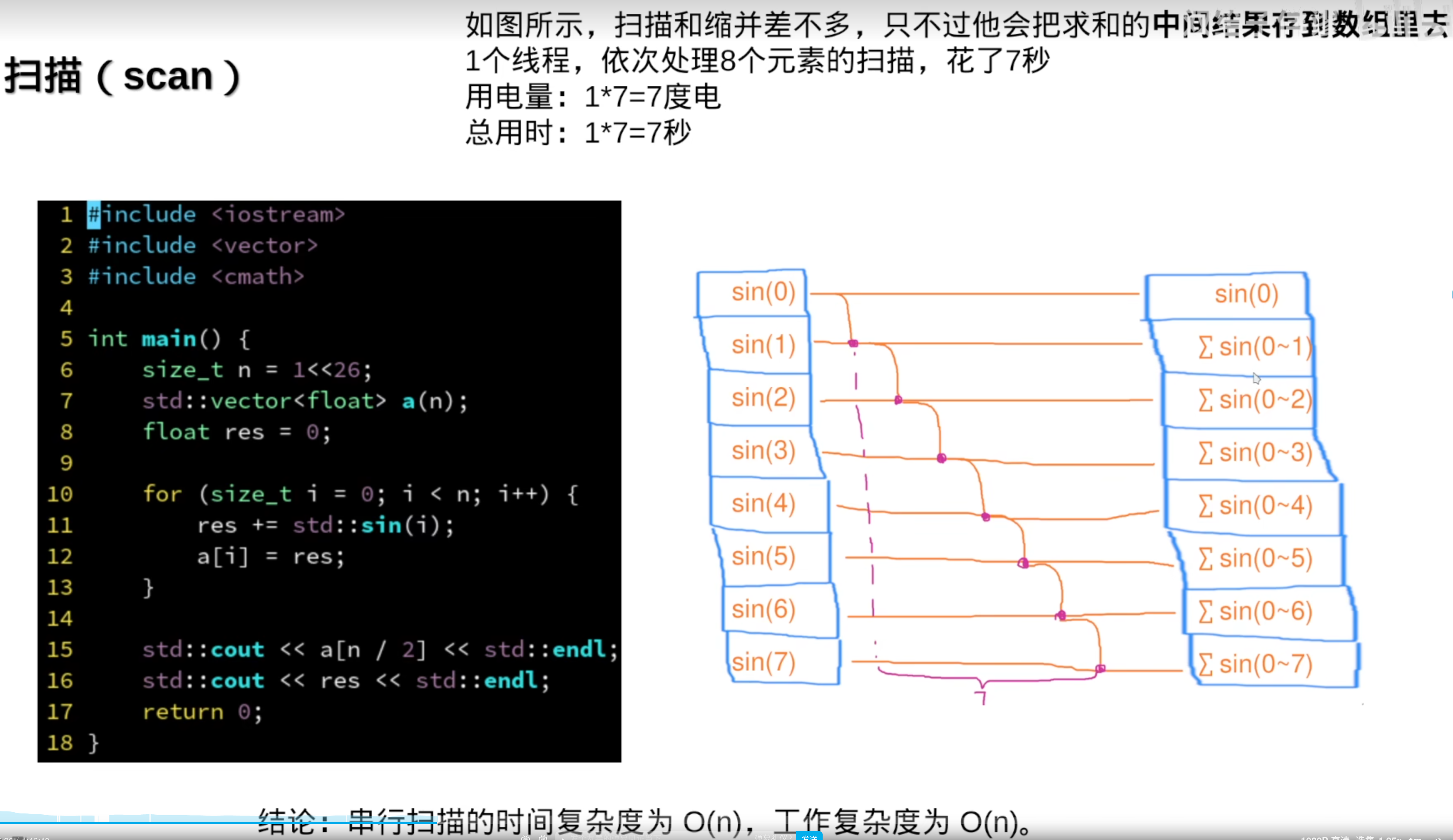
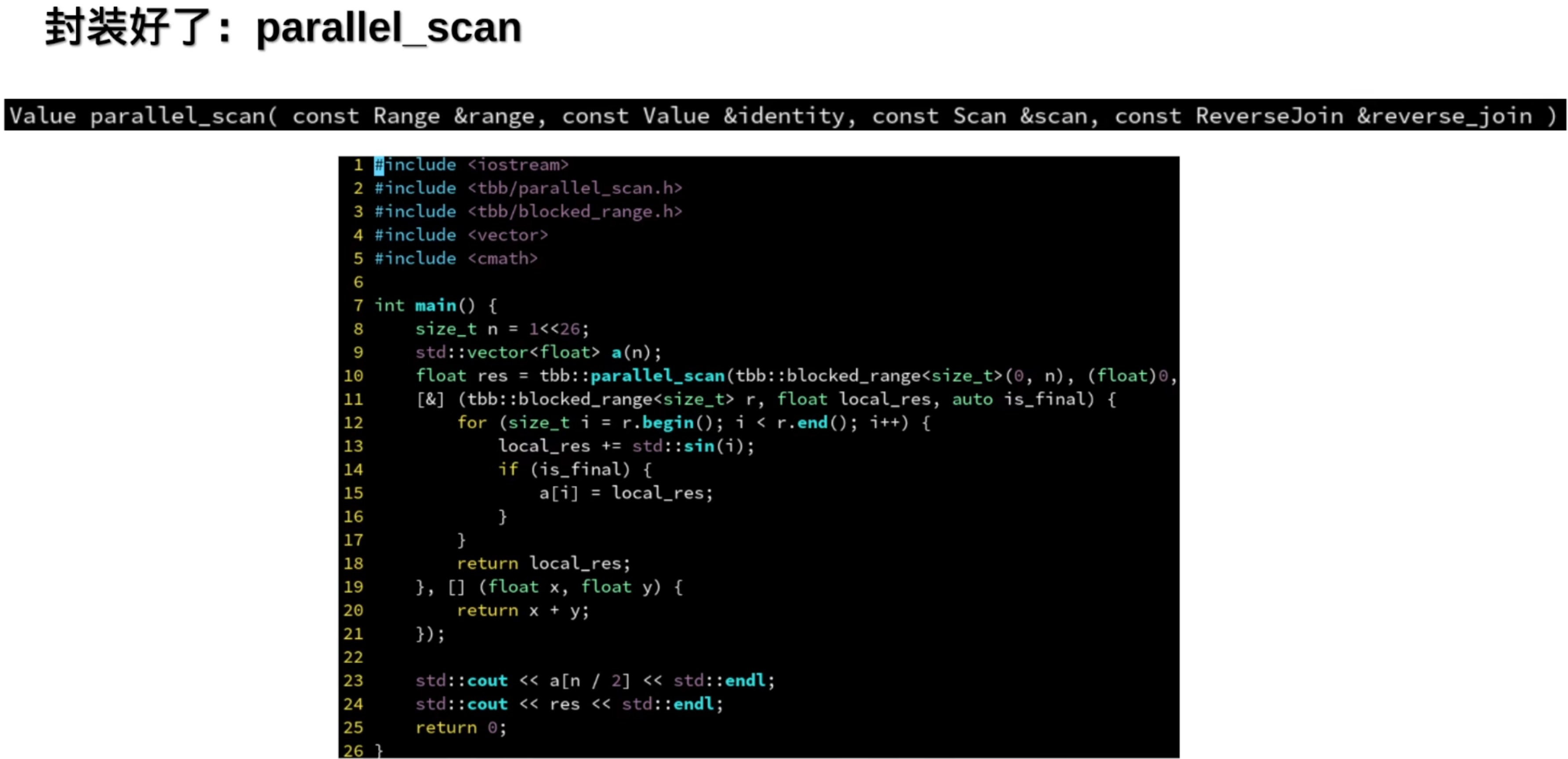
通常用于生成直方图
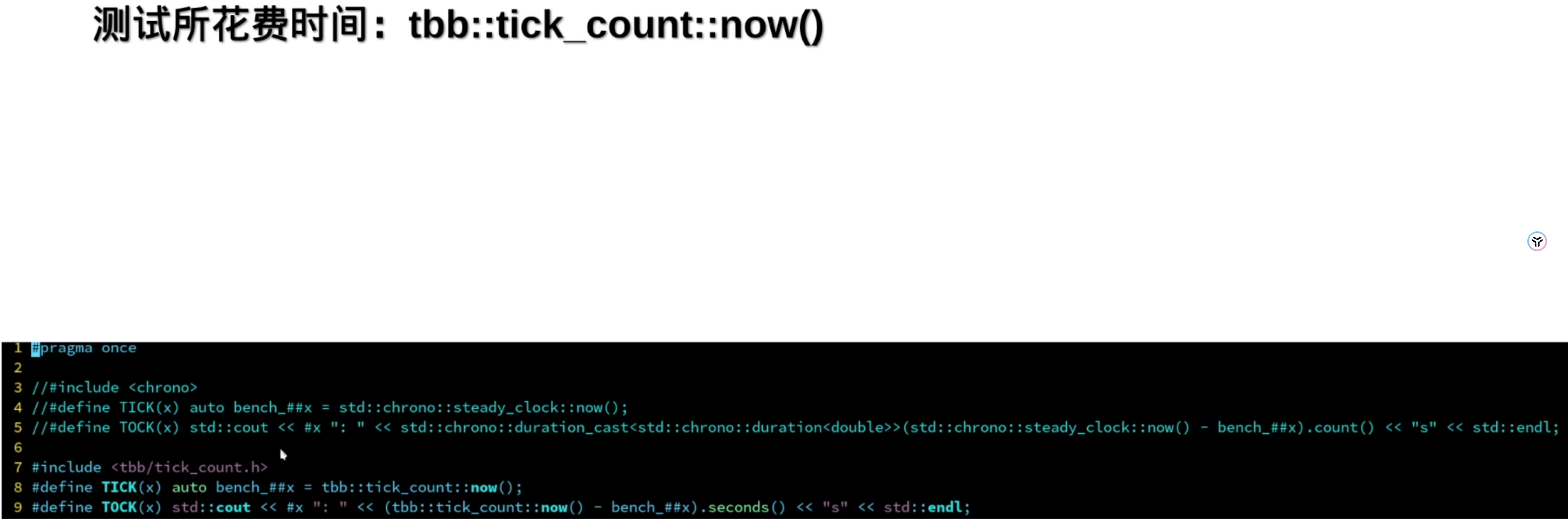

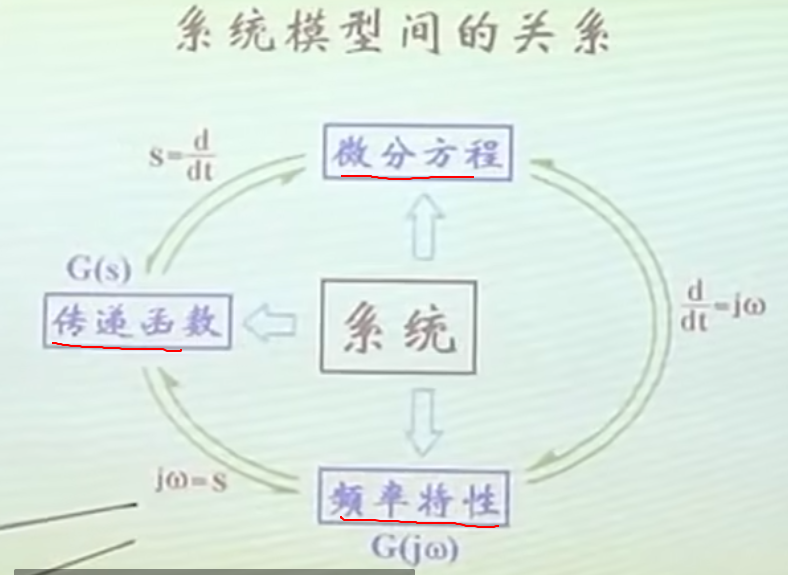
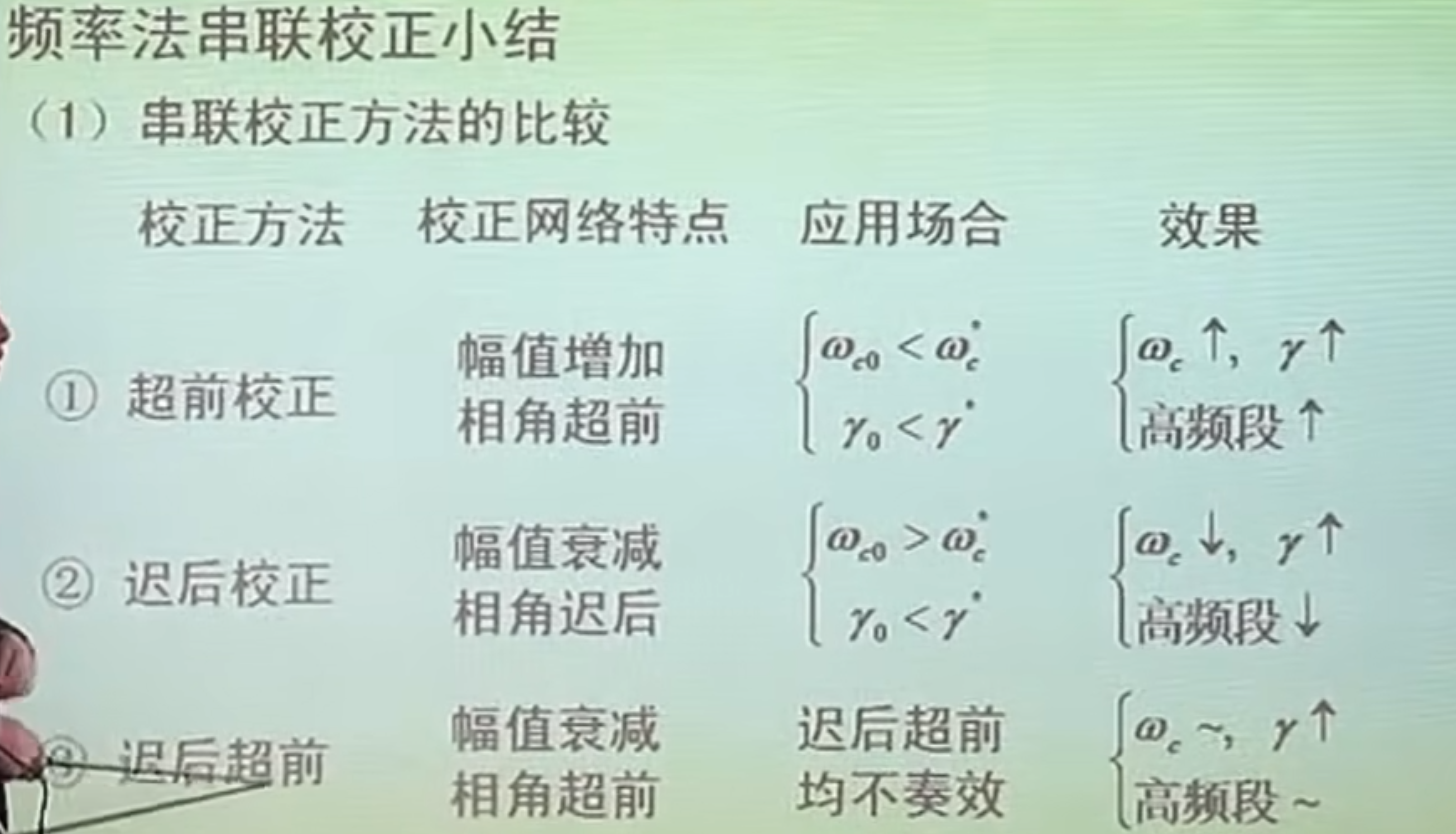
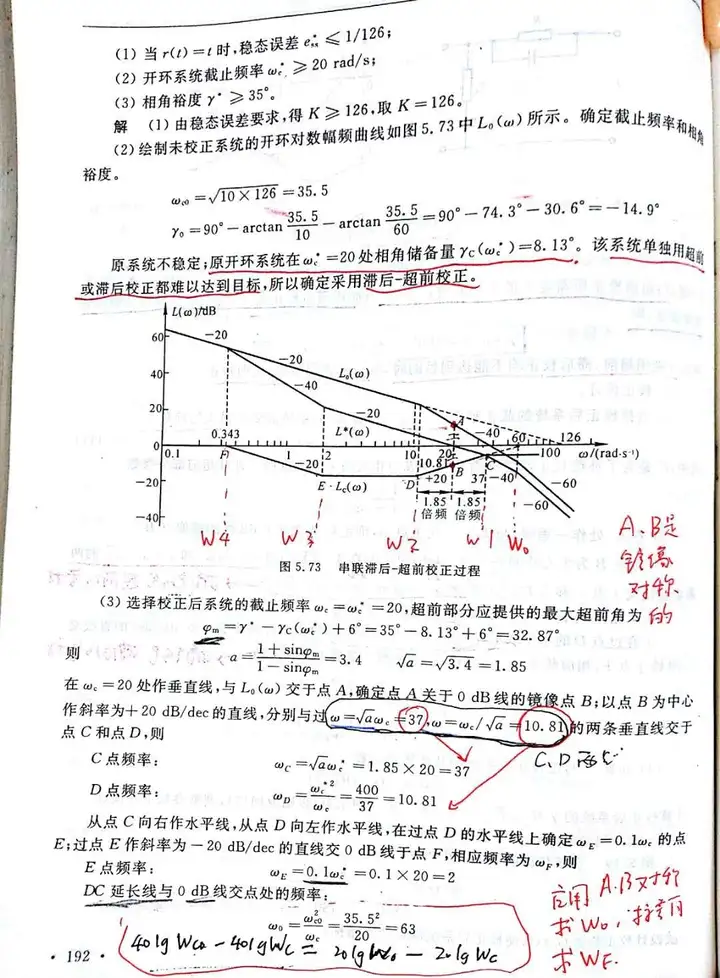
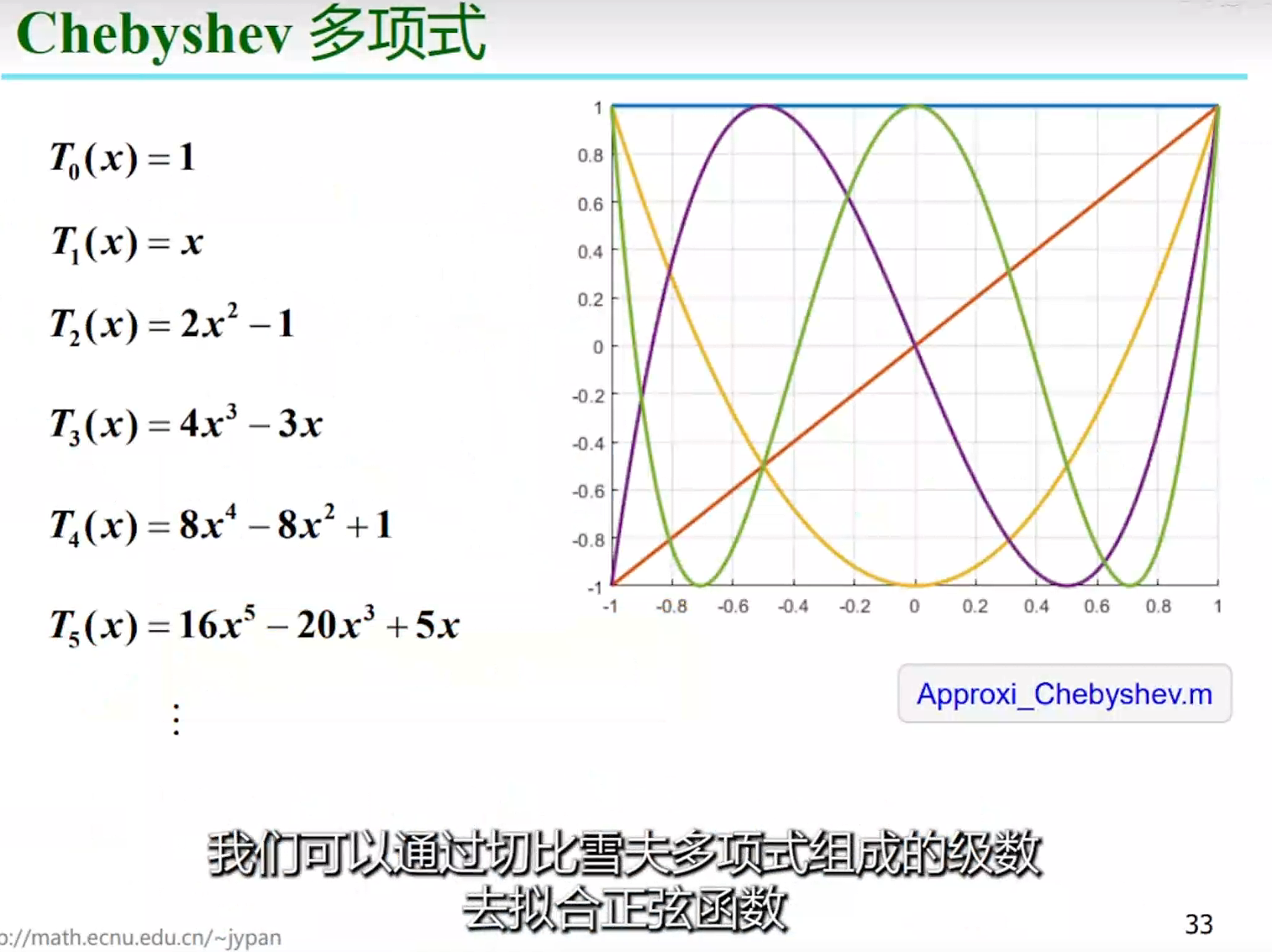
考试比较喜欢的考法是将这三种校正与“PID校正”校正结合起来,他们喜欢说PID校正,毕竟PD、PI、PID校正分别是超前、滞后、和滞后-超前校正的特殊情况。
$\text{最大超前角}\\varphi_m=\gamma^{\prime\prime}-\gamma+5°=45°-0°+5°=50°\a=\frac{1+\mathrm{sin}\varphi_m}{1-\mathrm{sin}\varphi_m}\approx8:,\quad10\mathrm{lg}a\approx9\mathrm{dB}$

