模版元编程与函数式

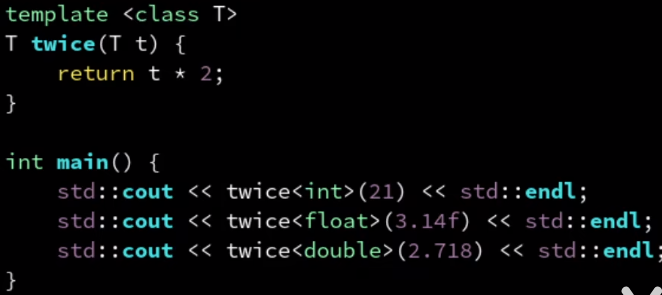
template


std::enable_if 是 C++ 标准库中的一个模板工具,通常用于实现 SFINAE(Substitution Failure Is Not An Error)技术。它位于 <type_traits> 头文件中,用于在模板编程中根据条件启用或禁用模板的实例化。
基本用法
std::enable_if的基本结构如下:template <bool B, typename T = void> struct enable_if { using type = T; }; template <typename T> struct enable_if<false, T> { // 这个结构体是未定义的 };解释
std::enable_if主要有两个模板参数:B:一个布尔值(通常是编译时常量表达式),用于决定type成员是否有效。T:一个默认类型(默认为void),当B为真时,type成员将定义为T。
当
B为真时,std::enable_if的type成员被定义为T。这意味着我们可以使用std::enable_if的type来在模板中进行条件判断。当
B为假时,std::enable_if的type成员没有定义。尝试使用这种情况下的type成员会导致编译错误,从而使得该模板实例化失败。这样可以用来控制模板的选择和重载。示例
以下是一个使用
std::enable_if的示例,演示如何根据类型的特性来启用或禁用函数模板:#include <iostream> #include <type_traits> // 用于启用整数类型的模板函数 template<typename T> typename std::enable_if<std::is_integral<T>::value, void>::type printType() { std::cout << "Integral type\n"; } // 用于启用非整数类型的模板函数 template<typename T> typename std::enable_if<!std::is_integral<T>::value, void>::type printType() { std::cout << "Non-integral type\n"; } int main() { printType<int>(); // 输出: Integral type printType<double>(); // 输出: Non-integral type return 0; }在这个示例中:
printType<int>()会选择第一个模板版本,因为int是整数类型。printType<double>()会选择第二个模板版本,因为double不是整数类型。工作原理
编译时替换:
std::enable_if根据布尔表达式B的值来决定是否定义type成员。条件启用:在模板参数中使用
std::enable_if可以有效地启用或禁用某些模板实例化。SFINAE:如果
B为假,type成员未定义,尝试实例化使用type的模板将导致编译错误,从而引发 SFINAE 机制。通过这种方式,
std::enable_if可以帮助实现条件模板选择,使得模板编程更加灵活和强大。
模板的参数可以作为编译器常量,可以自动优化

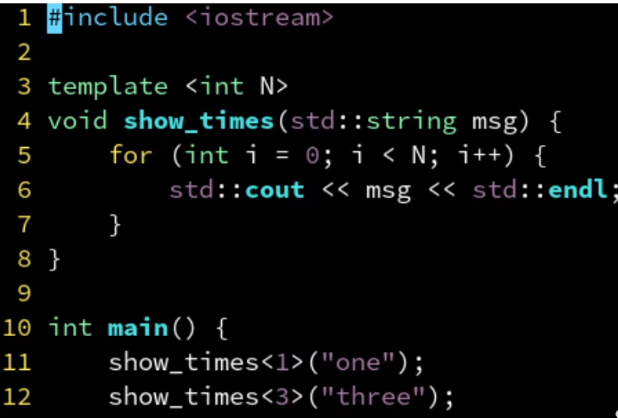
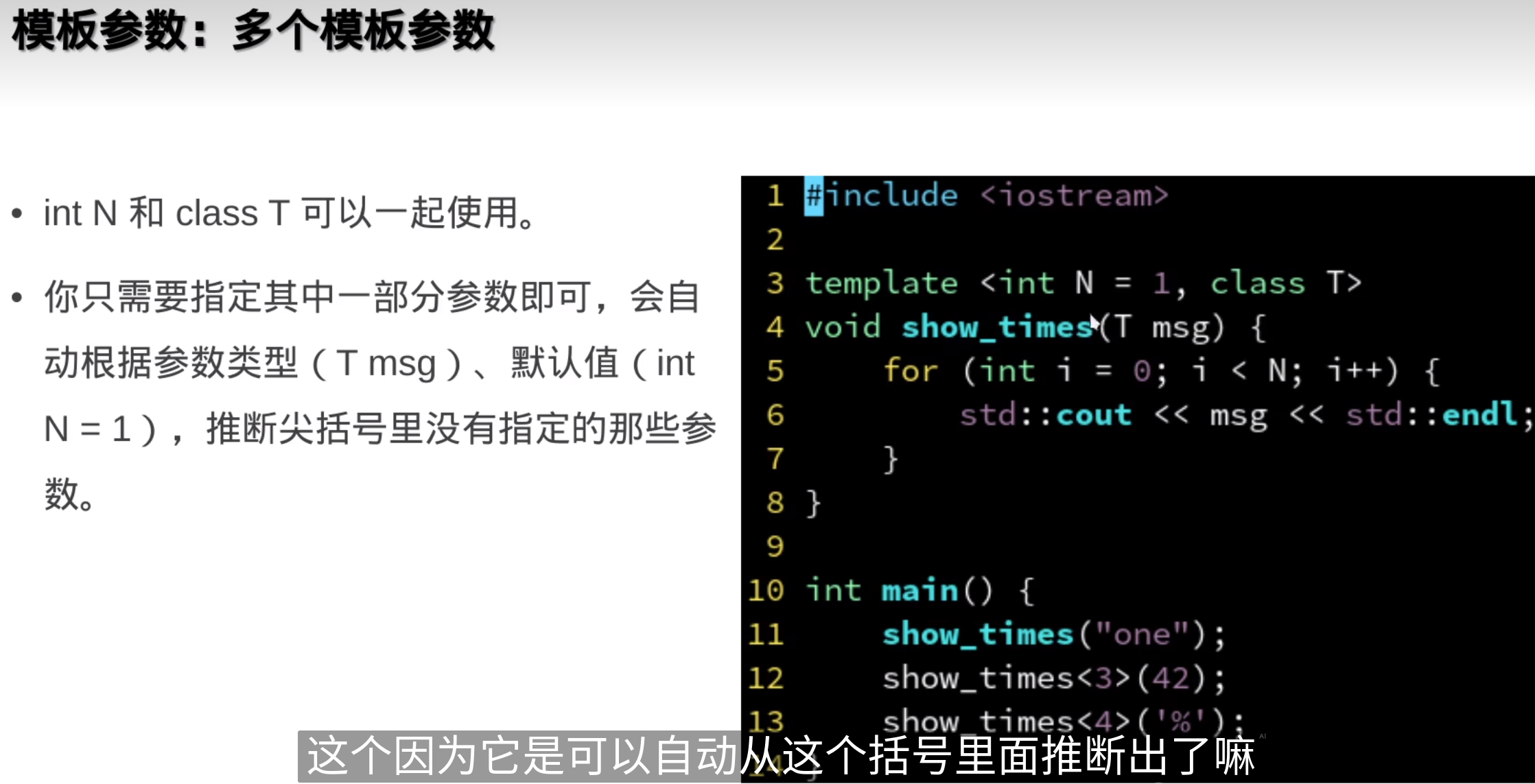
N变一次,编译器就会重新实例化一遍模版函数,编译就变慢
模版函数必须定义在同一个文件里才能使用(必须是内联的或者在头文件里的),所以模板函数的定义和实现无法分离,因此除非特殊手段,模板函数的定义和实现必须放到头文件里。
模板函数太多会导致头文件非常大。
模板函数内联要加static
 {:height 34, :width 232}
{:height 34, :width 232}


if constexpr是 C++17 中引入的一种编译时条件语句。它允许在编译时根据条件选择代码路径,从而避免在运行时进行条件判断。与传统的if语句不同,if constexpr在编译时会根据条件是否为true来决定是否编译相应的代码块。举个例子:
#include <iostream> #include <type_traits> template <typename T> void print_type() { if constexpr (std::is_integral<T>::value) { std::cout << "Integral type" << std::endl; } else { std::cout << "Non-integral type" << std::endl; } } int main() { print_type<int>(); // 输出 "Integral type" print_type<double>(); // 输出 "Non-integral type" }在这个例子中,
if constexpr会在编译时检查std::is_integral<T>::value是否为true,然后编译对应的代码块。这使得print_type函数的行为在编译时就被确定下来,从而避免了在运行时的类型检查。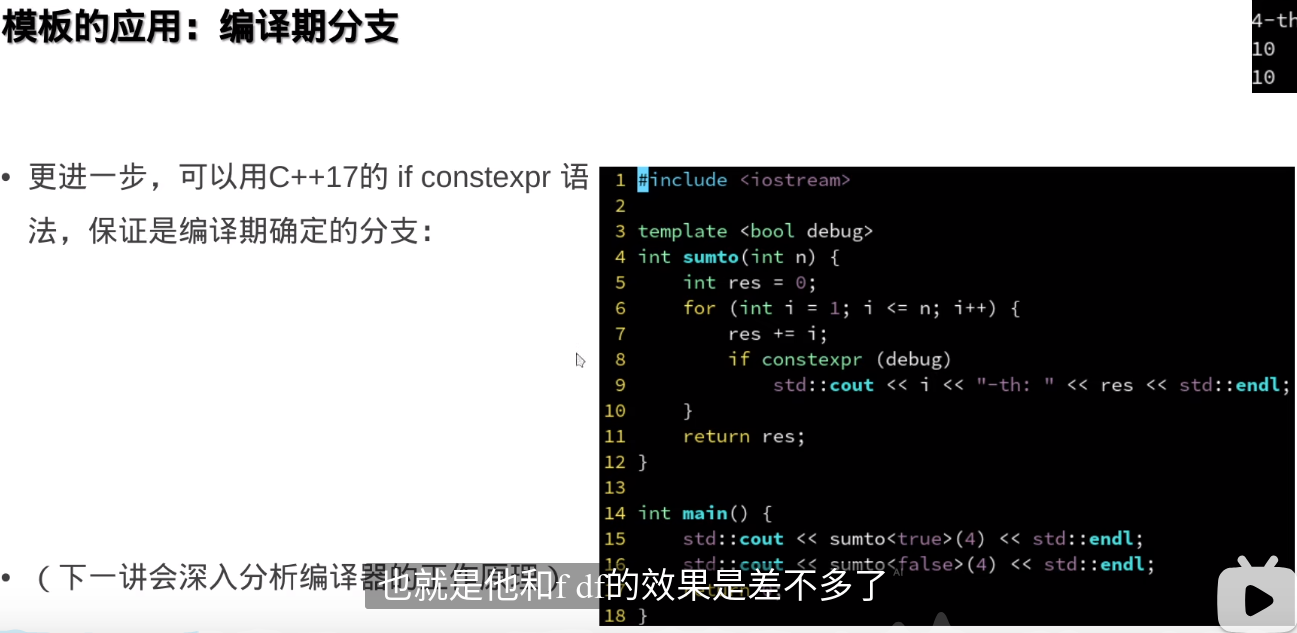
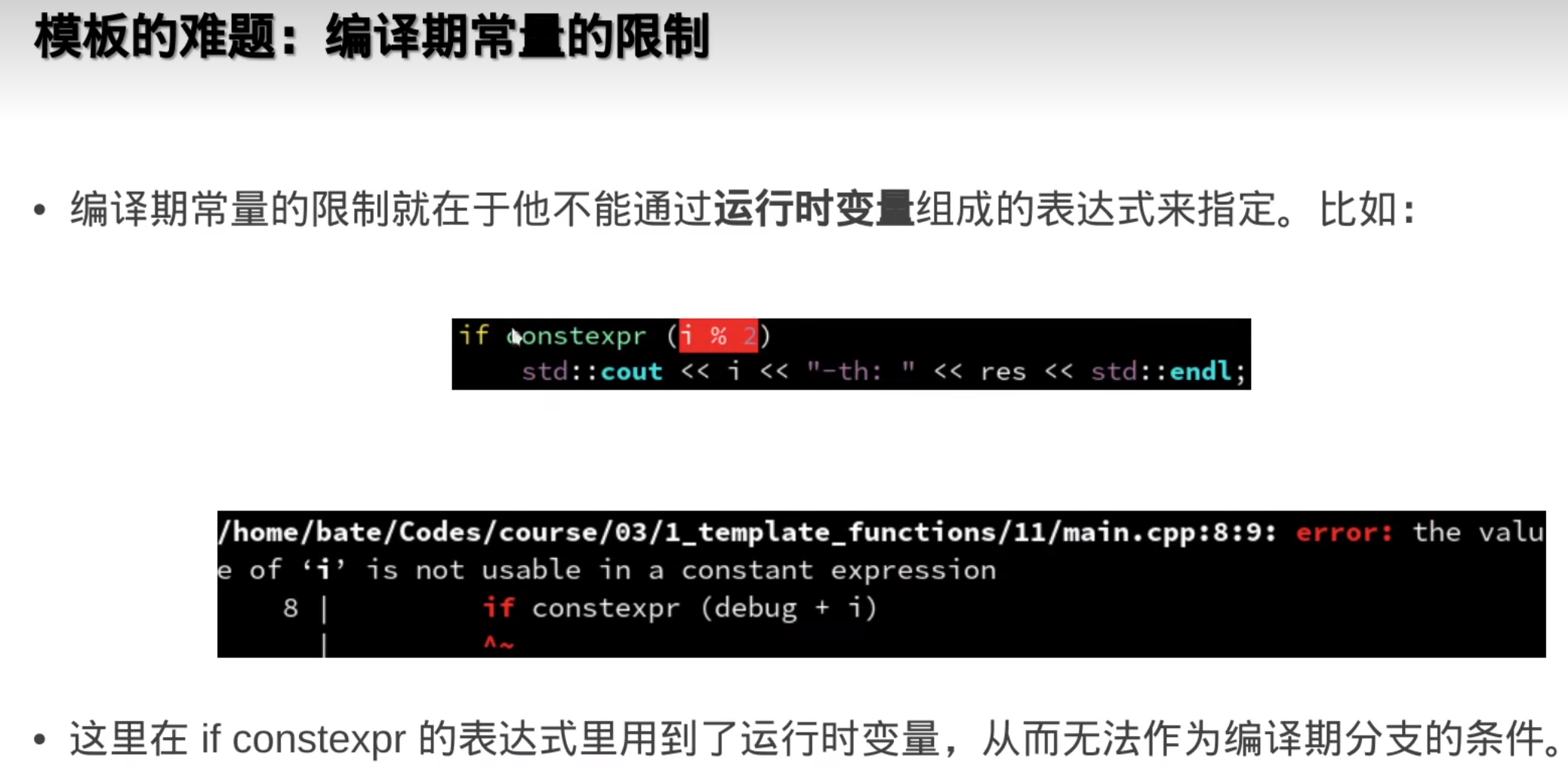
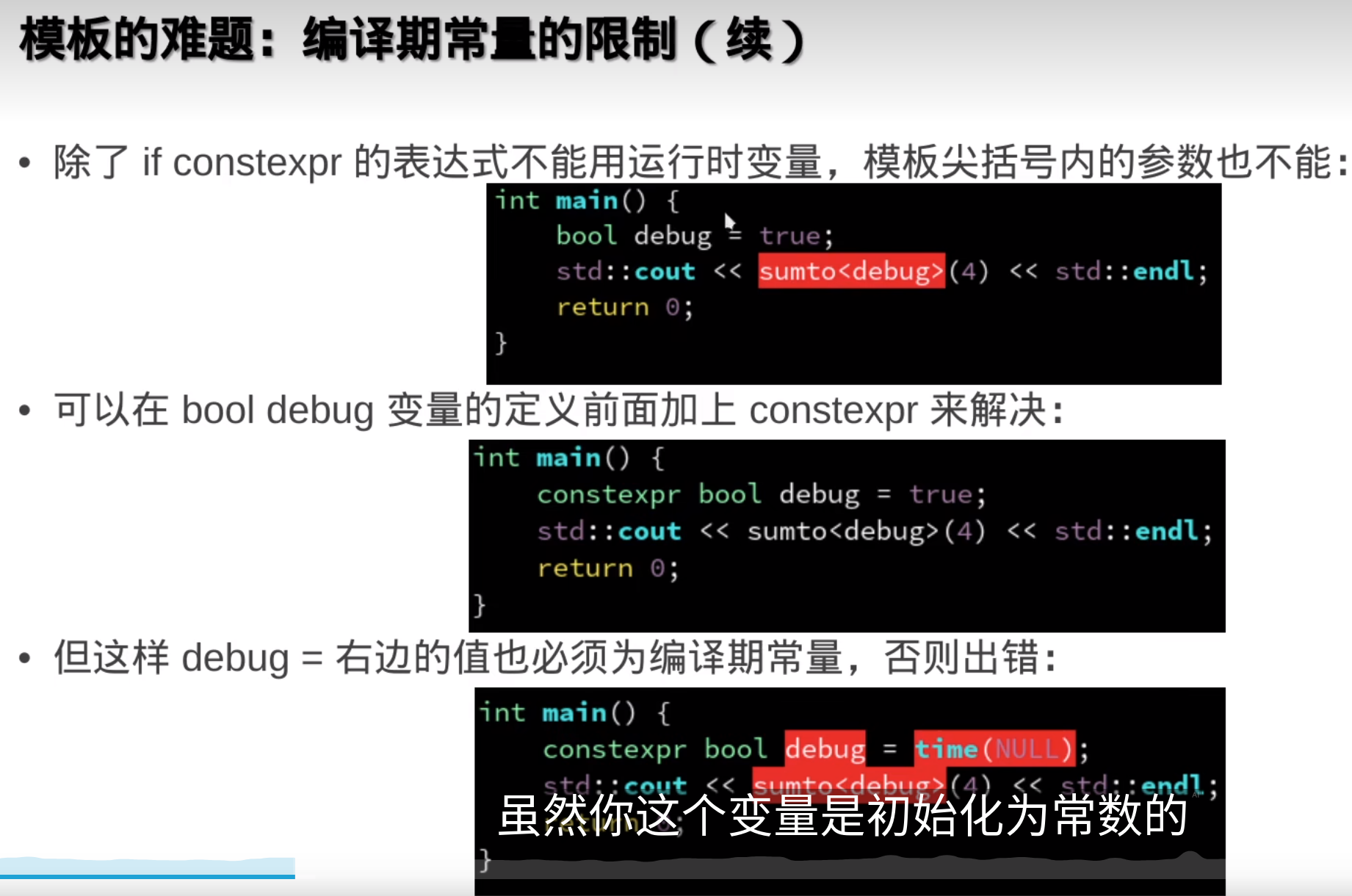

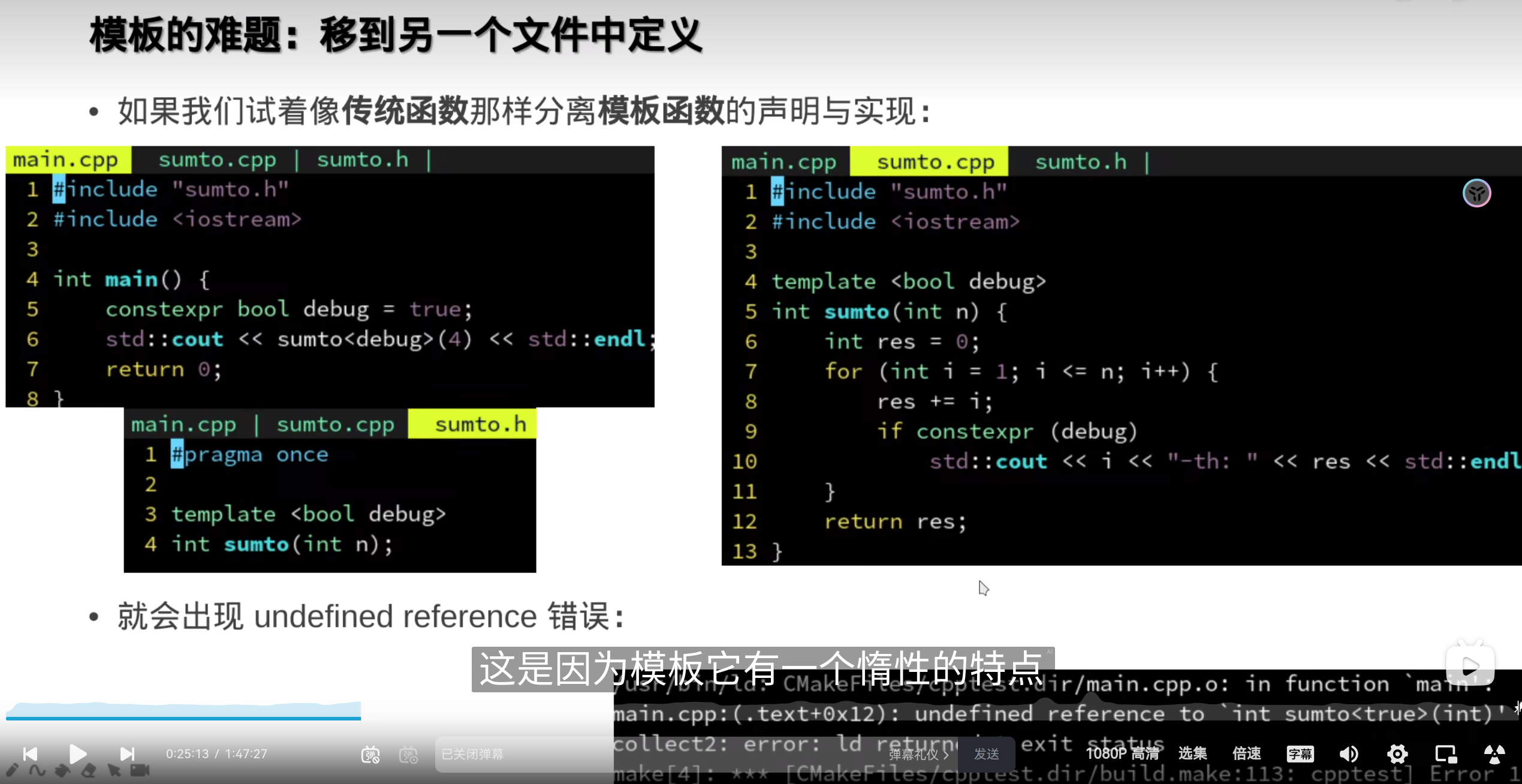
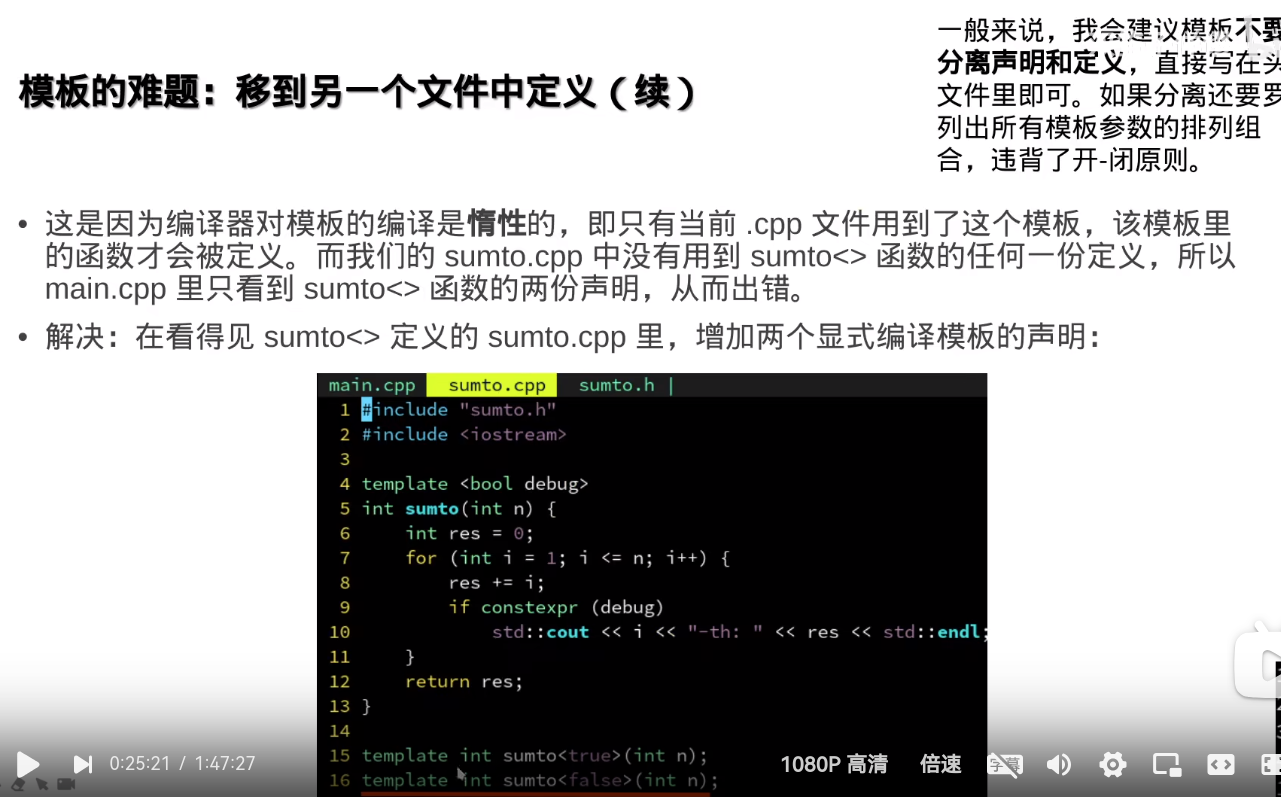 但是这样要把模板实例化的,每一种 情况都声明
但是这样要把模板实例化的,每一种 情况都声明所以,尽量不要把模板分离
 延迟编译:当一个函数定义在头文件里,可能用不到,可以在前面加 template
延迟编译:当一个函数定义在头文件里,可能用不到,可以在前面加 template 这个假模板,只有被调用的时候才会被编译 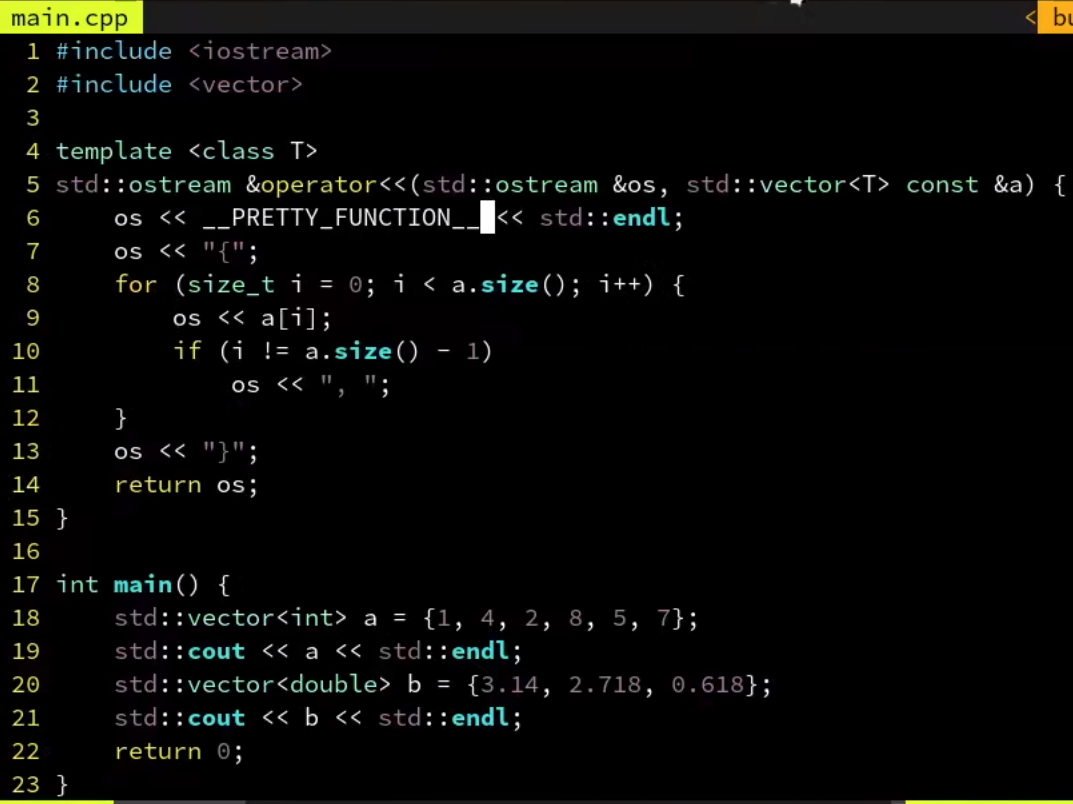
可以把函数的信息打印出来