文件扩展名 .tpp 通常表示 C++ 模板实现文件。它与 C++ 模板相关,主要用于存放模板类或函数的实现。
模板定义分离:在 C++ 中,通常将模板的声明和实现分开。在头文件(.hpp 或 .h)中,你可以声明一个模板,而在 .tpp 文件中实现该模板。这种做法有助于保持代码的组织性和可读性。
包含在头文件中:为了使用 .tpp 文件中的实现,通常会在相应的头文件中通过 #include 指令将其包含进来。
假设你有一个简单的模板类 MyClass,可以这样组织文件:
MyClass.hpp
#ifndef MYCLASS_HPP
#define MYCLASS_HPP
template <typename T>
class MyClass {
public:
MyClass(T value);
void display();
private:
T data;
};
#include "MyClass.tpp" // 包含实现文件
#endif // MYCLASS_HPP
MyClass.tpp
#include "MyClass.hpp"
#include <iostream>
template <typename T>
MyClass<T>::MyClass(T value) : data(value) {}
template <typename T>
void MyClass<T>::display() {
std::cout << data << std::endl;
}
debug生成的代码没有经过优化

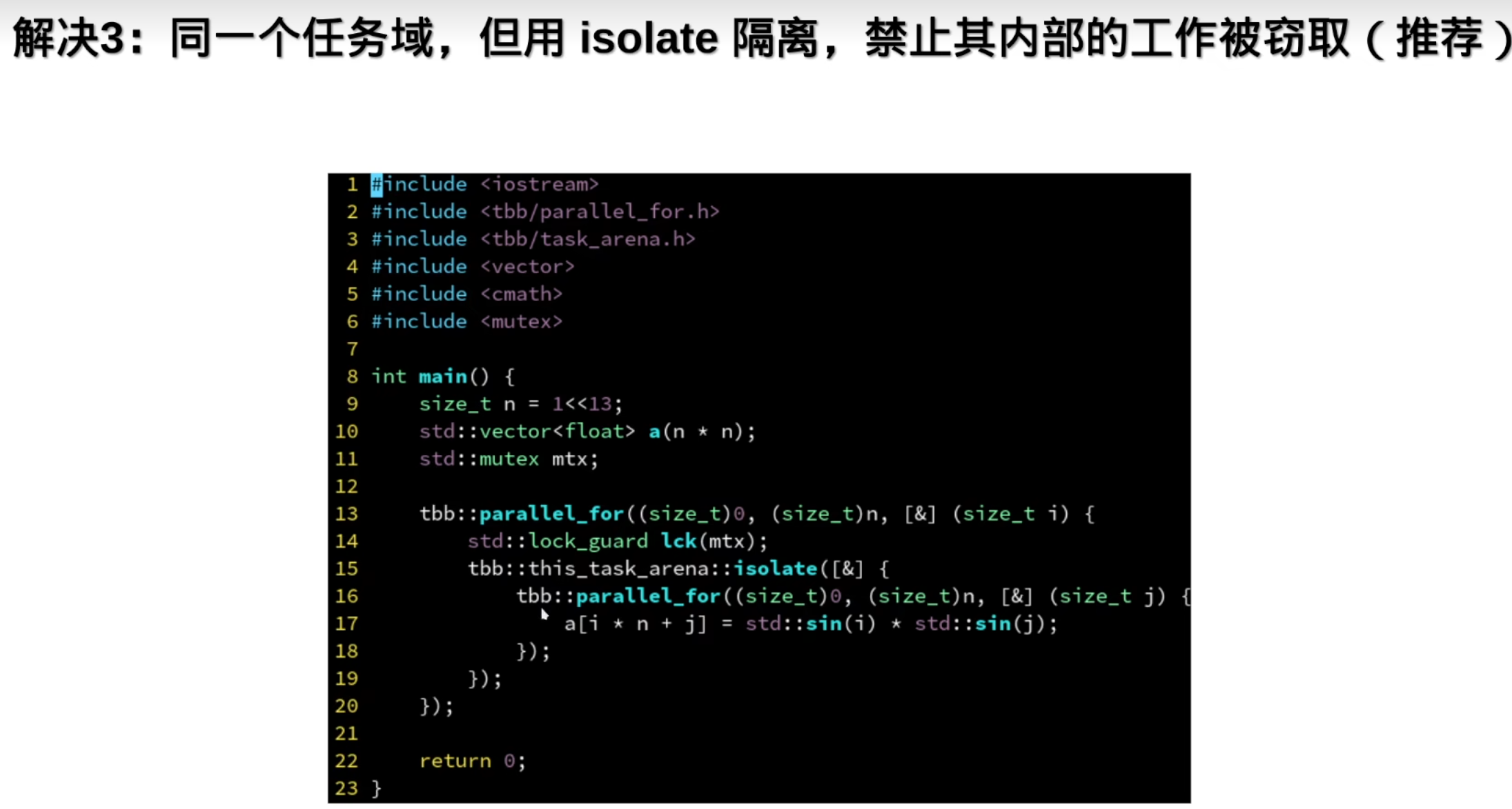
指定任务域里使用的线程
并行嵌套for循环
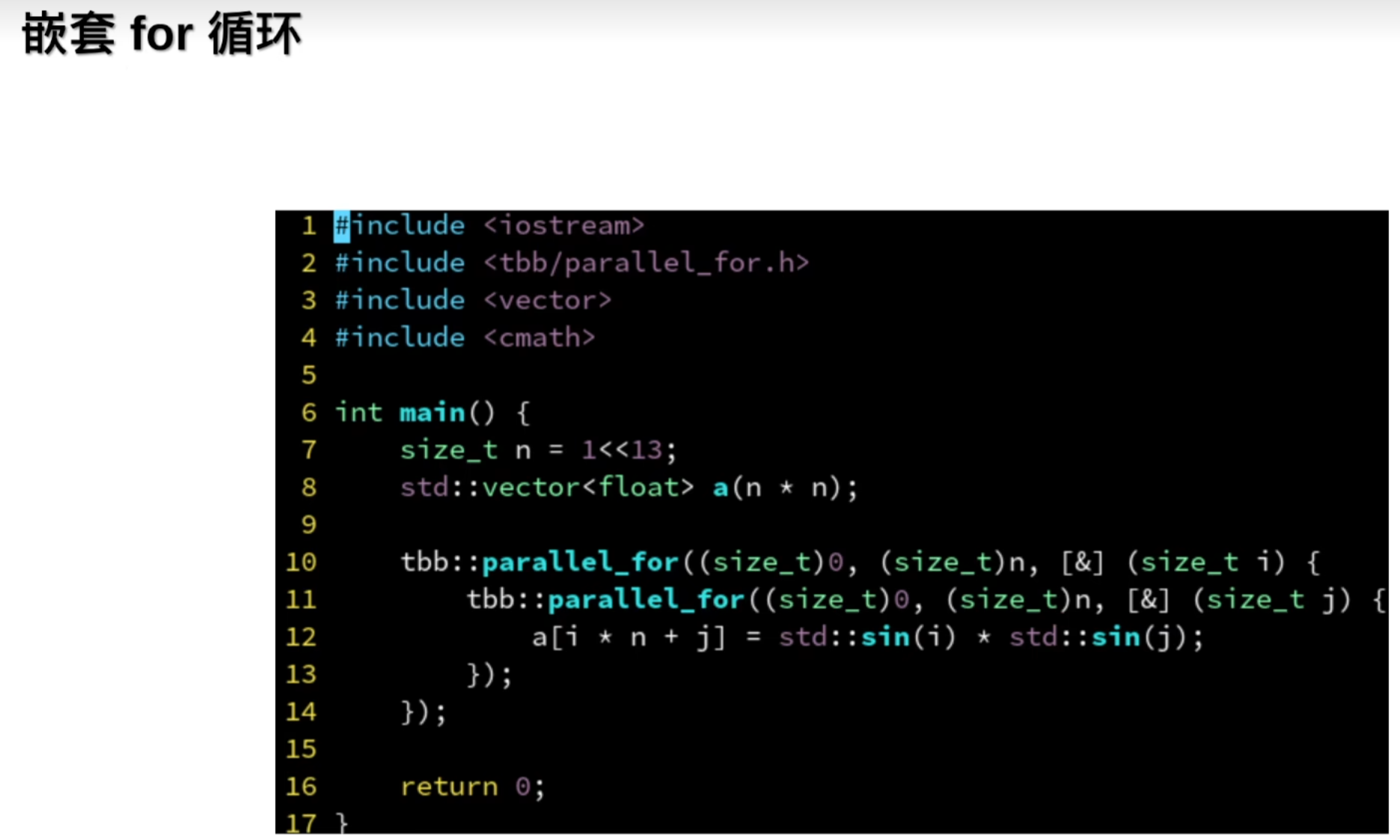
但是嵌套for循环会出现死锁问题:
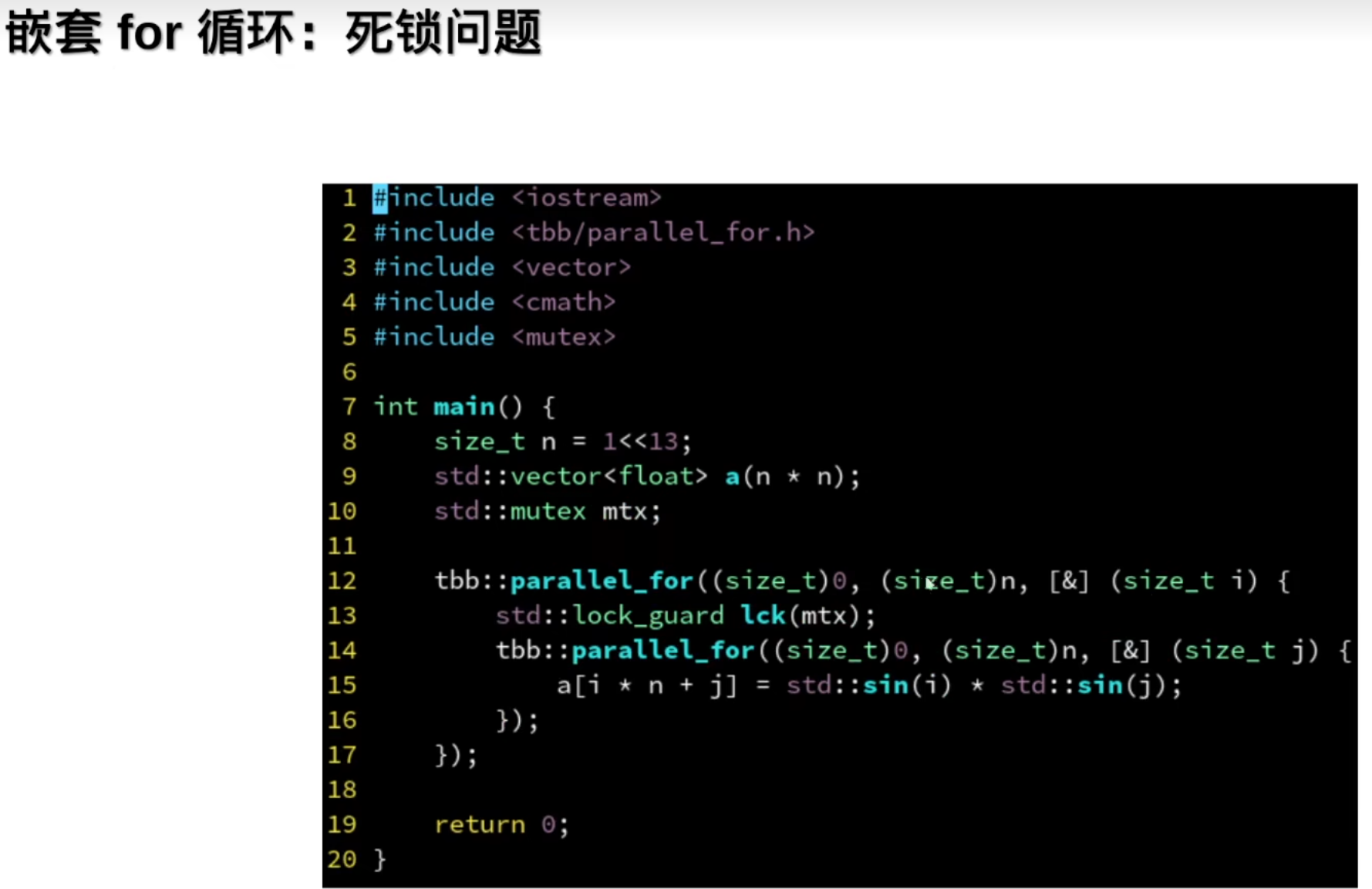
为啥:(性能优化:线程里的任务做完了,会去其他线程里取任务帮忙)

解决办法:

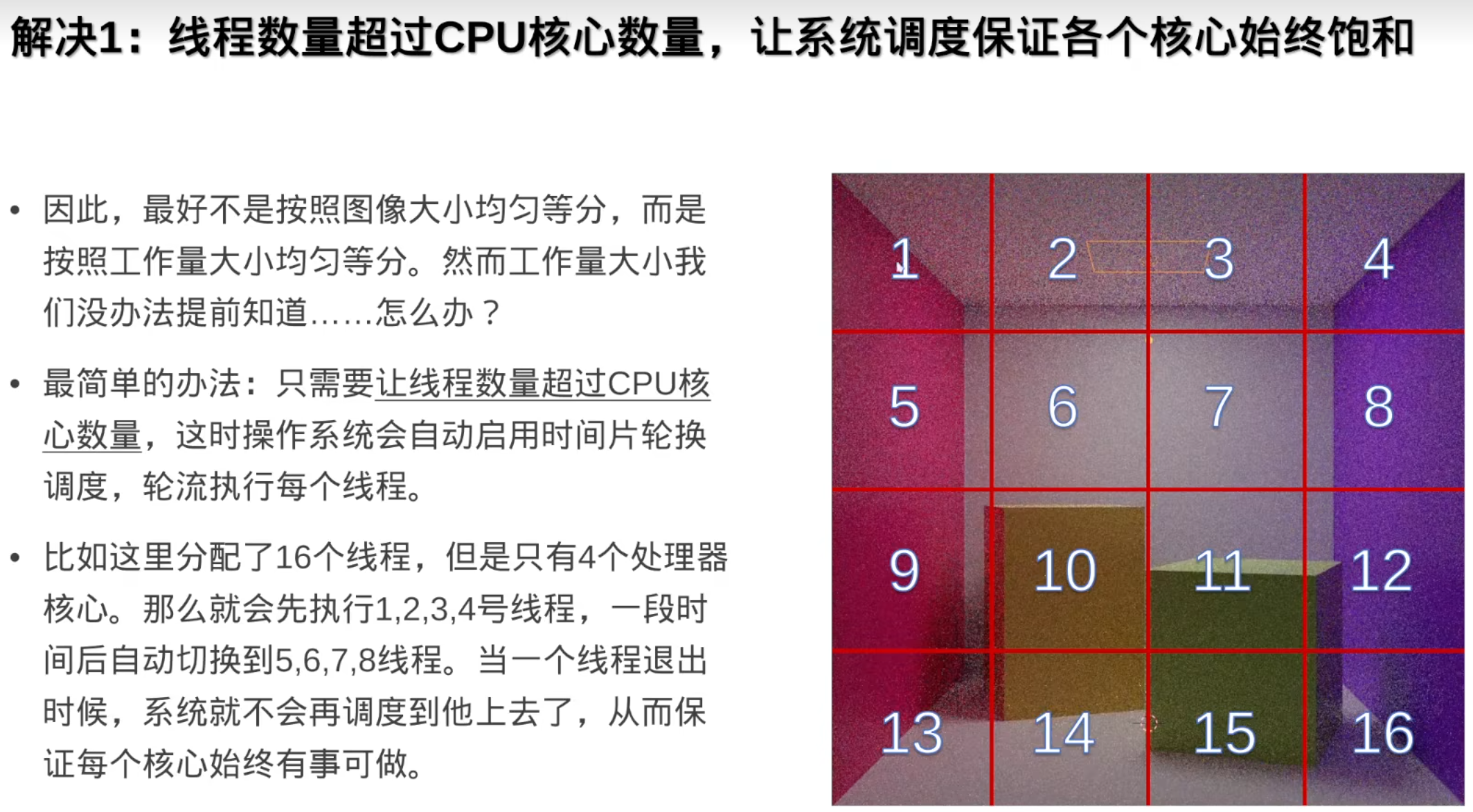
并行的时候怎样把一个任务均匀的分配到每个线程/核心(因为通常几个核心就开几个线程)呢:(线程和任务都不动)

效果不太好,不能让核心闲着,让核心上一直有线程在运行
解决:让线程数大于核心数(让线程动起来)
但是操作系统轮换是有开销(overhead)的,而且有可能破坏缓存一致性
解决:线程池(让任务动起来)
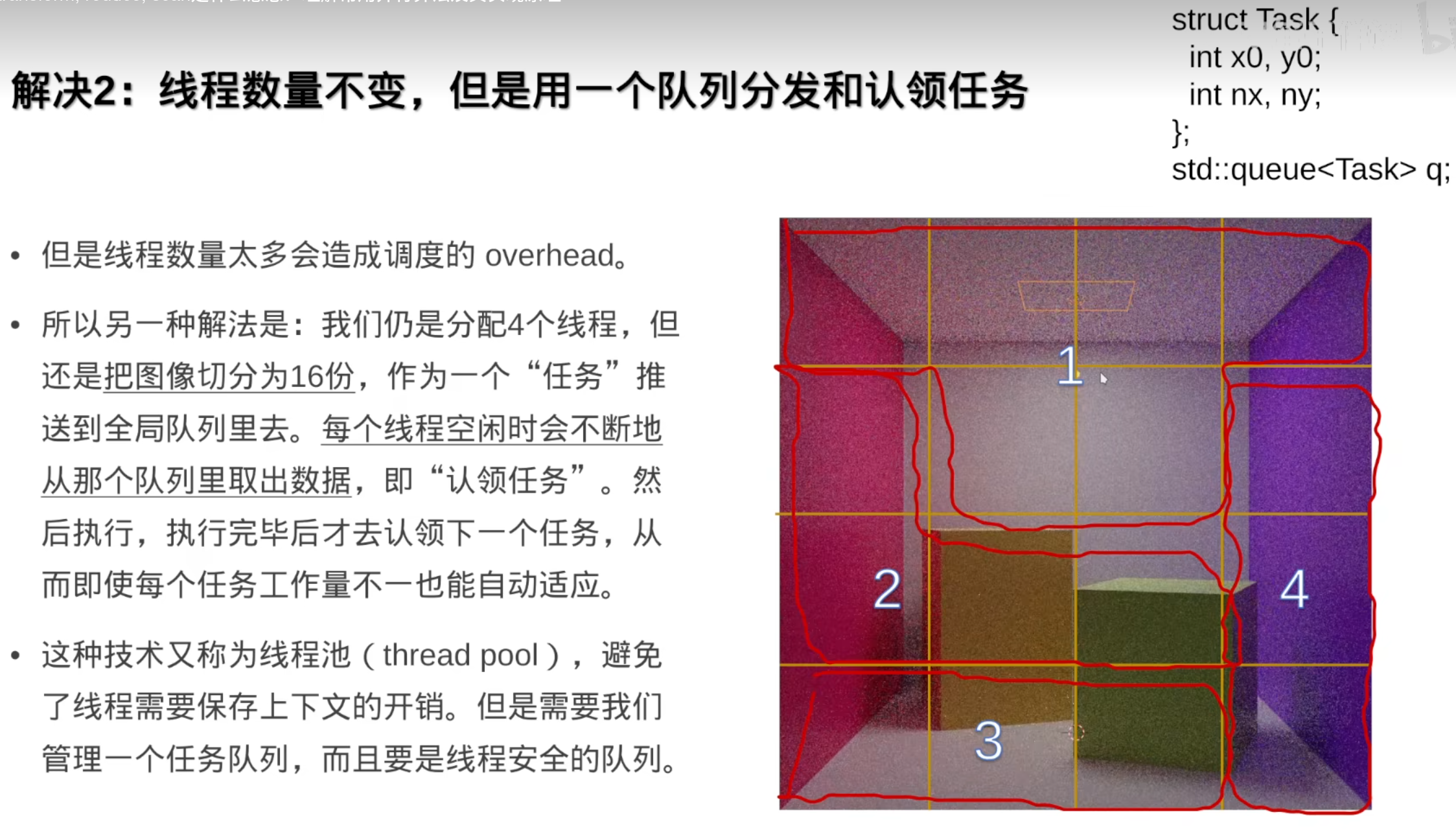
TBB的工作窃取法:
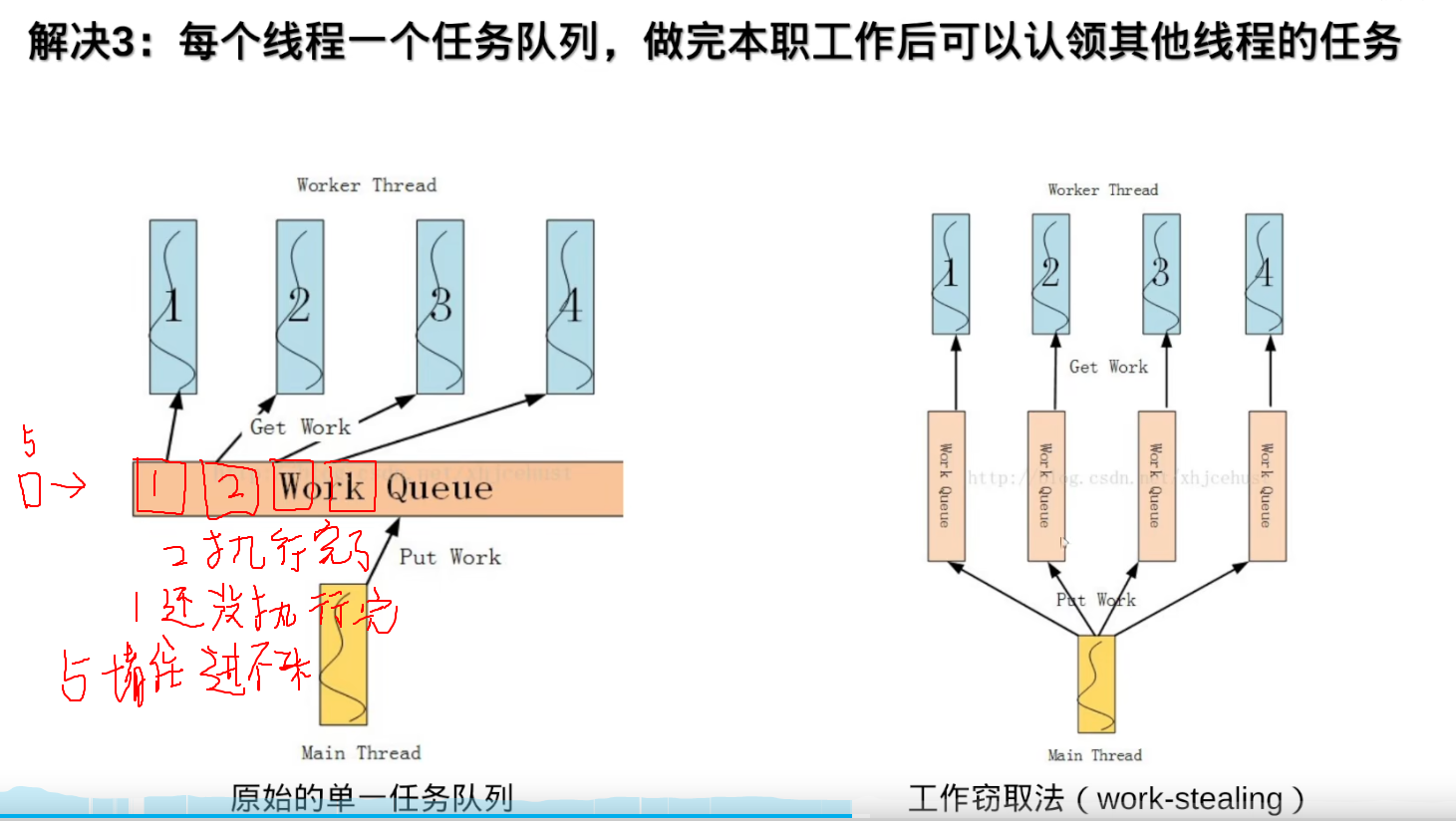
tbb::static_partitioner的线程与任务数量一致
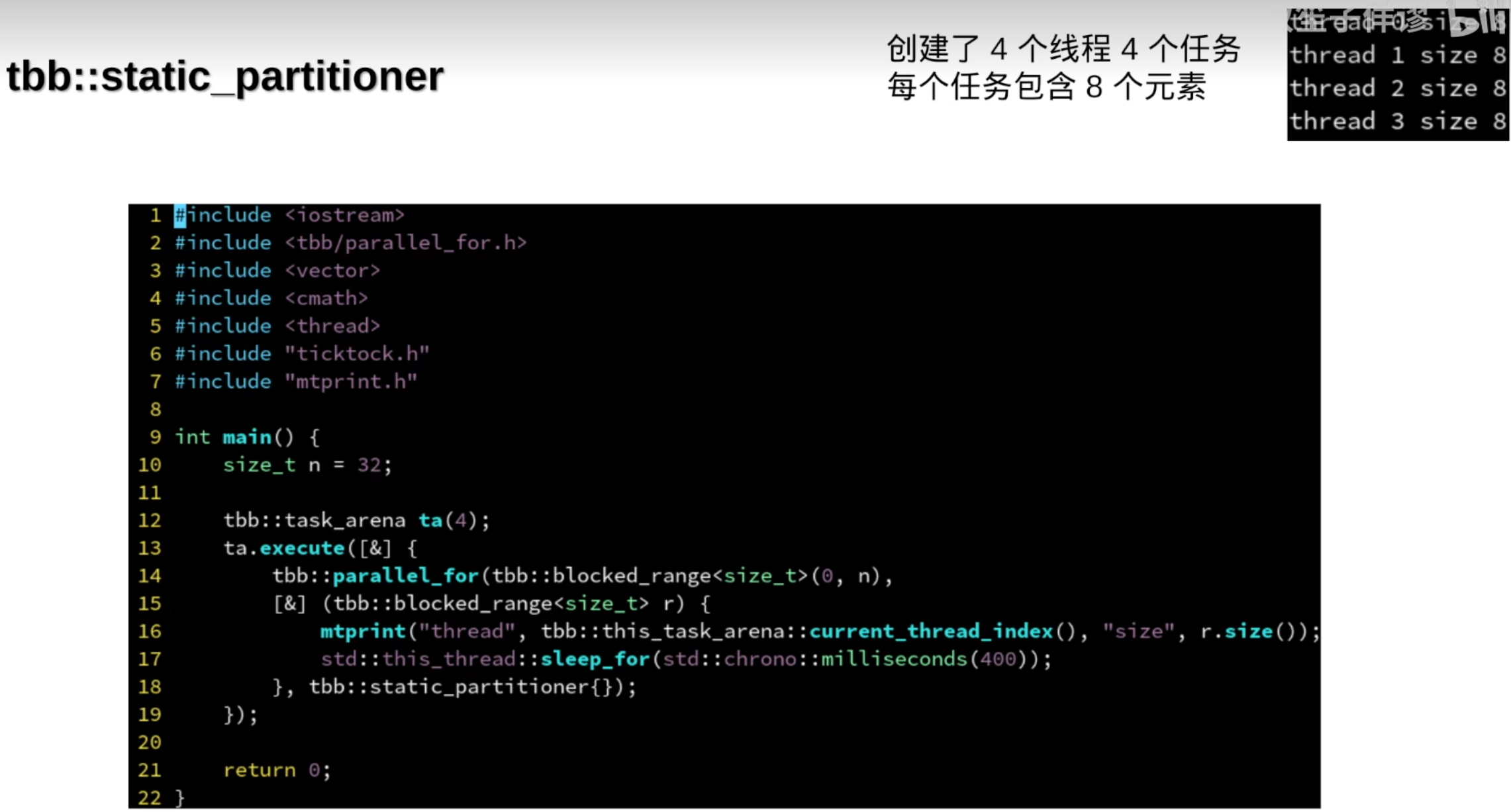
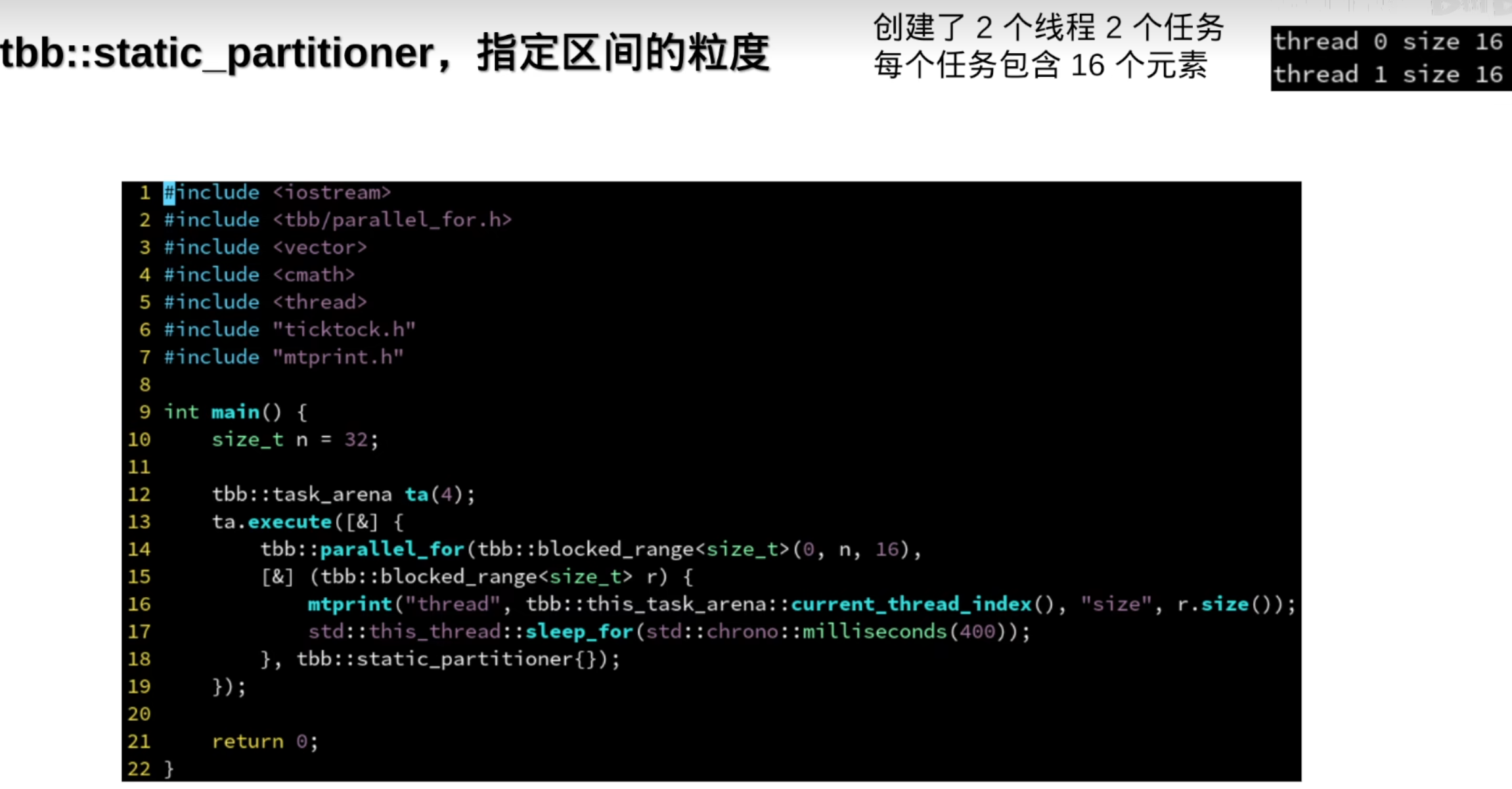
默认粒度(一个任务里的元素)是1


tbb::static_partitioner描述:将任务静态地分配给线程。
特性
:
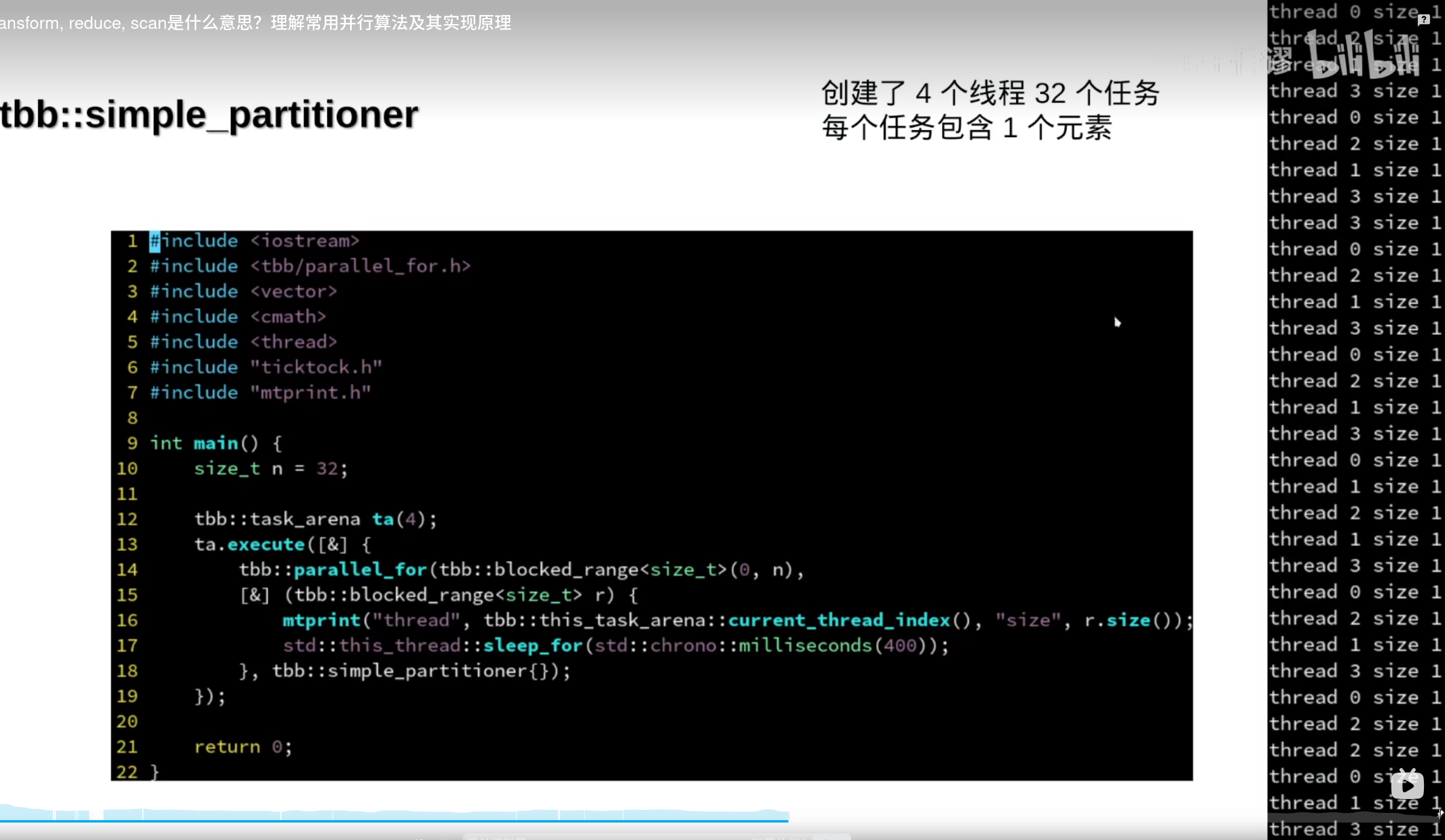
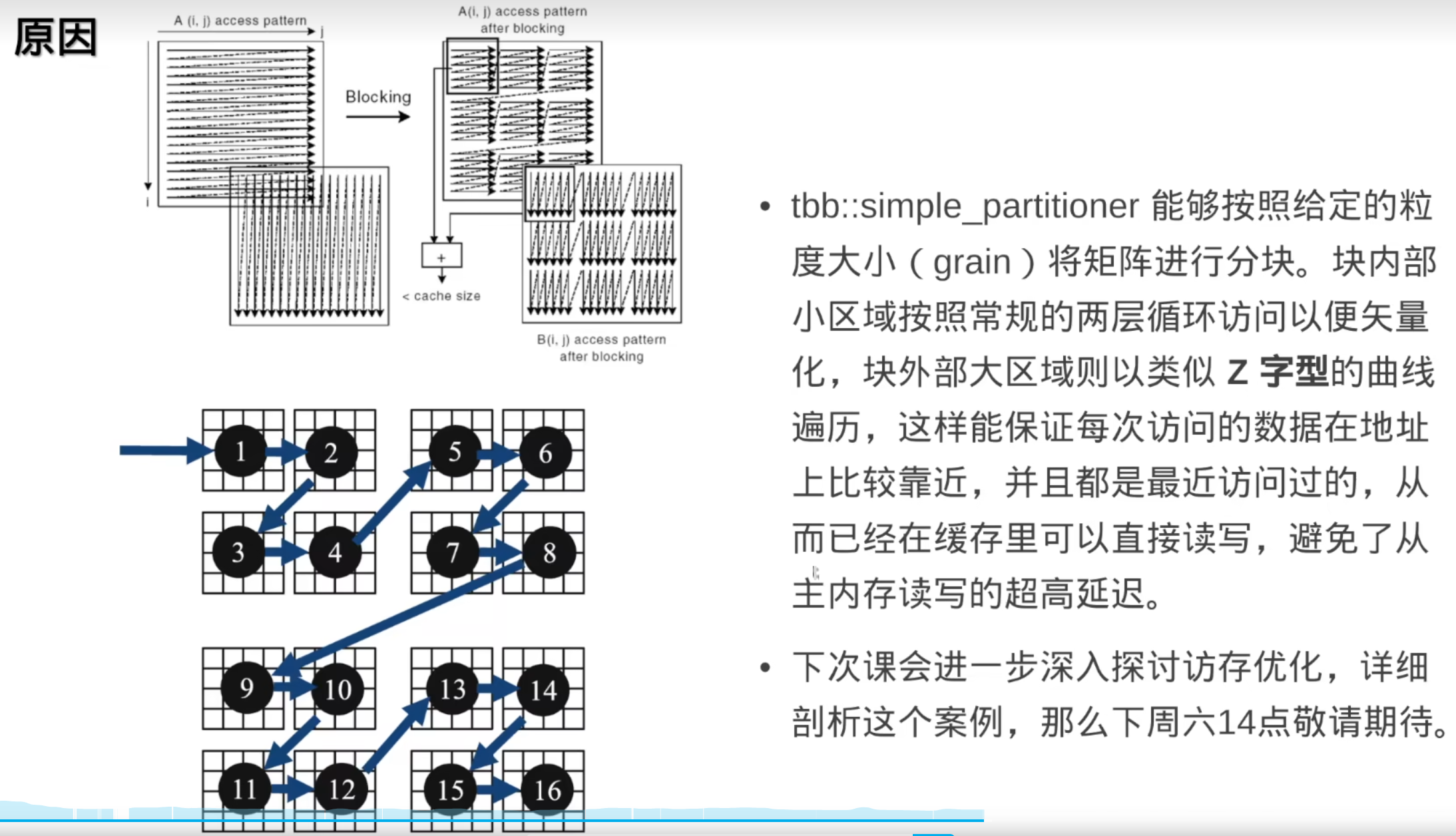
tbb::simple_partitioner描述:提供一个简单的分区策略。
特性
:
static_partitioner,simple_partitioner 允许更好的负载平衡。tbb::auto_partitioner描述:动态调整任务分配以优化性能。
特性
:
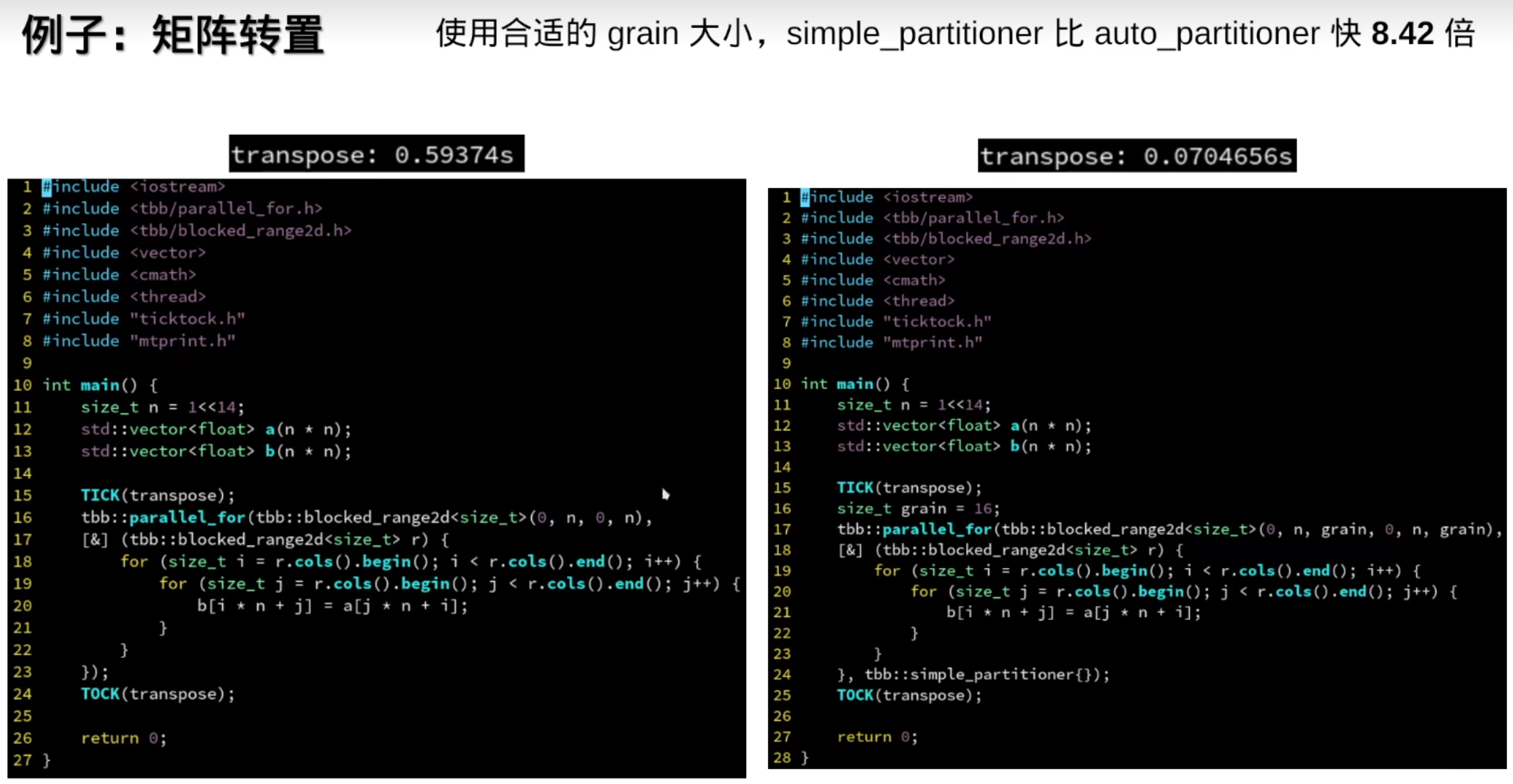
static_partitioner)适用于可预测且均匀的任务;不适合动态负载。simple_partitioner)在一定程度上改进了负载平衡,但仍然保持简单的结构。auto_partitioner)最灵活,适合于动态和不均匀的工作负载,通过实时监测和调整提高整体性能。tbb::static_partitioner对循环体不均匀的情况效果不如tbb::simple_partitioner(操作系统调度)
越来越快


但是auto_partitioner一定比simple_partitioner快吗
问题:

解决:


push_back()返回的是一个迭代器
用*获取迭代器指向的元素的引用,再用and(&)获取这个元素的指针
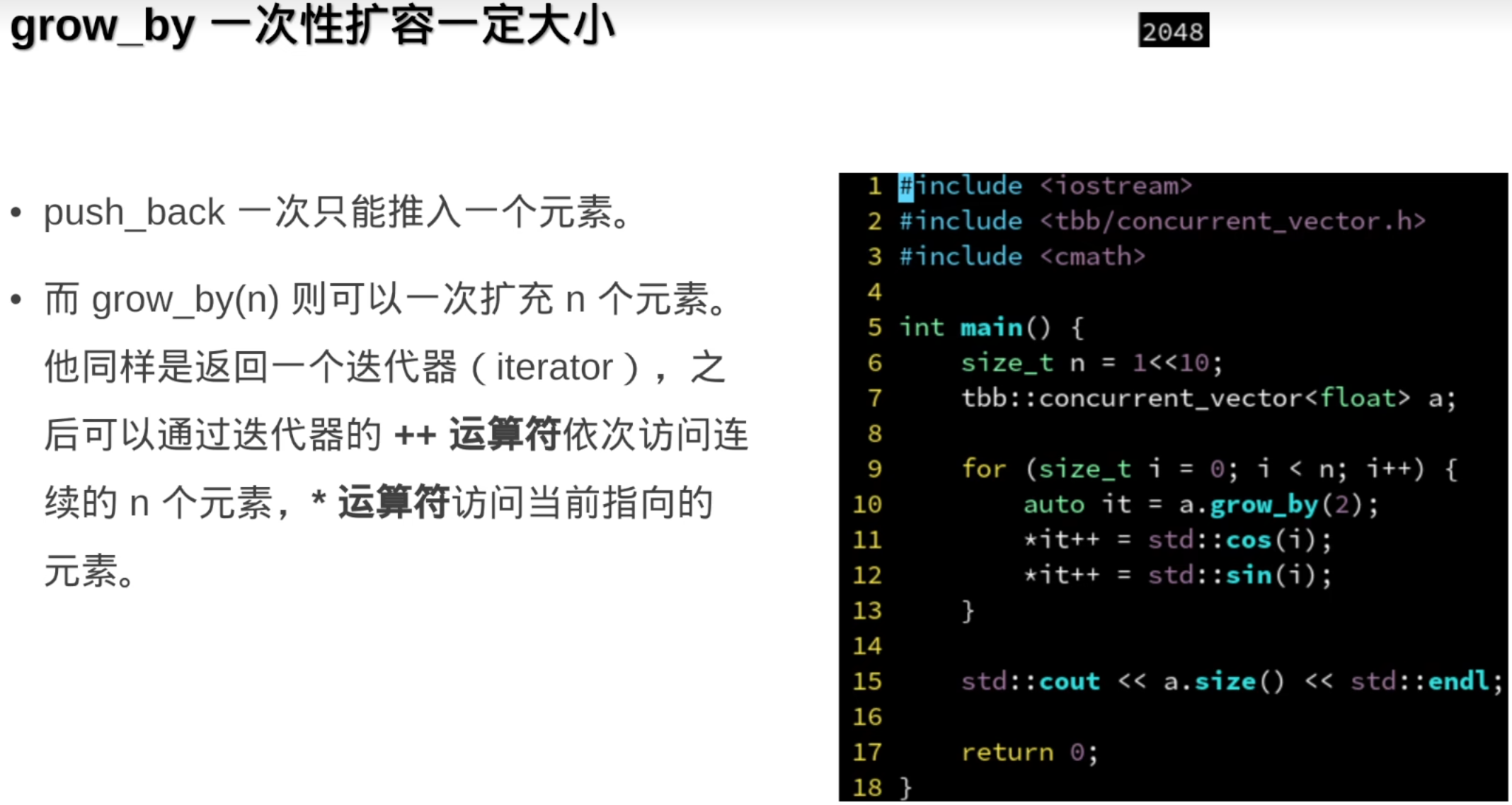
tbb::concurrent_vector还是一个多线程安全的容器

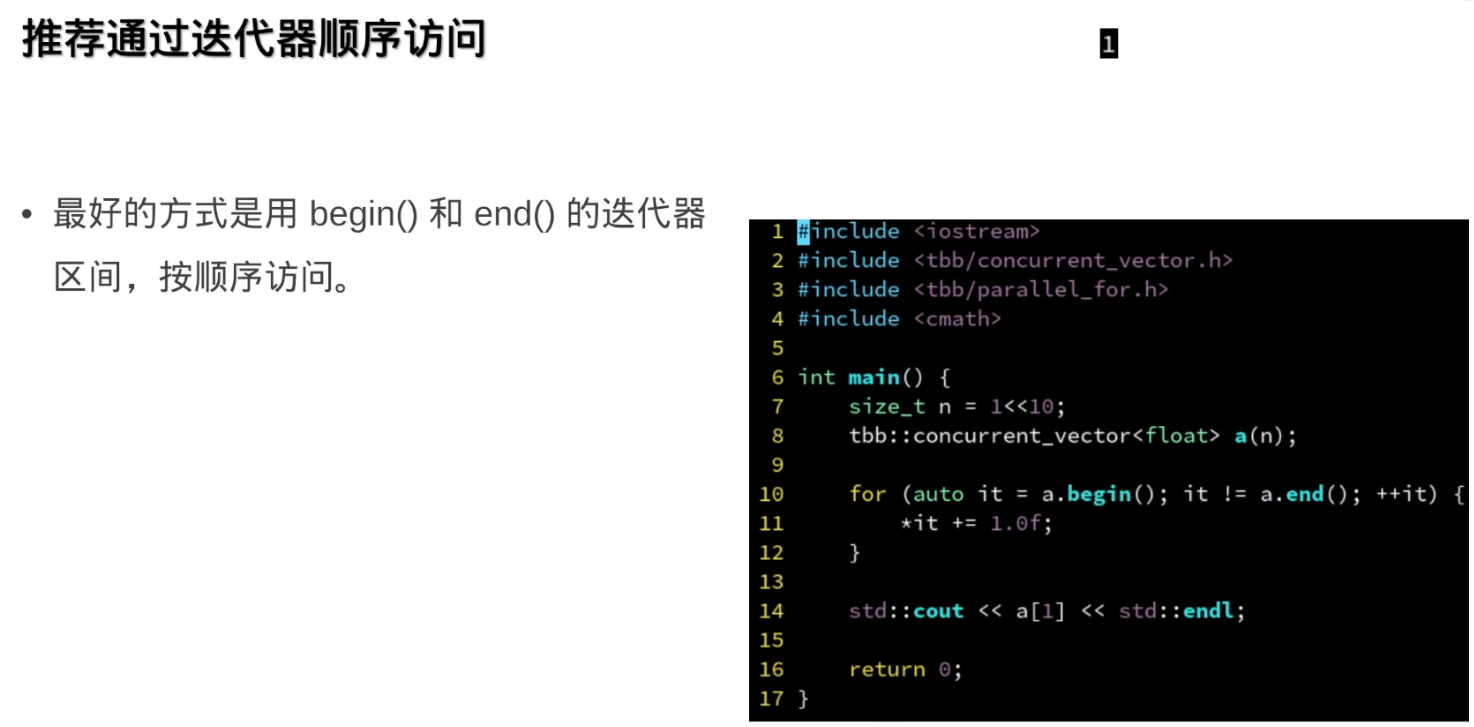
访问:随机访问效率不高

推荐顺序访问:

这些STL容器前加上concurrent就变成了多线程安全版
vector/concurrent_vector有一个常见的用法:用于并行筛选数据:
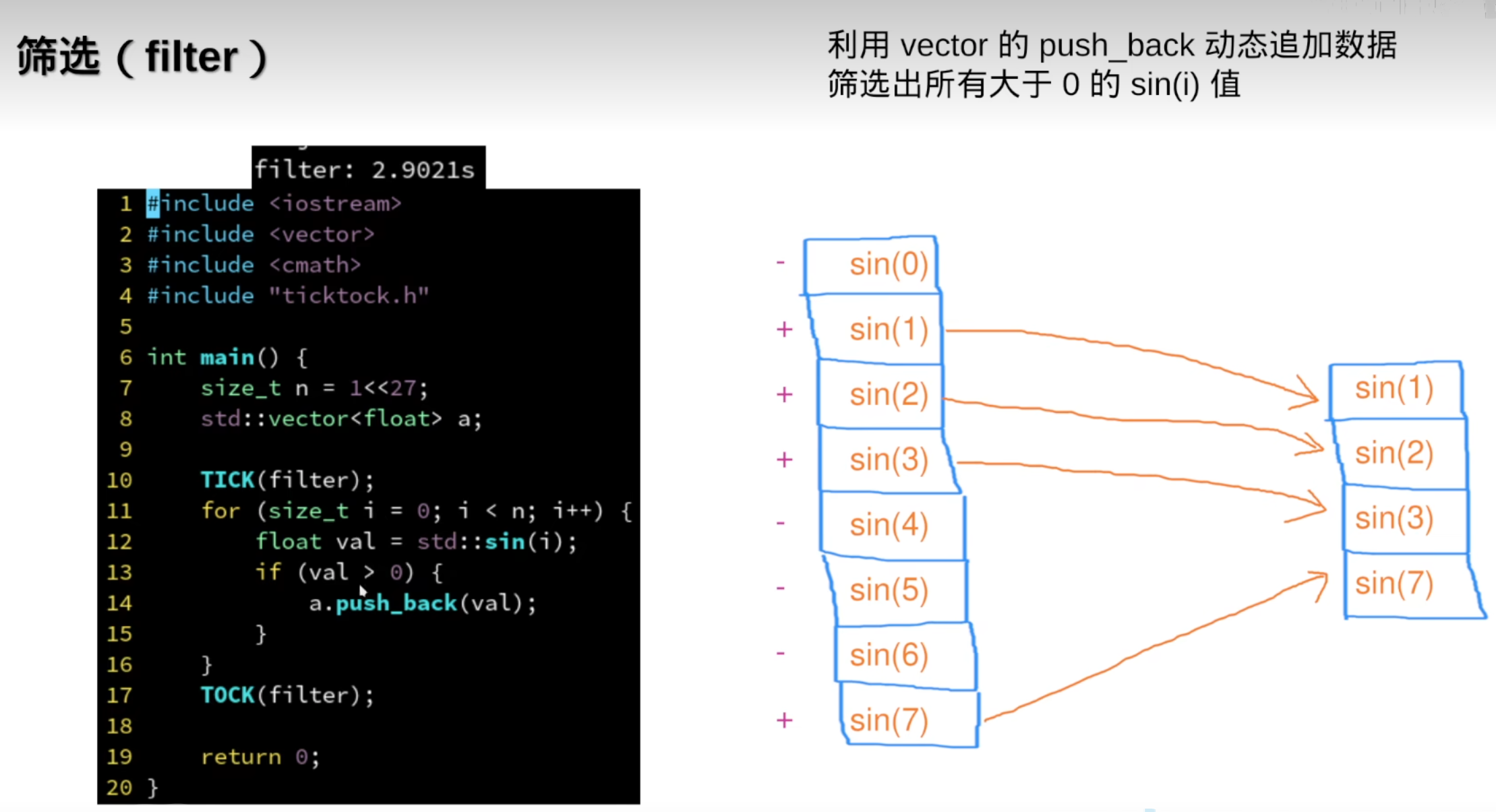
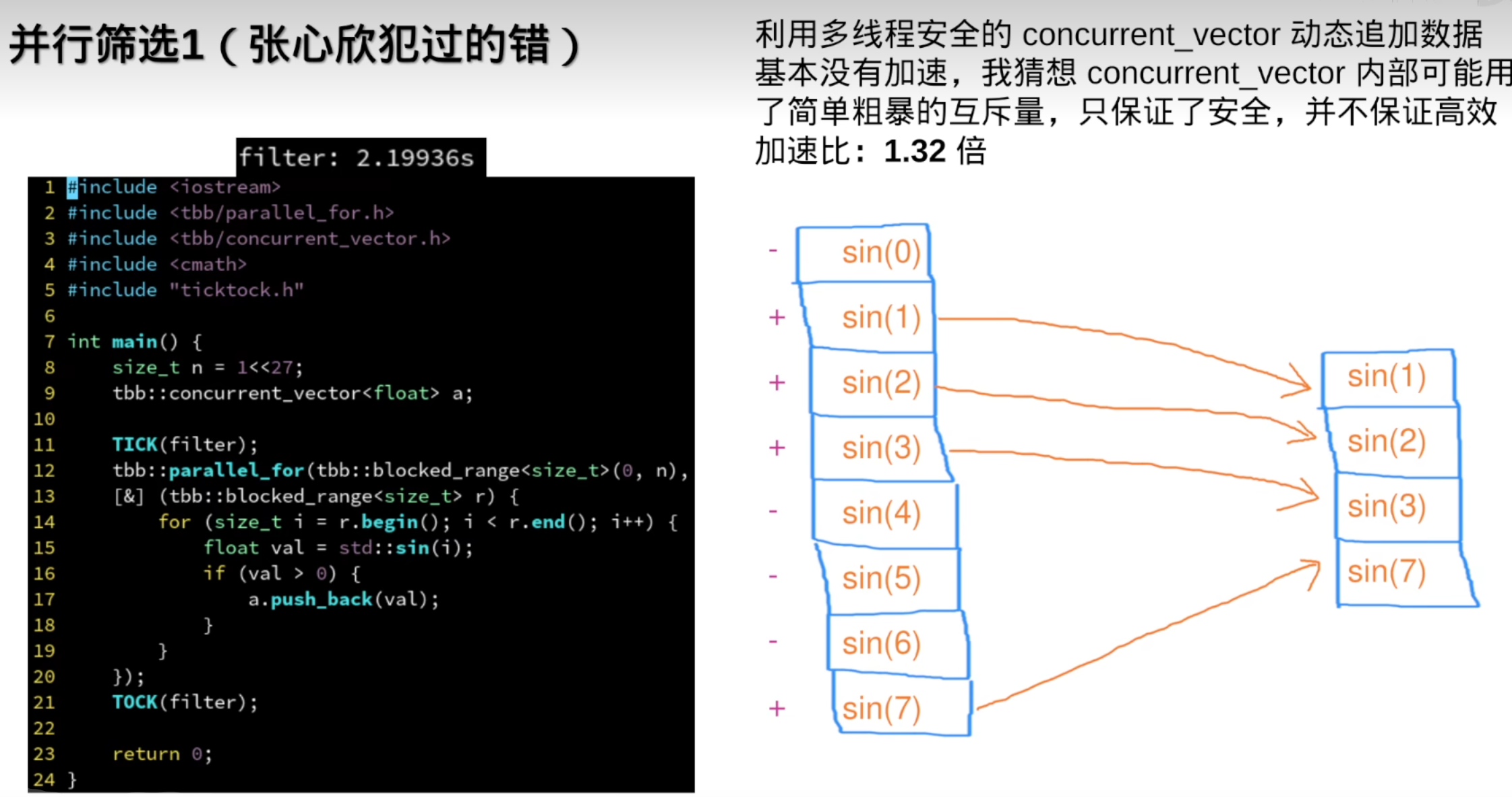