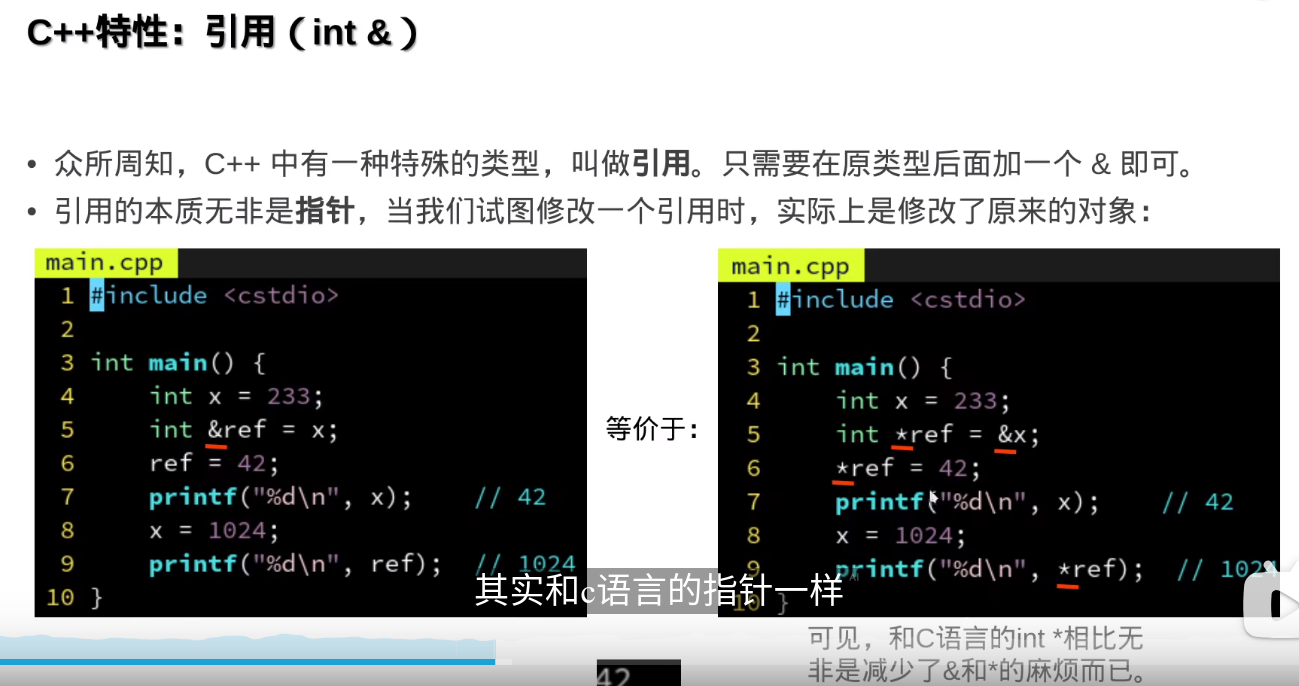
c++里的引用(int &)相当于C里面的指针(int*)
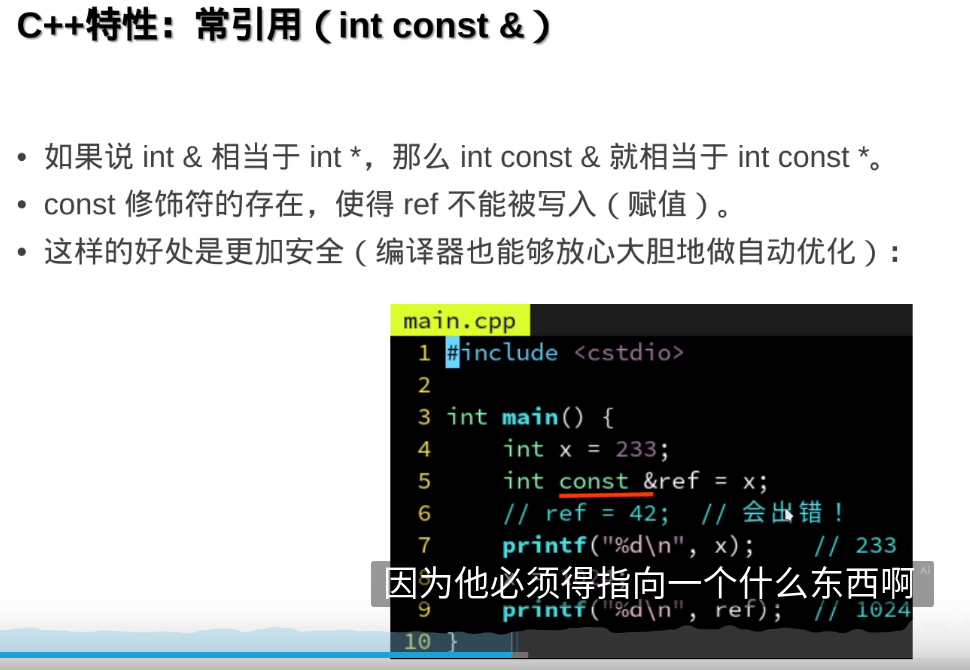 引用没有空,指针可以空
引用没有空,指针可以空auto & auto const & 也可
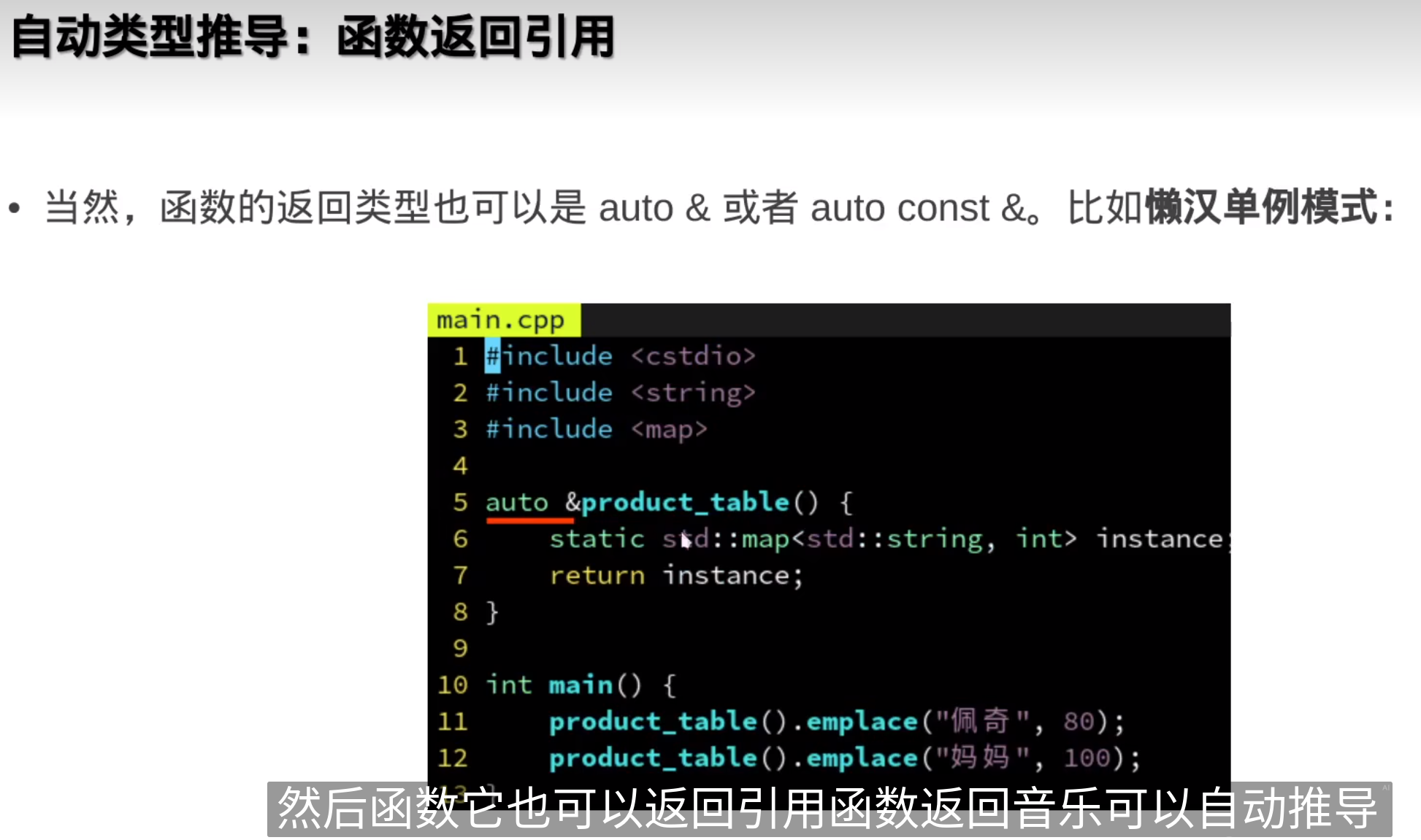
懒汉单例模式(Lazy Singleton)是一种设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。与饿汉单例模式不同,懒汉单例模式会在需要实例时才进行初始化,因此被称为“懒汉”模式。
懒汉单例模式的特点
- 延迟初始化:单例对象只有在第一次被使用时才会创建。
- 线程安全问题:在多线程环境下,需要处理线程安全问题,以确保只有一个实例被创建。
懒汉单例模式的实现方式
下面是一个基本的懒汉单例模式的实现示例(不考虑线程安全):
class Singleton { public: // 获取单例实例的静态方法 static Singleton* getInstance() { if (instance == nullptr) { instance = new Singleton(); } return instance; } // 禁止拷贝构造函数和赋值操作符 Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; private: // 私有构造函数 Singleton() {} // 静态成员变量,用于存储唯一的实例 static Singleton* instance; }; // 静态成员变量的初始化 Singleton* Singleton::instance = nullptr;线程安全的实现
在多线程环境下,上述实现可能会导致线程安全问题,因此需要对其进行改进。可以使用互斥锁(
mutex)来确保线程安全:#include <mutex> class Singleton { public: // 获取单例实例的静态方法 static Singleton* getInstance() { if (instance == nullptr) { std::lock_guard<std::mutex> lock(mutex); if (instance == nullptr) { instance = new Singleton(); } } return instance; } // 禁止拷贝构造函数和赋值操作符 Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; private: // 私有构造函数 Singleton() {} // 静态成员变量,用于存储唯一的实例 static Singleton* instance; // 互斥锁,用于保证线程安全 static std::mutex mutex; }; // 静态成员变量的初始化 Singleton* Singleton::instance = nullptr; std::mutex Singleton::mutex;C++11 及以后的标准
在C++11及以后的标准中,可以使用
std::call_once来确保实例的唯一性,并提高线程安全性:#include <mutex> class Singleton { public: // 获取单例实例的静态方法 static Singleton* getInstance() { std::call_once(flag, []() { instance.reset(new Singleton()); }); return instance.get(); } // 禁止拷贝构造函数和赋值操作符 Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; private: // 私有构造函数 Singleton() {} // 静态成员变量,用于存储唯一的实例 static std::unique_ptr<Singleton> instance; // 静态变量,用于确保单例实例只创建一次 static std::once_flag flag; }; // 静态成员变量的初始化 std::unique_ptr<Singleton> Singleton::instance; std::once_flag Singleton::flag;在这个实现中,
std::call_once和std::once_flag确保了即使在多线程环境中,单例对象也只会被创建一次。std::unique_ptr自动管理内存,避免了手动释放内存的麻烦。使用互斥锁(mutex)来确保线程安全时为什么只有锁:std::lock_guardstd::mutex lock(mutex); 没有解锁?
在使用
std::lock_guard<std::mutex>时,解锁是由std::lock_guard自动处理的,而不需要显式地调用解锁操作。这是因为std::lock_guard是一个RAII(Resource Acquisition Is Initialization)风格的类,它的设计目的是简化互斥锁的管理并自动释放资源。RAII 和
std::lock_guardRAII 是一种编程习惯,确保资源(如内存、文件句柄、互斥锁等)的生命周期由对象的生命周期来管理。
std::lock_guard利用 RAII 原则来管理互斥锁的锁定和解锁:- 构造函数:当
std::lock_guard对象被创建时,它会在构造函数中自动锁定传递给它的std::mutex对象。 - 析构函数:当
std::lock_guard对象被销毁(即其作用域结束时),它的析构函数会自动释放(解锁)互斥锁。
这种设计使得你不需要显式地编写解锁代码,降低了因为遗漏解锁操作而导致的潜在错误。
- 构造函数:当
解释
std::lock_guard<std::mutex> lock(mutex);:
- 当执行到这行代码时,
lock对象会在构造函数中自动锁定mutex。 - 当
lock对象超出作用域(例如,getInstance方法的执行结束时),lock的析构函数会被调用,从而自动解锁mutex。
- 当执行到这行代码时,
优点
自动解锁:减少了因为忘记解锁导致的死锁问题。
简化代码:不需要显式地管理锁的释放,使代码更加简洁和易于维护。
异常安全:即使在
getInstance方法中发生异常,std::lock_guard也会确保互斥锁在lock对象被销毁时正确解锁,从而避免死锁。通过
std::lock_guard或其他类似的 RAII 风格的工具,C++ 提供了一种简洁而安全的方式来管理互斥锁,帮助程序员编写更健壮的多线程代码。


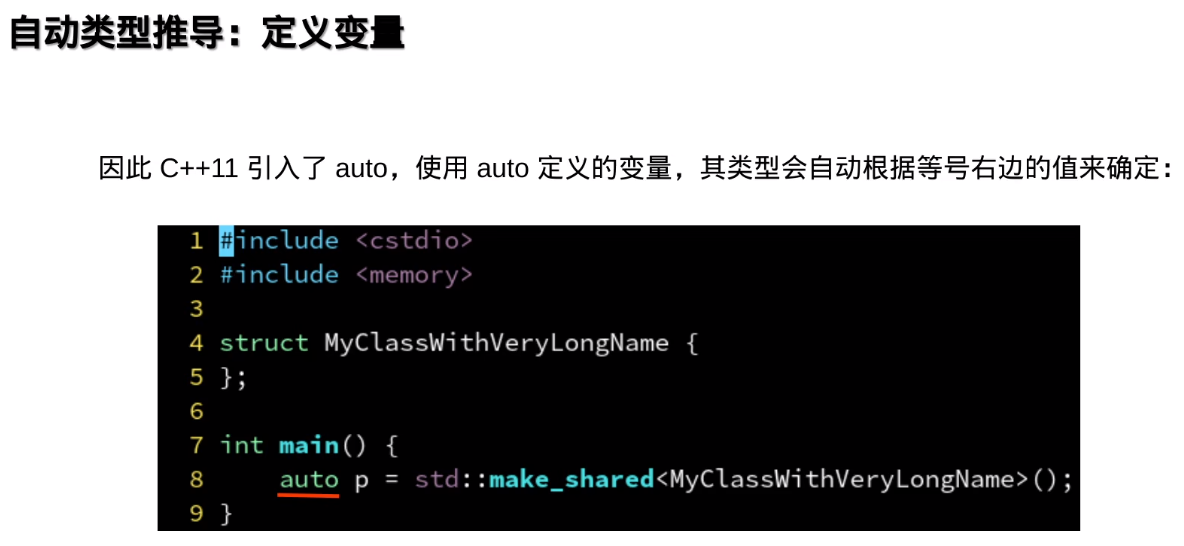
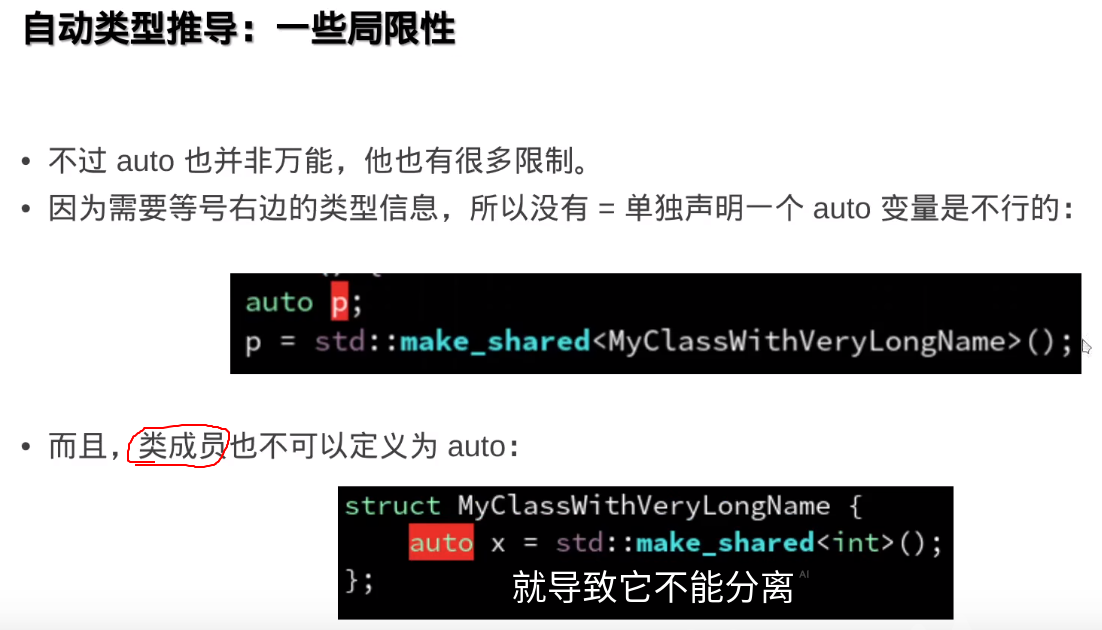
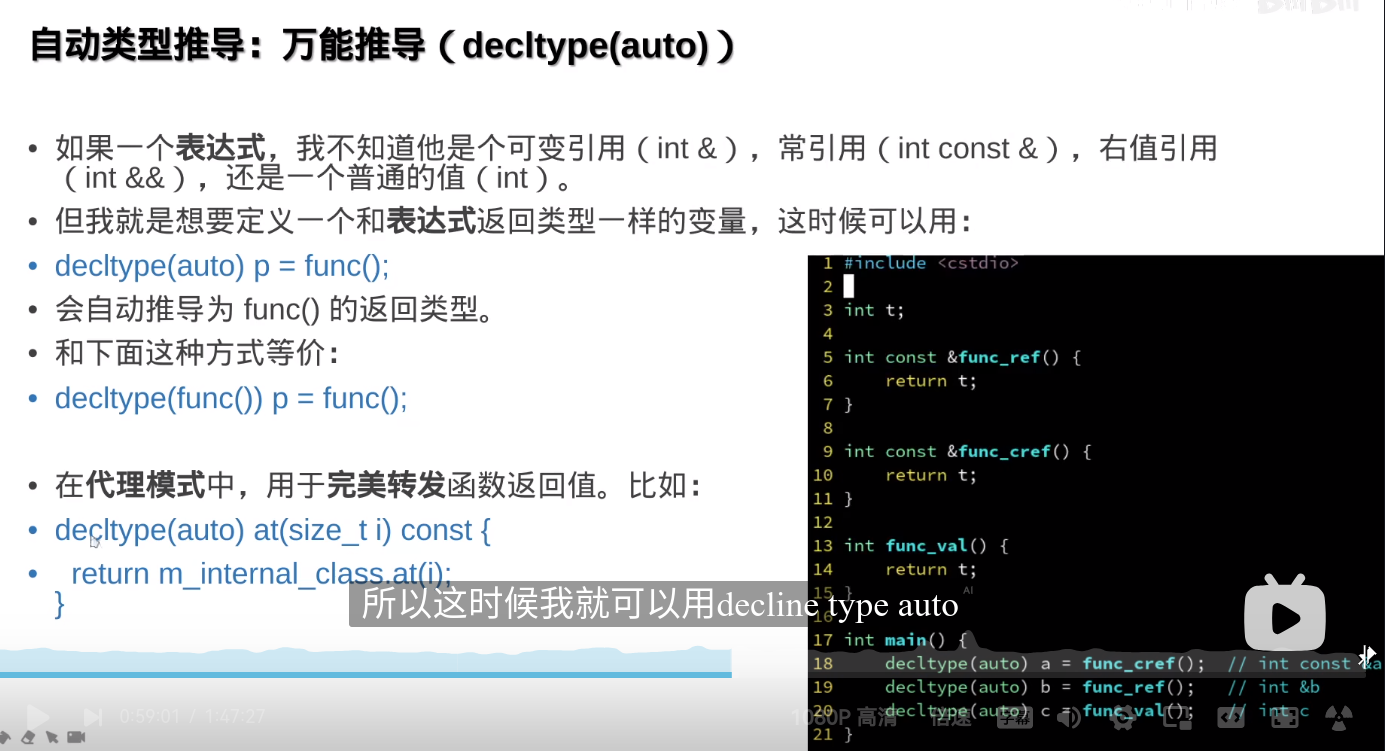
decltype(auto)和auto的区别
decltype(auto) 和 auto 都用于类型推导,但它们有不同的行为:
auto:- 用于自动推导变量的类型。
auto根据表达式的值推导类型,不会保留表达式的引用性(即auto不会推导出引用类型,除非显式指定)。 - 例如,
auto x = 5;中,x的类型是int。
- 用于自动推导变量的类型。
decltype(auto):- 结合
decltype和auto的特性。它推导出表达式的类型,包括引用(decltype会保留表达式的原始类型)。 - 例如,
decltype(auto) y = (5);中,y的类型是int&,因为(5)是一个左值引用。
- 结合
总结:
- 使用
auto时,结果类型是值类型。 - 使用
decltype(auto)时,结果类型保持原表达式的类型,包括引用。