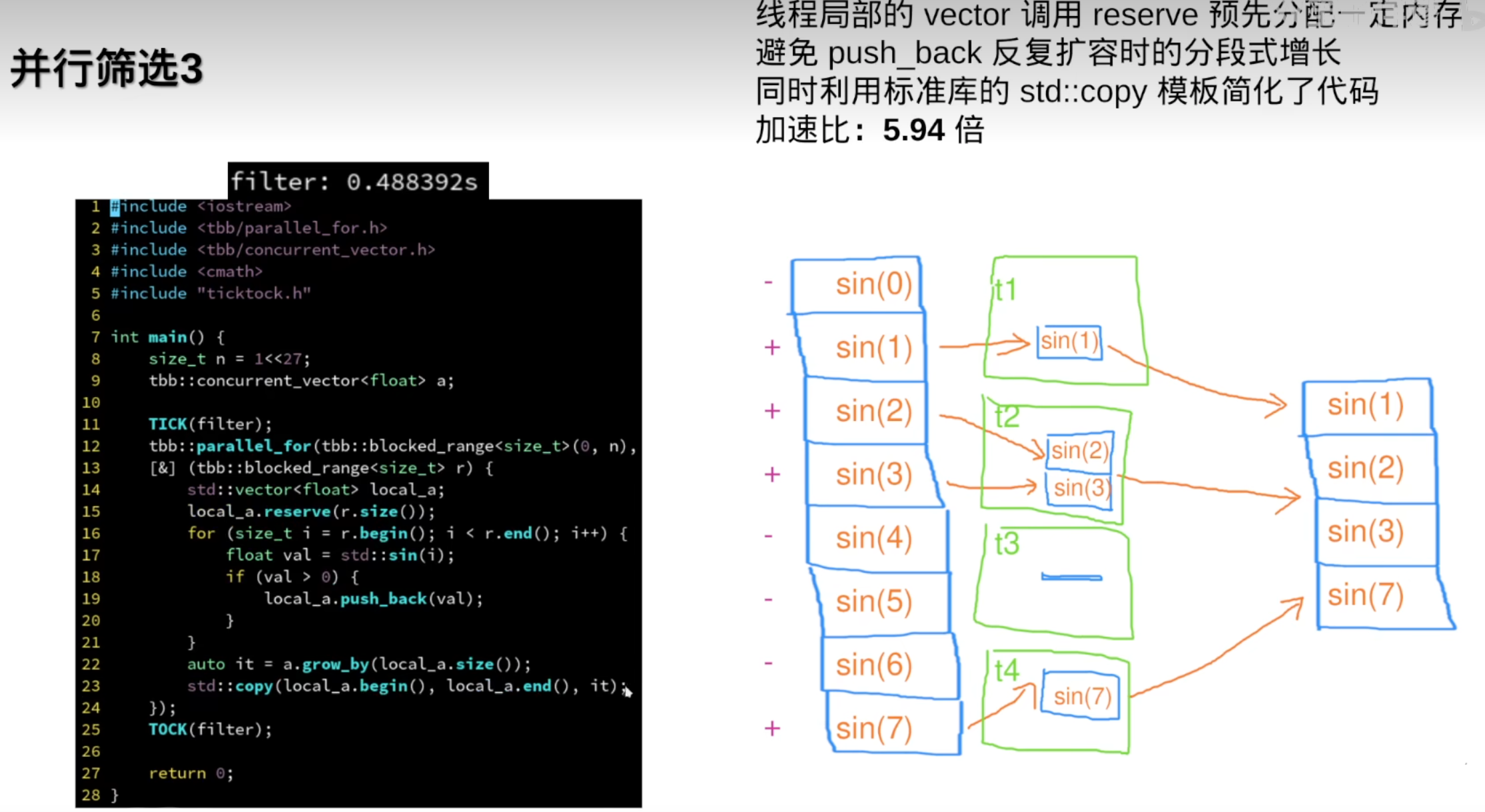
但需要连续数据时,还是需要std::vetor
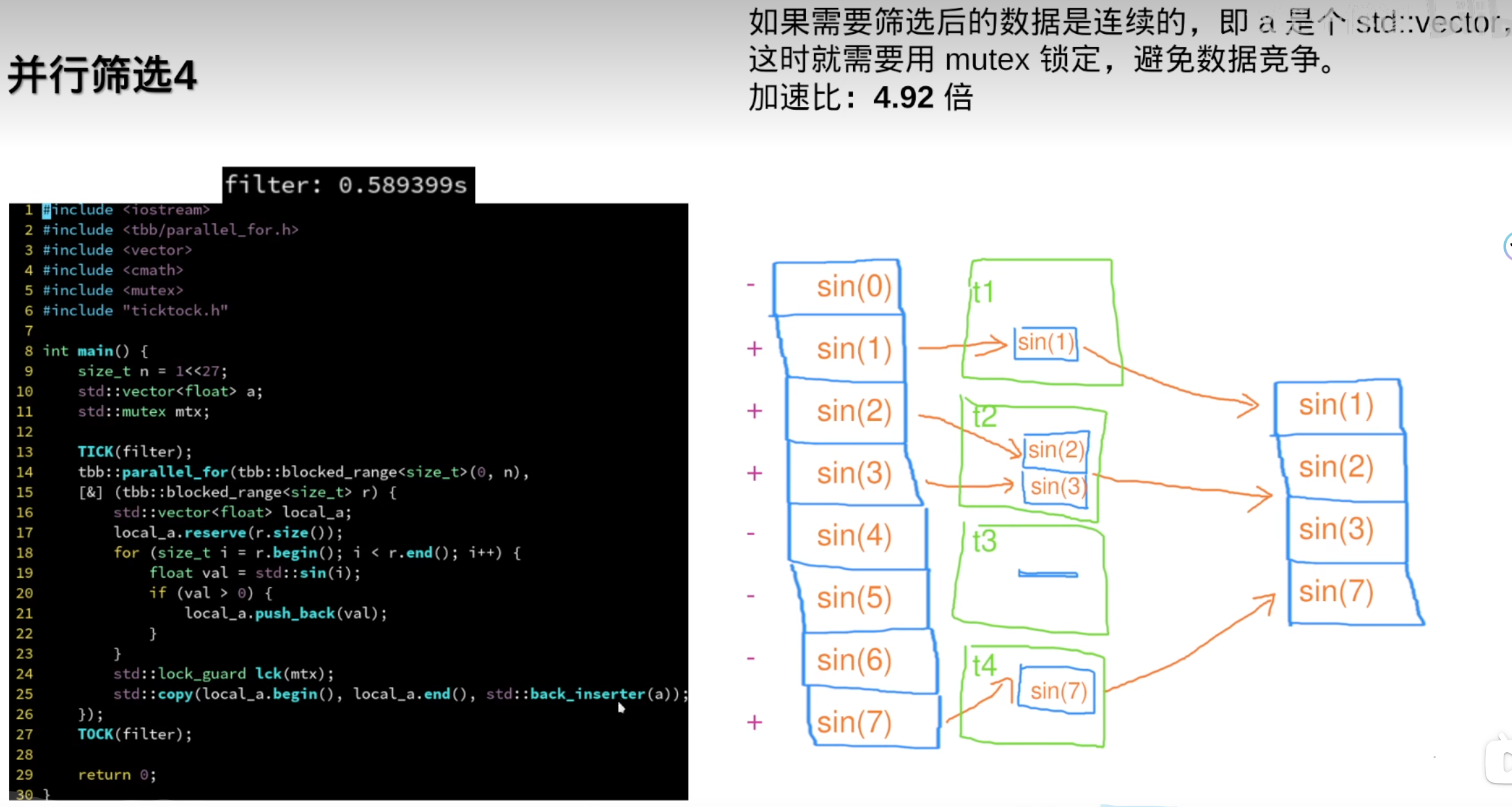
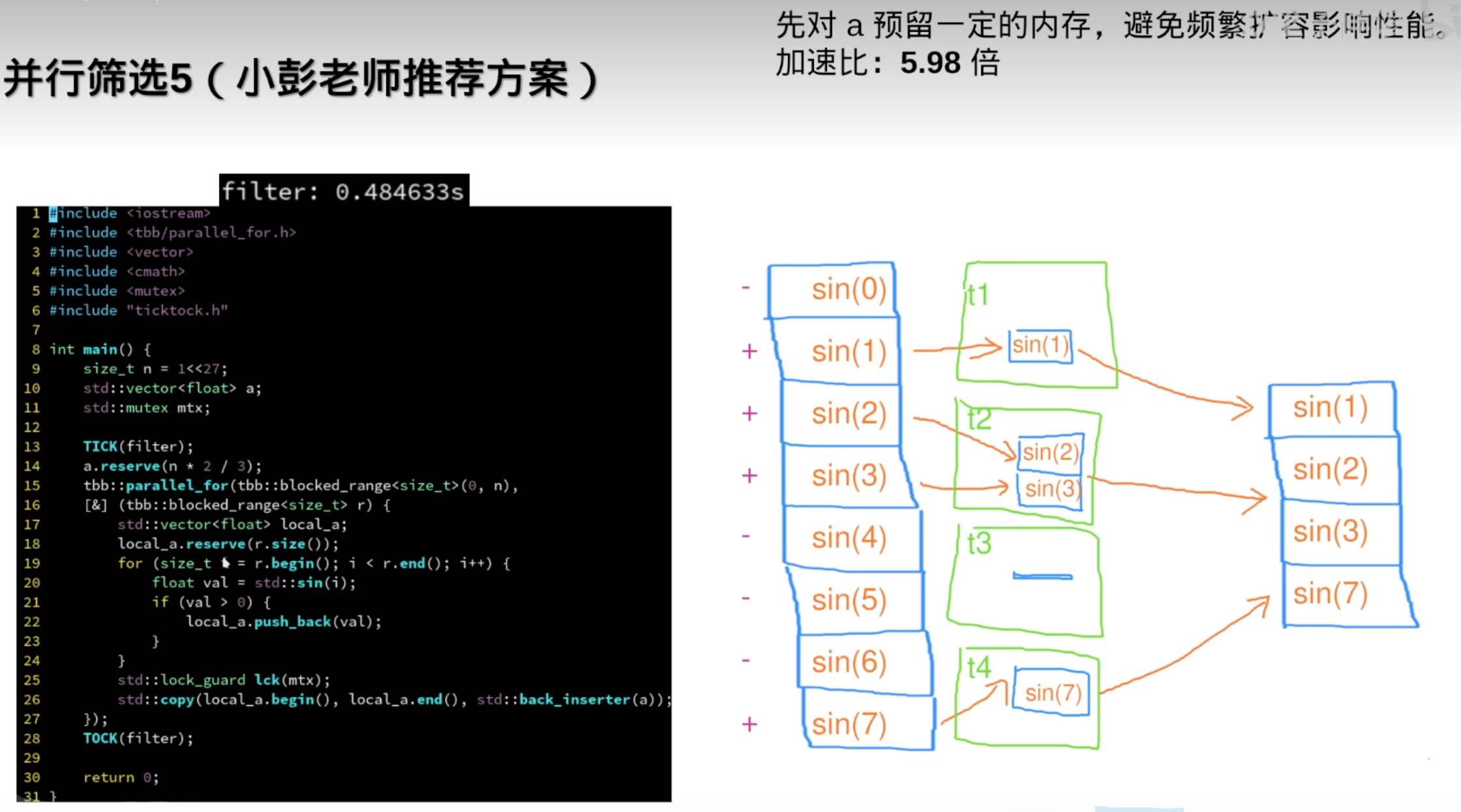
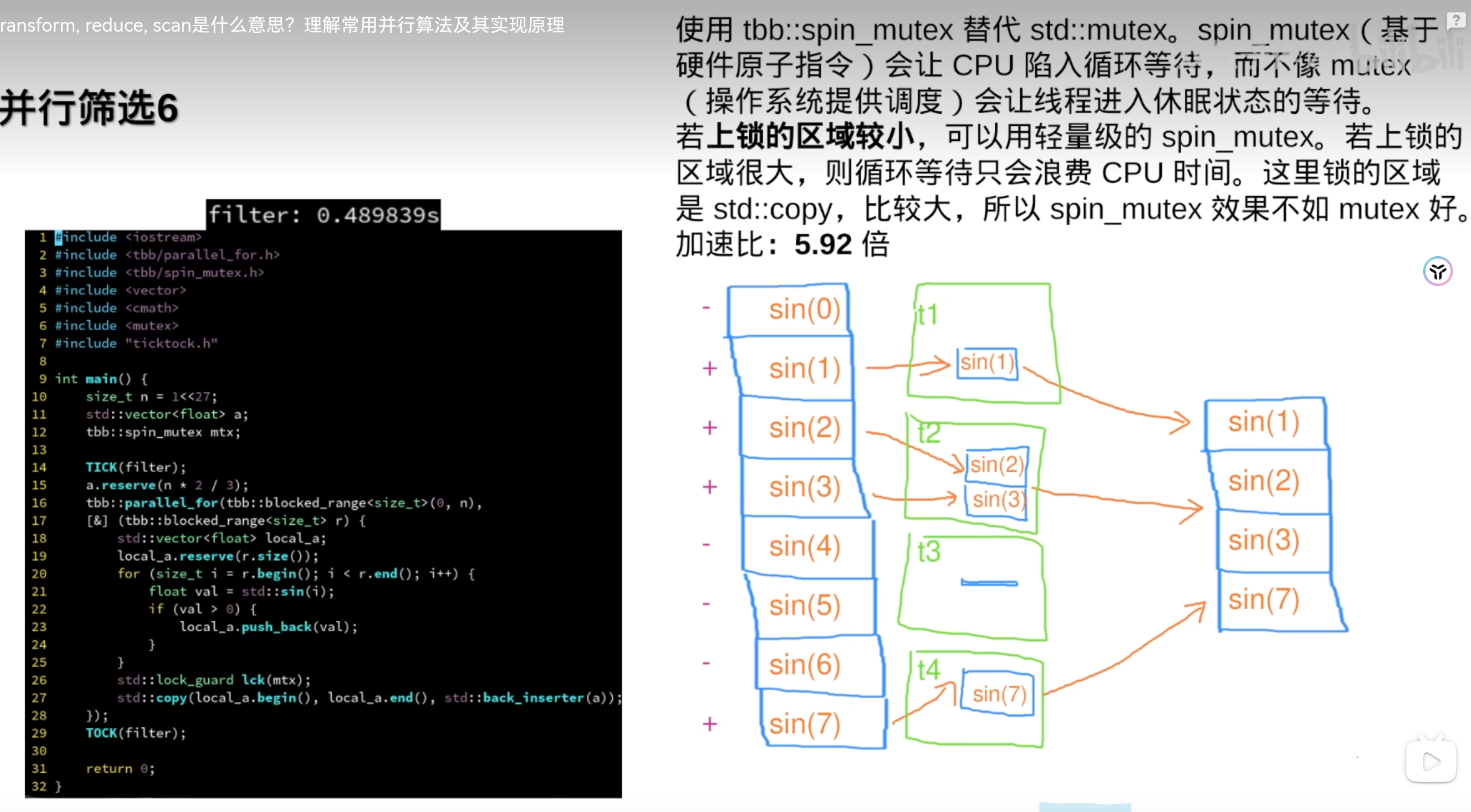
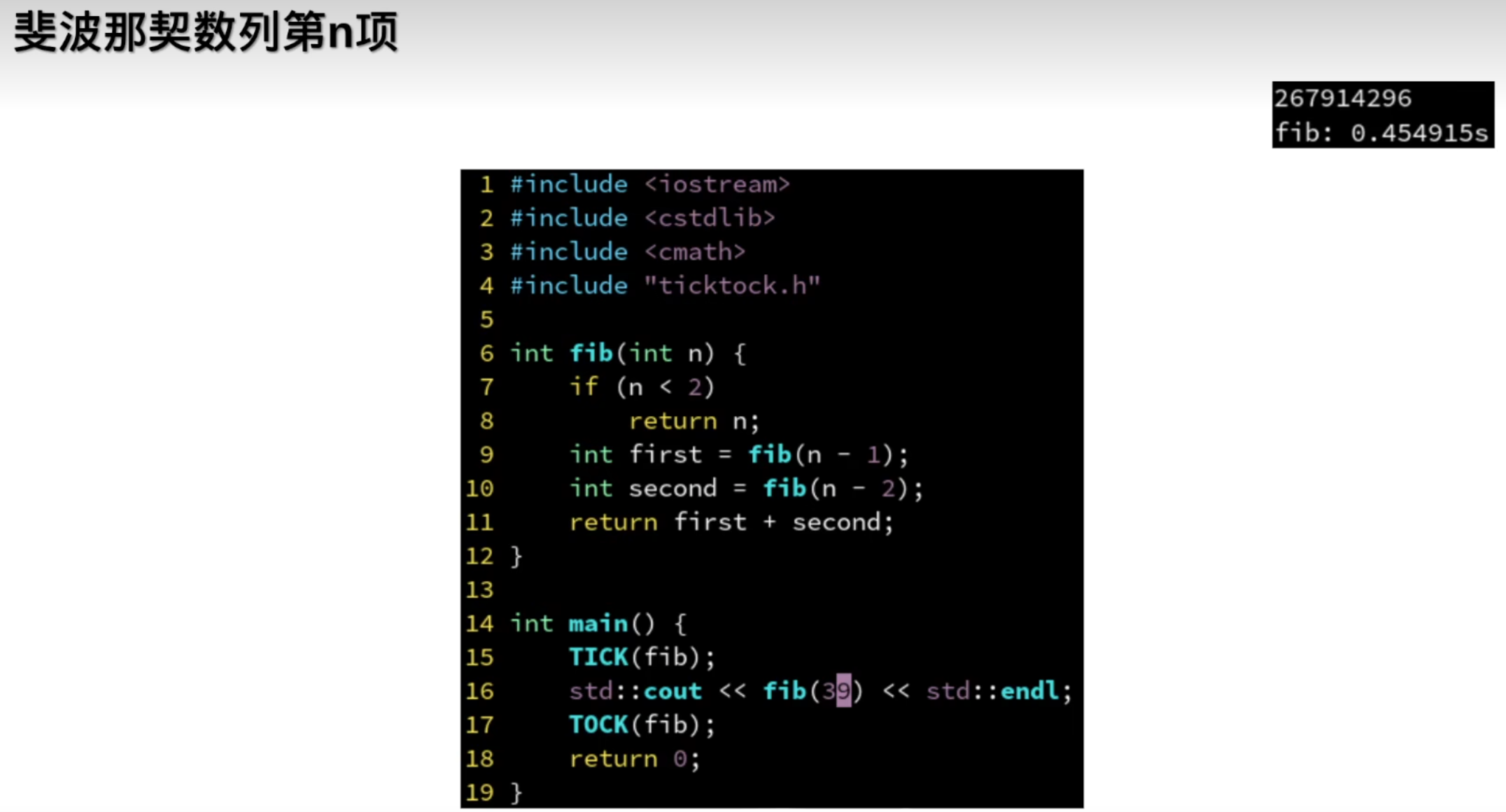
反而变慢了:
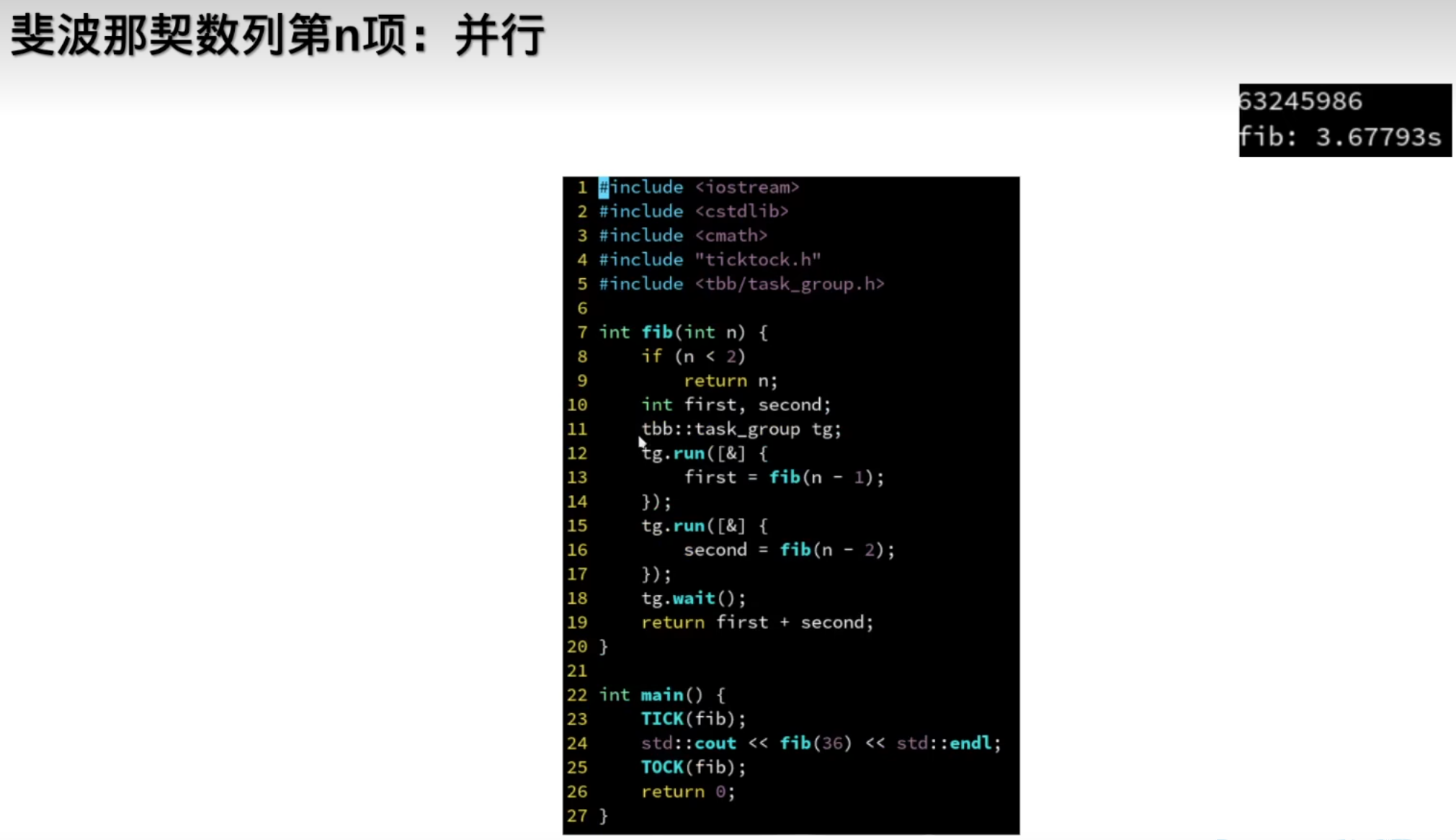
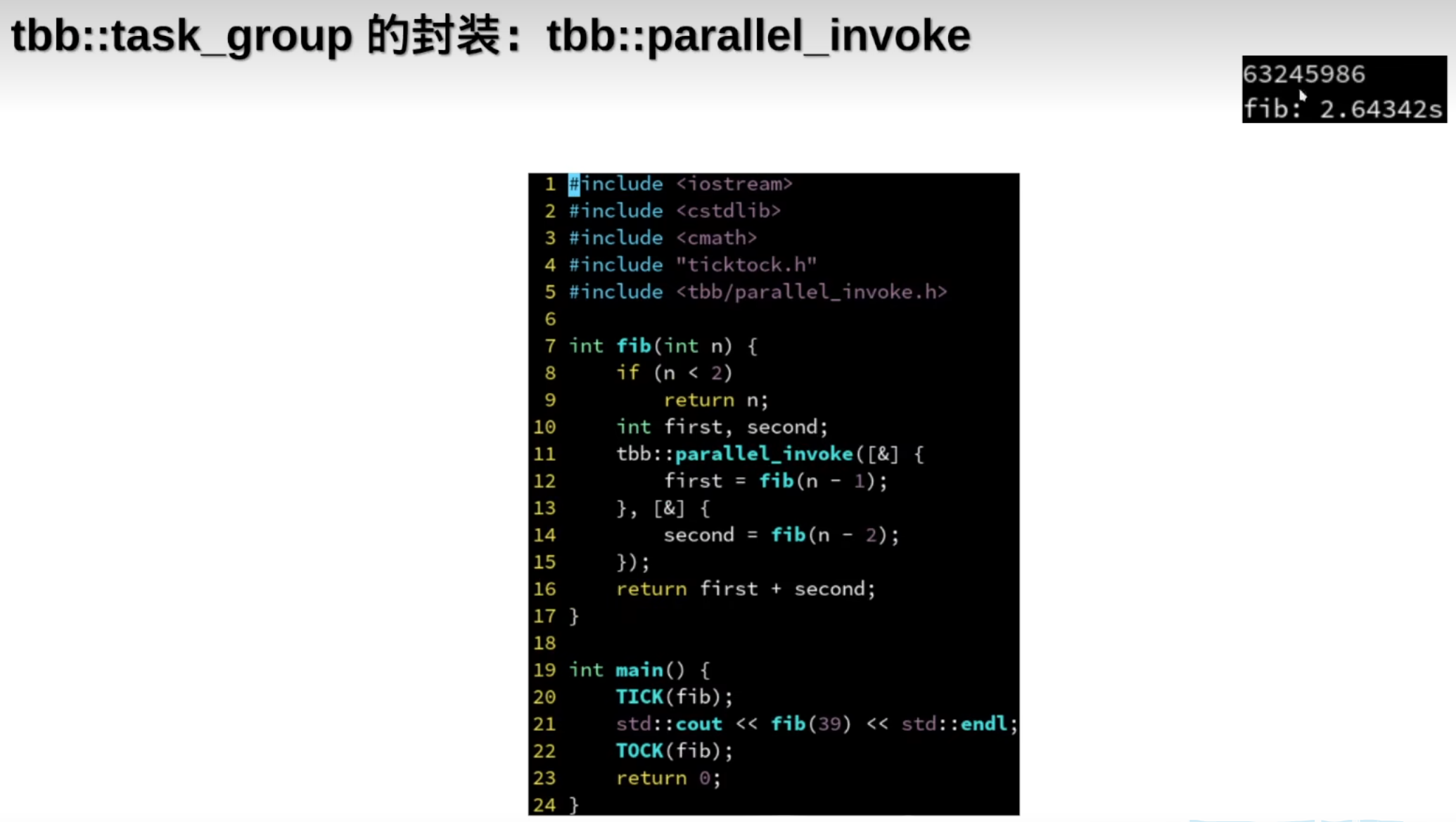
分治

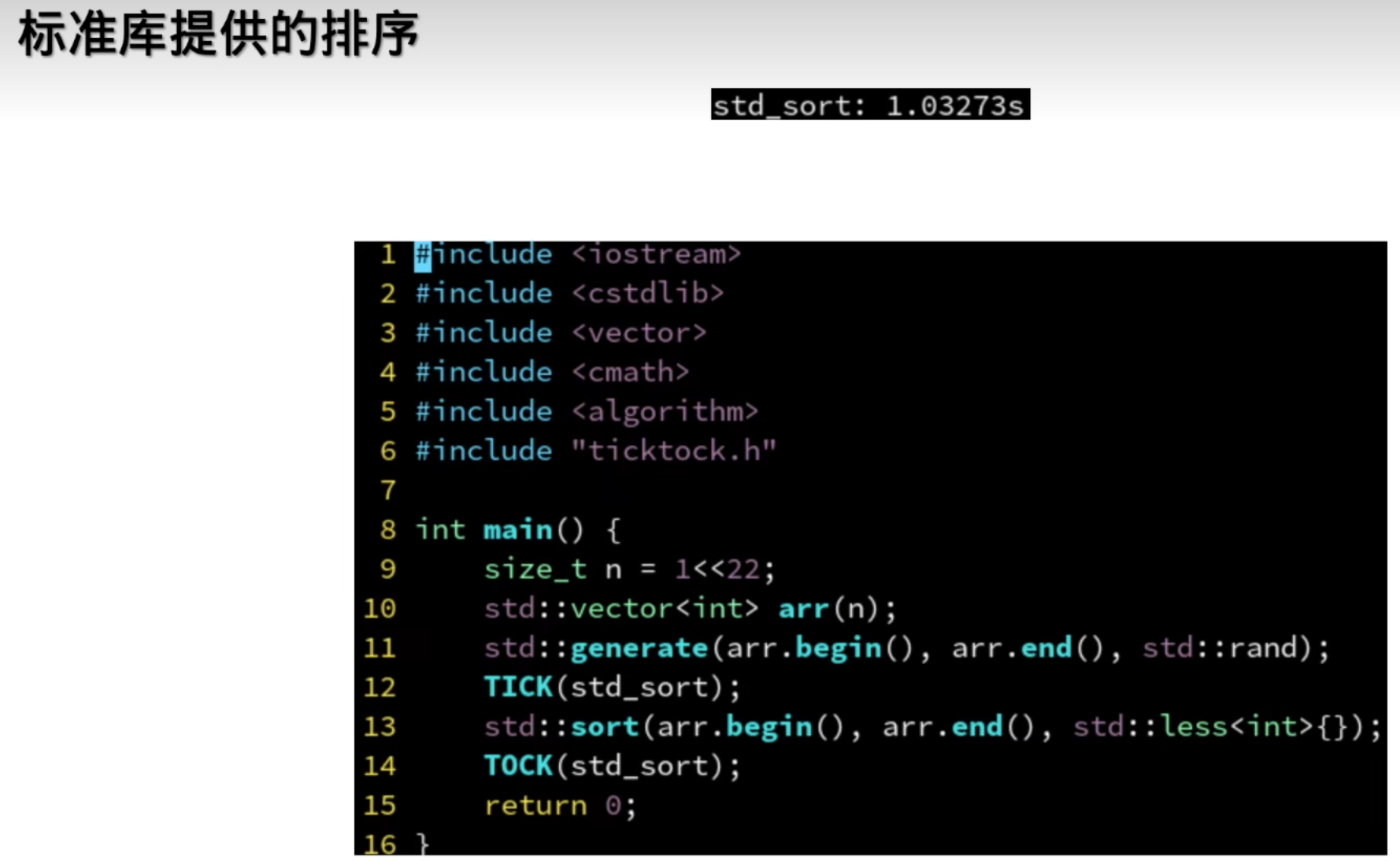
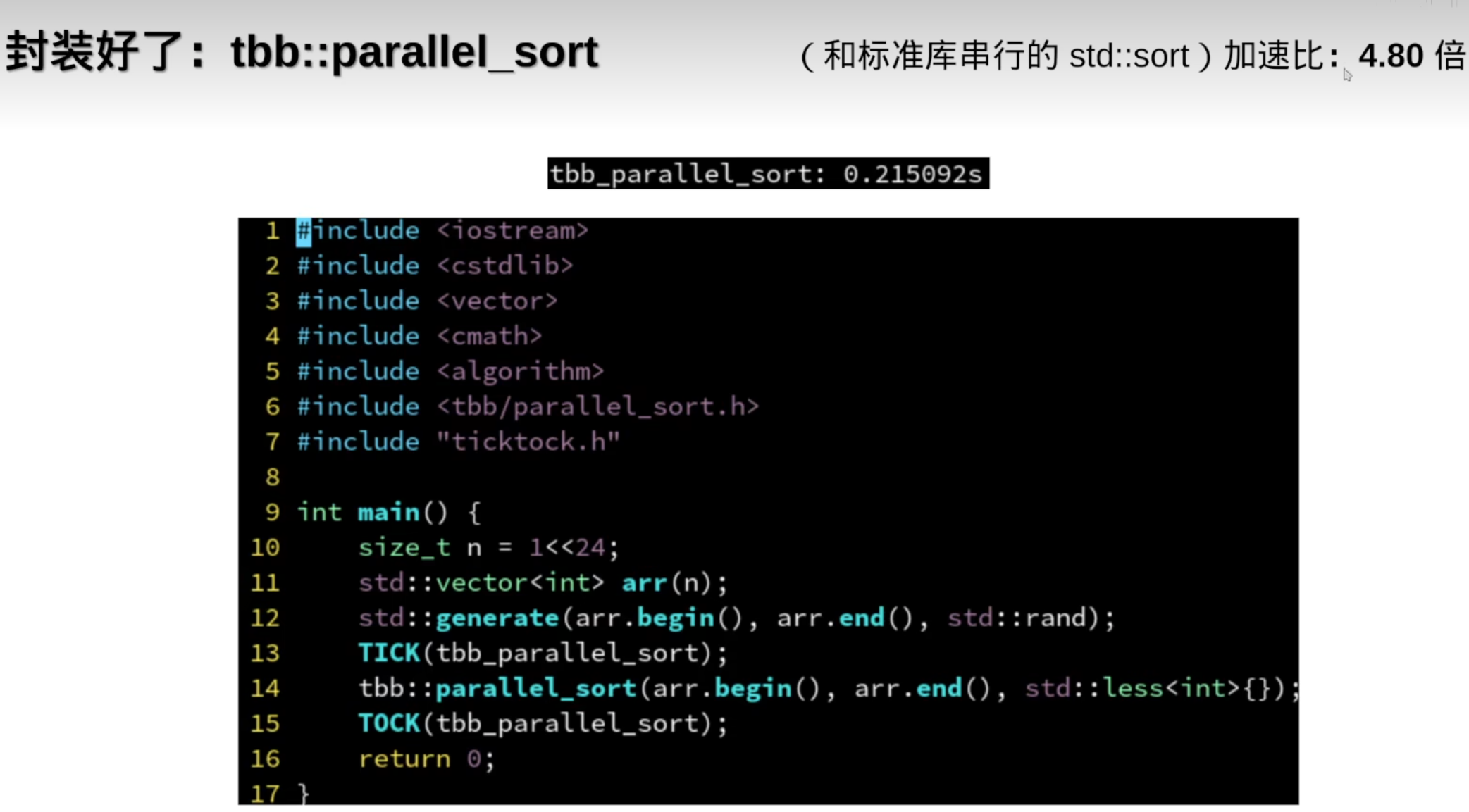

类对象的声明
ThreadPool threadPool {}; 和 ThreadPool threadPool; 的主要区别在于初始化方式:
ThreadPool threadPool {};ThreadPool 类的默认构造函数。ThreadPool threadPool;ThreadPool 类没有定义任何构造函数,编译器会自动生成一个默认构造函数。ThreadPool 对象并调用默认构造函数。ThreadPool threadPool {}; 更安全,适用于需要避免潜在类型转换问题的场景。不存在这样的写法:ThreadPool threadPool ();
变量的声明
std::atomic_flag flag; 和 std::atomic_flag flag {}; 的效果是相同的,都会将 flag 初始化为未设置状态。不过,使用 {} 的形式更加显式,可能更符合现代C++的最佳实践。
new SimpleTask() 和 new SimpleTask 在功能上是等价的,都是创建一个 SimpleTask 对象并返回指向该对象的指针。
非常量左值引用问题
const T&)可以绑定到临时对象,而非常量左值引用(T&)则不能。glm::vec3 setPixel(size_t x,size_t y,glm::vec3 &pixel){
return pixels[width*y+x]=pixel;
}
film.setPixel(y,x,glm::vec3(0.5,0.4,0.3));
Non-const lvalue reference to type 'vec<...>' cannot bind to a temporary of type 'vec<...>'
或者
film.setPixel(y,x,{0.5,0.4,0.3});
Non-const lvalue reference to type 'glm::vec3' (aka 'vec<3, float, defaultp>') cannot bind to an initializer list temporary
改为:
glm::vec3 setPixel(size_t x,size_t y,const glm::vec3 &pixel){
return pixels[width*y+x]=pixel;
}
QWidget 和 QMainWindow 是 Qt 框架中的两个重要类,它们都用于创建图形用户界面(GUI),但有一些关键的区别:
QWidgetQWidget 是 Qt 中所有用户界面对象的基类。它提供了一个基础的窗口部件,其他窗口部件(如按钮、文本框)都是从 QWidget 继承而来的。QWidget 本身是一个通用的窗口部件,没有特别的窗口管理功能。它可以作为窗口的基础组件,也可以作为其他复杂组件的容器。QWidget 提供了布局管理功能,可以使用布局管理器来控制其子部件的位置和大小。QWidget 用作对话框、工具条、或是任何其他需要的窗口部件。如果你只需要一个简单的窗口,QWidget 是一个合适的选择。QMainWindowQMainWindow 是 QWidget 的子类,提供了更丰富的窗口功能和特性。QMainWindow 是设计用于主窗口的类,它提供了菜单栏、工具栏、状态栏和中央窗口区域的支持。这使得它特别适合用于主应用窗口的设计。QMainWindow 提供了特定的布局区域,如菜单栏、工具栏、状态栏和中央部件区域。你可以使用这些功能来创建更复杂的应用程序界面。QMainWindow 是一个理想的选择。它适合用于具有复杂界面的桌面应用程序。QWidget: 基础窗口部件,功能较少,适合用于创建简单的窗口或部件。QMainWindow: 提供额外的功能,如菜单栏、工具栏和状态栏,适合用于主应用窗口。QWidget: 适合用作对话框、工具条、或简单的窗口部件。QMainWindow: 适合用于需要复杂用户界面的主窗口。QWidget: 你需要手动设置布局。QMainWindow: 提供了内置的菜单栏、工具栏、状态栏和中央部件区域,可以直接使用这些功能来设计主窗口界面。connect(menu, &QMenu::triggered, this, &Widget::onMenuTriggered); 为什么QMenu* menu;时不报错 当QMenu menu;时报错:No matching member function for call to ‘connect’
在 Qt 中,connect 函数的作用是将一个信号与一个槽函数连接起来。它依赖于信号发射的对象和槽函数的对象都是有效的,并且能够正确识别和匹配。
QMenu* menuQMenu* menu = new QMenu();
connect(menu, &QMenu::triggered, this, &Widget::onMenuTriggered);
menu 是一个指向 QMenu 对象的指针。connect 函数可以使用 menu 指针来连接信号和槽,因为 QMenu 对象在堆上分配,并且其生命周期由指针管理。QMenu 的实例通过指针能够正确地传递给 connect,并且 QMenu 的成员函数和信号可以被正确识别。QMenu menuQMenu menu;
connect(menu, &QMenu::triggered, this, &Widget::onMenuTriggered);
menu 是一个栈上的 QMenu 对象。connect 时会导致问题,因为 connect 期望信号发射对象在其生命周期内有效。栈上的对象会在超出作用域时被销毁。menu 可能在连接信号和槽时已经过早销毁,导致 connect 函数找不到有效的信号源。QMenu* menu:指针允许动态管理对象的生命周期,connect 可以正常工作。QMenu menu:栈上的对象在超出作用域时可能被销毁,导致 connect 函数不能正确地处理信号和槽。因此,使用指针确保 QMenu 对象在 connect 调用期间有效。
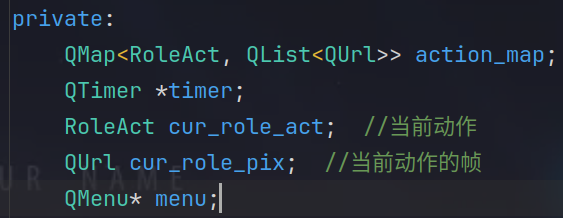
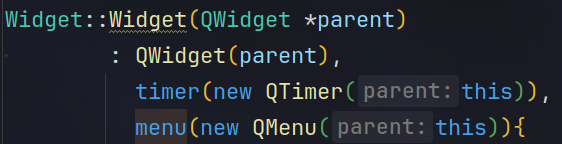
定义对象的指针,让widght来管理对象的生命周期,要是直接定义对象,可能不知道什么时候对象就被销毁了,有些用到这些对象的函数就可能报错,因为在栈上找不到他了
Qstring的用法:
Qstring::number(i)
//把数字变成字符串

3.STL字符串和Qstring字符串转换
std;;string s="qwert";
Qstring::fromStdString(s);
git init
git add .
git commit -m "003class"
git remote add origin git@github.com:Zgh20060114/Qt_Guide.git
git branch -m 003Class
git push -u origin 003Class
手柄:
sudo apt-get install joystick
ls /dev/input/
jstest /dev/input/js0
GLFW 创建一个窗口,并通过它创建一个 OpenGL 上下文。GLEW 来加载系统支持的 OpenGL 扩展。
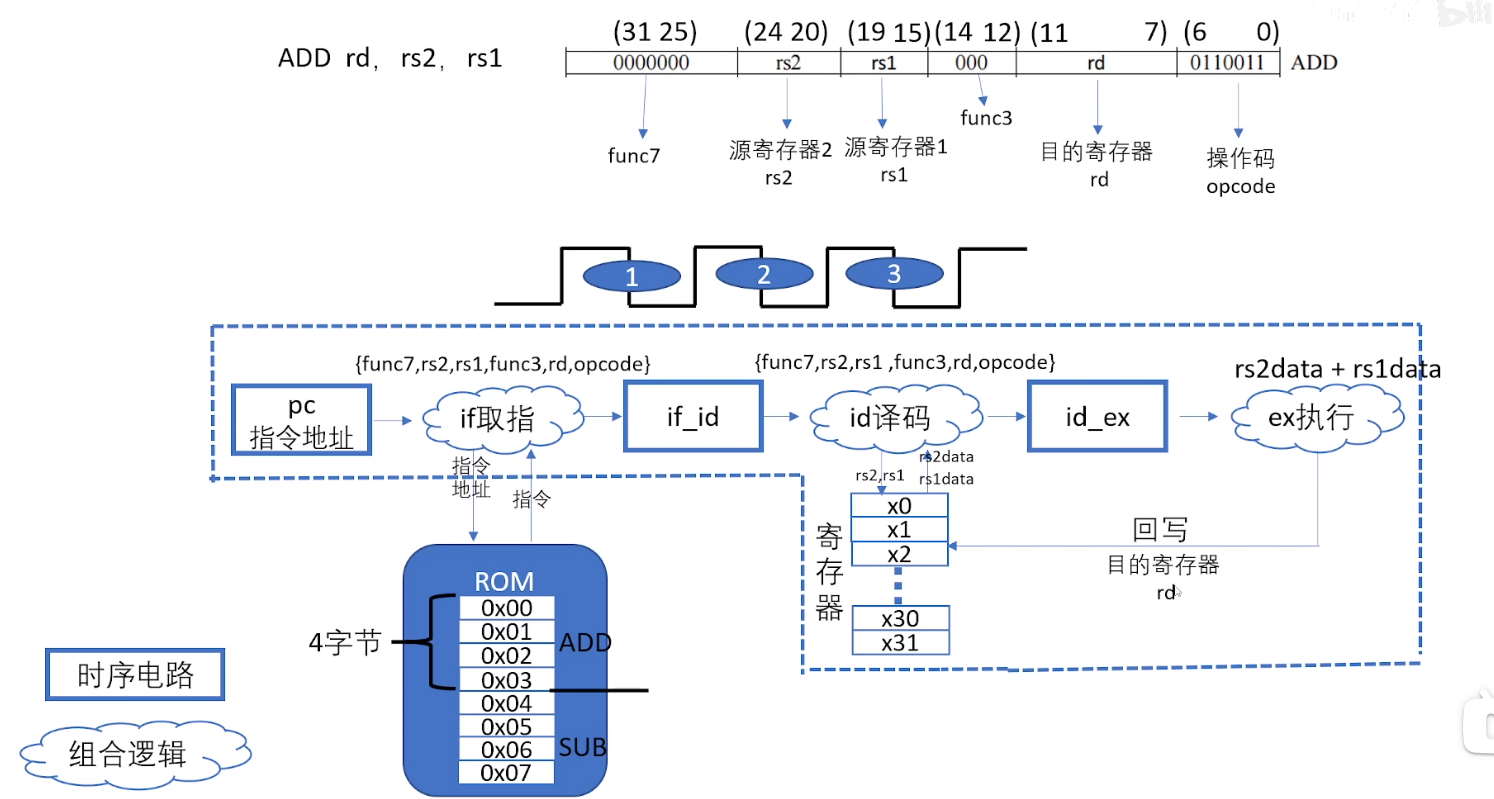
在RISC-V架构中,IF_ID和ID_EX是两个流水线寄存器,用于在指令执行过程中传递数据。
通过使用这些流水线寄存器,RISC-V架构可以实现指令流水线的并行执行,提高指令的执行效率。
在 C++ 中,冒号(:)用于初始化类的成员变量或调用父类的构造函数。这种语法称为成员初始化列表(member initialization list),它允许在构造函数体执行之前对成员变量进行初始化。
在这里,vec3() : e{0,0,0} {} 中的冒号后面就是成员初始化列表。: e{0,0,0} 表示对类的成员变量 e 进行初始化,其中 {0,0,0} 是对数组 e 的初始化值。
double& operator[](int i) { return e[i]; }double&:
double&,即返回一个 double 类型的左值引用。引用和原变量本质上是同一个东西,对引用的修改就是对原变量的修改
double& 表示引用
inline 关键字在C++中用于建议编译器将某个函数的代码在每次调用时直接插入到调用处,而不是进行常规的函数调用。从而可以减少函数调用的开销,尤其是当函数体非常小、调用频繁时,这种优化可能会带来性能提升。
using color = vec3; 这行代码是一个类型别名(type alias)的定义,将 vec3 类型重命名为 color 类型。也就是说,使用 color 关键字可以代替 vec3 类型的使用。
可以看出,我们只需要像步进电机那样不断的重复这六部换向就可以让BLDC转动起来,甚至会产生一种错觉,是不是我们换向越快电机转的越快呢?答案是:否,这里我们一定要认识到,是当转子处于特定位置时才去触发换向操作,换向是被动换向,想要提高转速一定是要提高电流,让定子产生的磁场更强,让转子更快的达到目标点然后触发换向
如何获得转子角度?
我们已经知道了要先检测角度再去换向,那么如何检测当前角度呢?,有以下三种方式。
1.通过安装编码器来计算出当前角度。
2.通过安装霍尔元件计算当前角度。
3.通过检测电流来计算当前角度
编码器方式获取电机当前角度
编码器方式分为两种,增量式编码器和绝对式编码器。
增量式编码器:
每次启动之气都需要做一次校准,而且为了防止单片机性能问题导致脉冲丢失,还需要对编码器每圈校准一次。因此经常使用ABZ三轴编码器,AB输出正交信号,Z轴输出中断。
绝对式编码器:
只需要在出厂之前做一次校准,之后如果没有拆机便不需要校准,通讯方式一般是SPI和IIC,需要考虑通讯时间对系统的影响。
为什么要对编码器进行校准?
因为我们无法保证在安装的时候让编码器的0°(机械角度)刚好对应电机绕组的0°(电气角度)