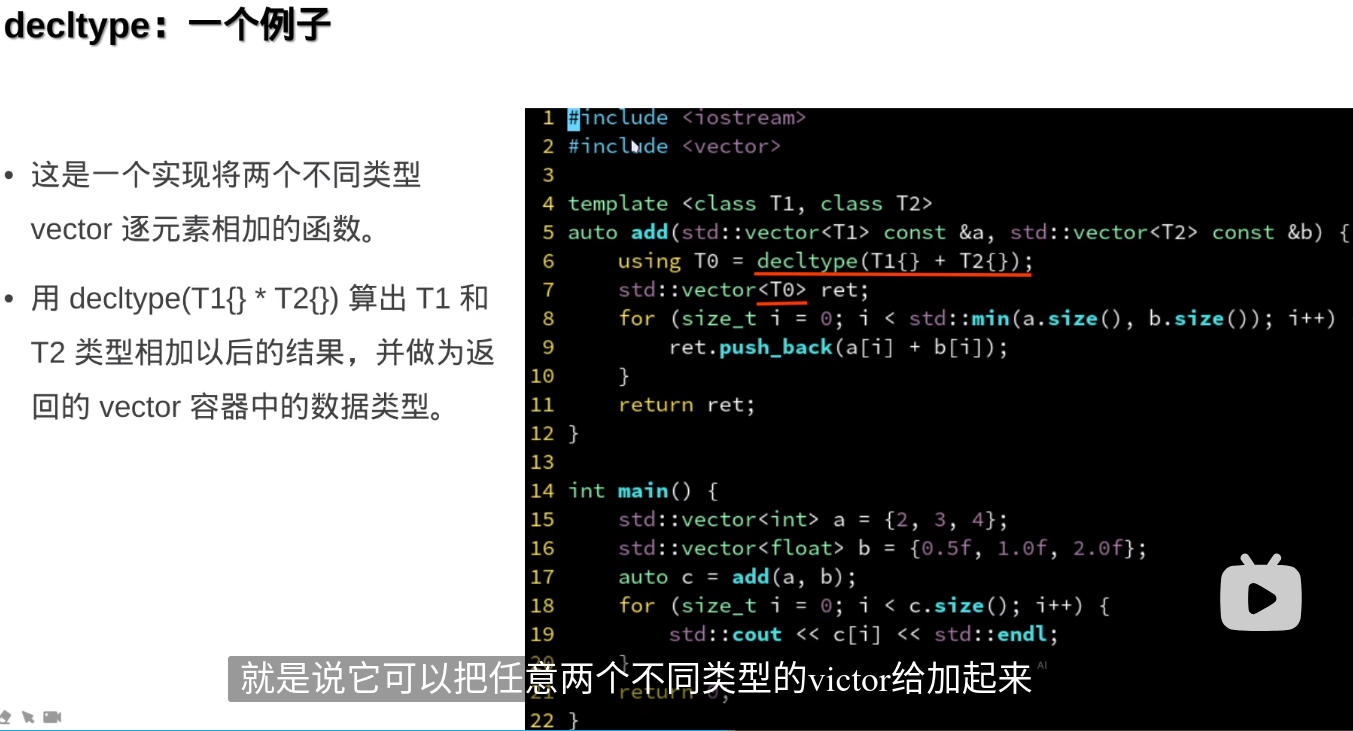 T1{}创建一个T1的对象
T1{}创建一个T1的对象
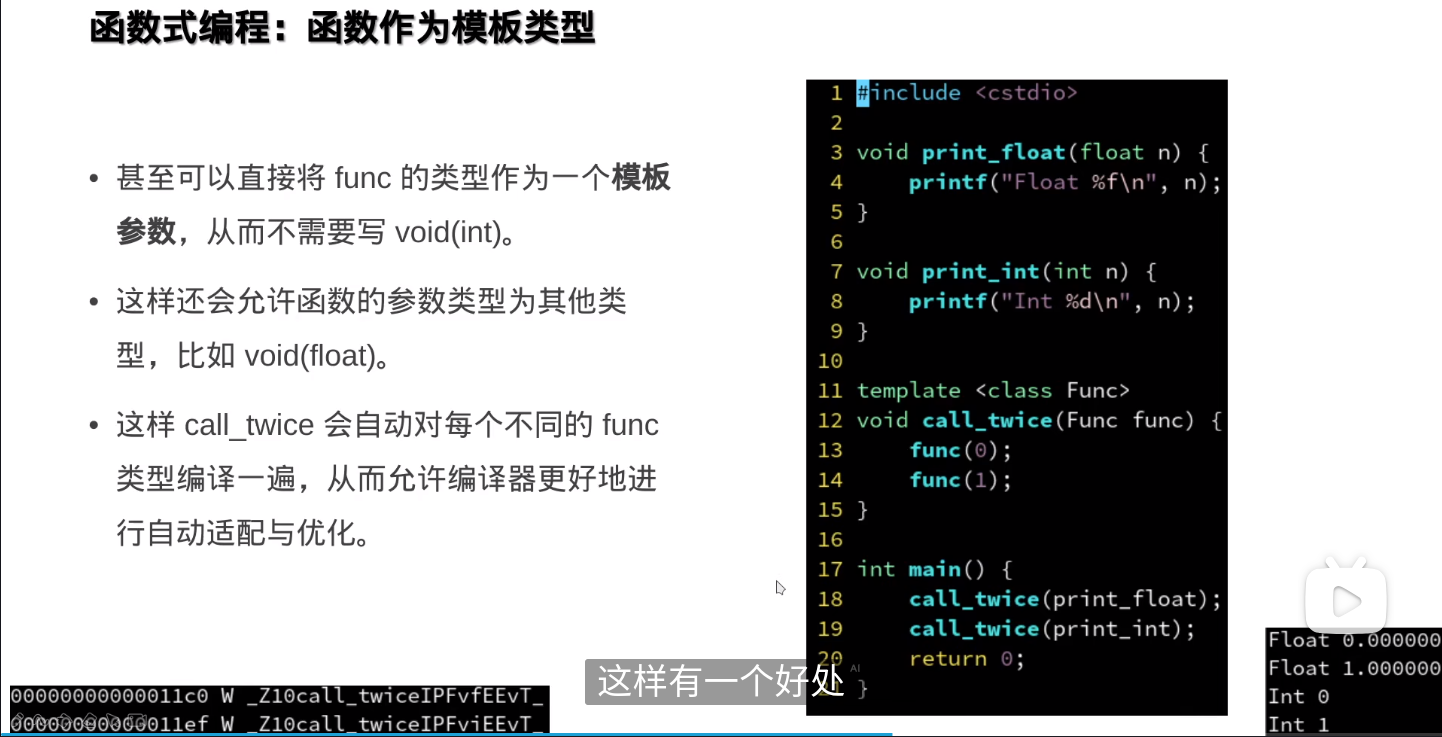
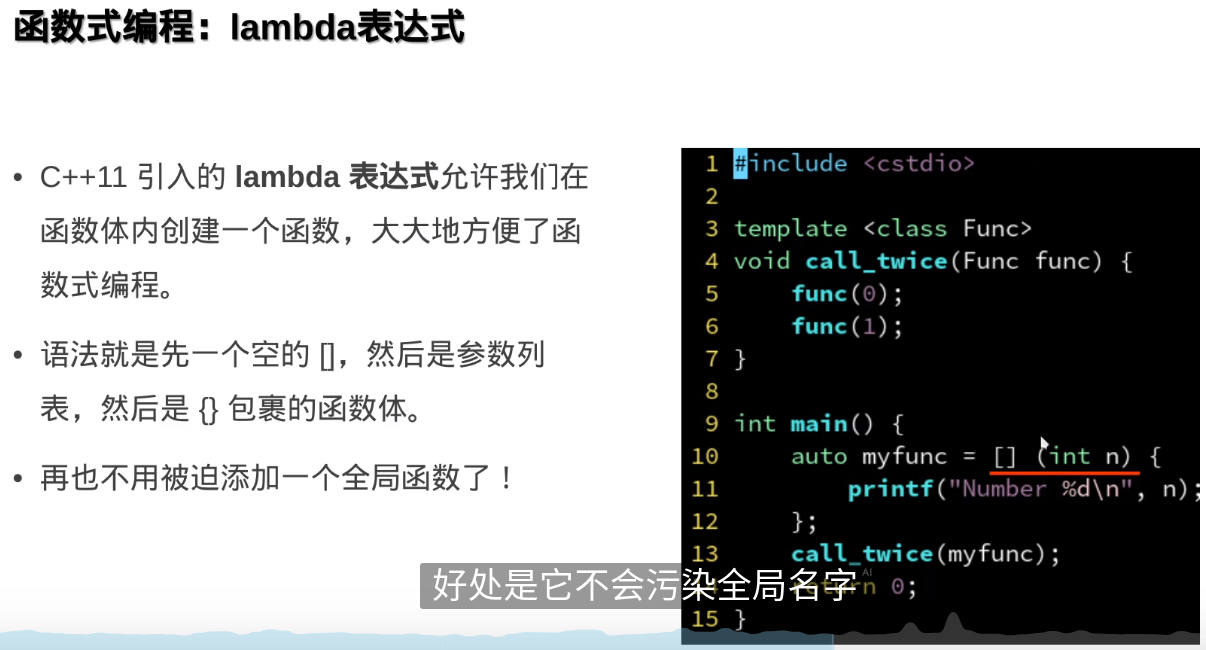
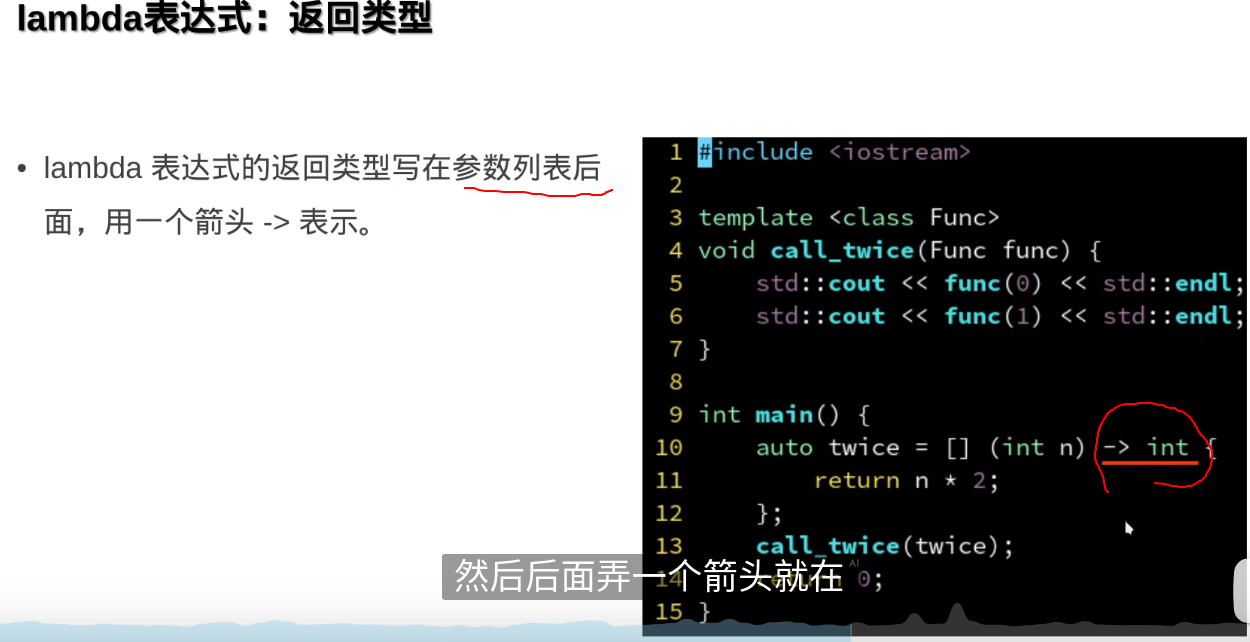
函数式编程

函数作为参数传入另一个函数,实际传的是这个函数的起始地址

确实相当于函数指针



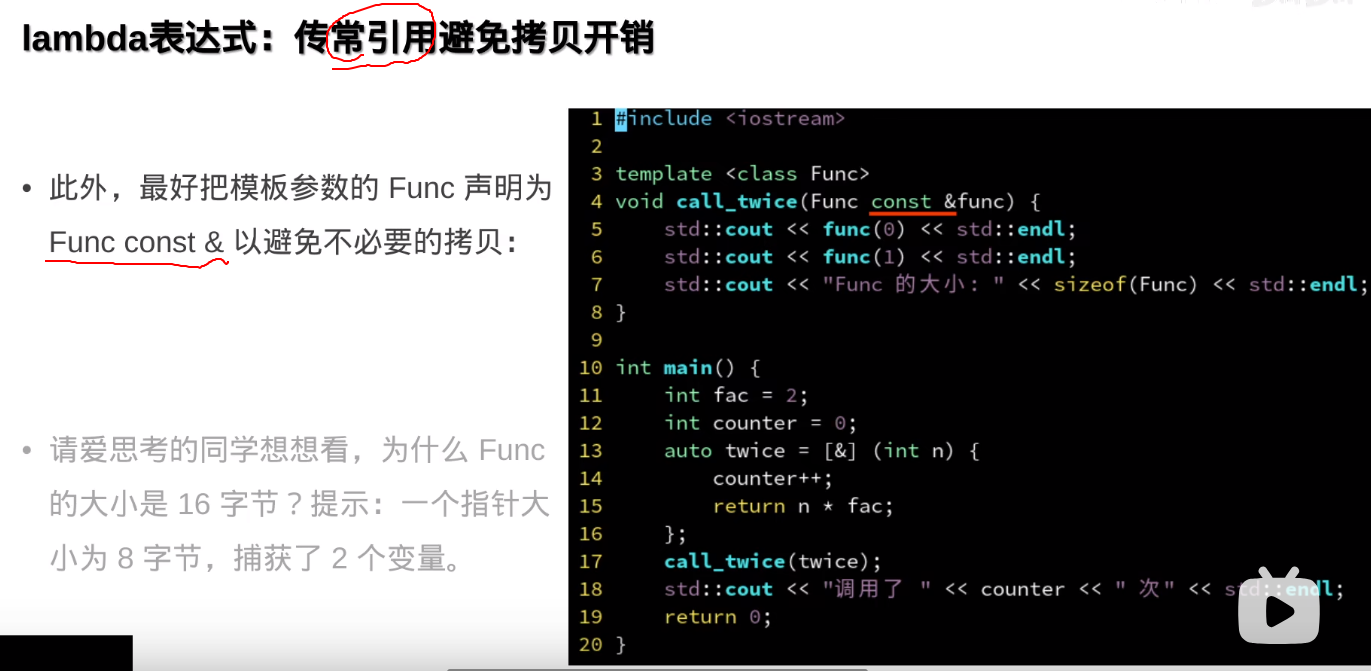



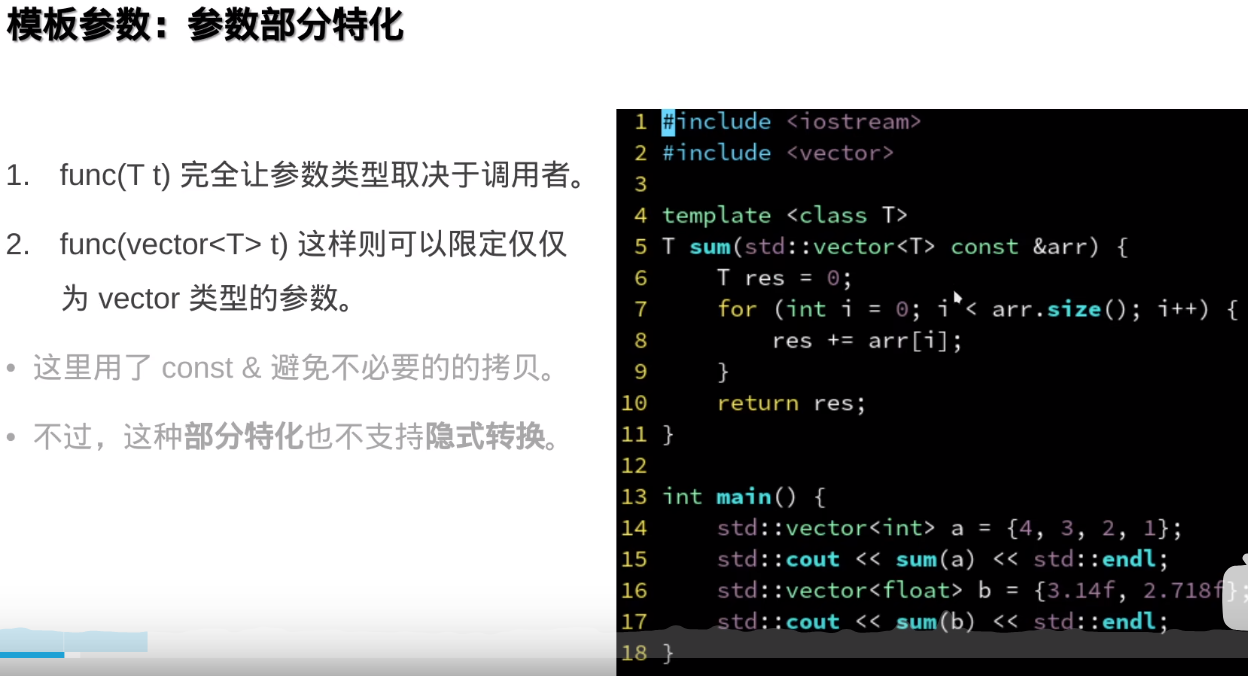
###避免使用模板参数
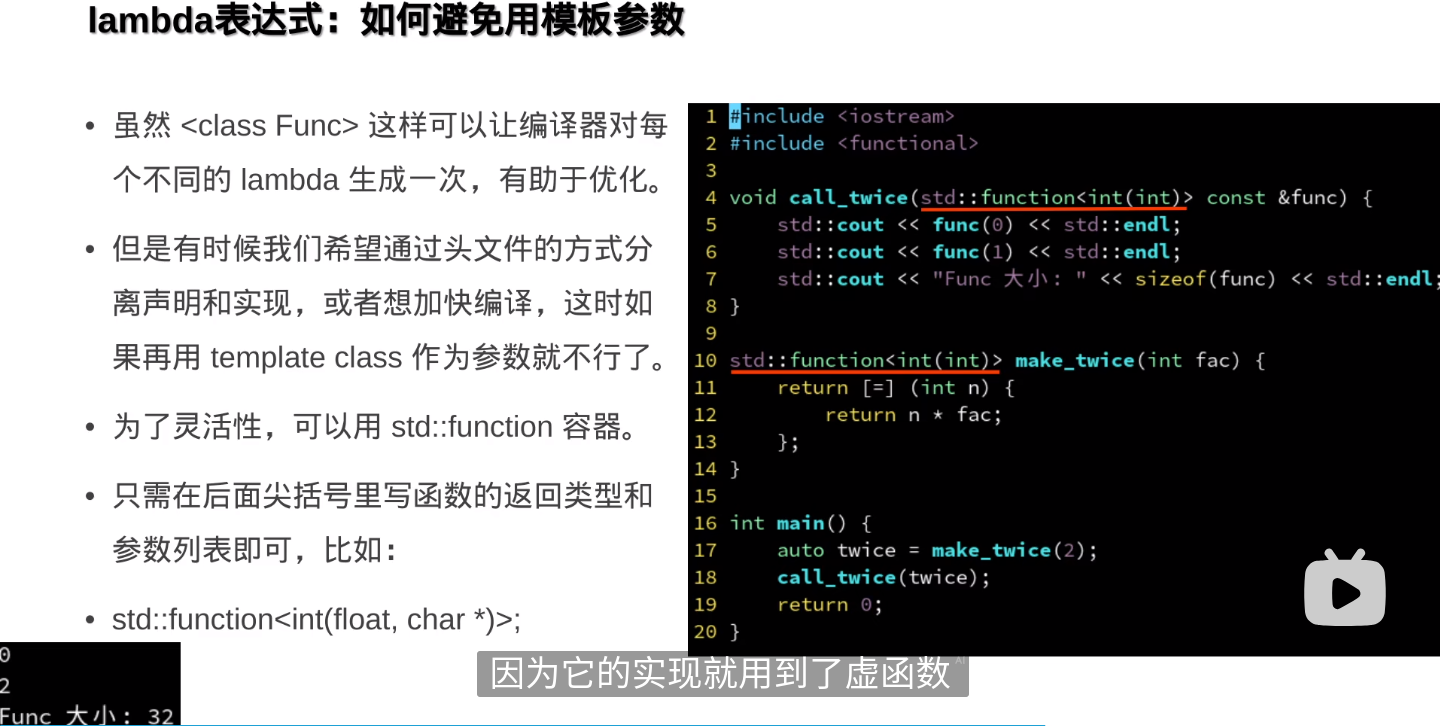
类型擦除技术:std::function容器

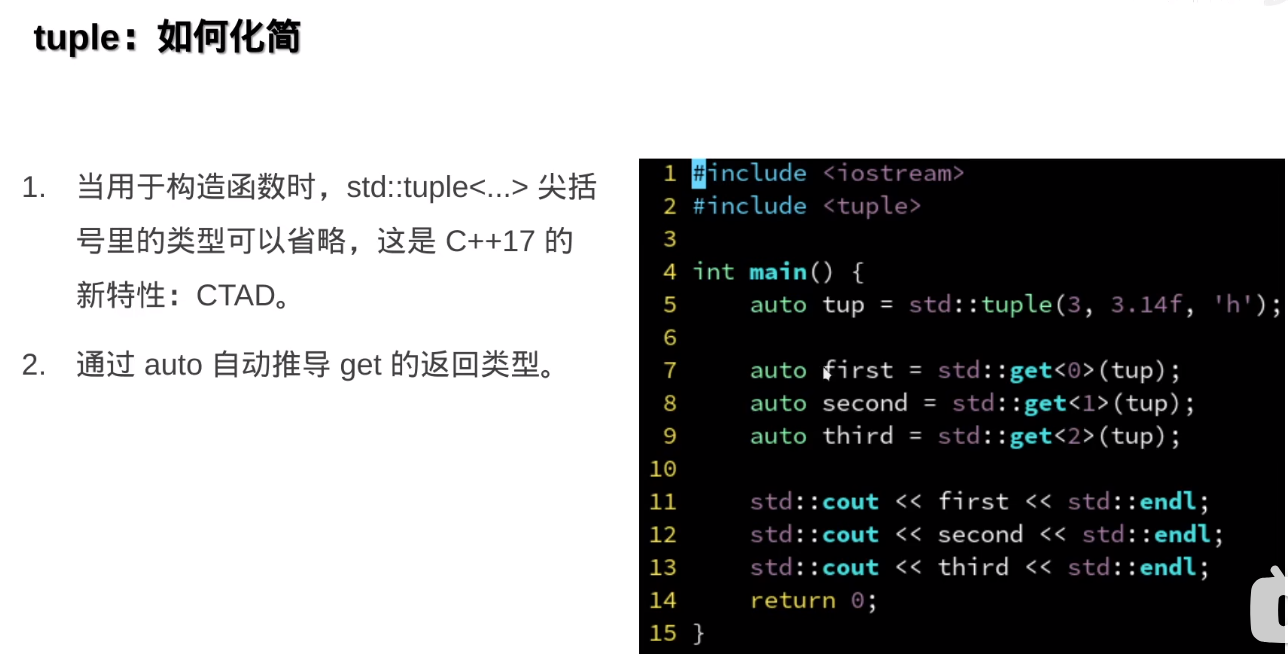
 但是没办法做部分特例化
但是没办法做部分特例化

立即调用 Lambda:在 lambda 表达式的定义后面加上 (),立即调用这个匿名函数。 lambda 表达式的返回值可以用于初始化变量或进行其他操作。

可以利用return自带的break效果既实现break又赋值的效果





左值持久,右值短暂,左值有持久的状态,而右值要么是字面常量,要么是在表达式求值过程中创建的临时对象(将要被销毁的对象)。
右值引用的好处是减少右值作为参数传递时的复制开销
使用std::move可以获得绑定到一个左值的右值引用
int intValue = 10;
int &&intValue3 = std::move(intValue);
decltype(auto) 是 C++11 引入的一种类型推断工具,它结合了 decltype 和 auto 的特性,用于在声明变量时推断其类型。与 auto 不同,decltype(auto) 更精确地推断变量的类型,包括引用性。
用法:
decltype(auto)在声明变量时,会推断出表达式的确切类型,包括是否是引用类型。int x = 10; int& ref = x; decltype(auto) y = ref; // y 是 int&,与 ref 类型相同区别:
auto只推断值类型,而decltype(auto)会保持原有的引用类型或常量性。auto a = x; // a 是 int decltype(auto) b = x; // b 是 int,b 不是引用 decltype(auto) c = ref; // c 是 int&,与 ref 类型相同
总结:decltype(auto) 在需要精确类型推断,包括引用时非常有用。
但是tuple容器的万能推导由于历史原因,不是decltype(auto),而是auto &&
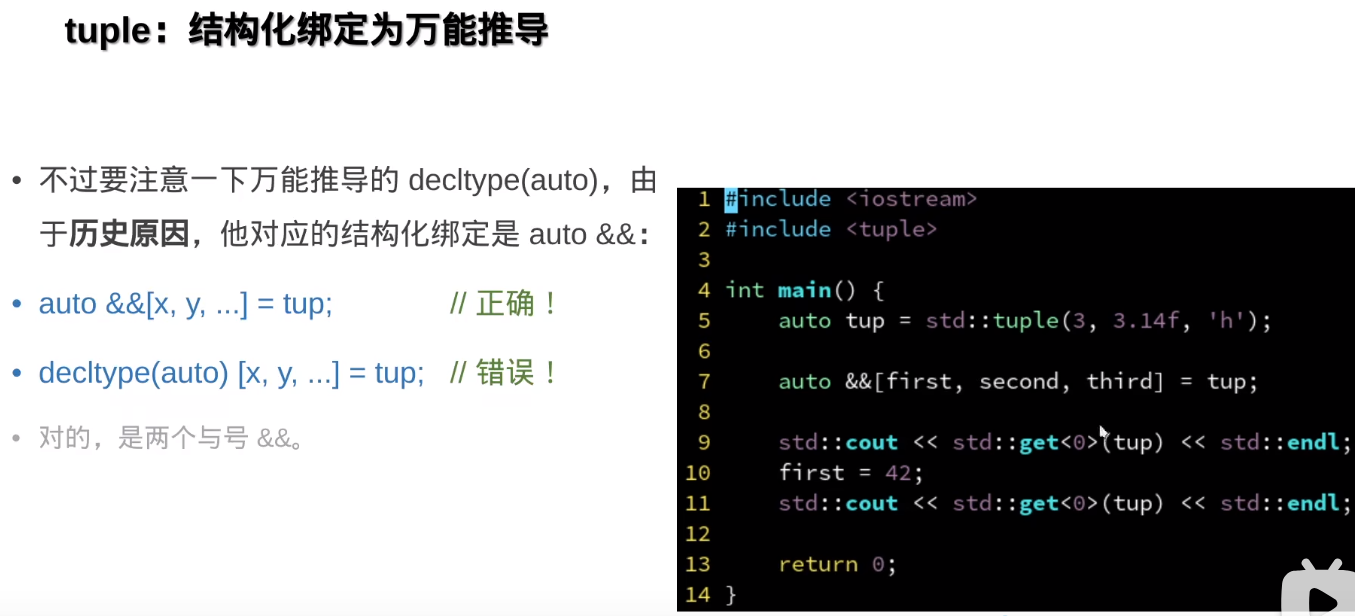
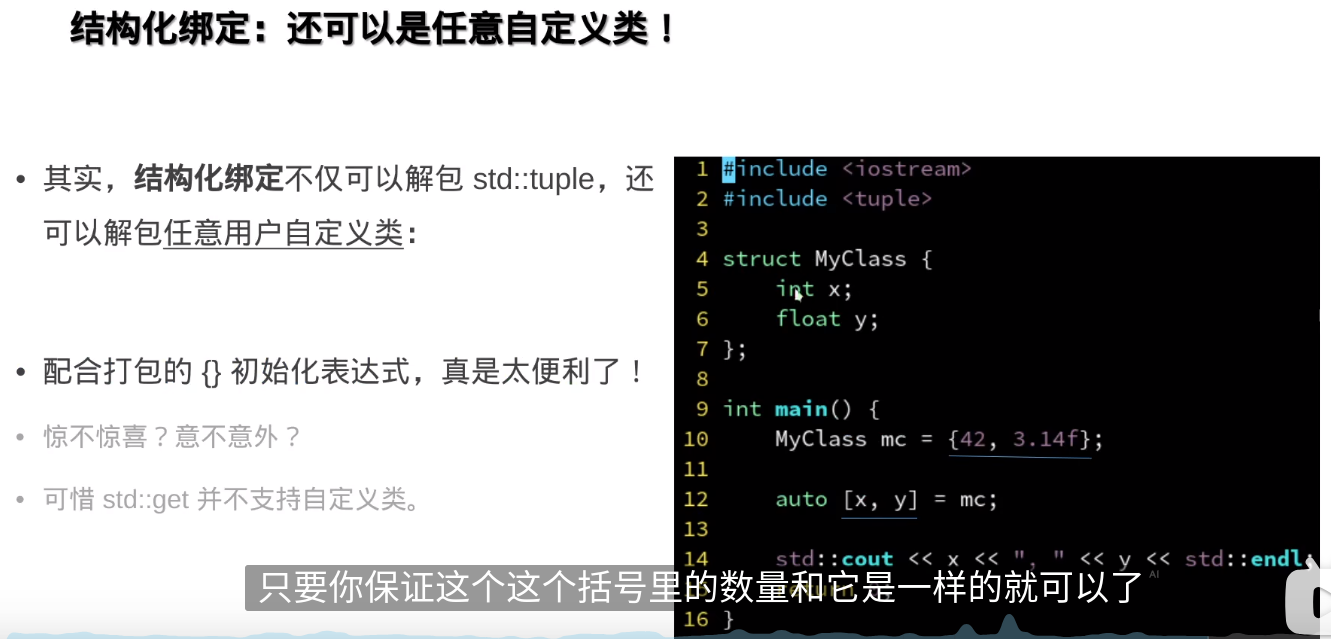
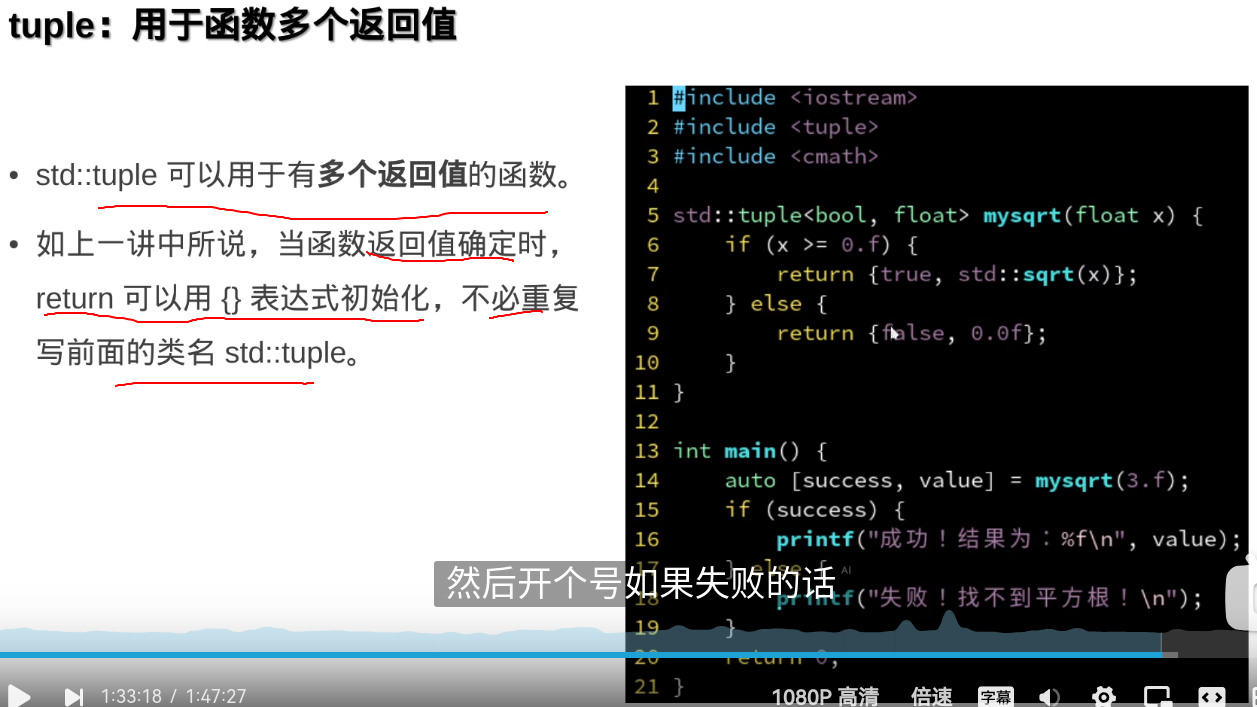
结构化绑定的基本语法如下:
auto [var1, var2, var3] = expression;
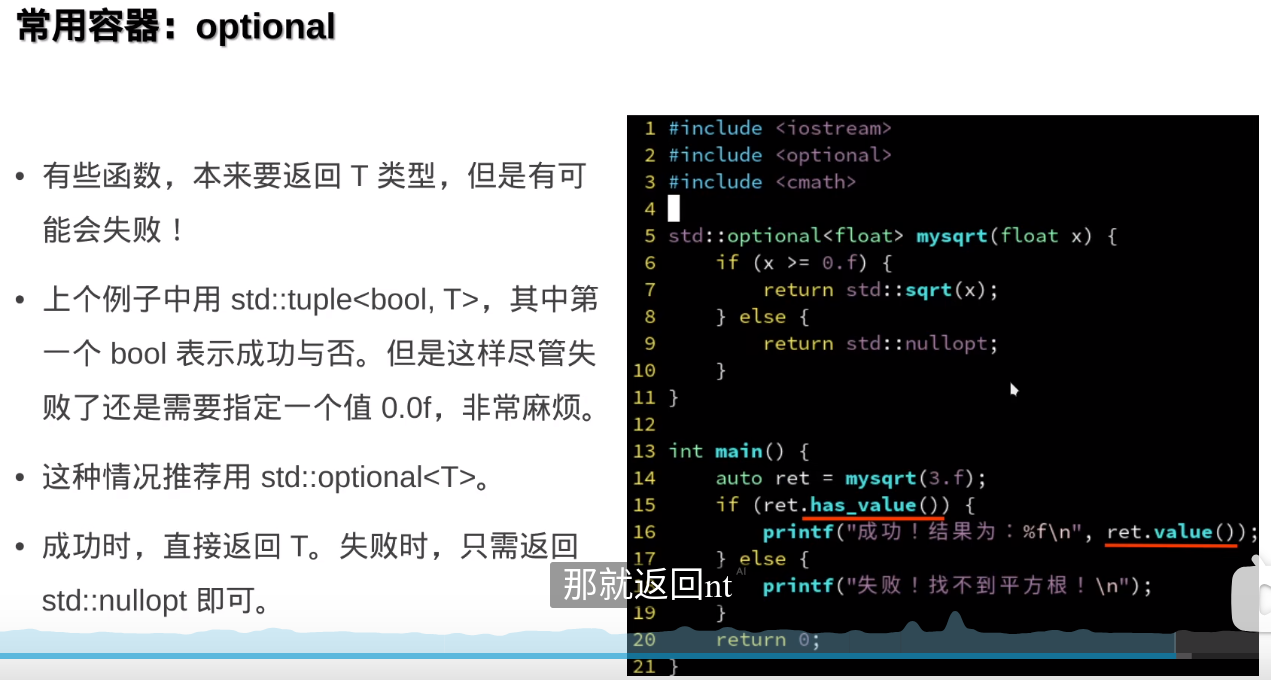
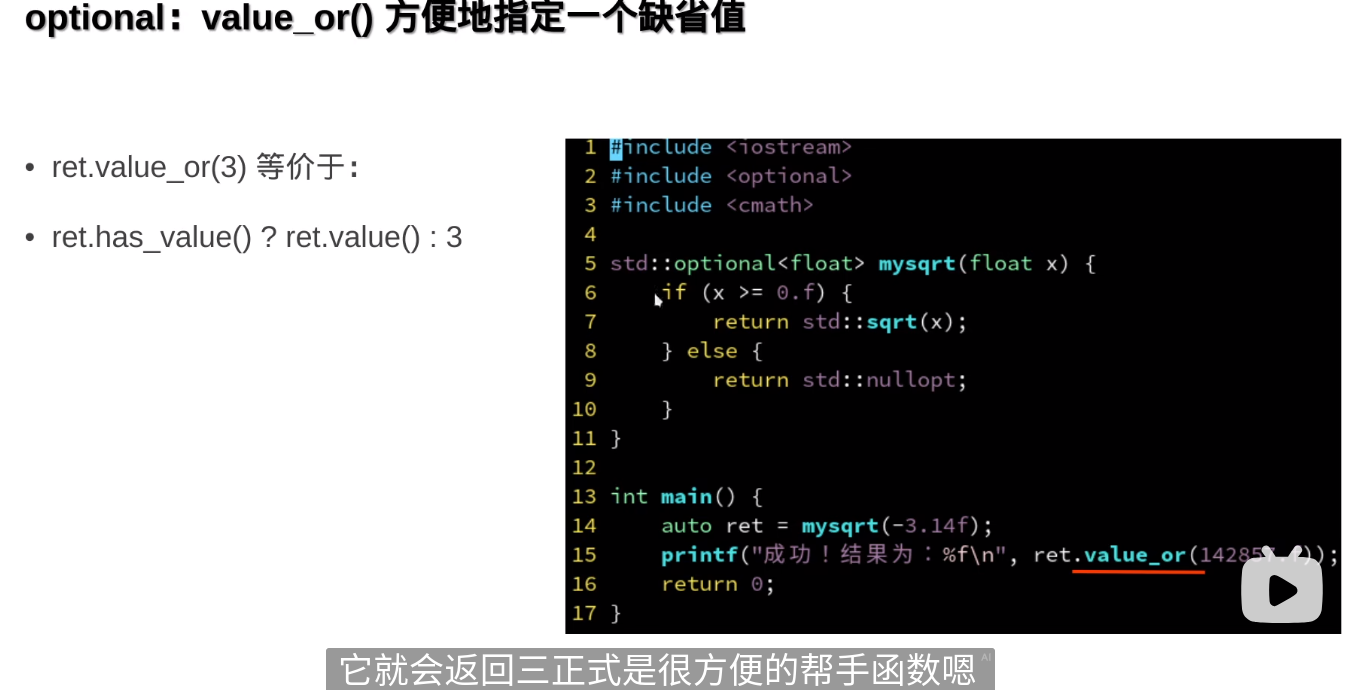