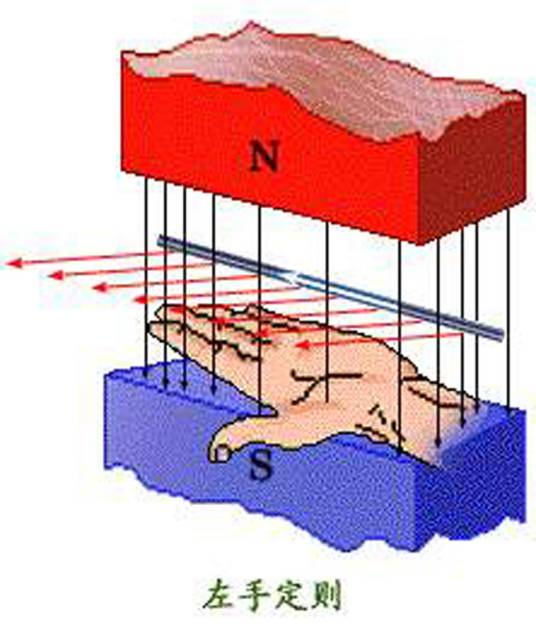
伸开左手,使拇指与其他四指垂直且在一个平面内,让磁感线从手心流入,四指指向电流方向,大拇指指向的就是安培力方向(即导体受力方向)
右手平展,使大拇指与其余四指垂直,并且都跟手掌在一个平面内。把右手放入磁场中,让磁感线从掌心进入(当磁感线为直线时,相当于手心面向N极),大拇指指向导线运动方向,则四指所指方向为导线中感应电流(动生电动势)的方向。
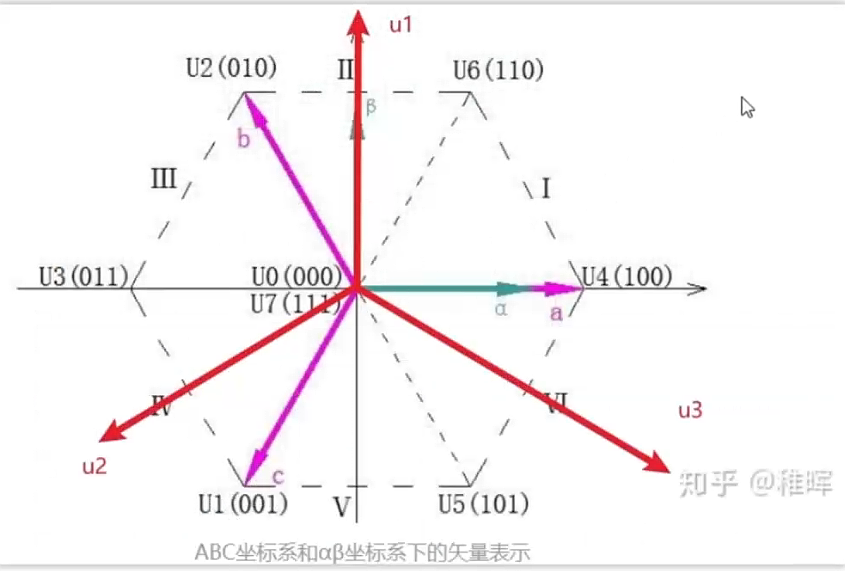
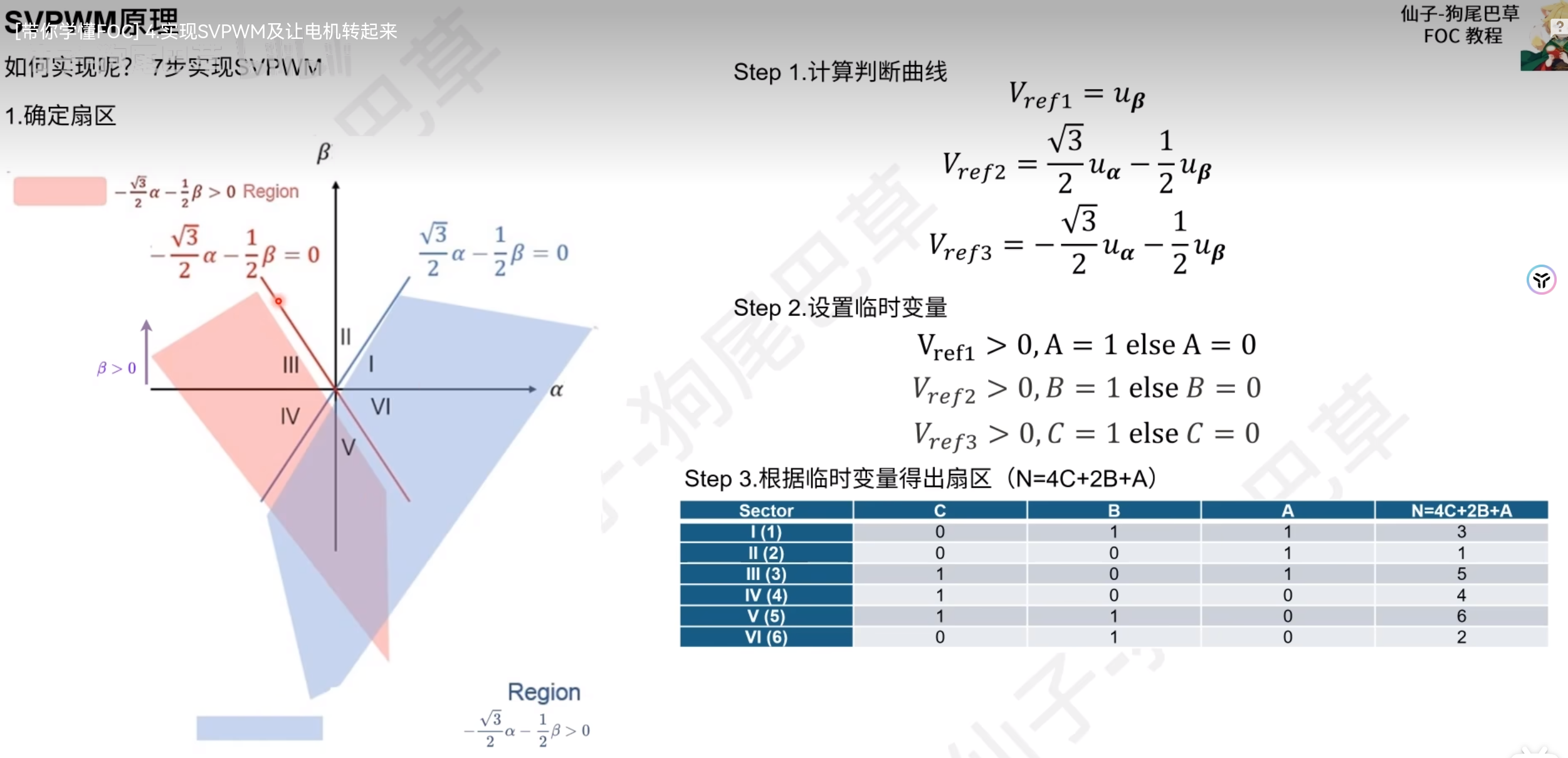
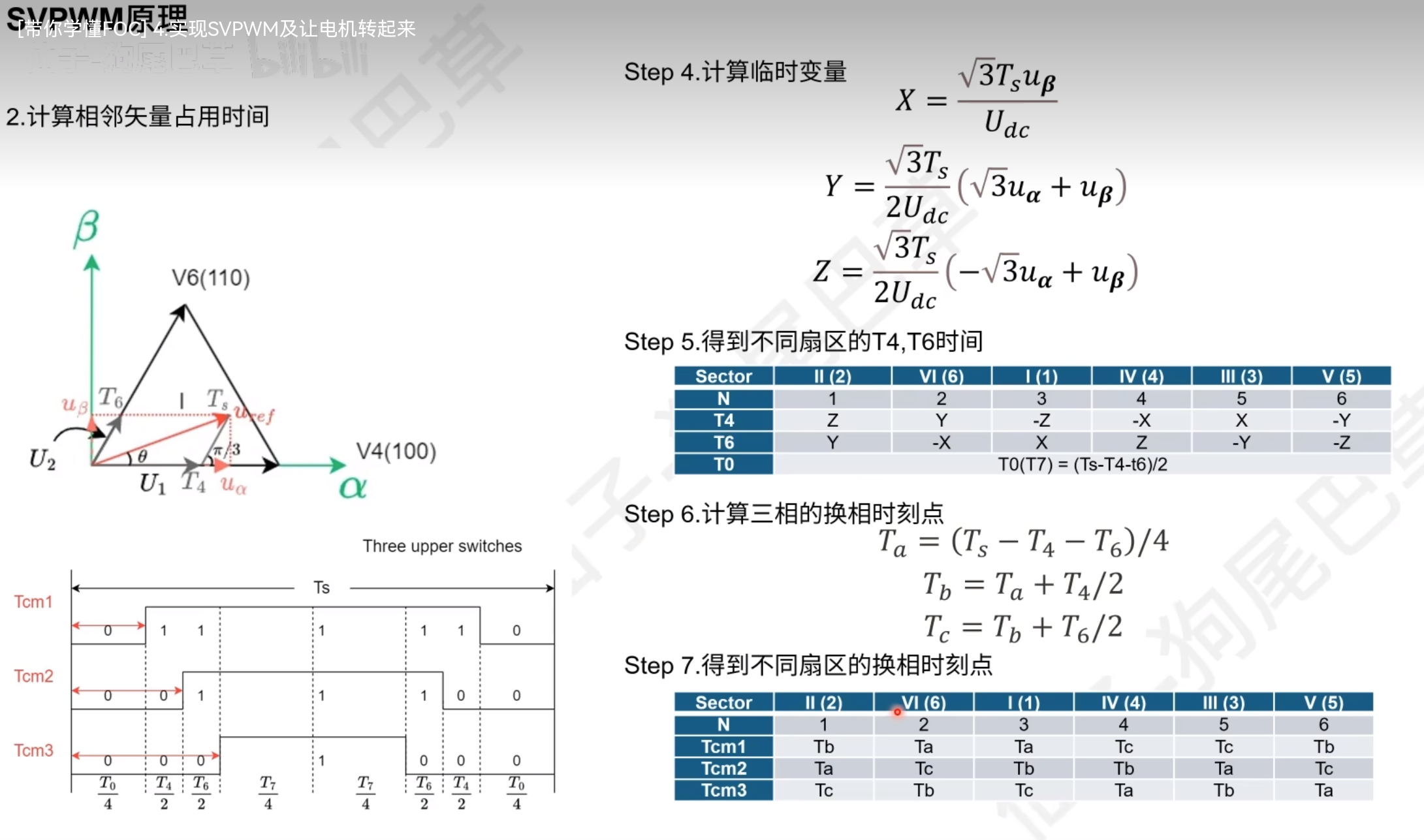
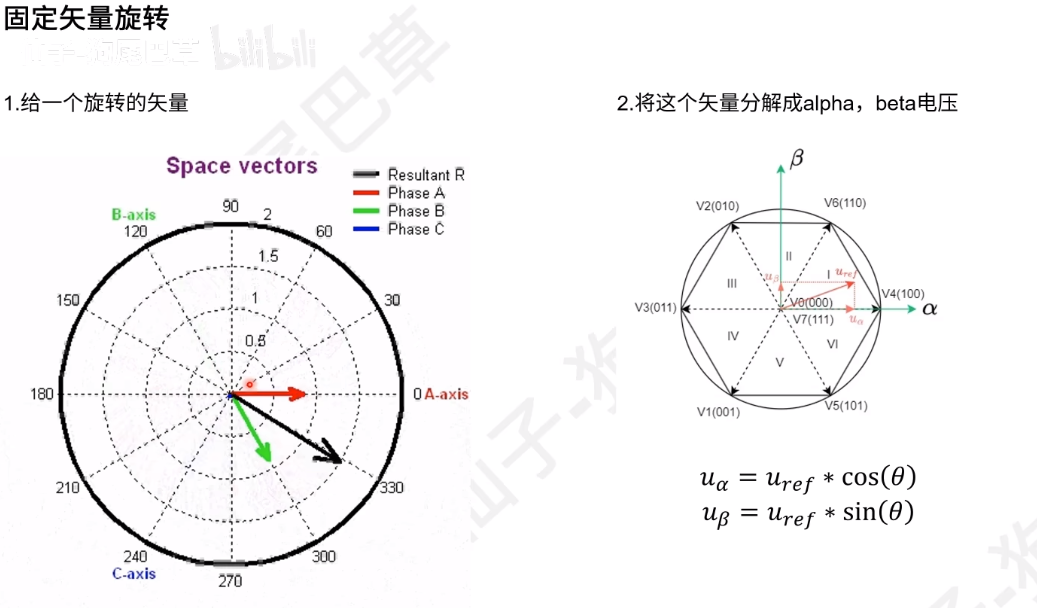
根据想得到的电流矢量到u1,u2,u3上投影的正负,来判断在哪个扇区里,u1,u2,u3可由u_alpha,u_beta表示出
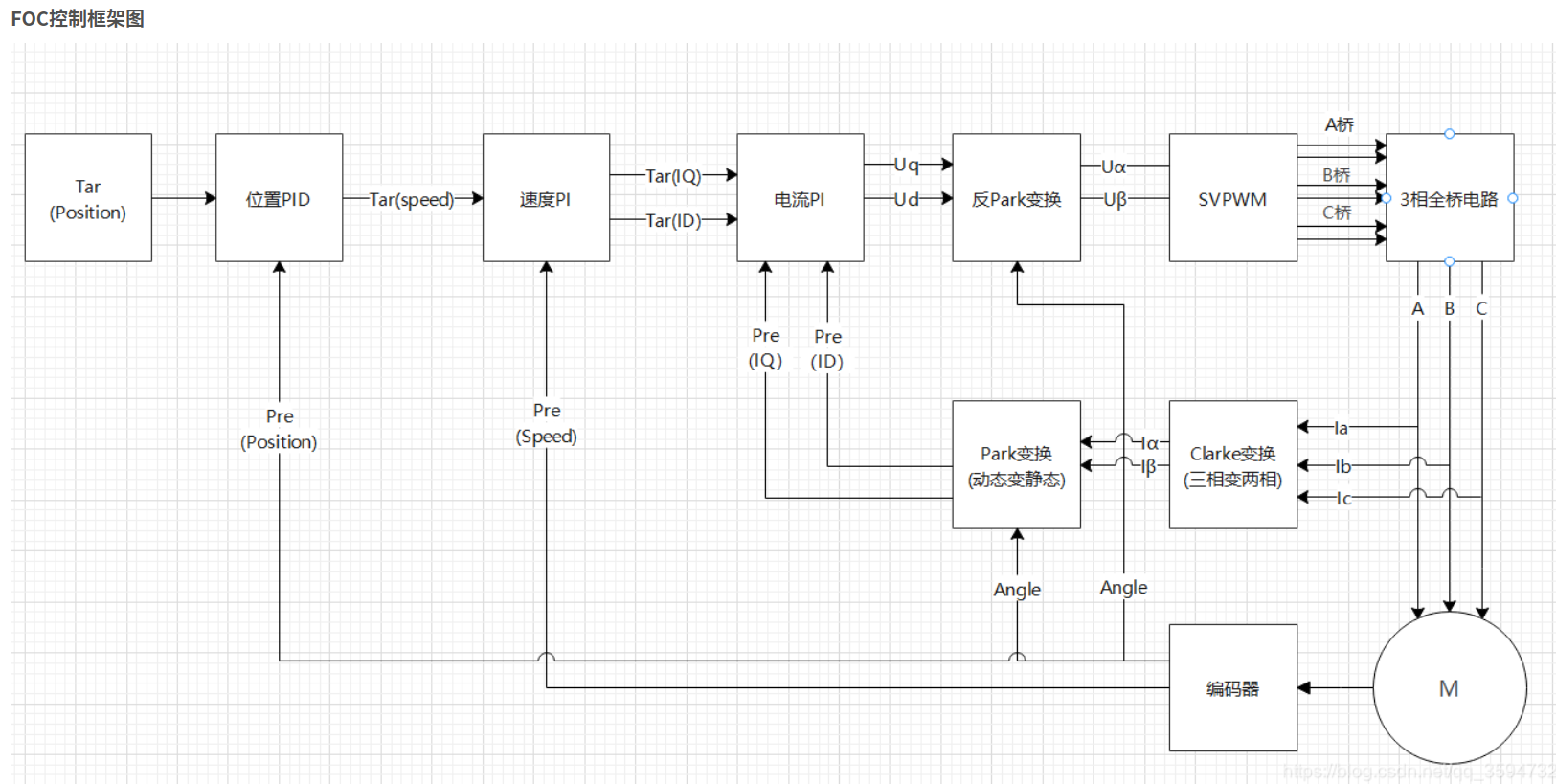
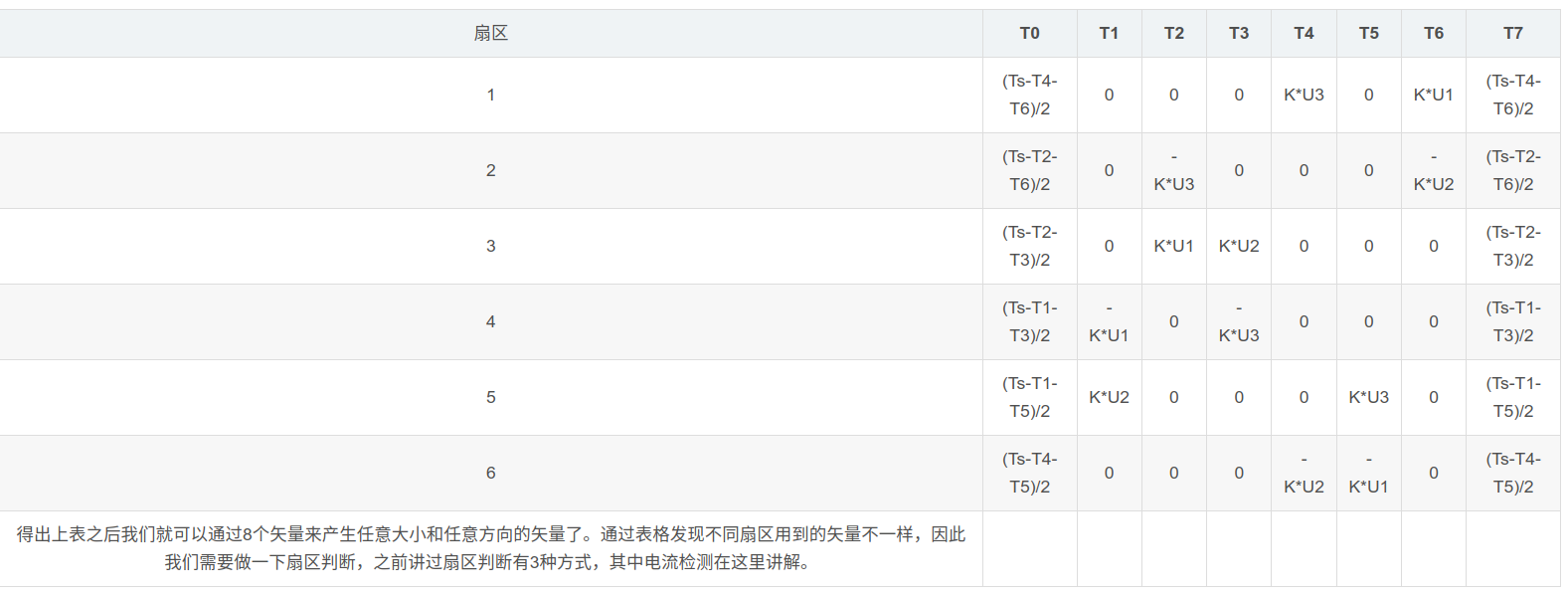
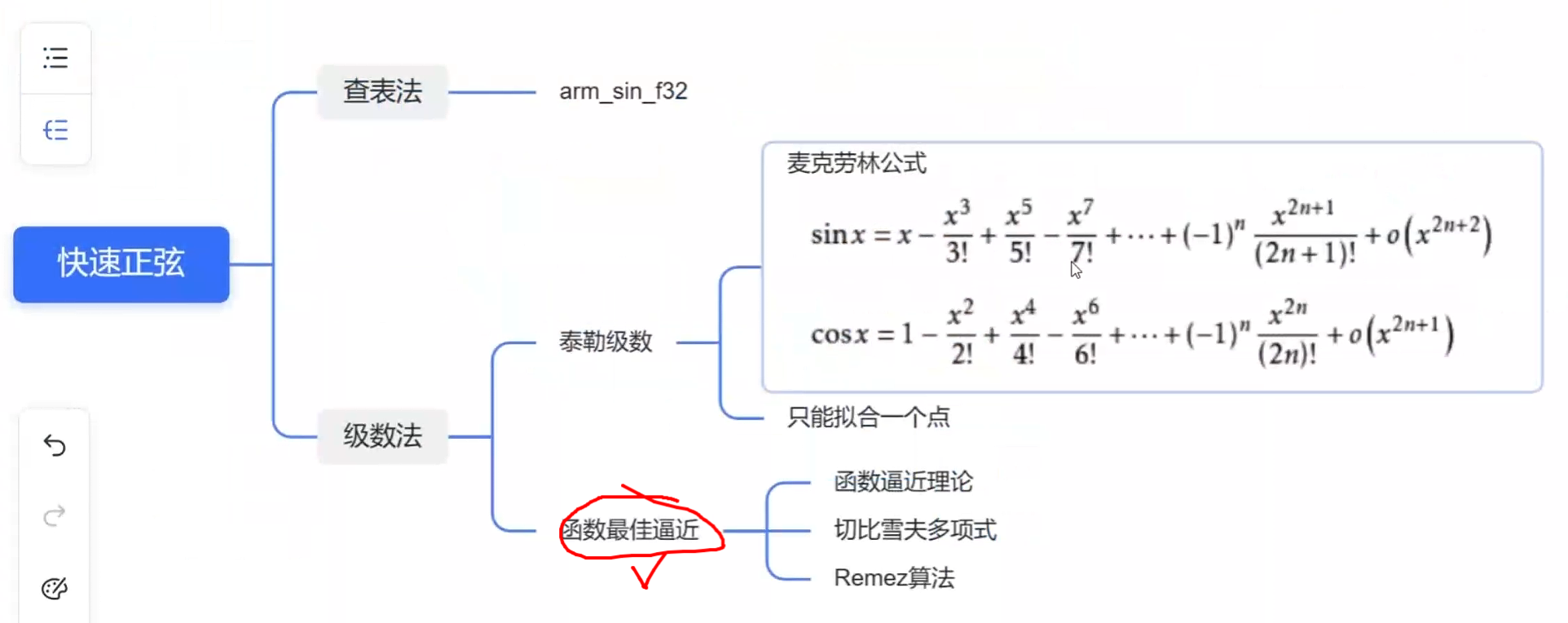