 optional就像一个更安全的指针
optional就像一个更安全的指针
在 C++ 中,union 是一种数据结构,它允许在同一内存位置存储不同的数据类型。union 的所有成员共享同一块内存区域,这意味着在任何给定时刻,union 只能存储一个成员的数据。使用 union 可以节省内存,特别是在需要存储多种不同类型但从不同时存储这些类型时。
union 的基本语法
union UnionName {
type1 member1;
type2 member2;
type3 member3;
// more members
};
主要特点
内存共享:
union中的所有成员共享同一块内存。因此,union的大小由其最大成员的大小决定。
只能存储一个成员:
- 虽然
union可以定义多个成员,但在任何时刻只能存储一个成员的数据。写入一个成员会覆盖掉之前写入的成员的数据。
- 虽然
节省内存:
- 因为所有成员共用一块内存,所以
union可以节省内存,尤其是在只需要存储其中一个成员的数据时。
- 因为所有成员共用一块内存,所以
使用示例
#include <iostream>
union Data {
int intValue;
float floatValue;
char charValue;
};
int main() {
Data data;
data.intValue = 5;
std::cout << "intValue: " << data.intValue << std::endl;
data.floatValue = 3.14;
std::cout << "floatValue: " << data.floatValue << std::endl;
data.charValue = 'A';
std::cout << "charValue: " << data.charValue << std::endl;
// 访问数据会输出不确定的结果,因为各个成员共享同一内存
std::cout << "intValue (after modifying to charValue): " << data.intValue << std::endl;
return 0;
}
在上面的示例中,union Data 可以存储 int, float, 和 char 三种数据类型,但它们共享同一块内存。当写入 floatValue 后,之前存储的 intValue 的数据会被覆盖,读取 intValue 会得到不可预测的结果。
注意事项
类型安全:
- 使用
union时要注意类型安全。读取当前未写入的成员数据可能会导致未定义的行为。
- 使用
构造和析构:
union允许只有一个成员的构造和析构。C++11 之后,union可以包含具有非平凡构造函数、析构函数或拷贝/移动操作符的成员,但这些操作必须在使用union的情况下正确处理。
std::variant替代:- C++17 引入了
std::variant,这是一个更安全的替代union,提供了类型安全的联合体和更丰富的功能。
- C++17 引入了
总的来说,union 是一个低级数据结构,用于内存优化和处理不同类型的数据,但在实际编程中需谨慎使用。




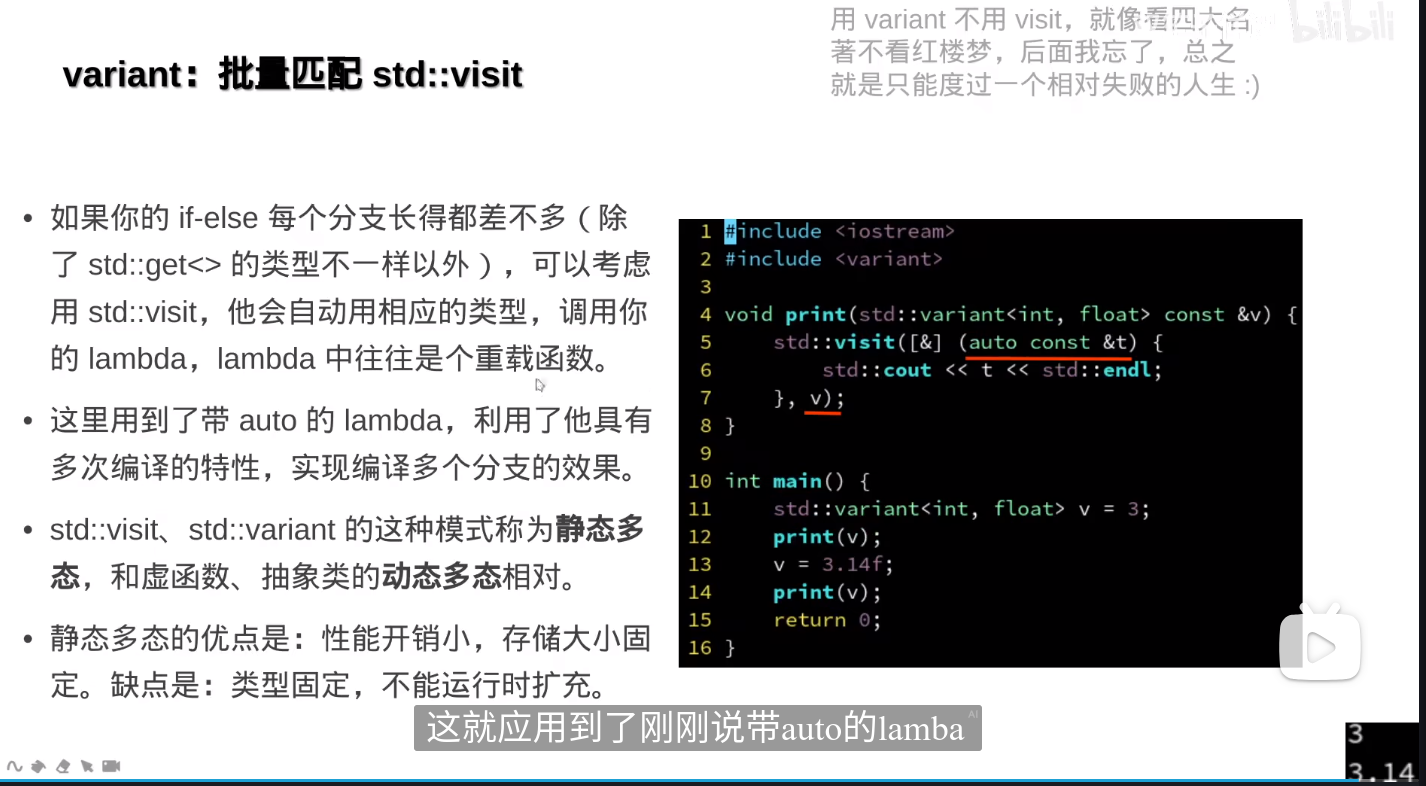
- 使用
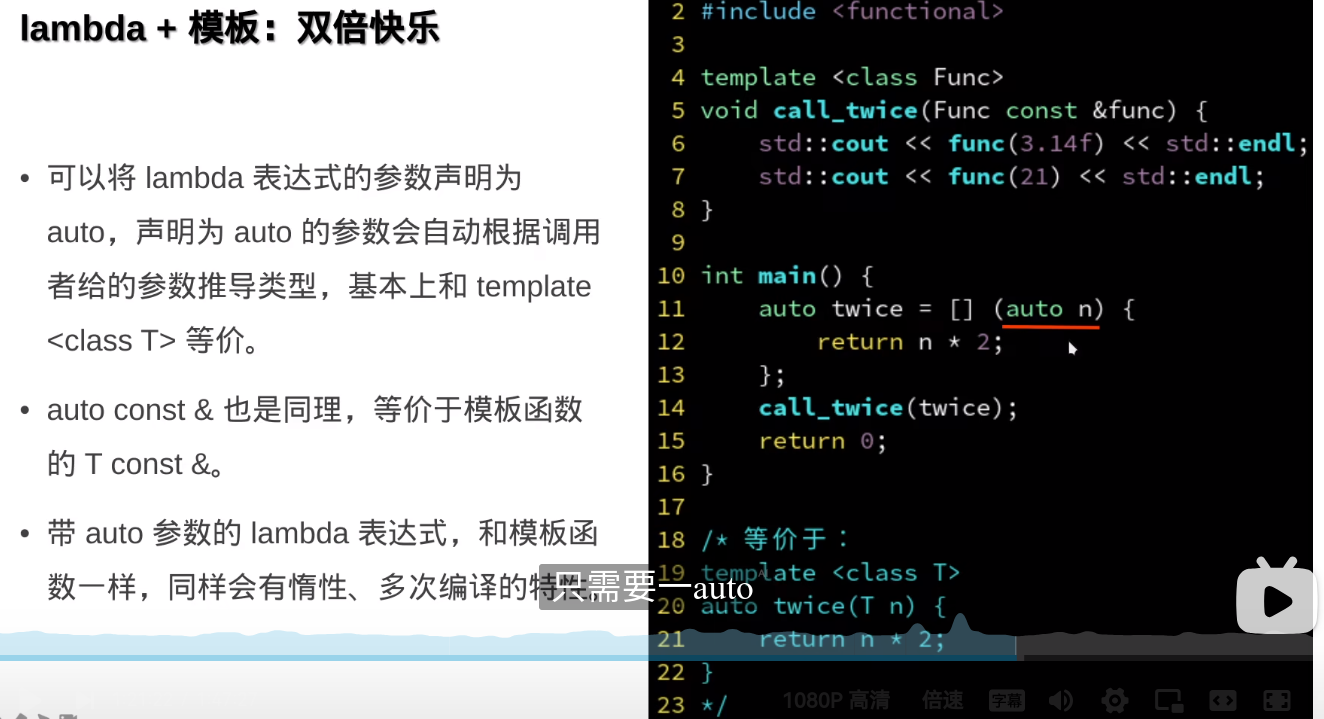
auto作为参数类型实际上利用了 C++ 的模板机制,因为auto类型推断相当于模板类型参数的自动推导。虽然 lambda 本身不是一个模板,但它的参数使用auto实际上是利用了模板的类型推断机制。 [&] (auto const &t){}使用了模板特性中的类型推断机制,通过auto使得 lambda 表达式能够处理多种不同类型的参数。这个功能在 C++11 及其后续版本中成为了更灵活、强大的工具,使得代码更加简洁和通用。

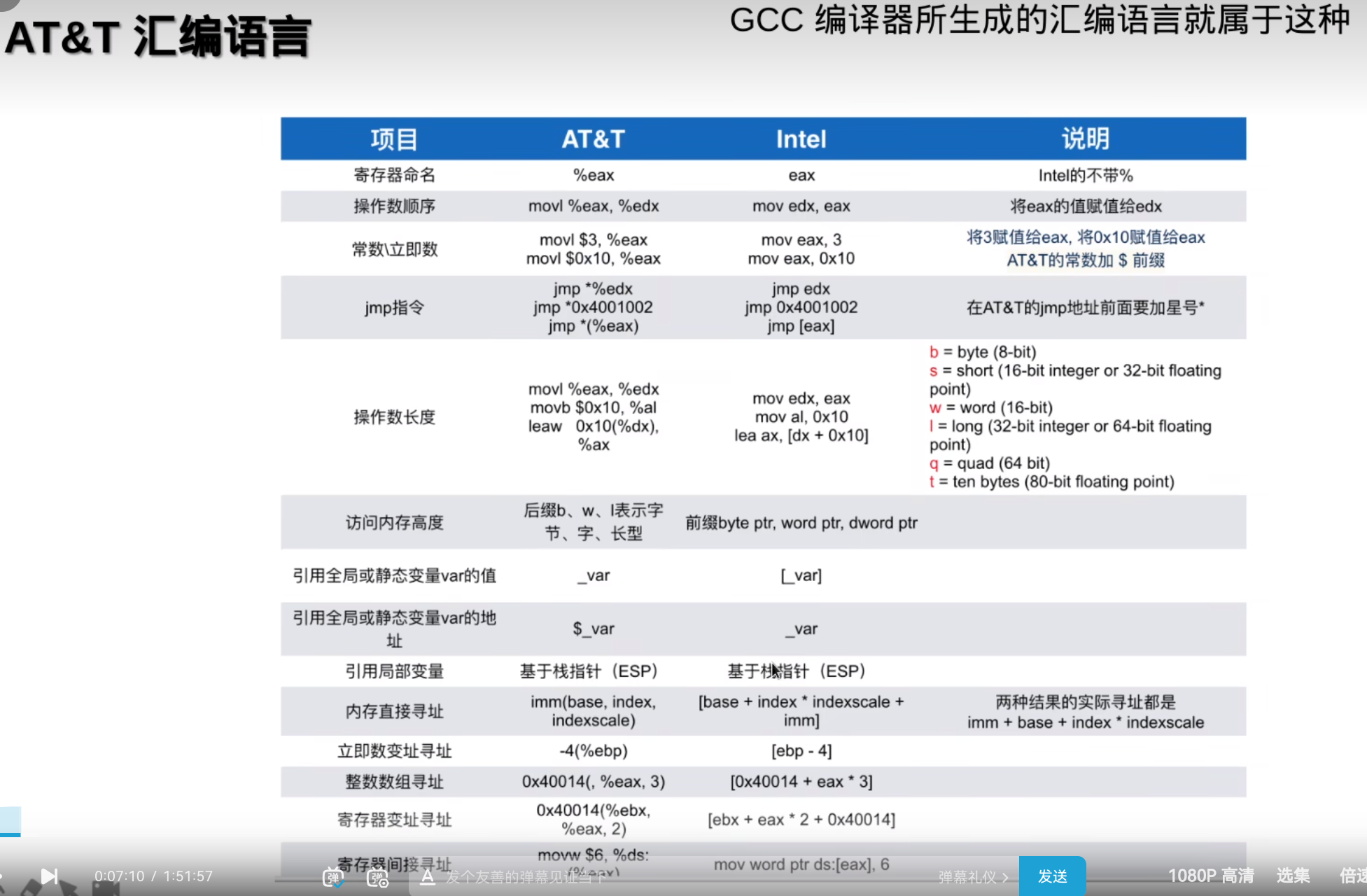
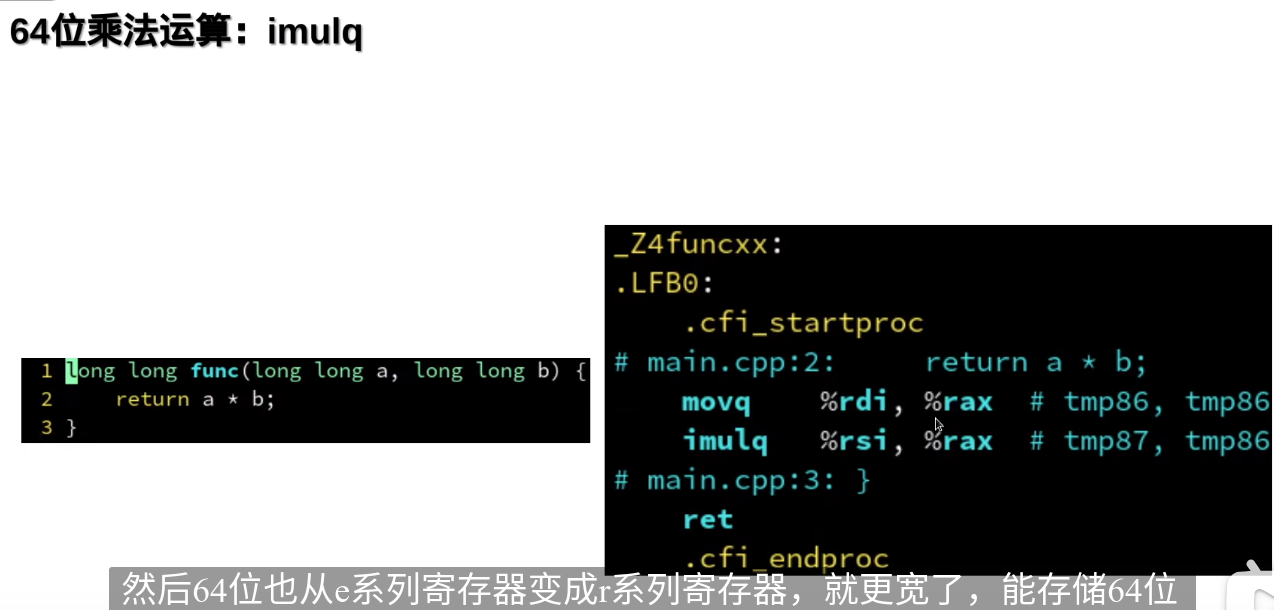
从汇编角度看编译器优化
编译器是从源代码生成汇编语言

RIP是当前执行的代码的地址
MMX,XMM,YMM都是用于储存浮点数的寄存器
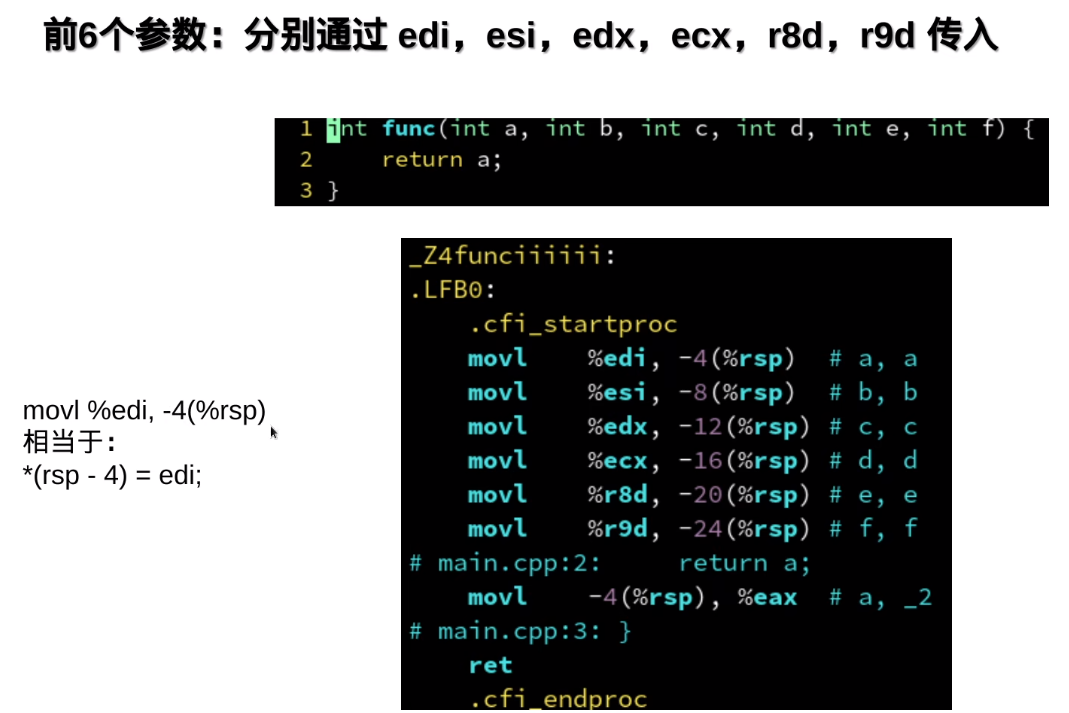
把局部变量放入寄存器,读写就更快了
rsp代表堆栈: -4(%rsp)其中-代表是堆栈上的某一个地址


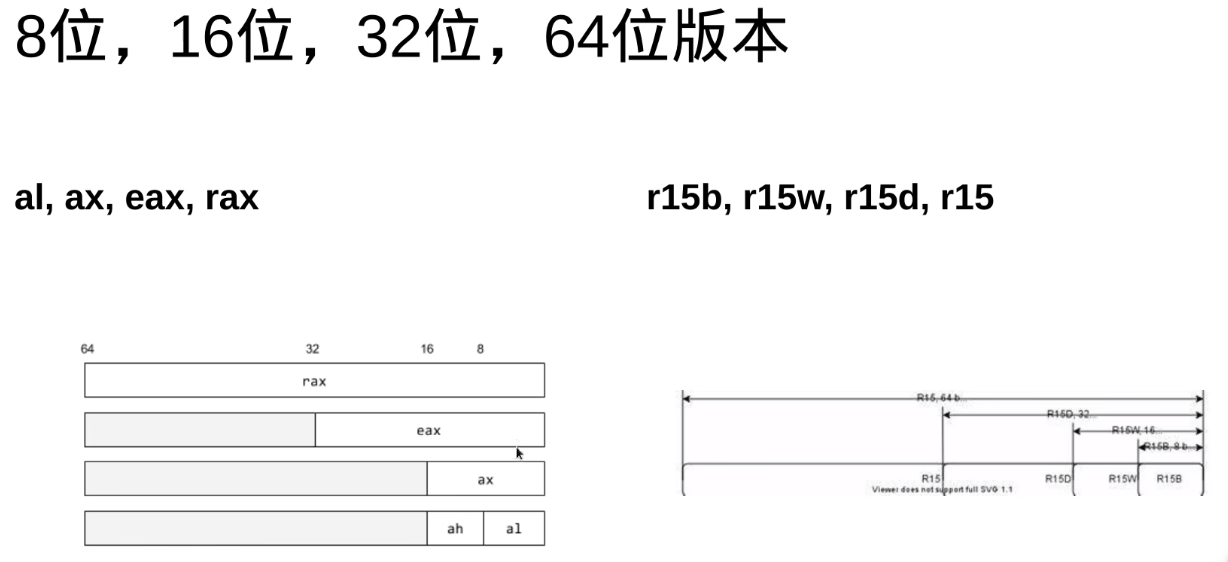
eax与rax的低32位是共用的
ax与eax的低16位是通用的
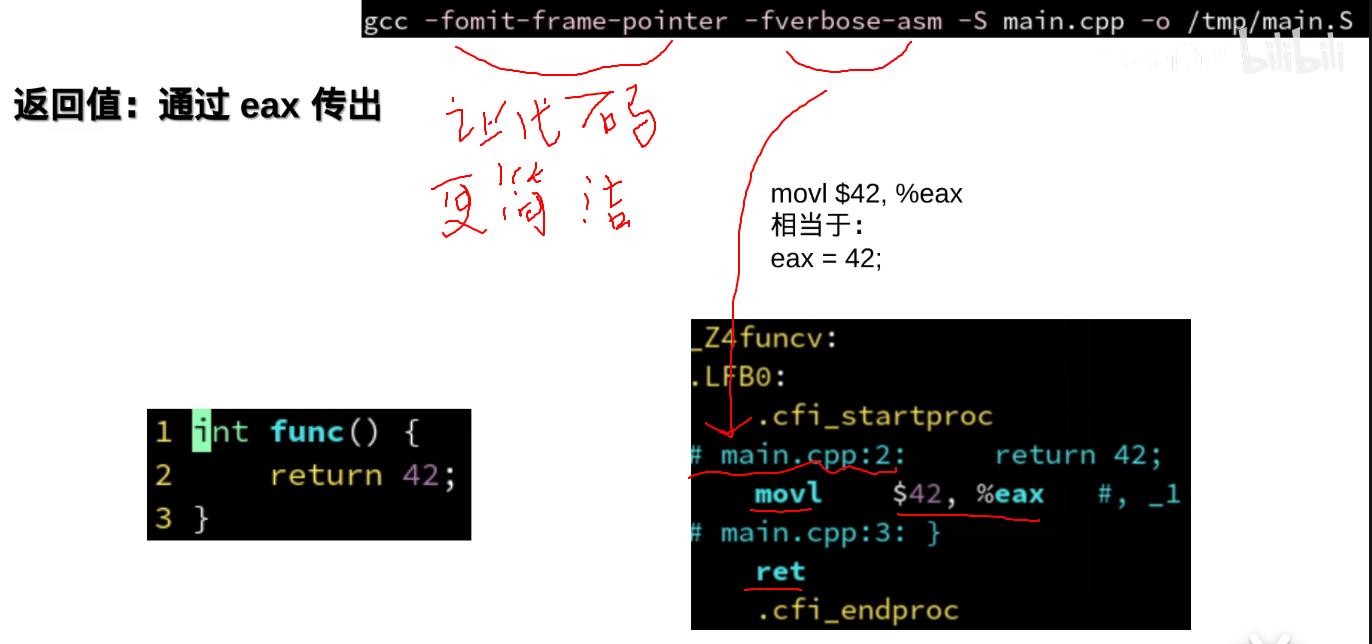 %eax :返回值
%eax :返回值
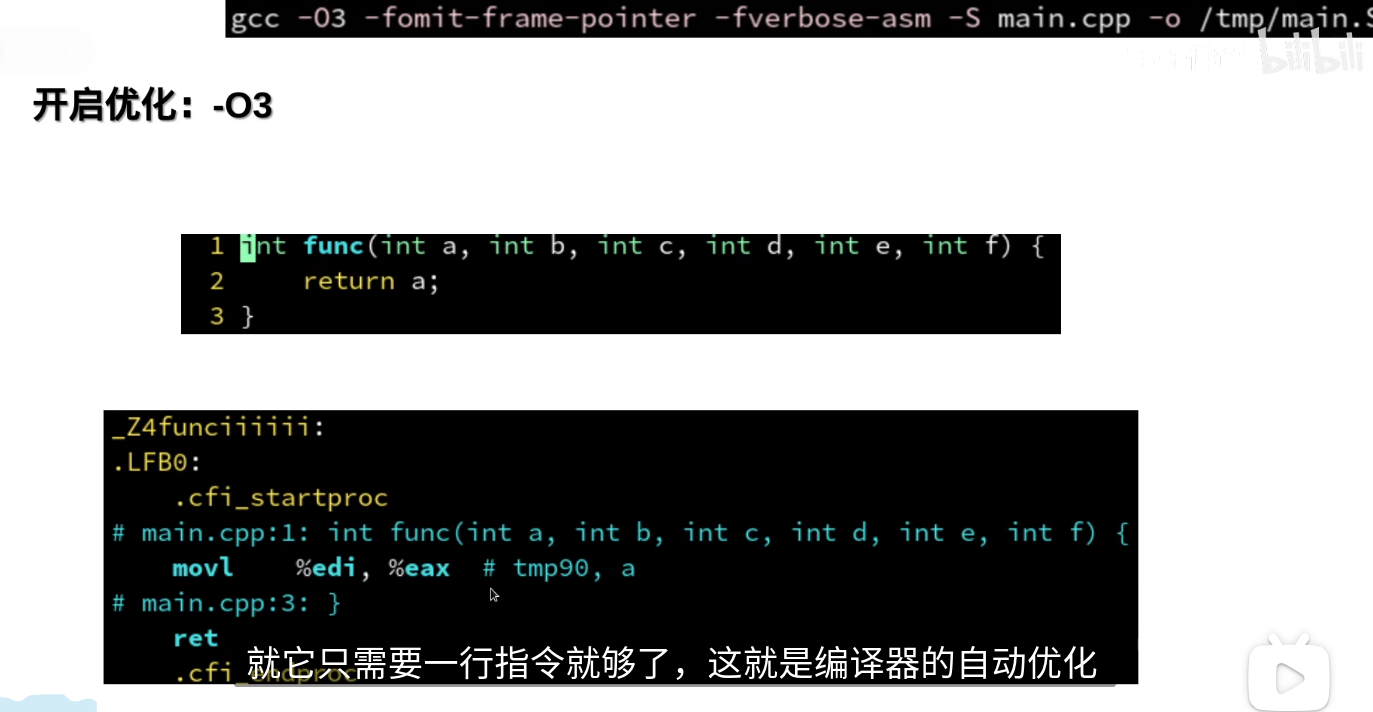

l代表32位,q代表64位


在 C++ 中,ThreadPool threadPool {}; 和 ThreadPool threadPool ; 是两种不同的初始化方式,它们对 ThreadPool 对象的初始化有所不同。
1. ThreadPool threadPool {};
这是 直接初始化(Direct Initialization) 的一种方式,使用了 统一初始化语法(Uniform Initialization Syntax)。具体来说,这种写法会调用 ThreadPool 的默认构造函数,并且初始化所有成员变量为默认值:
- 如果
ThreadPool有默认构造函数,它将被调用来创建对象。 - 如果
ThreadPool的构造函数没有显式初始化某些成员变量,它们会被自动初始化为其类型的默认值。对于基本数据类型(如int),这意味着它们会被初始化为0。对于指针类型,它们会被初始化为nullptr。
2. ThreadPool threadPool ;
这是 默认初始化(Default Initialization) 的一种方式。在这种情况下,ThreadPool 对象的初始化行为依赖于以下几种情况:
- 如果
ThreadPool有默认构造函数,它将被调用来创建对象。 - 如果
ThreadPool的构造函数没有显式初始化某些成员变量,那么这些成员变量的初始化方式依赖于它们的类型和是否有默认构造函数。基本数据类型(如int)不会被初始化到任何特定值(它们会是未定义的),指针类型也不会自动初始化(它们的值是不确定的)。
总结
- **
ThreadPool threadPool {};**:使用统一初始化语法,所有成员变量被初始化为其类型的默认值,较为安全。 ThreadPool threadPool ;:默认初始化,成员变量的初始值依赖于其类型和构造函数,可能会导致未定义行为(对于基本数据类型)。
在实践中,推荐使用 ThreadPool threadPool {}; 以确保对象的成员变量被正确地初始化,避免潜在的未定义行为。
在对象构造时,std::lock_guard 会自动锁定传入的互斥锁,而在对象析构时,它会自动释放锁
std::lock_guard<std::mutex> guard(lock);
当执行 std::lock_guard<std::mutex> guard(lock); 时:
- 锁定:
guard对象在创建时会自动调用lock()方法来锁定传入的互斥锁(lock)。 - 作用域结束: 当
guard对象的作用域结束(例如,离开当前的代码块或函数)时,它的析构函数会自动调用unlock()方法来解锁互斥锁
要理解 subset 中的这行数据,我们可以将其拆解成几部分来分析:
[[ 0. 1. 2. 3. 4. 5.
6. 7. 8. -1. -1. 9.
-1. -1. 10. 11. 12. -1.
21.50975911 13. ]]
1. 关键点索引
- 前 18 个值
[0, 1, 2, 3, 4, 5, 6, 7, 8, -1, -1, 9, -1, -1, 10, 11, 12, -1]代表了关键点的索引。- 正整数表示该位置有一个有效的关键点索引。
-1表示该位置没有对应的关键点。
2. 总评分
21.50975911是这个组合的总评分。这个评分是所有有效关键点的评分之和或某种加权评分的结果。
3. 关键点数量
13是这个组合中的有效关键点数量。这里13表示在该组合中共有 13 个有效的关键点索引。
结合信息
这个 subset 行数据表示一个关键点组合,其中包含 13 个有效的关键点,所有这些关键点的索引被列出。组合的总评分为 21.50975911。通过这些信息,你可以了解该组合的结构以及它在某种评分机制下的表现。
详细解读:
- 有效关键点索引为
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],总共 13 个。 - 索引为
-1的位置表示这些位置没有有效的关键点。 - 总评分
21.50975911可能是根据这些有效关键点的某些特性(如评分、置信度等)计算出来的。
这样的 subset 数据通常用于在处理关键点检测任务中,选择或评估最佳的关键点组合。
这个是candidate: [[2.19000000e+02 1.18000000e+02 9.45192695e-01 0.00000000e+00] [1.96000000e+02 2.63000000e+02 9.28416848e-01 1.00000000e+00] [8.70000000e+01 2.89000000e+02 8.54923248e-01 2.00000000e+00] [6.60000000e+01 4.49000000e+02 8.24636817e-01 3.00000000e+00] [1.20000000e+02 5.07000000e+02 7.98071980e-01 4.00000000e+00] [3.07000000e+02 2.38000000e+02 8.55016530e-01 5.00000000e+00] [3.64000000e+02 3.76000000e+02 7.69826353e-01 6.00000000e+00] [2.81000000e+02 4.45000000e+02 8.87847126e-01 7.00000000e+00] [1.68000000e+02 5.42000000e+02 4.70188409e-01 8.00000000e+00] [2.98000000e+02 5.27000000e+02 4.78751719e-01 9.00000000e+00] [1.94000000e+02 1.03000000e+02 9.33498561e-01 1.00000000e+01] [2.30000000e+02 1.02000000e+02 9.27351594e-01 1.10000000e+01] [1.35000000e+02 1.22000000e+02 8.83832693e-01 1.20000000e+01]] 这个是subset: [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. -1. -1. 9. -1. -1. 10. 11. 12. -1. 21.50975911 13. ]]
“Stack underflow”和“stack overflow”都是与栈(stack)数据结构相关的错误,但它们的含义和发生的情况不同:
Stack Overflow(栈溢出)
- 定义:栈溢出发生在栈的大小超过其最大容量时。通常是由于过深的递归调用或在栈上分配了过多的局部变量导致的。
- 后果:栈溢出通常会导致程序崩溃或异常终止,因为系统无法继续在栈上分配内存。
Stack Underflow(栈下溢出)
- 定义:栈下溢出发生在试图从空栈中弹出元素时。例如,尝试执行“pop”操作但栈为空。
- 后果:栈下溢出可能导致访问未定义的内存,程序可能会抛出异常或返回错误。
总结
- 溢出(overflow):栈容量超出限制。
- 下溢(underflow):试图从空栈中移除元素。
NULL 是一个预处理宏,通常被定义为 0 或 ((void*)0)。它在类型上是一个整数,因此可能导致类型不安全的情况。
nullptr是 C++11 引入的一个关键字,表示空指针。它是一个特定的类型std::nullptr_t,能更好地支持类型安全。OpenGL 上下文:OpenGL 上下文是一个包含了所有 OpenGL 状态的信息的环境。每个窗口通常会有一个自己的上下文。
gcc -E main.cpp | tail -n 15 是什么意思
gcc -E main.cpp | tail -n 15 是一个命令行指令,具体含义如下:
gcc:GNU 编译器集合,用于编译 C 和 C++ 程序。-E:该选项告诉gcc只进行预处理,即处理源代码中的宏和包含文件,但不进行编译。main.cpp:要处理的源文件。|:管道符,用于将前一个命令的输出传递给后一个命令。tail -n 15:该命令输出前一个命令的最后 15 行。
因此,整个命令的作用是预处理 main.cpp 文件,并显示预处理后的结果的最后 15 行。这通常用于调试宏和包含的头文件。
constexpr
编译时常量
在编译时计算
结合 if constexpr 根据条件选择性编译代码
__attribute__((inline)) 是 GCC 和 Clang 编译器中的一个扩展,用于建议编译器将某个函数内联。内联函数的目的是减少函数调用的开销,通过将函数代码直接插入到调用处来提高性能。
- 性能优化:可以减少函数调用的开销,尤其是在小型函数中。
- 不强制:即使使用了
inline属性,编译器仍然可以选择不内联,具体取决于优化策略和函数的复杂性。 - 适用场景:通常用于小的、频繁调用的函数。
把std::string opengl_errno_name(int err)改成static const char *opengl_errno_name(int err)的好处
将 std::string opengl_errno_name(int err) 改为 static const char *opengl_errno_name(int err) 的好处包括:
- 性能提升:使用
const char*可以减少内存分配和拷贝操作,提高性能,尤其在频繁调用的情况下。 - 内存管理:
const char*不需要动态分配内存,避免了内存泄漏的风险,使用起来更加安全。 - 简单性:直接返回字符串字面量或静态数组,使代码更简洁,减少不必要的复杂性。
- 更好地适应 C 风格 API:在与 C 语言库交互时,使用
const char*更加兼容。
#include <GL/gl.h> 和 #include <GL/glu.h> 是 OpenGL 的头文件,它们用于图形编程。具体来说:
- **
<GL/gl.h>**:- 包含了 OpenGL 的核心函数和常量,提供了绘制图形所需的基本接口,比如渲染点、线、三角形等几何图形,以及设置视图、光照、纹理等功能。
- **
<GL/glu.h>**:- 提供了一些辅助功能和工具,简化了 OpenGL 的使用。例如,它包含了用于生成和操作网格、处理矩阵变换、创建透视和正交投影等的函数。
#include <GLFW/glfw3.h> 是用于包含 GLFW 库的头文件,GLFW 是一个开源的跨平台库,主要用于创建窗口、处理用户输入以及管理 OpenGL 上下文。具体功能包括:
- 创建和管理窗口:可以创建多种类型的窗口,并设置其属性。
- 处理输入:支持键盘、鼠标和游戏手柄输入,方便处理用户交互。
- 上下文管理:简化 OpenGL 上下文的创建和管理,使得在窗口中进行图形渲染更为高效。、
#include <glm/glm.hpp> 和 #include <glm/ext.hpp> 是用于包含 GLM(OpenGL Mathematics)库的头文件。具体功能如下:
- **
<glm/glm.hpp>**:- 提供基础数学类型和操作,例如向量、矩阵、四元数等,支持高效的数学运算,适用于图形编程和物理计算。
- **
<glm/ext.hpp>**:- 包含一些扩展功能,比如矩阵变换、投影、视图等常用数学函数,方便进行更复杂的数学运算。
GLM 常用于 OpenGL 应用程序中,以简化数学计算和数据管理。
❥ 基本
jk / kj /
q / :wq / ZZ 保存并退出
Q 记录宏
gl / $ 移动到行末尾
gh / ^ 移动到行开头(不包括空格)
3gl / $2l 移动到行末尾倒数第 3 个字符
3gh / ^2h 移动到行开头倒数第 3 个字符
❥ 跳转
gd 跳转到定义
gD 跳转到声明
gy 跳转到变量类型的定义
gY 跳转到虚函数实现
go 头文件和源文件来回跳转
gr 寻找符号引用
gz 罗列所有相关信息(定义、引用等)
gf 打开光标下的文件名
gF 打开光标下的文件名并跳到右侧指定的行号
gx 打开光标下的网页链接
❥ 重构
gcc 注释/取消注释当前选中的代码/行
gn 重命名变量
gw 尝试自动修复问题
g= 自动格式化当前代码
❥ 预览
K 悬浮窗查看文档
gsf 预览函数定义
gsc 预览类定义
gsd 预览语法错误
❥ 开关
gso 打开大纲
gsg 打开 Git 面板
gsp 打开项目文件树
gss 查看所有静态语法错误
gsl 查看所有编译器报错
gsi 开关 Inlay Hint
❥ 标签页
g
❥ 文本查找
,, 当前文件中模糊查找
,k 当前项目中正则表达式查找
,l 当前项目中的所有文件
,b 当前 Vim 已打开文件
,o 最近打开过的历史文件
,i 当前所有加入 Git 仓库的文件
,p 当前 Git 有未提交修改的文件
,c 所有 Git 提交历史
,v 所有 Git 分支
❥ 选择
vac 选中当前类
vic 选中当前类体内
vaf 选中当前函数
vif 选中当前函数体
vab 选中当前块
vib 选中当前块中内容
vai 选中当前函数调用语句
vii 选中当前函数调用语句的参数列表
vap 选中当前参数(包括逗号)
vip 选中当前参数(不包括逗号)
vin 选中当前数字
vat 选中当前注释块
- 扩大选择
- 缩小选择
举一反三:dat 删除当前注释块,cip 修改当前参数
❥ 移动
]c 下一个类开头
[c 上一个类开头
]C 下一个类结尾
[C 上一个类结尾
]f 下一个函数开头
[f 上一个函数开头
]F 下一个函数结尾
[F 上一个函数结尾
…以此类推,所有英文字母同上“选择”所述…全屏任意移动
❥ 换位
mh 左移参数
ml 右移参数
mj 下移当前语句
mk 上移当前语句
maf 下移当前函数
mif 上移当前函数
mac 下移当前类
mic 上移当前类
❥ 括号
可视模式中:
s) 给当前选中内容包上 () 括号
s} 给当前选中内容包上 {} 括号
s] 给当前选中内容包上 [] 括号
s> 给当前选中内容包上 <> 尖括号
s’ 给当前选中内容包上 ‘’ 单引号
s” 给当前选中内容包上 “” 双引号
stspan 给当前选中内容包上标签
sta href=”b.html” 给当前选中内容包上标签
普通(NORMAL)模式中:
ysi添加括号
cs改变括号
ds删除括号
❥ CMake
cmc 或 :CMakeGenerate 配置当前项目
cmb 或 :CMakeBuild 构建当前项目
cmr 或 :CMakeRun 运行当前项目
cms 或 :CMakeStopRunner 杀死当前终端中的正在运行的程序
❥ 文件树
y 拷贝
x 剪切
d 删除
p 粘贴
a 创建
ALT+shift+左右箭头 跳转
pendulum:
joint_state_controller:
publish_rate: 100
type: joint_state_controller/JointStateController
x_controller:
joint: base_to_plat
type: effort_controllers/JointEffortController
其中joint_state_controller和x_controller是什么意思 这个文件的作用是什么
1. joint_state_controller
- 用途:这个控制器用于发布机器人的关节状态(例如位置、速度和加速度)到 ROS 主题。它通常是机器人系统中的基础控制器,负责获取各个关节的状态信息并将其传递给其他组件。
- 类型:
joint_state_controller/JointStateController是一个标准的控制器类型,用于处理关节状态的更新。 joint_state_controller是用于发布所有关节状态信息的控制器。它会收集机器人的所有关节(如位置、速度和加速度)的状态,并将这些信息发布到 ROS 主题上,通常是/joint_states主题。- publish_rate:表示发布关节状态的频率,这里设置为 100 Hz。
2. x_controller
- 用途:这个控制器用于控制名为
base_to_plat的关节的努力(力或扭矩)。通常用于执行某种运动控制任务,比如驱动一个关节以实现预期的动态行为。 - 类型:
effort_controllers/JointEffortController是一个控制器类型,专注于控制关节施加的力或扭矩。
文件的作用
这个文件主要是用于配置 ROS 控制器管理器,定义机器人各个关节的控制方式及其参数。通过这个配置,您可以在启动时自动加载和初始化这些控制器,使得机器人能够实时进行关节状态的监测和控制。
总结
joint_state_controller负责关节状态的信息发布。x_controller则用于具体关节的力量控制。- 整个 YAML 文件用于配置和管理这些控制器,使机器人能够有效地执行控制任务。
##并发
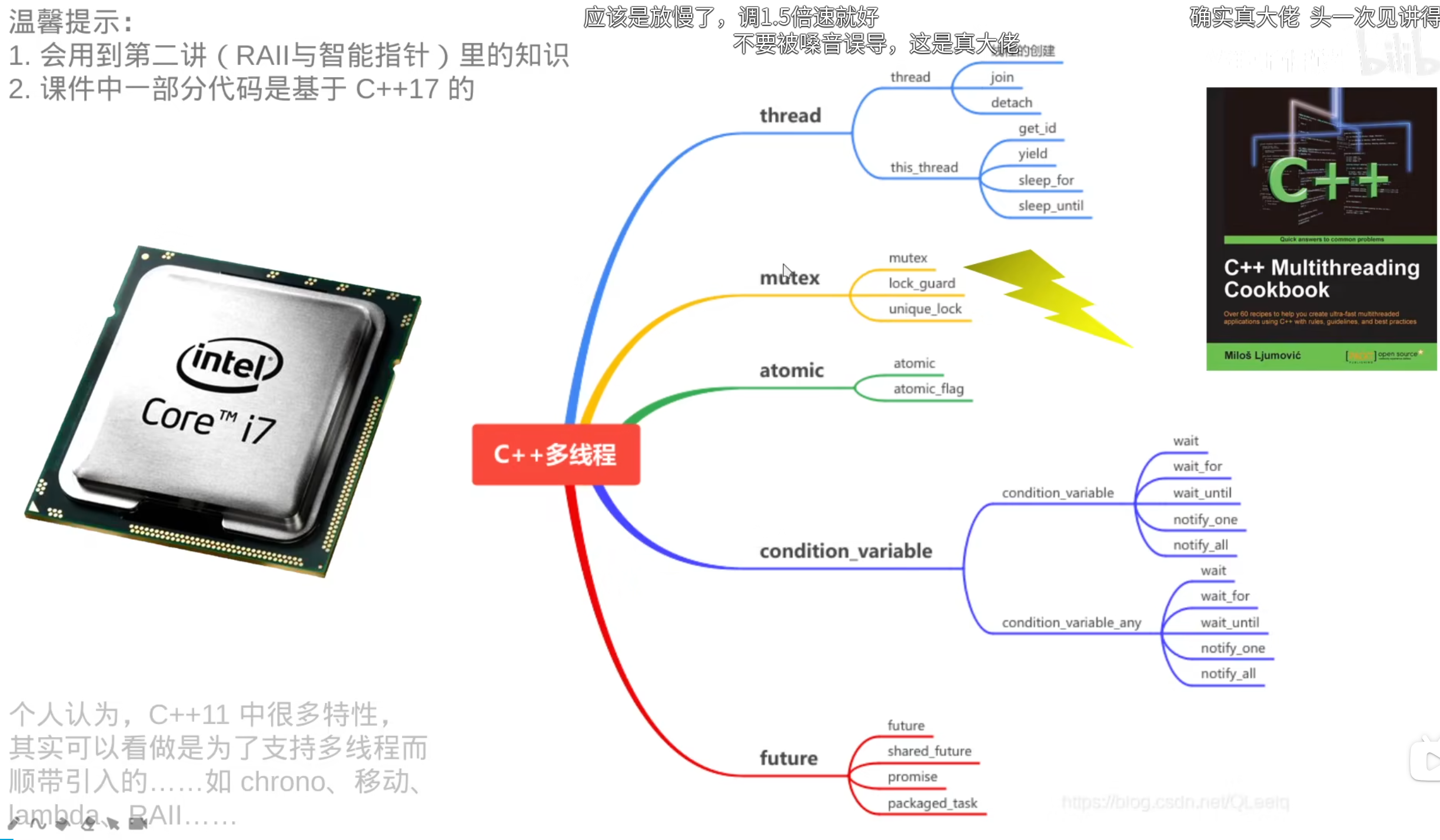
###0.时间 time

###1.线程 thread

join汇合加入,把子线程加到主线程里,这样主线程只有在子线程结束后才会退出

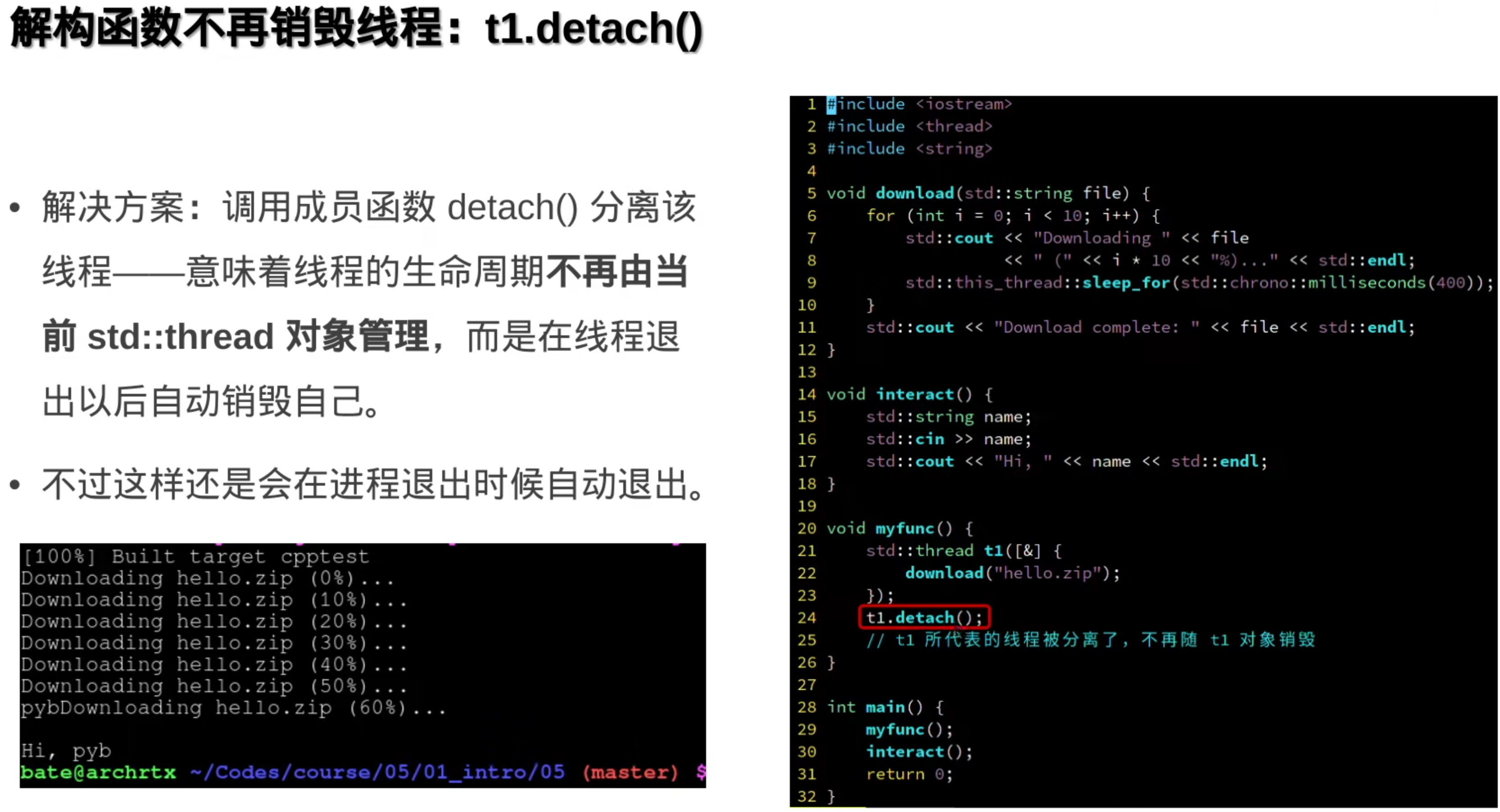
当想要对线程进行封装时,会发现线程会随着封装函数执行过去而被销毁(因为thread的析构函数):