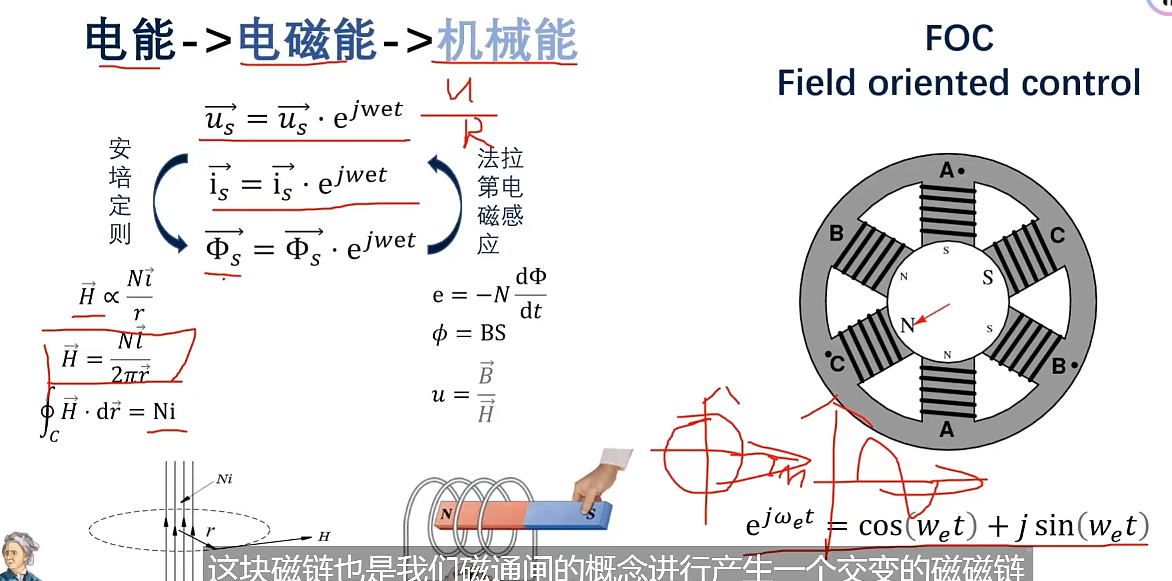
从定子来计算
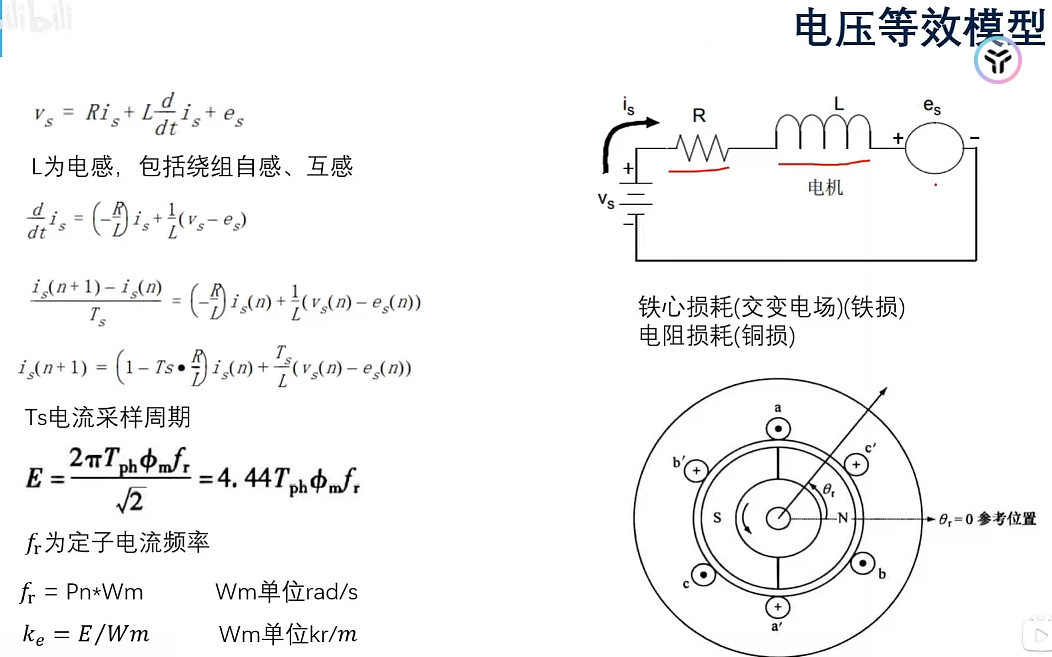 可以计算出反电动势,进而计算转子的速度和位置(无感)
可以计算出反电动势,进而计算转子的速度和位置(无感)
当变压器的初级绕组通电后,线圈所产生的磁通在铁心流动,因为铁心本身也是导体(由硅钢片制成),在垂直于磁力线的平面上就会感应电势,这个电势在铁心的断面上形成闭合回路并产生电流,好象一个旋涡所以称为“涡流”。这个“涡流”使变压器的损耗增加,并且使变压器的铁心发热变压器的温升增加。由“涡流”所产生的损耗我们称为“铁损”。
另外要绕制变压器需要用大量的铜线,这些铜导线存在着电阻,电流流过时这电阻会消耗一定的功率,这部分损耗往往变成热量而消耗,我们称这种损耗为“铜损”。
铁损等于铜损时,变压器效率最高。大概就是变压器额定负荷的0.65倍左右。
从绕组来计算(d,q,轴的电压方程)
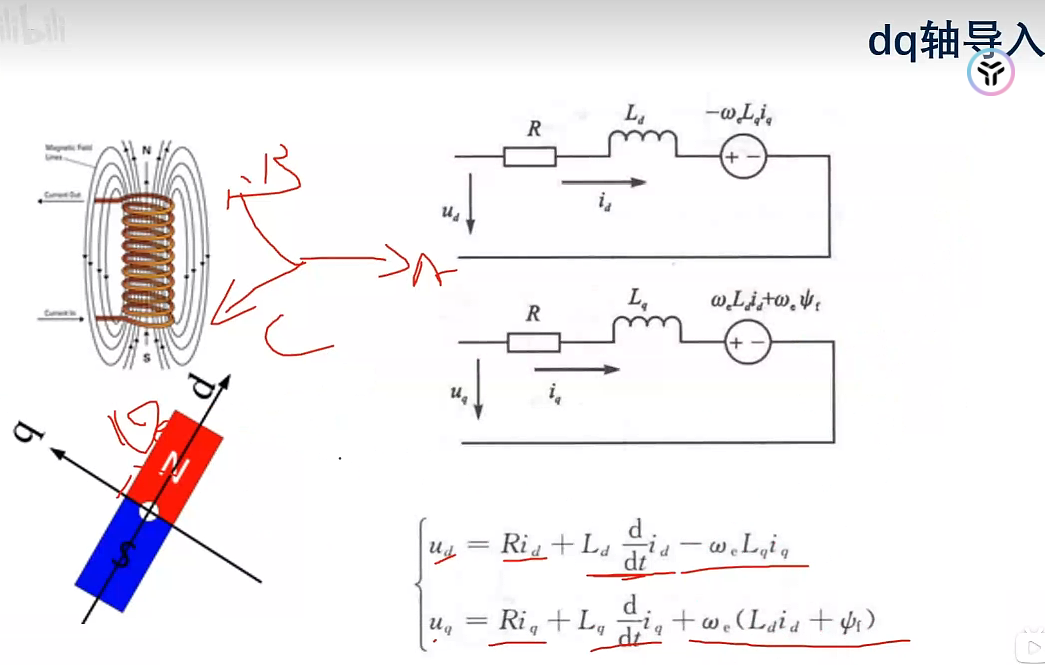
由于定子自感的属性,电流会滞后电压90度
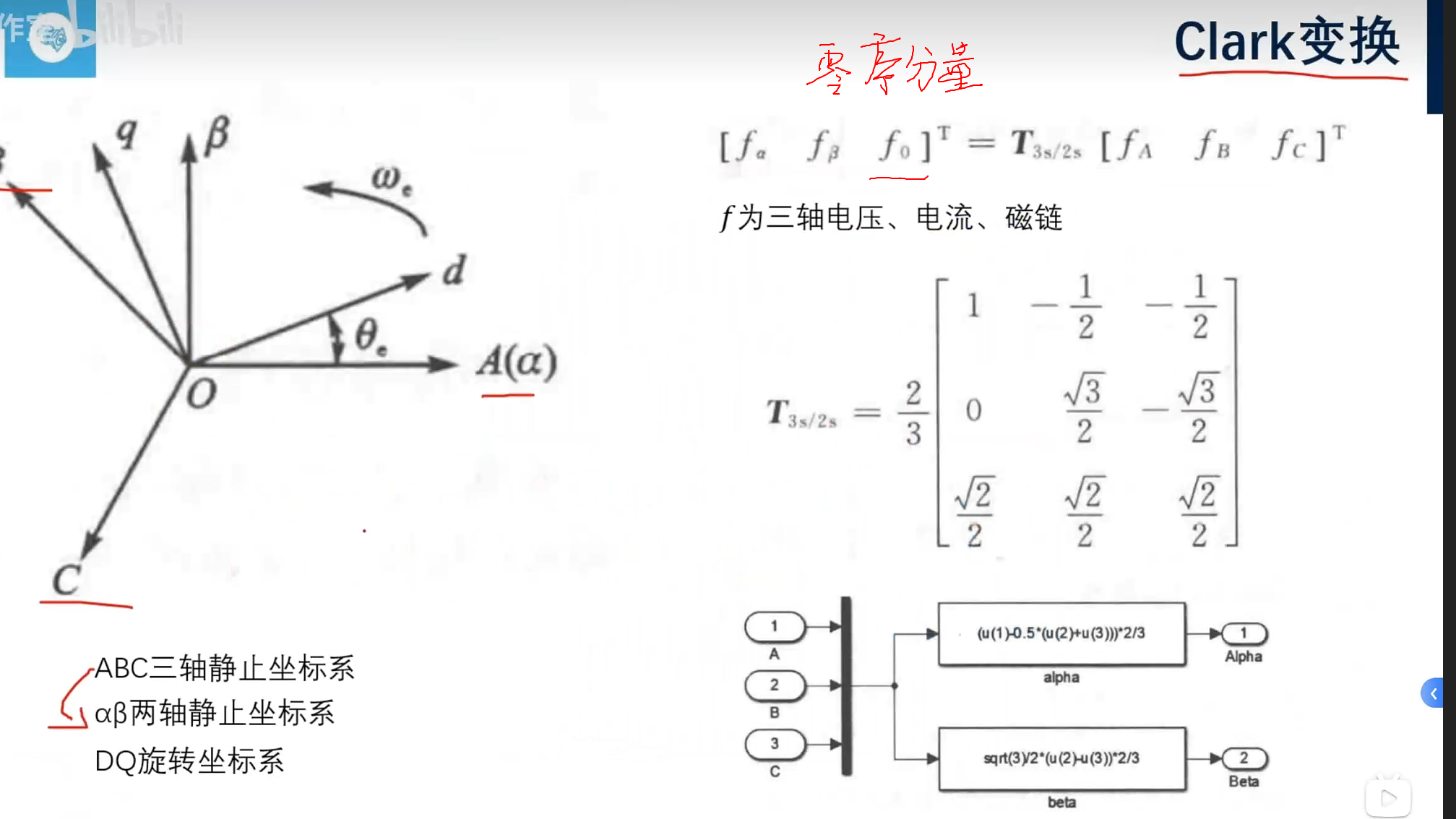
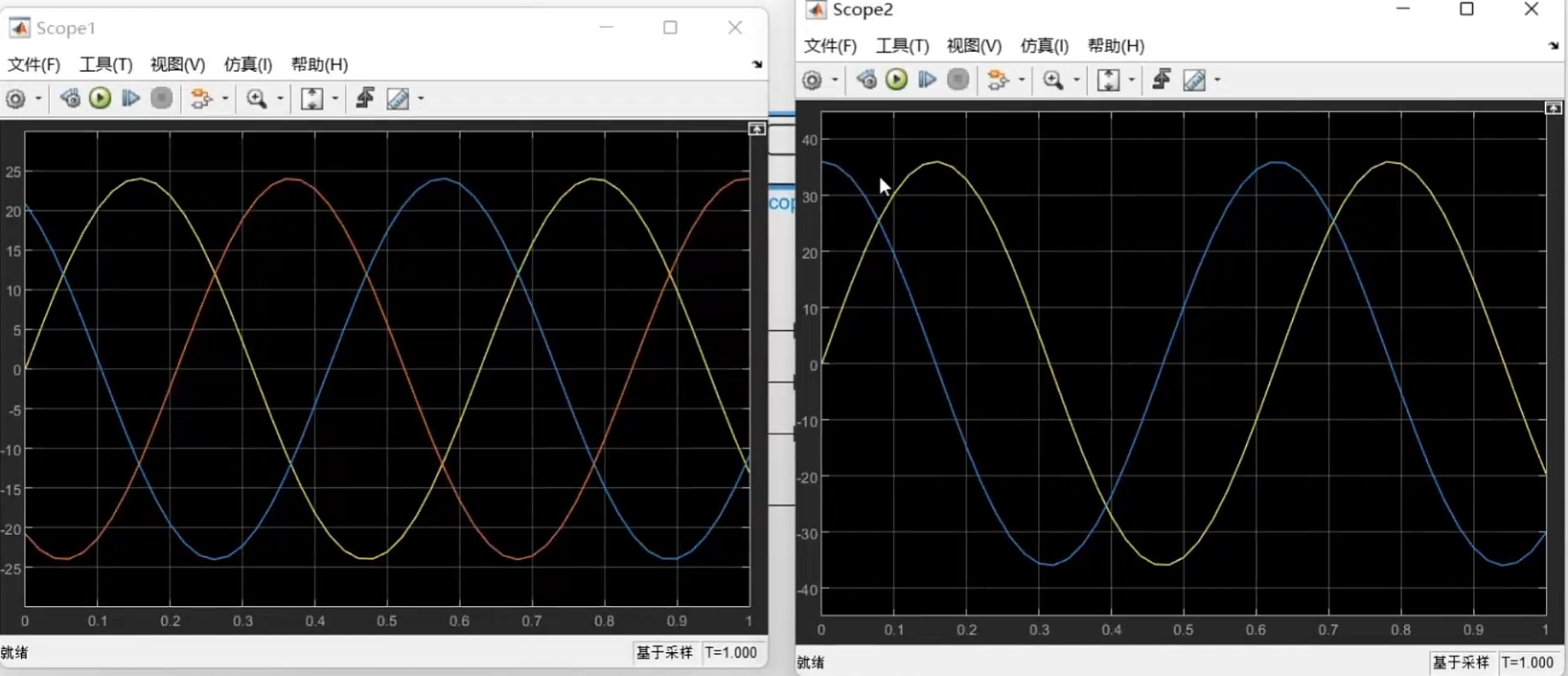
要等幅变换,所以要乘(2/3)
如果遇到乘(根号下2/3),是等功率变换
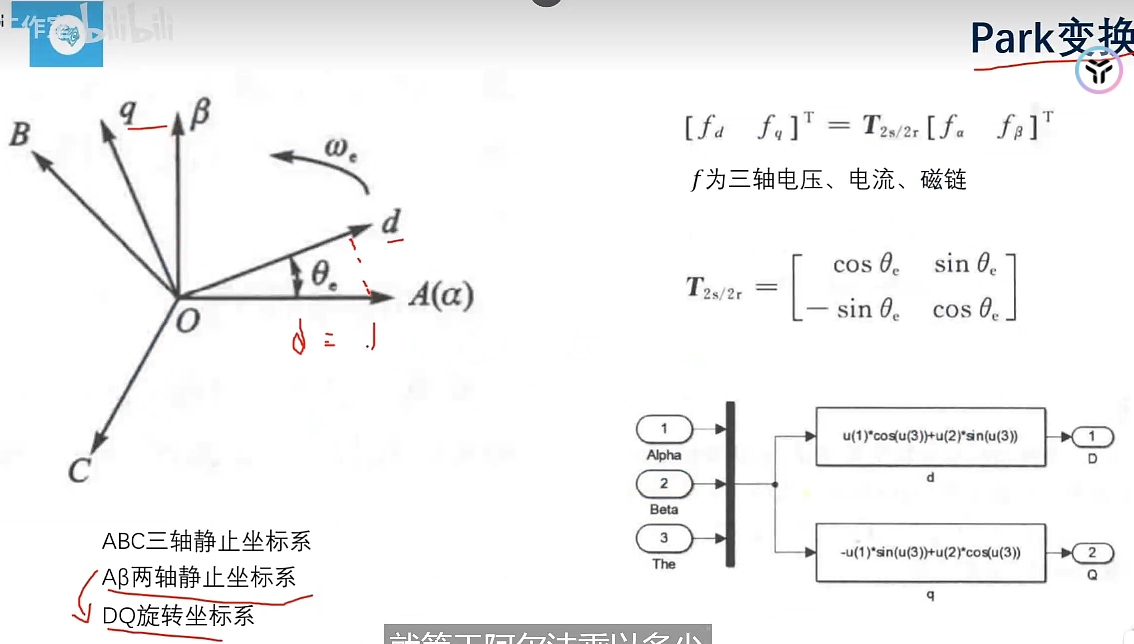


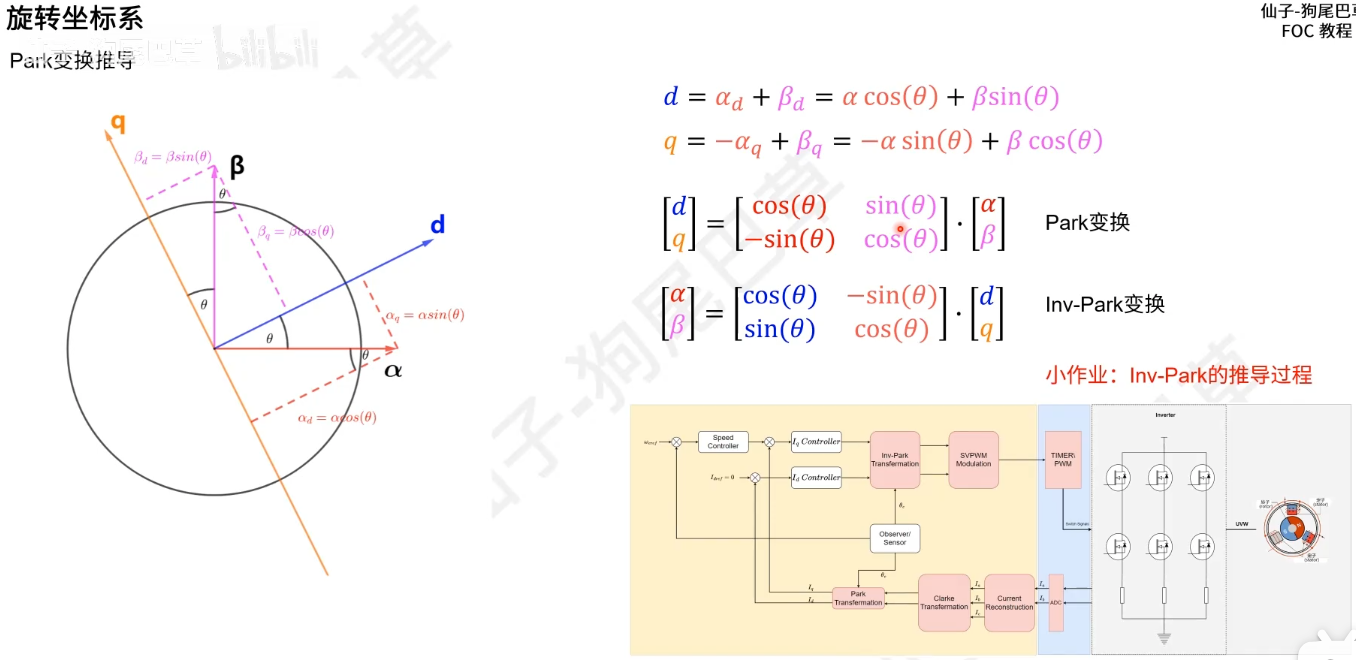
反帕克变换就是对帕克变换旋转矩阵求逆
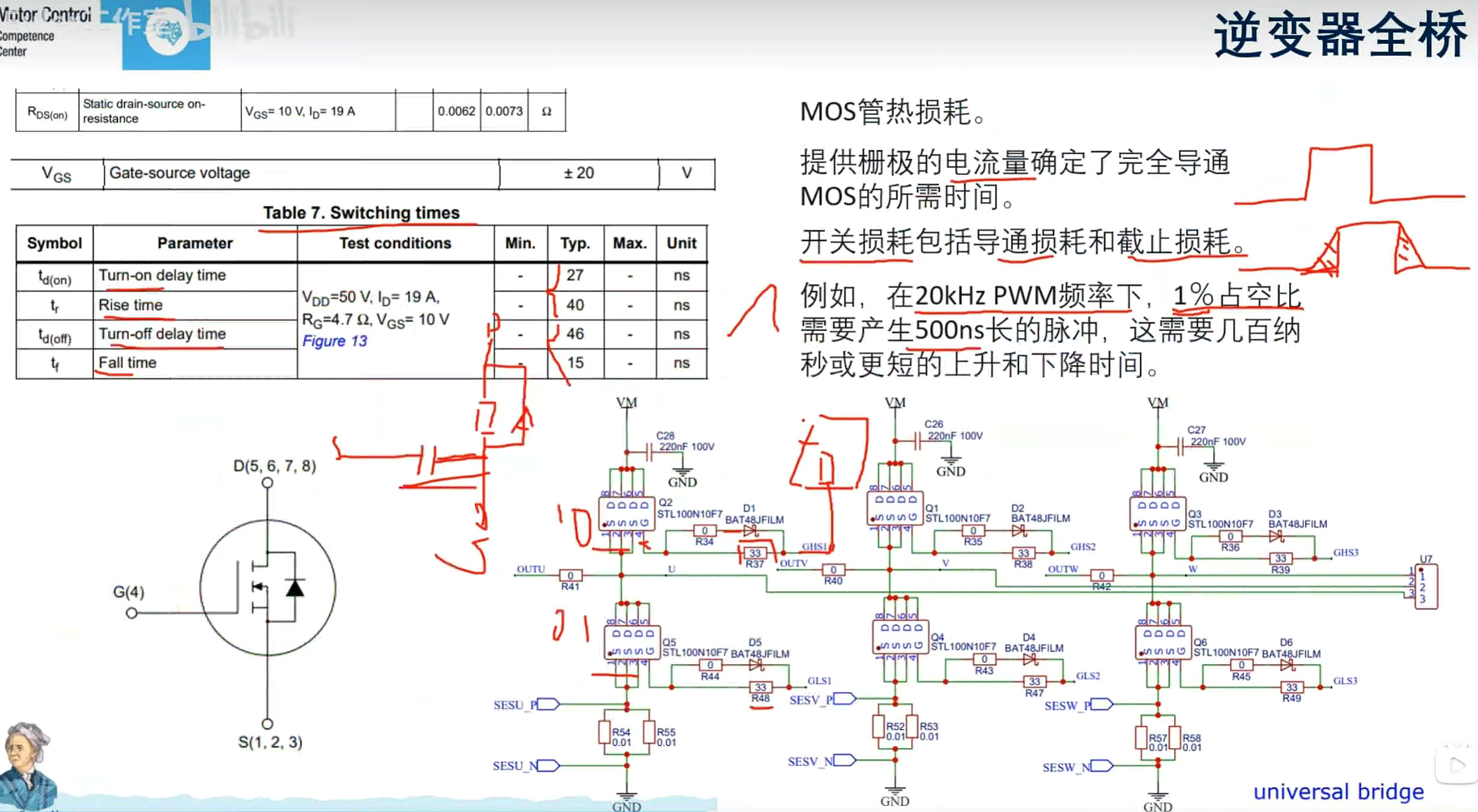
MOS管是电压驱动型,三极管是电流驱动型
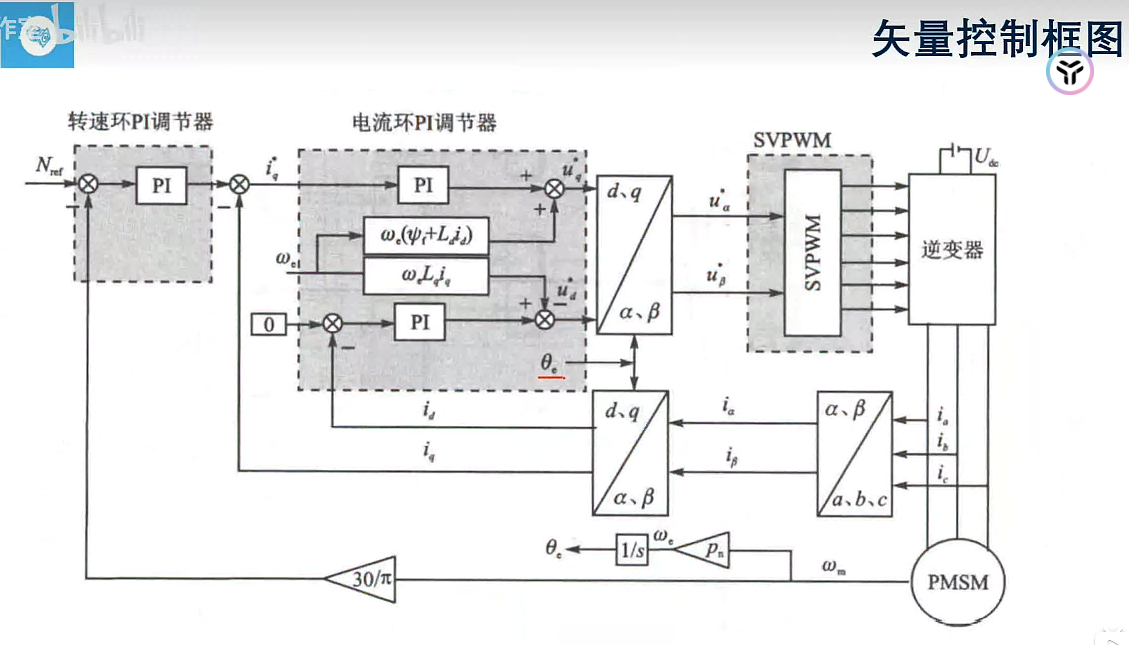
电角度=极对数(或者级数/2)*机械角度