使用detach(),还是不行(因为没用join,主线程不会等子线程):
全局变量,生命周期会大于封装函数,join,等待子线程: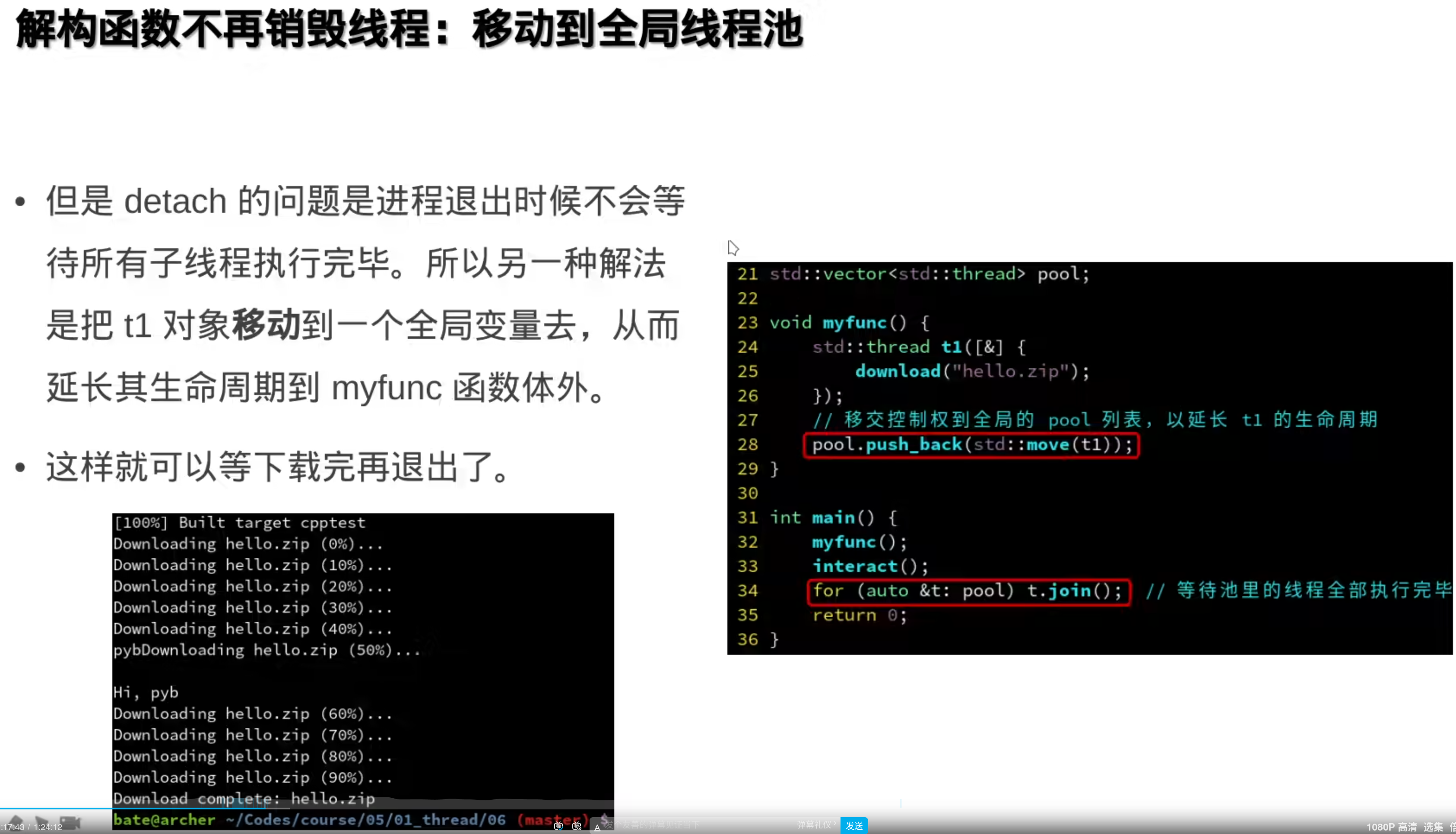
利用析构函数简化: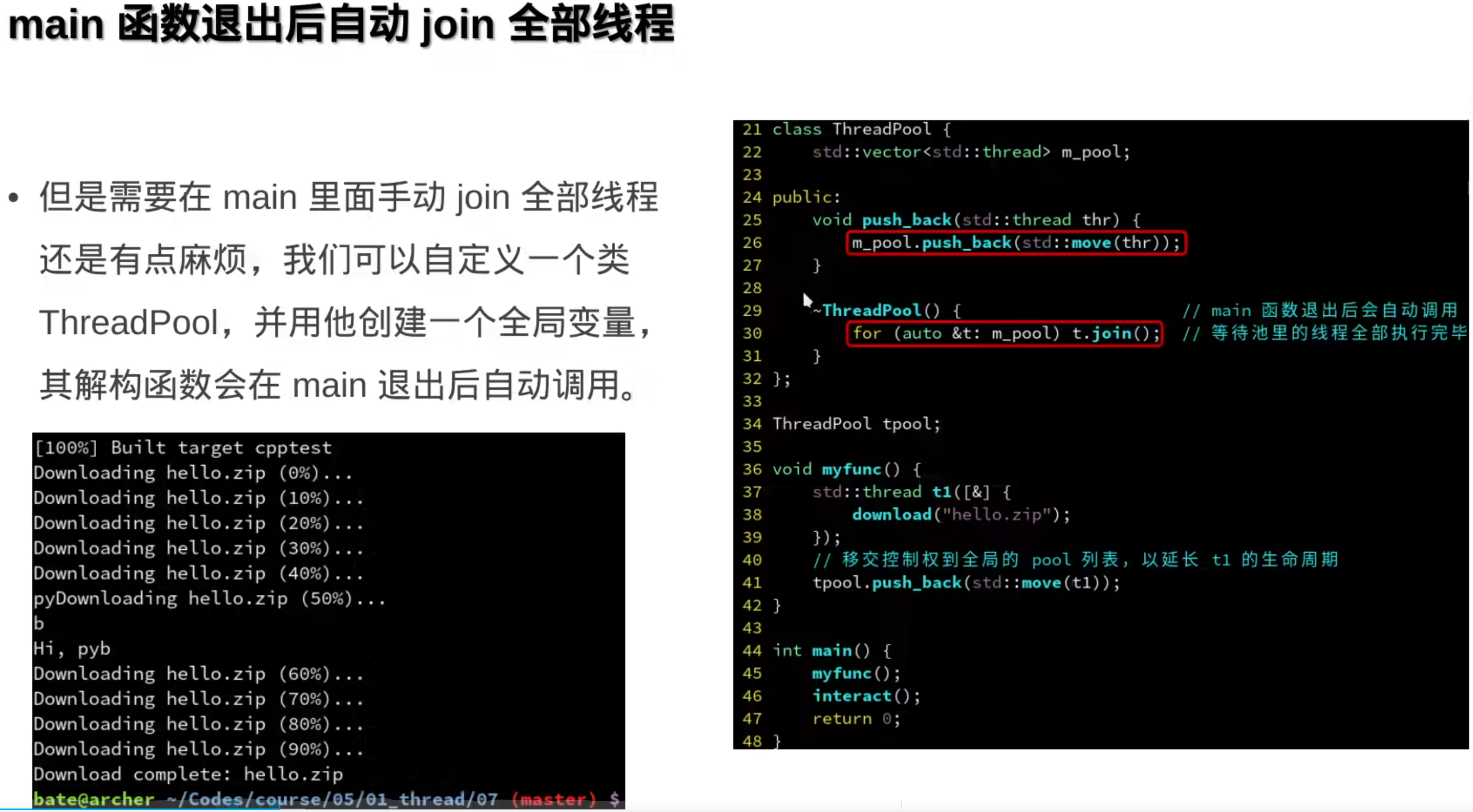
再简化,标准函数帮你把析构函数写了:

2.异步async
异步相当于thread的帮手函数,专注于任务本身而不是底层的线程管理,不用那么底层了,使用简单了,但是能力也就下降了。
std::async 和 std::thread 都是 C++11 引入的用于处理并发和多线程编程的工具,但它们在设计目的、使用方式和抽象级别上存在一些关键的关系与区别。以下是它们之间的详细比较:
关系
- 都属于 C++ 标准库:两者都是 C++11 提供的并发支持的一部分,旨在简化多线程编程。
- 功能互补:尽管各自的设计有不同侧重点,但它们可以一起使用。例如,可以在
std::async中使用std::thread,或者在创建线程时使用std::async来管理结果。
区别
| 特性 | std::thread |
std::async |
|---|---|---|
| 抽象级别 | 更低级别的线程管理 | 更高层次的异步任务管理 |
| 线程控制 | 开发者需要手动管理线程的生命周期(启动、加入、分离) | 自动管理线程的生命周期,返回 std::future |
| 执行策略 | 一般立即启动新线程 | 可选择立即执行或延迟执行(std::launch::async 或 std::launch::deferred) |
| 结果处理 | 返回值需要通过共享数据或其他同步机制来获取 | 通过 std::future 对象直接获取结果 |
| 异常处理 | 异常不会传播到主线程,需要手动管理 | 异常会被捕获并在调用 future.get() 时重新抛出 |
| 适用场景 | 需要细致控制线程行为的场景,如实时系统、服务器等 | 简单的异步任务、并行计算、提高程序响应性 |
使用示例
使用 std::thread 的示例:
#include <iostream>
#include <thread>
void task() {
std::cout << "Task is running in a separate thread.\n";
}
int main() {
std::thread t(task);
t.join(); // 等待线程完成
return 0;
}
使用 std::async 的示例:
#include <iostream>
#include <future>
int task() {
return 42; // 返回结果
}
int main() {
std::future<int> result = std::async(task);
std::cout << "Result from async task: " << result.get() << '\n'; // 获取结果
return 0;
}
总结
- **选择使用
std::thread**:当你需要更细粒度的线程控制,或者需要实现复杂的线程交互时。 - **选择使用
std::async**:当你希望简化异步任务的管理,并专注于任务本身而不是底层的线程管理时。
根据具体的需求和场景,开发者可以灵活选择这两者中的一种或结合使用。
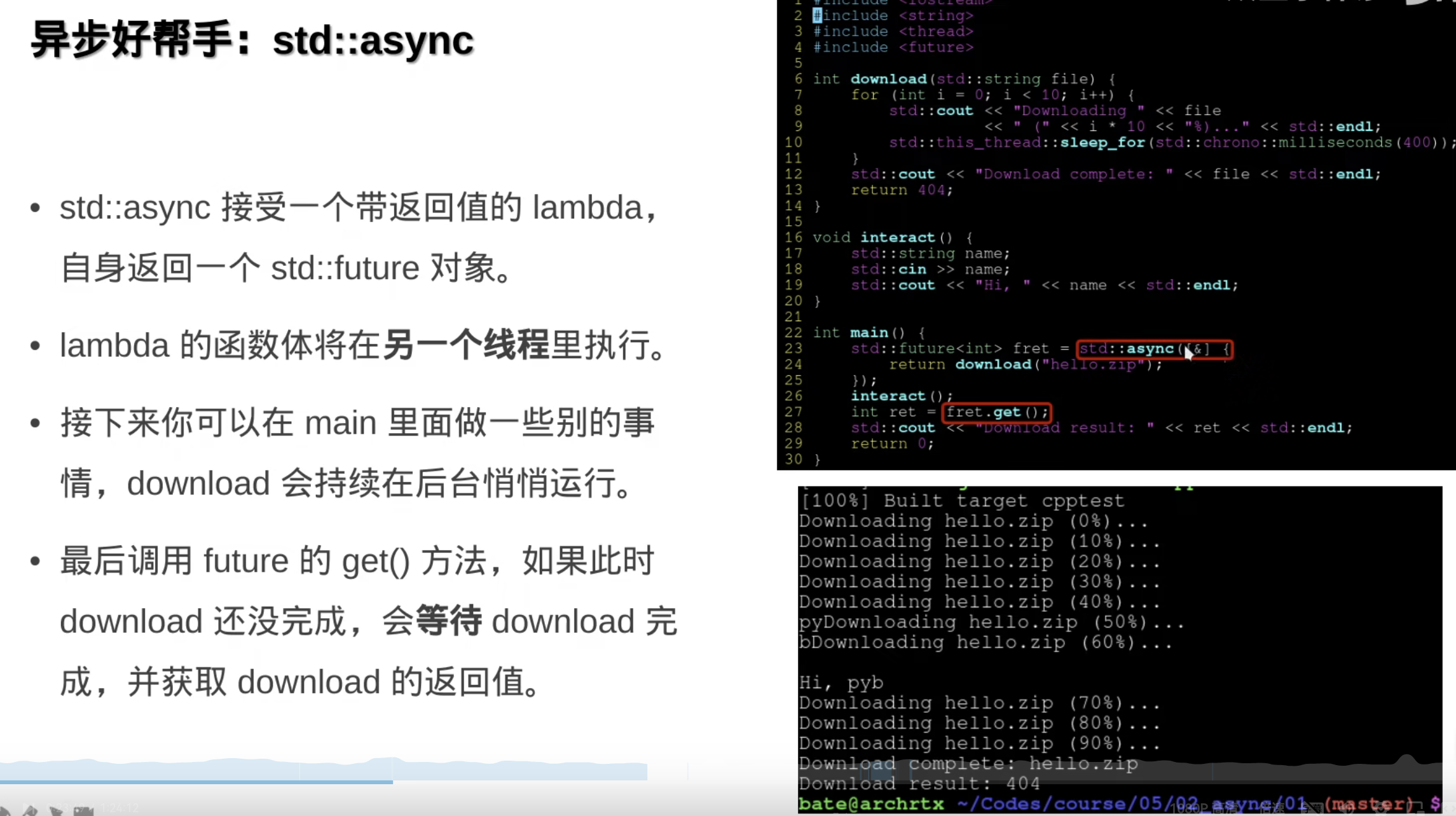

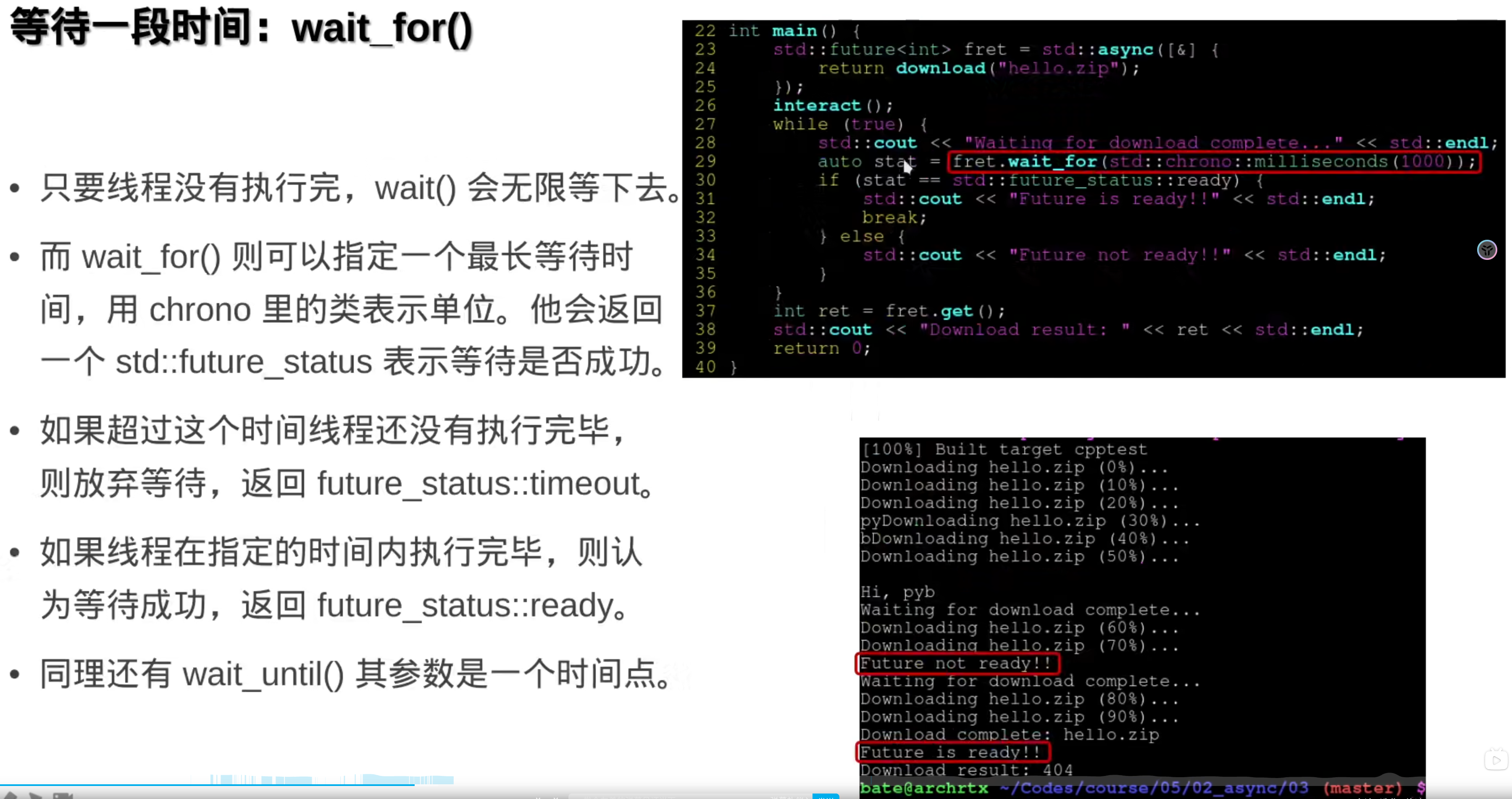
std::async相当于在后台开一个线程偷偷执行,如果不想用线程的话,可以用假线程:

std::async的底层实现:(应该用不到吧)

3.互斥量

std::lock_guard grd(mtx); // 创建 lock_guard 对象 grd,锁定 mtx
这个有个弊端:不能提前unlock,可以用std::unique_lock:

如果你即想使用unique_lock的自动解锁,又想手动lock:

这个是已经上锁了,又想使用自动解锁:
4.死锁
问题一:

不要同时锁两个
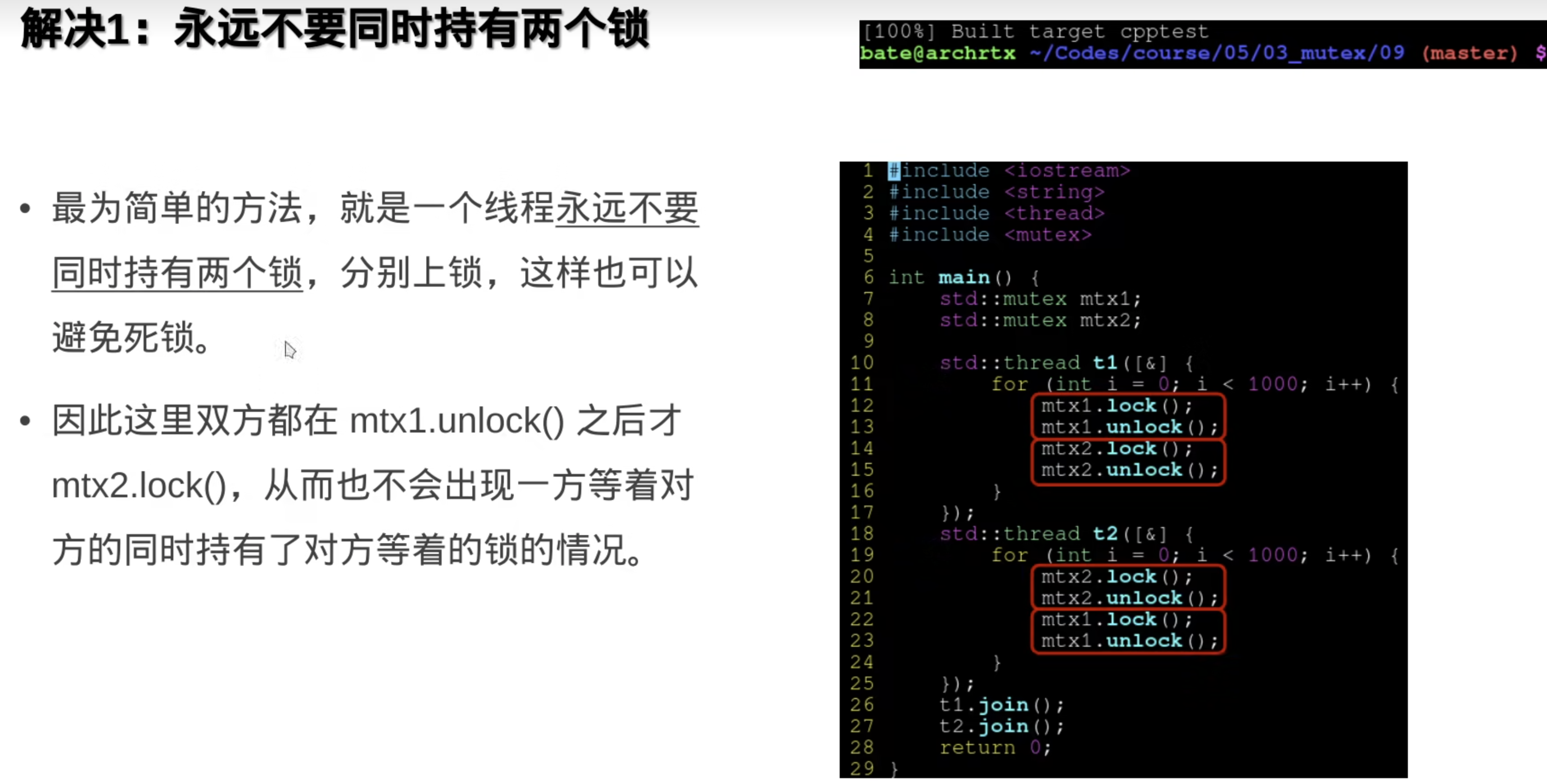
保证线程里上锁的顺序一样
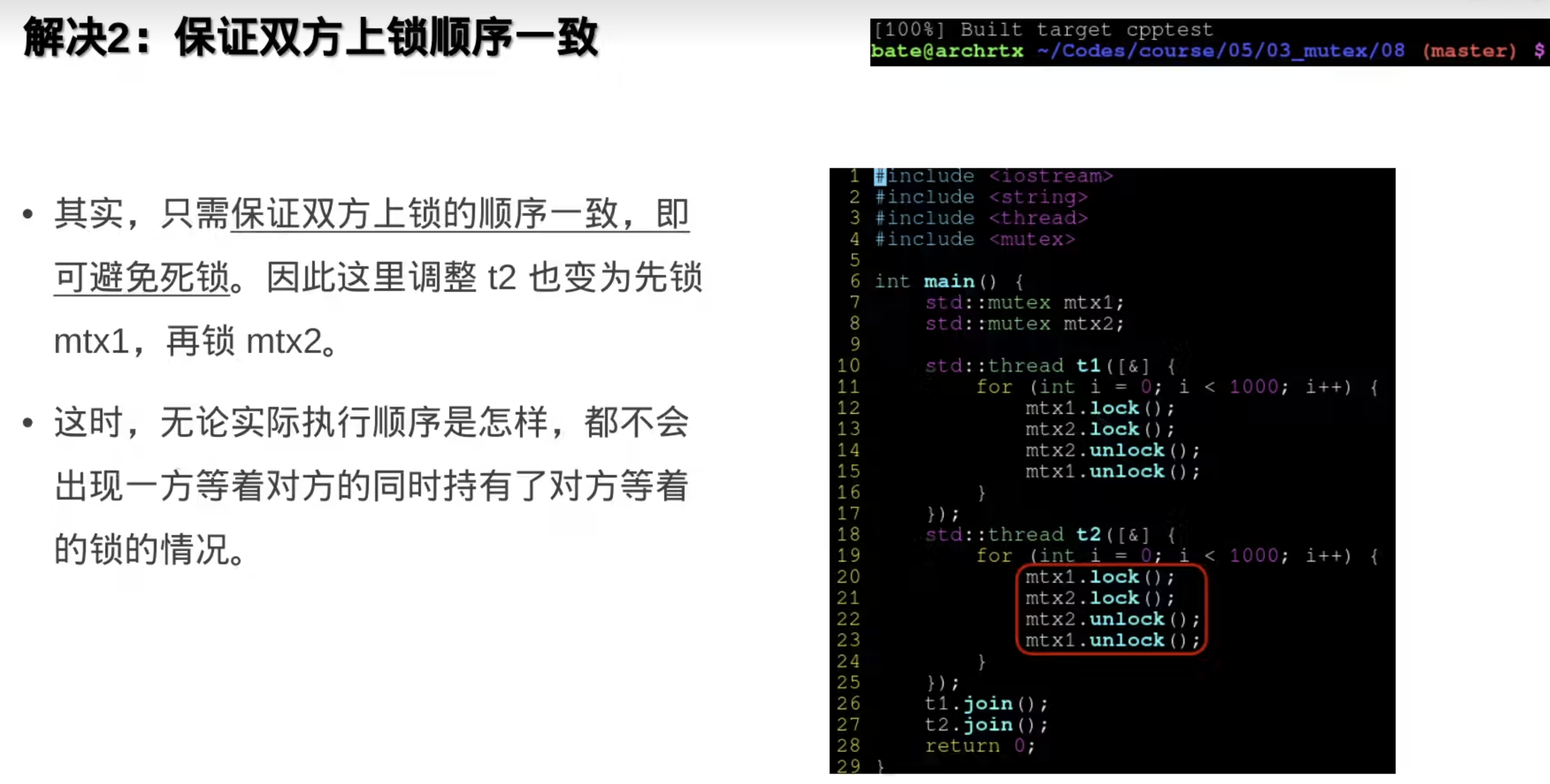
使用标准库里的std::lock

同样,为了避免忘记解锁,有了一个RALL版本的std::lock
问题二:

std::recursive_mutex

5.数据结构

封装一下:
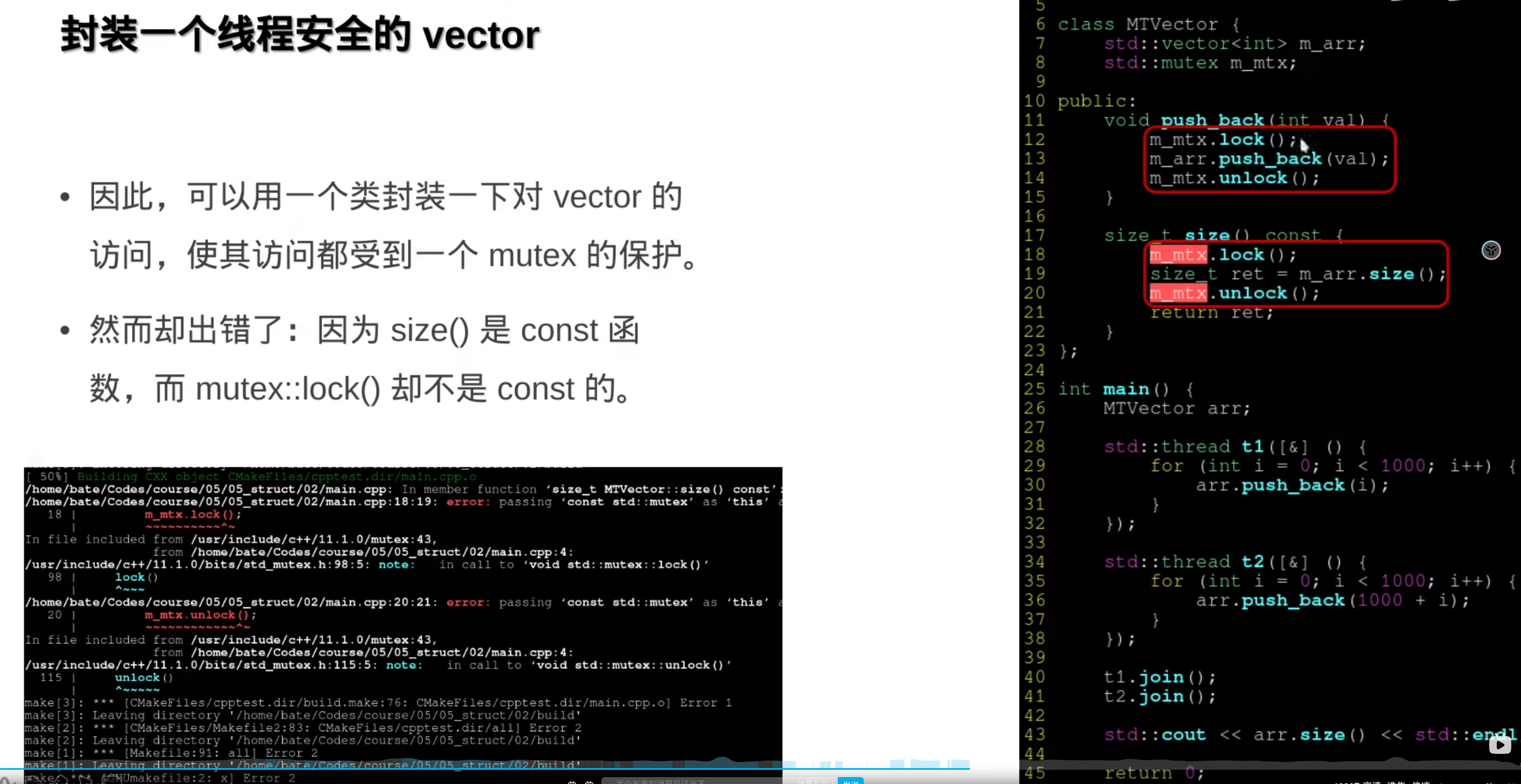
因为mutex::lock()不是const的 ,那么使用mutable修饰一下:

####读写锁:

std::shared_mutex
lock()的RAII是std::unique_lock
lock_shared()的RAII是std::shared_lock


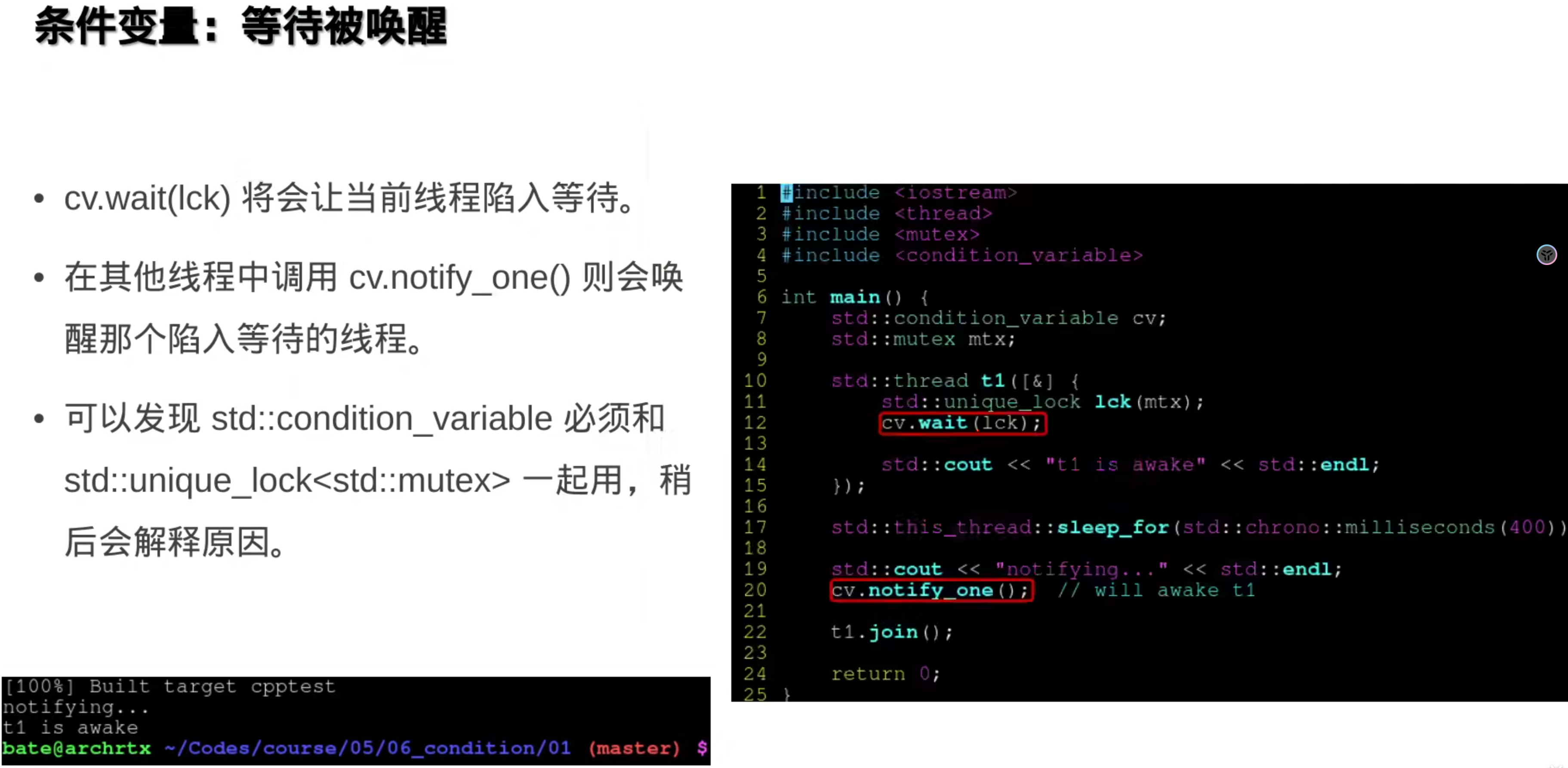
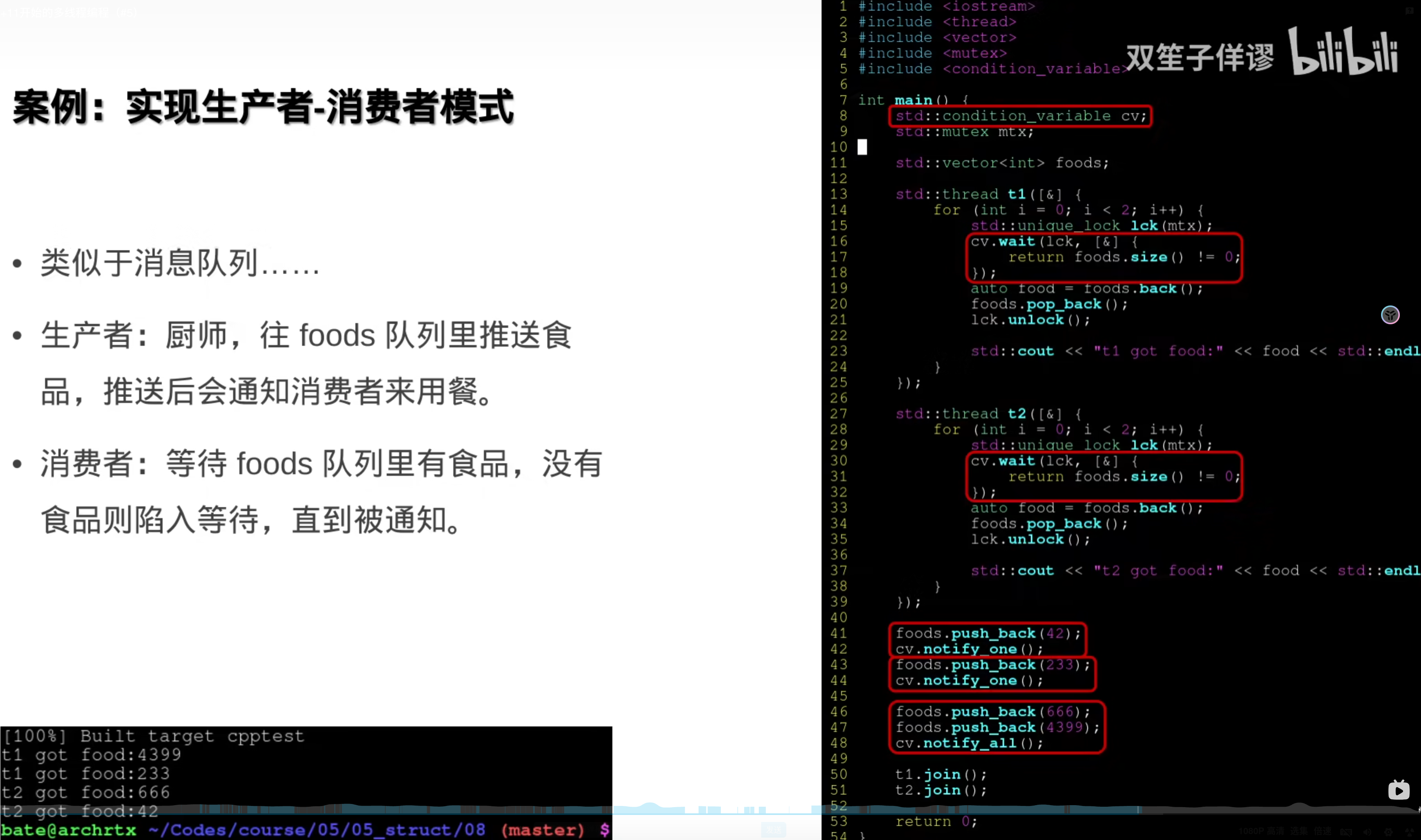
6.条件变量




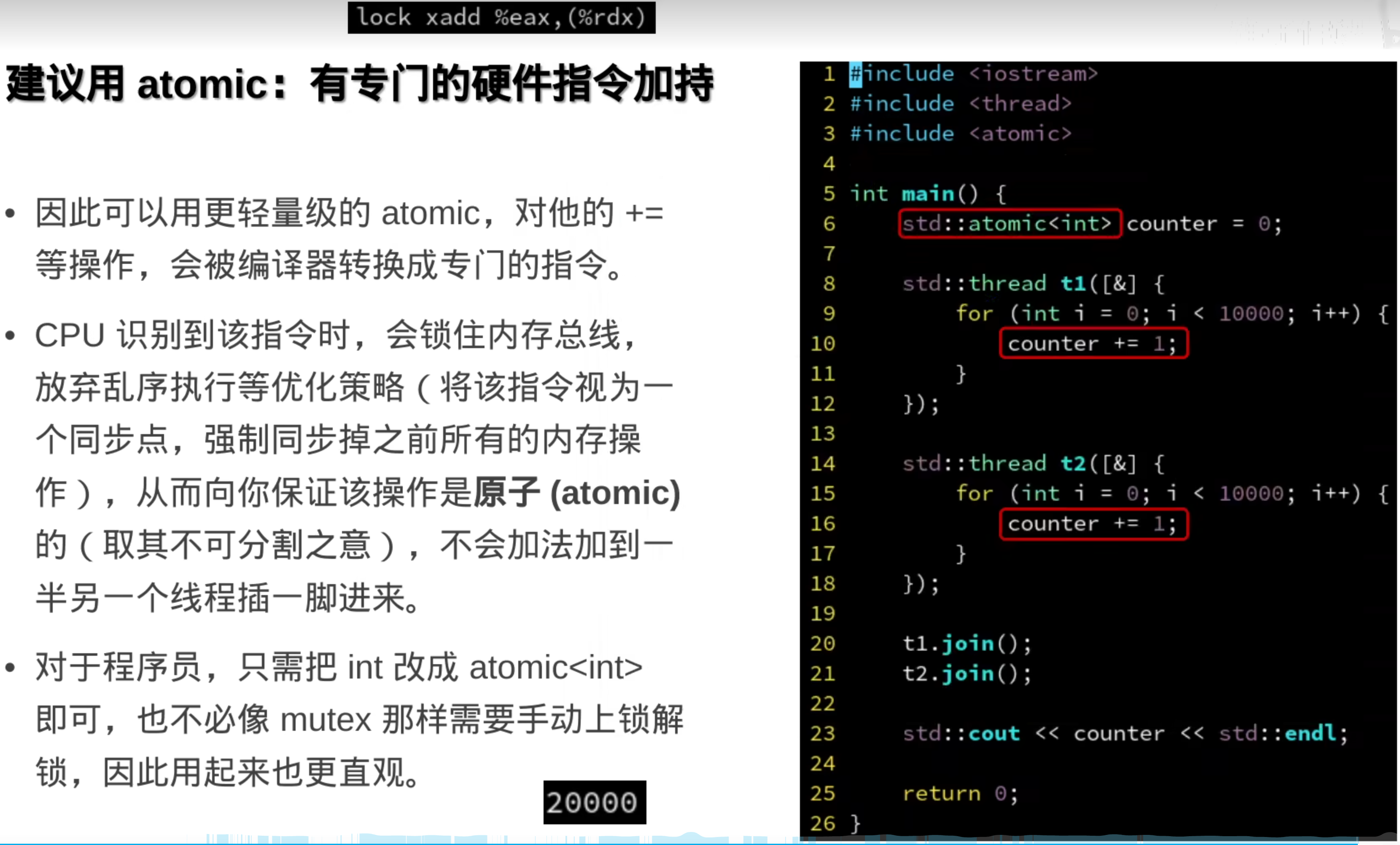
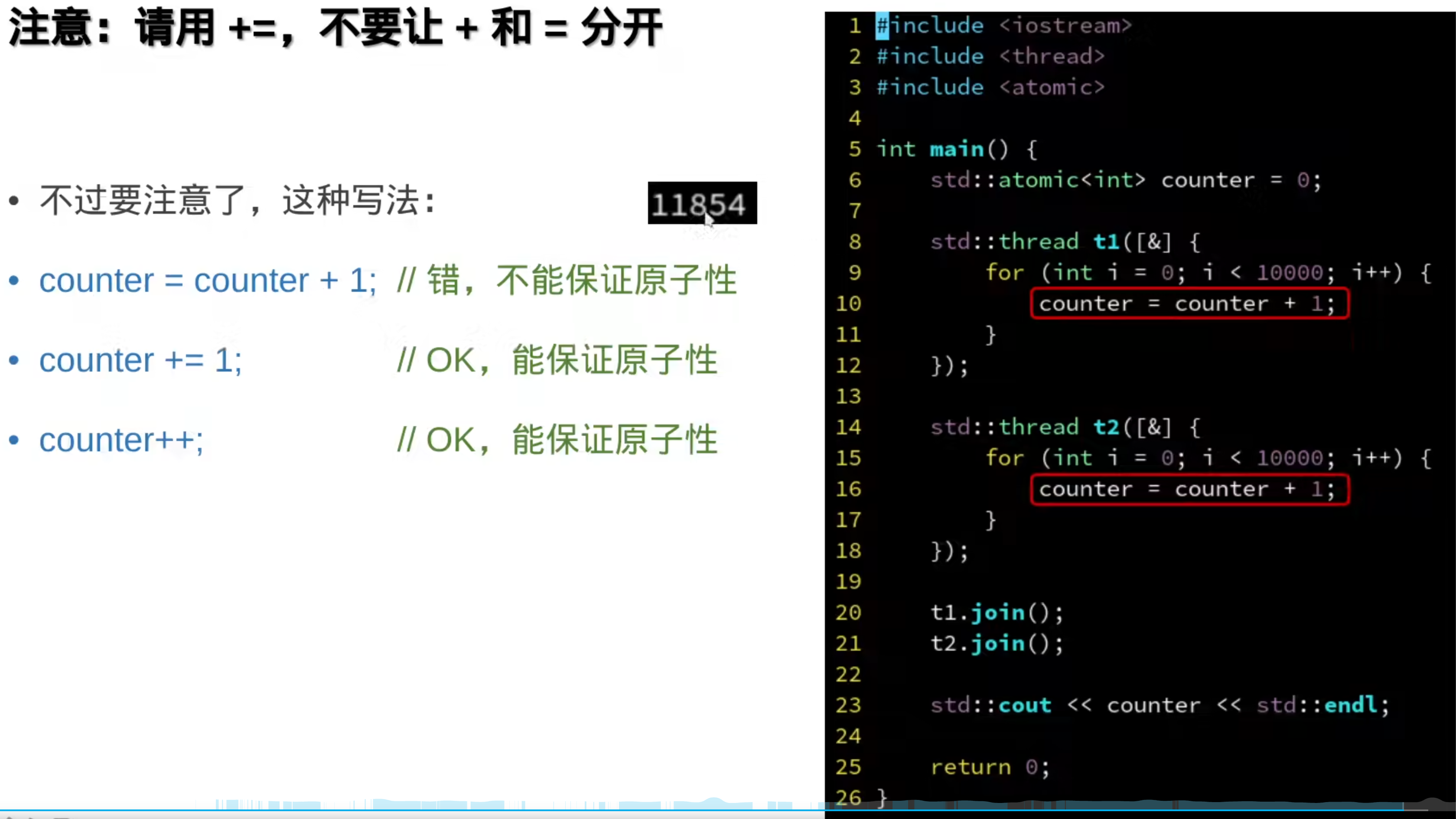
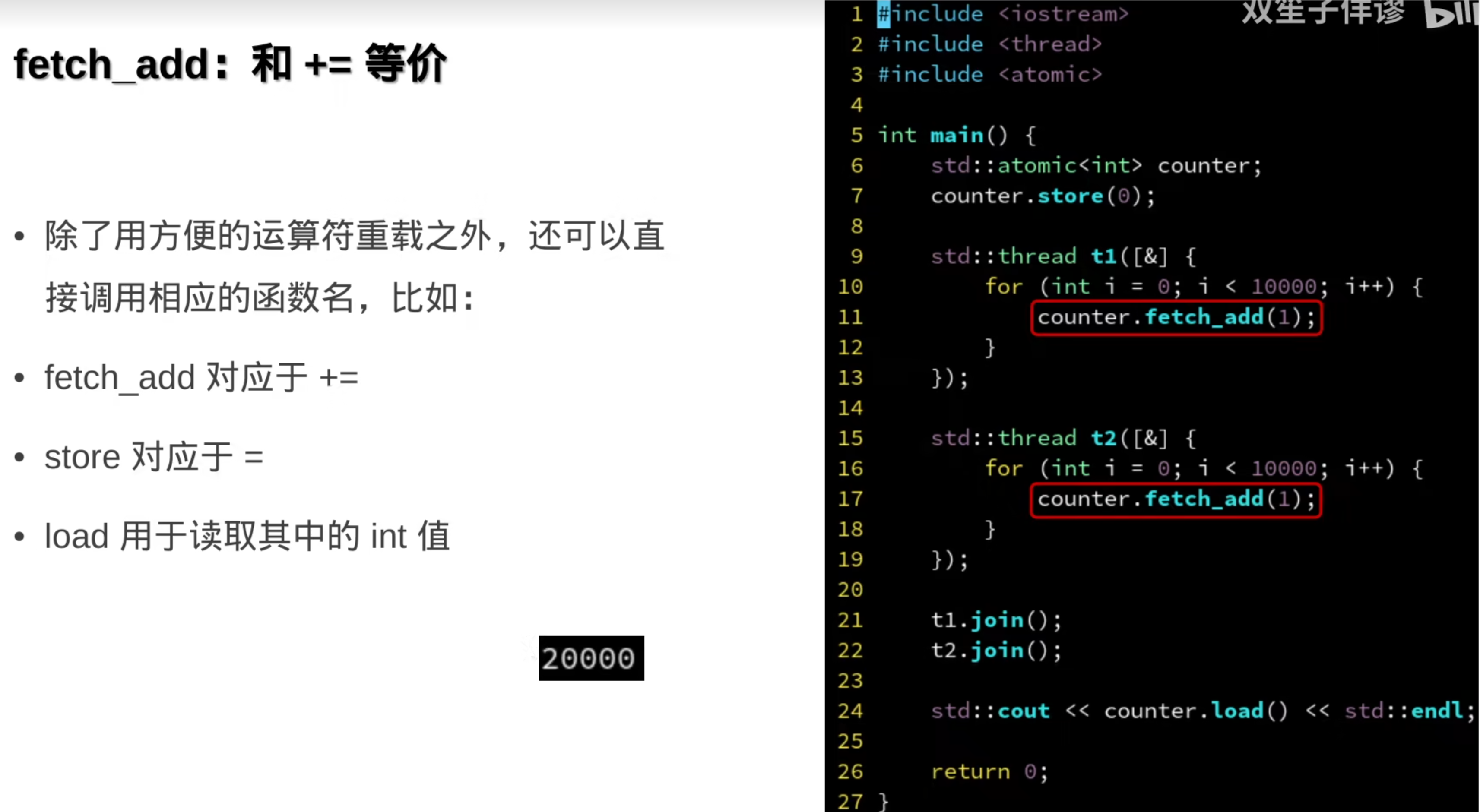
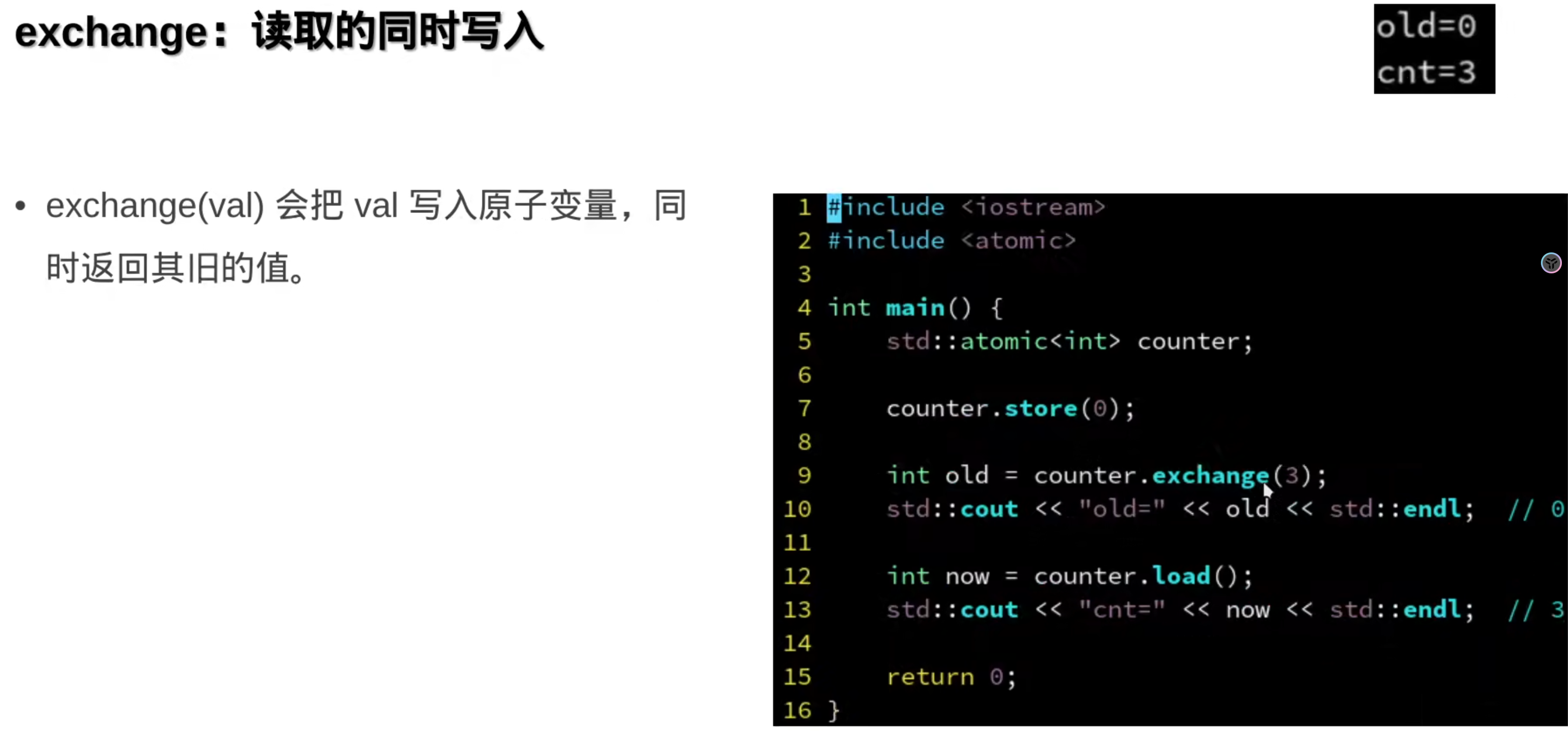
###7.原子操作(硬件层面)
前面的都是操作系统层面的
硬件解释:


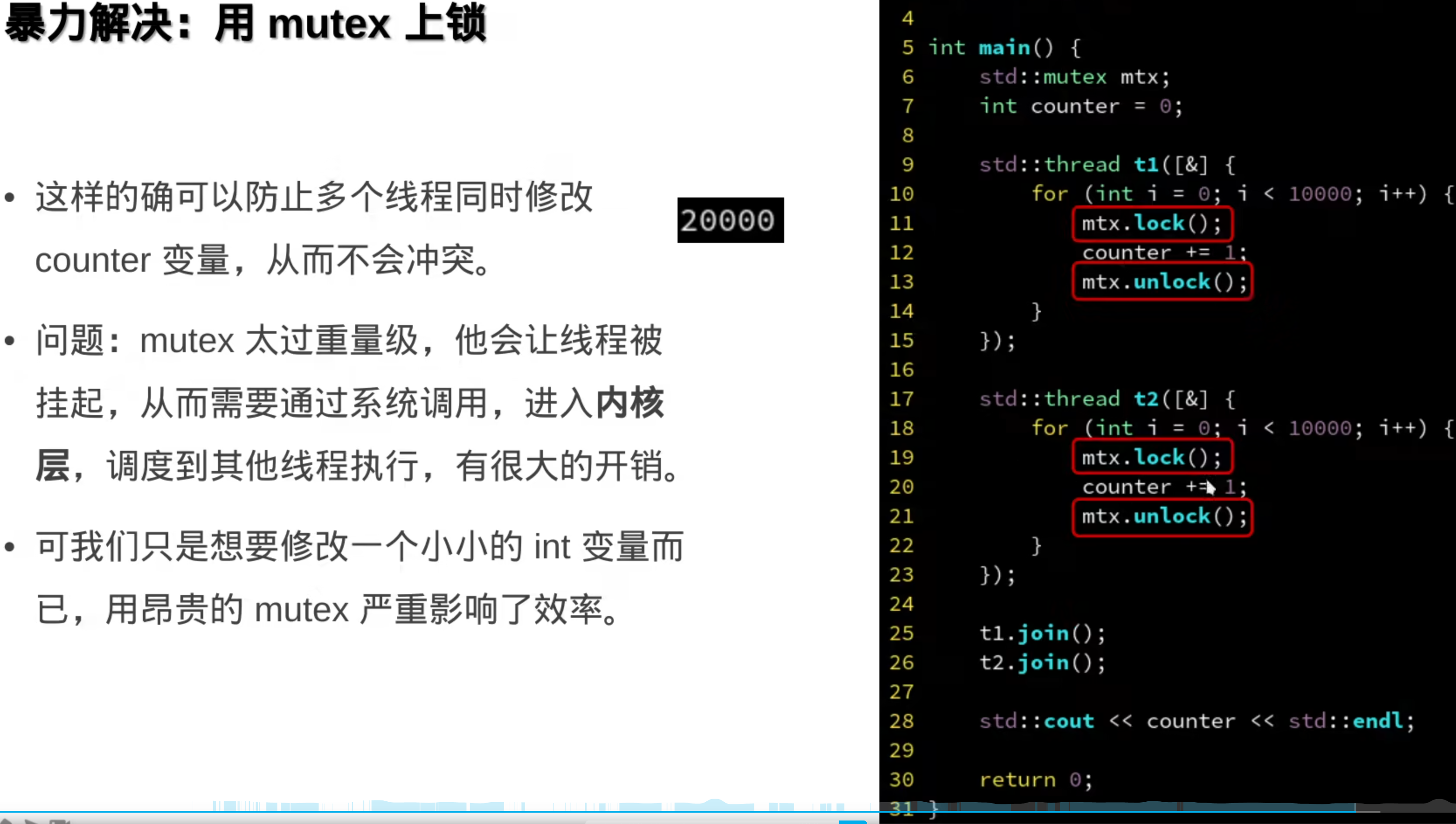
原子变量:


并行
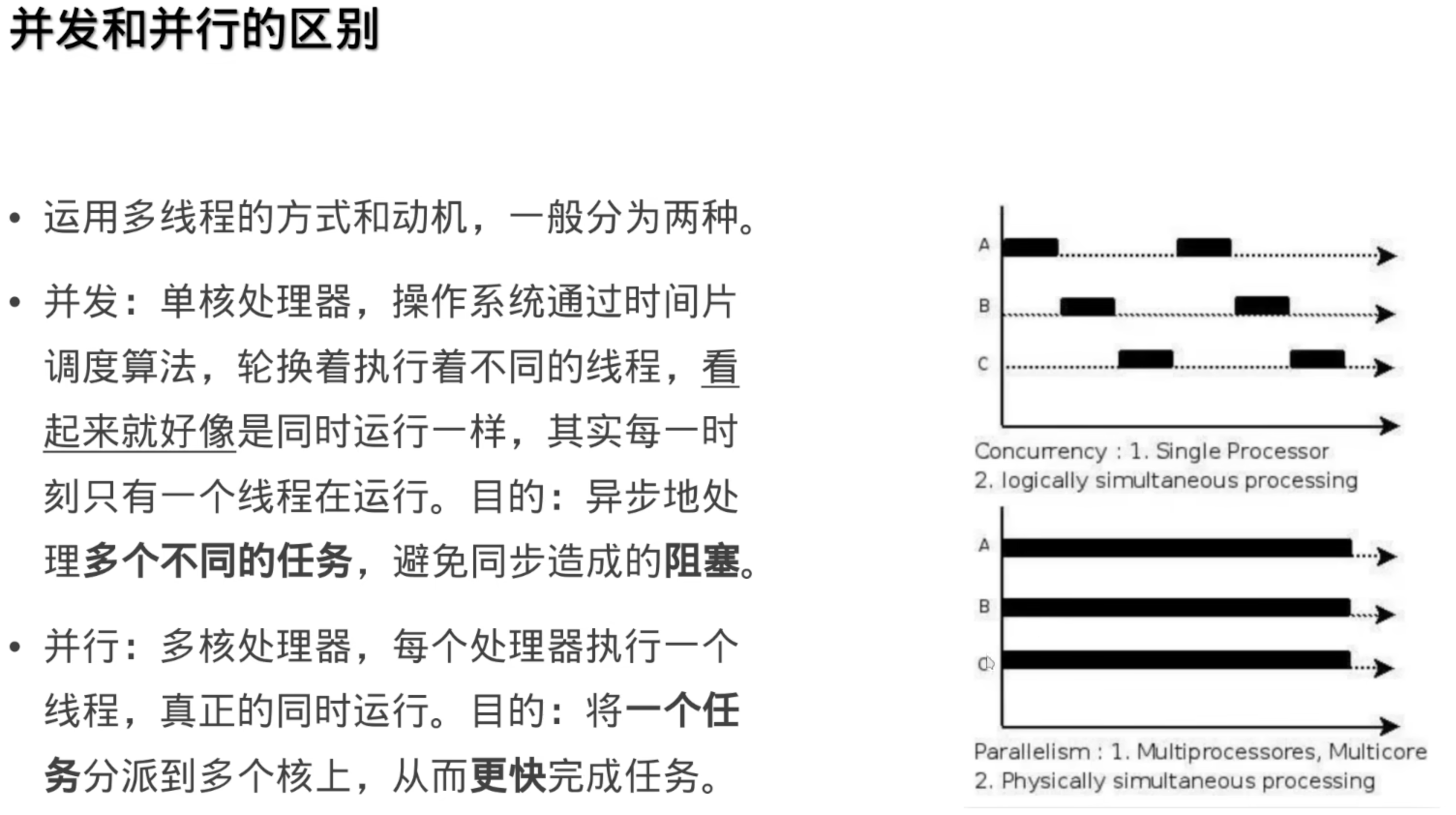
###——TBB开启的并行编程之旅(Intel TBB并行编程框架)
###0.从并发到并行


不需要手动创建线程池:

std::thread是操作系统意义上的线程,TBB的一个任务不一定代表一个线程,把任务分配到线程上去, TBB可视为一个高效调度器
ubuntu20.04蓝牙耳机连上了,但是声音还是输出在内置扬声器上,使用 pactl load-module module-bluetooth-discover 时遇到“模块初始化失败”的错误.
检查 Bluetooth 服务:
确保 Bluetooth 服务正在运行。可以使用以下命令启动服务:sudo systemctl start bluetooth安装必要的包:
确保已安装 PulseAudio 和 Bluetooth 支持。运行以下命令安装相关组件:sudo apt install pulseaudio pulseaudio-module-bluetooth pavucontrol重启 PulseAudio:
有时重启 PulseAudio 可以解决问题。可以使用以下命令:pulseaudio -k pulseaudio --start
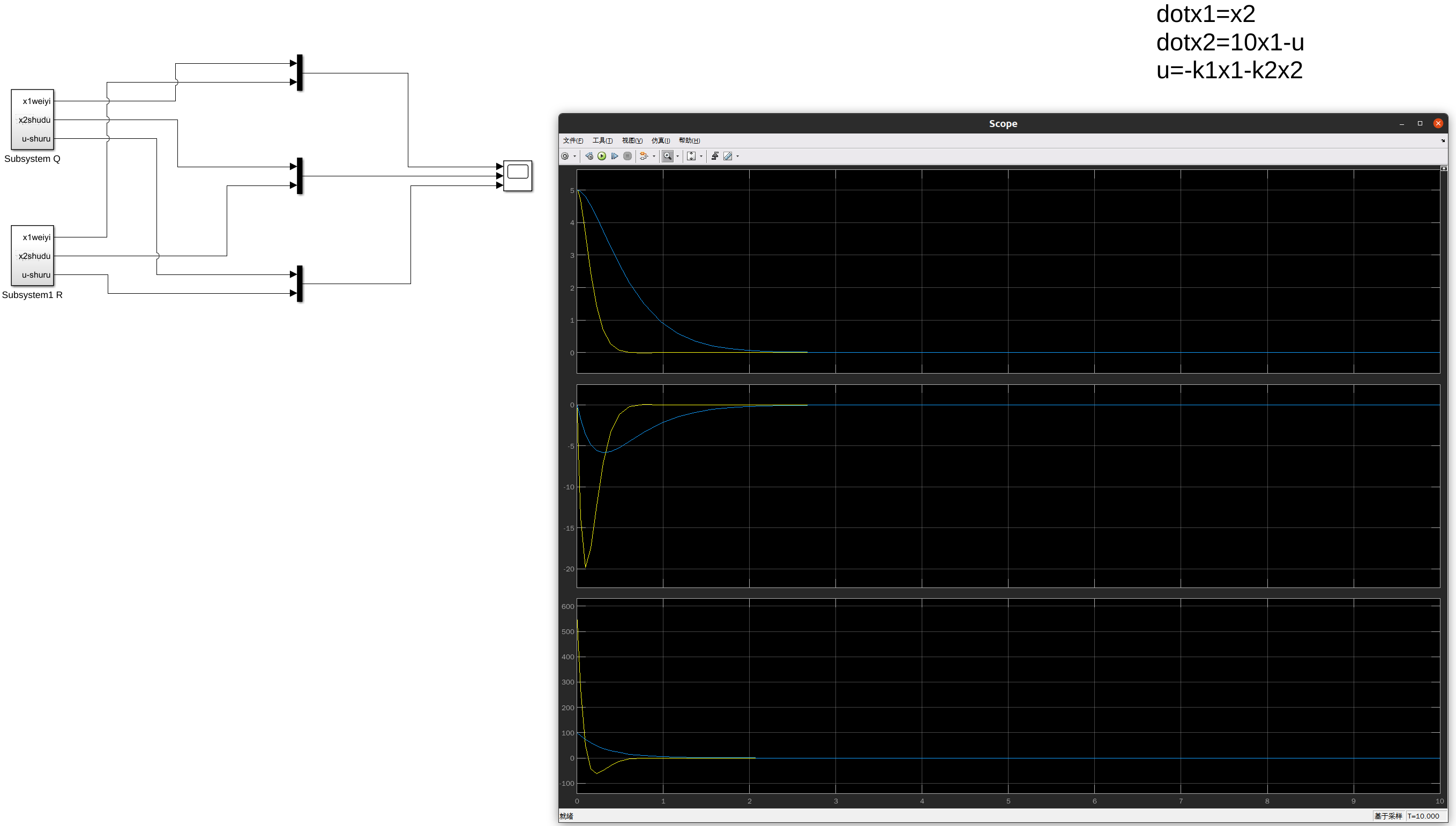
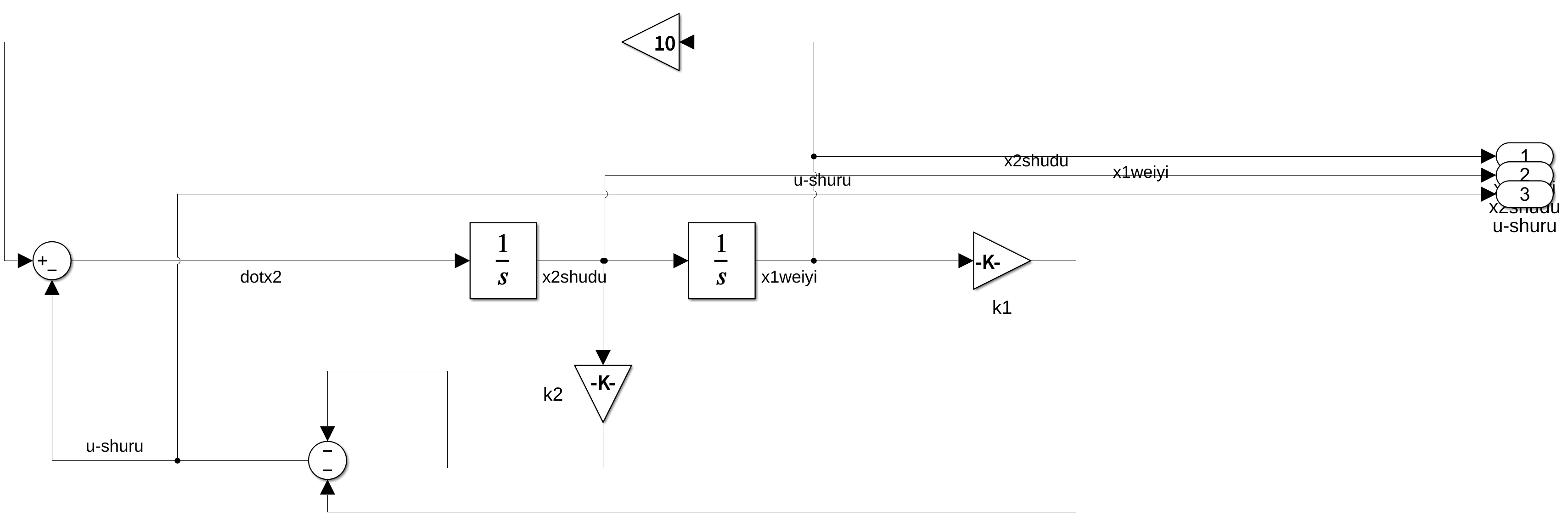
当然可以。根据你提供的代码,系统的状态空间方程可以表示为以下形式:
状态方程:
$$[
\begin{align*}
\dot{x}_1 &= x_2 \
\dot{x}_2 &= \frac{-b \cdot (I + m \cdot l^2)}{P} \cdot x_2 + \frac{m \cdot m \cdot g \cdot l^2}{P} \cdot x_3 \
\dot{x}_3 &= x_4 \
\dot{x}_4 &= \frac{-b \cdot m \cdot l}{P} \cdot x_2 + \frac{m \cdot g \cdot l \cdot (M + m)}{P} \cdot x_3 + \frac{1}{P} \cdot u
\end{align*}
]$$
其中,( x_1 ) 和 ( x_2 ) 可能表示倒立摆的位移和速度,而 ( x_3 ) 和 ( x_4 ) 可能表示摆角和角速度。控制输入 ( u ) 是作用在倒立摆上的力。
输入方程:
$$[
u = 0 \cdot x_1 + \frac{(I + m \cdot l^2)}{P} \cdot x_2 + 0 \cdot x_3 + \frac{m \cdot l}{P} \cdot x_4
]$$
但实际上,控制输入 ( u ) 是由控制器决定的,所以输入方程应该表示控制律,而不是状态变量直接映射到控制输入。
根据你的代码,状态空间方程的矩阵形式是:
$$[
\begin{align*}
\dot{\mathbf{x}} &= \mathbf{A} \mathbf{x} + \mathbf{B} u \
y &= \mathbf{C} \mathbf{x} + \mathbf{D} u
\end{align*}
]$$
其中,(\mathbf{x}) 是状态向量,(u) 是控制输入,(y) 是系统输出。在你的代码中,并没有明确给出输出矩阵 (\mathbf{C}) 和直接馈通矩阵 (\mathbf{D}),所以我们假设它们是:
$$[
\mathbf{C} = \begin{bmatrix}
1 & 0 & 0 & 0 \
0 & 1 & 0 & 0
\end{bmatrix}, \quad
\mathbf{D} = \begin{bmatrix}
0 \
0
\end{bmatrix}
]$$
这意味着系统的输出是状态向量 (\mathbf{x}) 的前两个元素。
因此,状态空间方程的矩阵形式为:
$[
\mathbf{A} = \begin{bmatrix}
0 & 1 & 0 & 0 \
0 & -\frac{b \cdot (I + m \cdot l^2)}{P} & \frac{m \cdot m \cdot g \cdot l^2}{P} & 0 \
0 & 0 & 0 & 1 \
0 & -\frac{b \cdot m \cdot l}{P} & \frac{m \cdot g \cdot l \cdot (M + m)}{P} & 0
\end{bmatrix}
]$
$$[
\mathbf{B} = \begin{bmatrix}
0 \
\frac{(I + m \cdot l^2)}{P} \
0 \
\frac{m \cdot l}{P}
\end{bmatrix}
]$$
请注意,这里的 $(\mathbf{A})$ 和 $(\mathbf{B})$ 矩阵与你代码中定义的矩阵相匹配,但是根据你的系统定义,你可能需要调整 $(\mathbf{C})$ 和 $(\mathbf{D}) $矩阵以反映实际的系统输出。

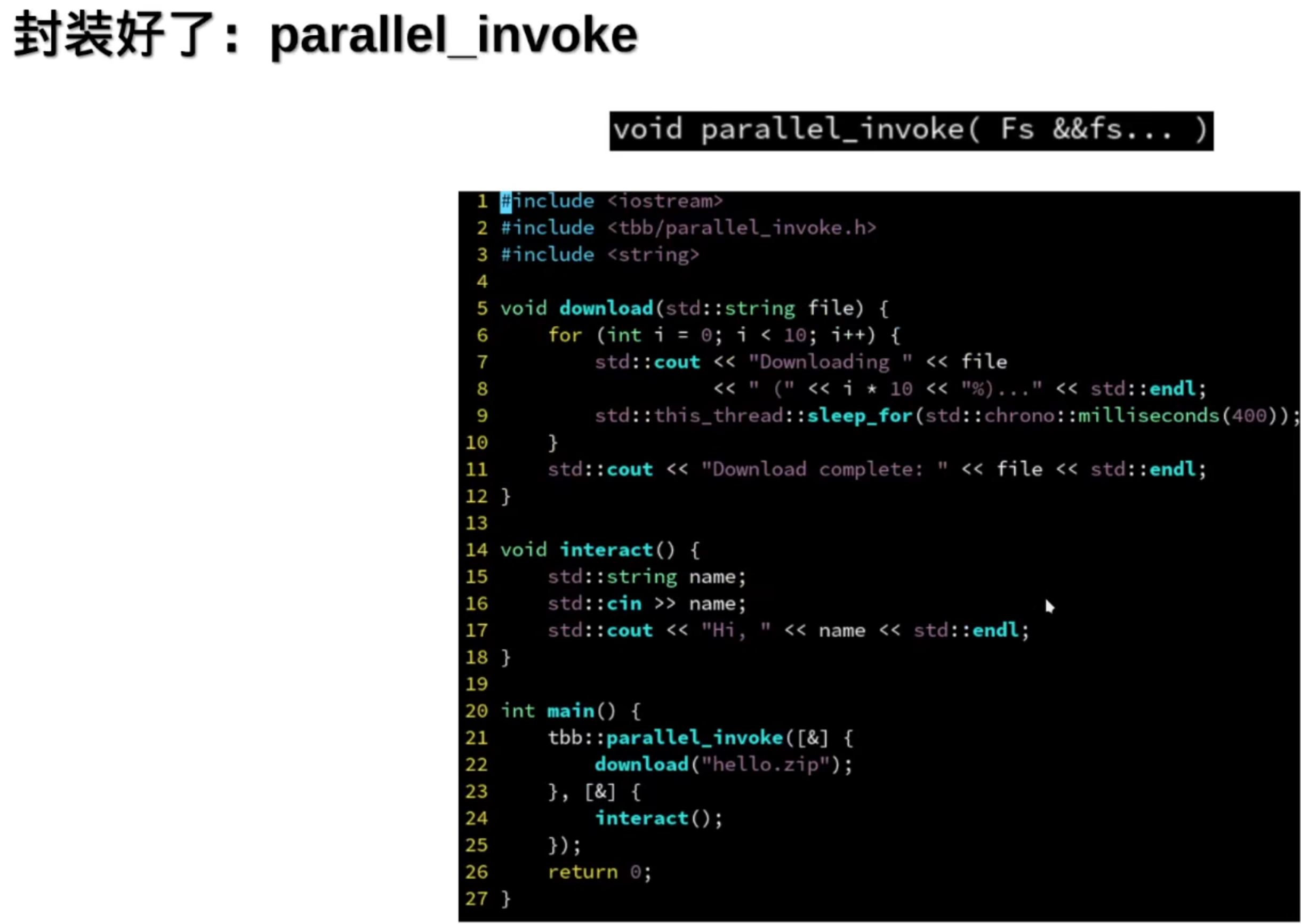
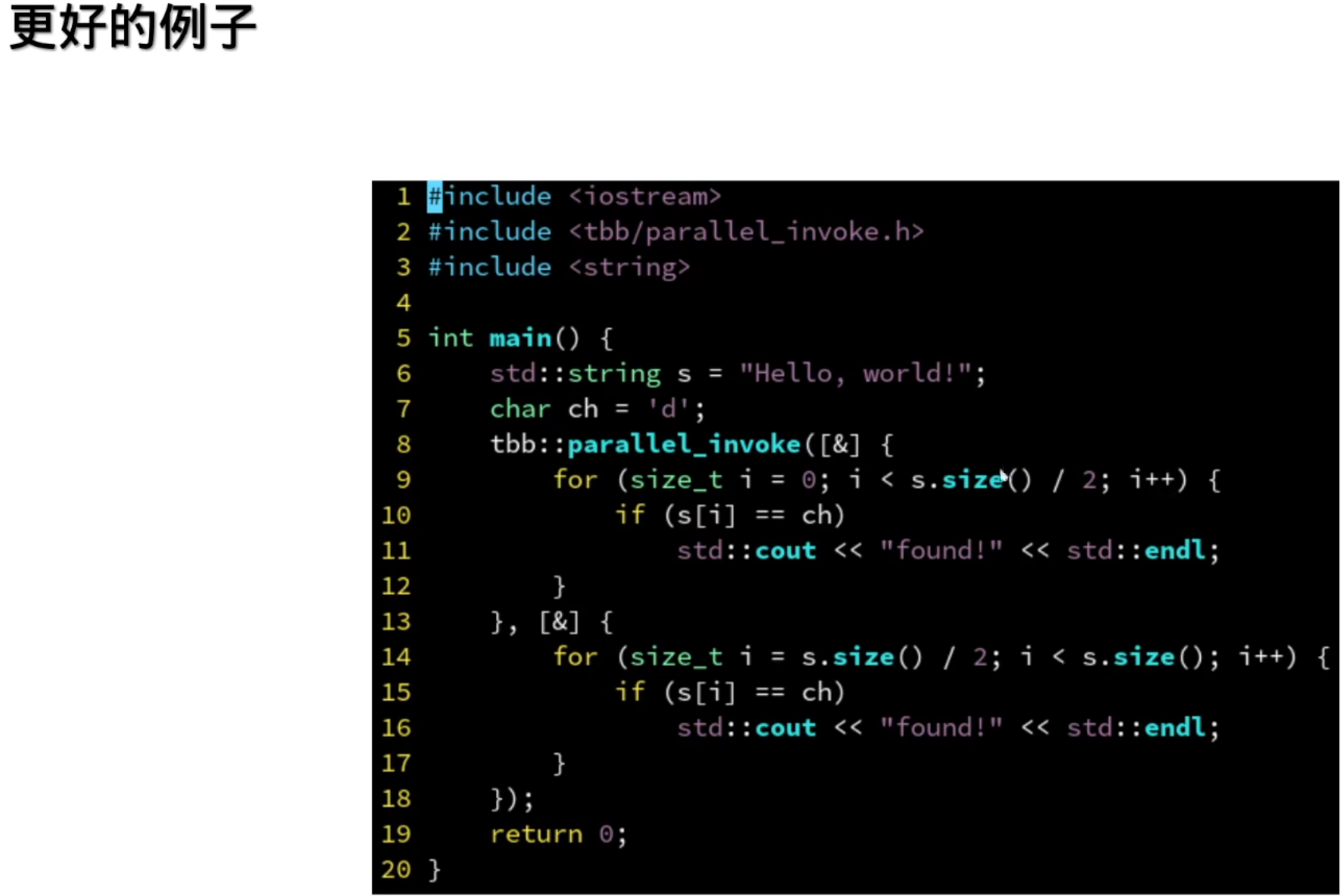
1.并行循环
并行的for循环 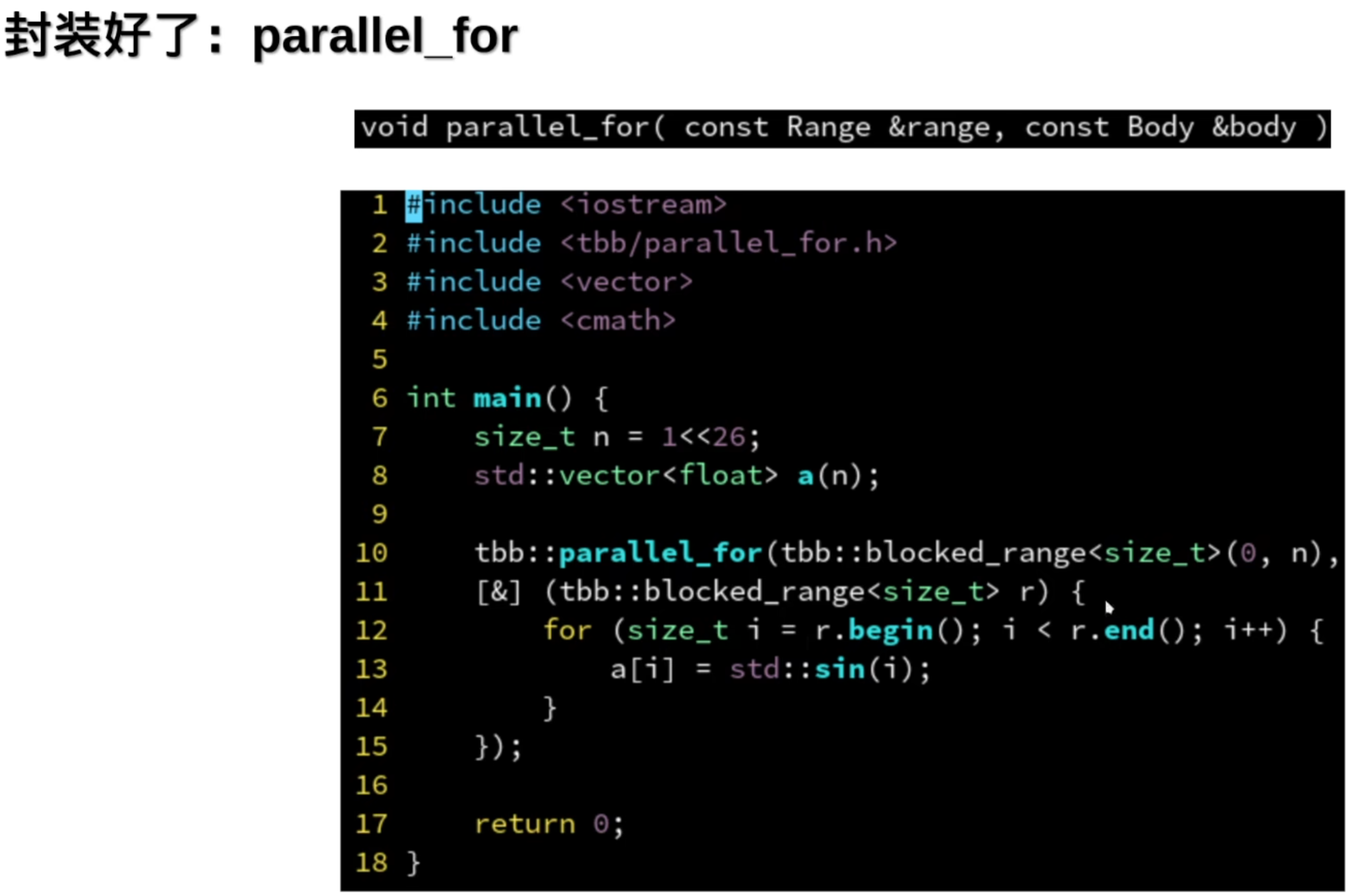
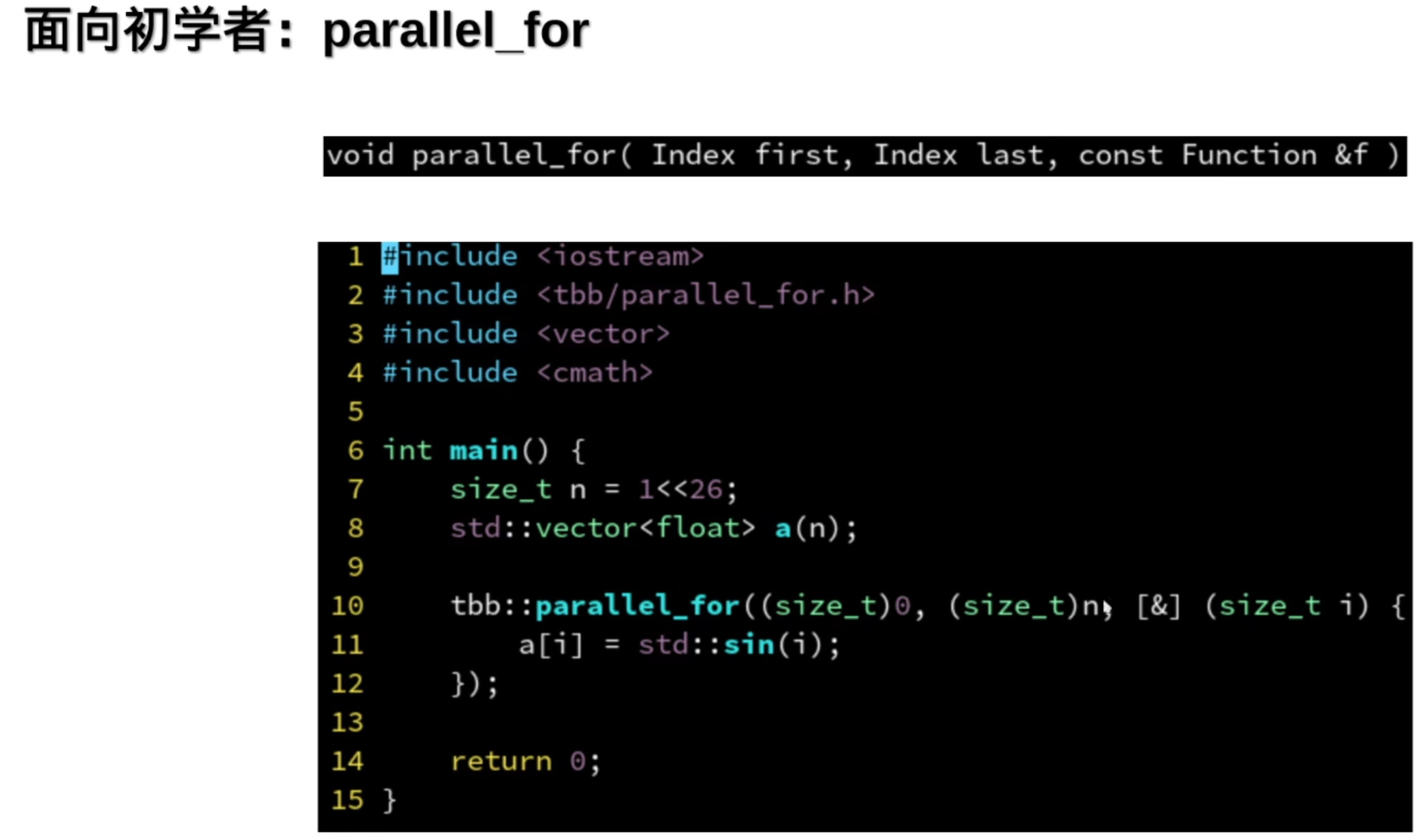
简单,但是有代价,无法被编译器优化了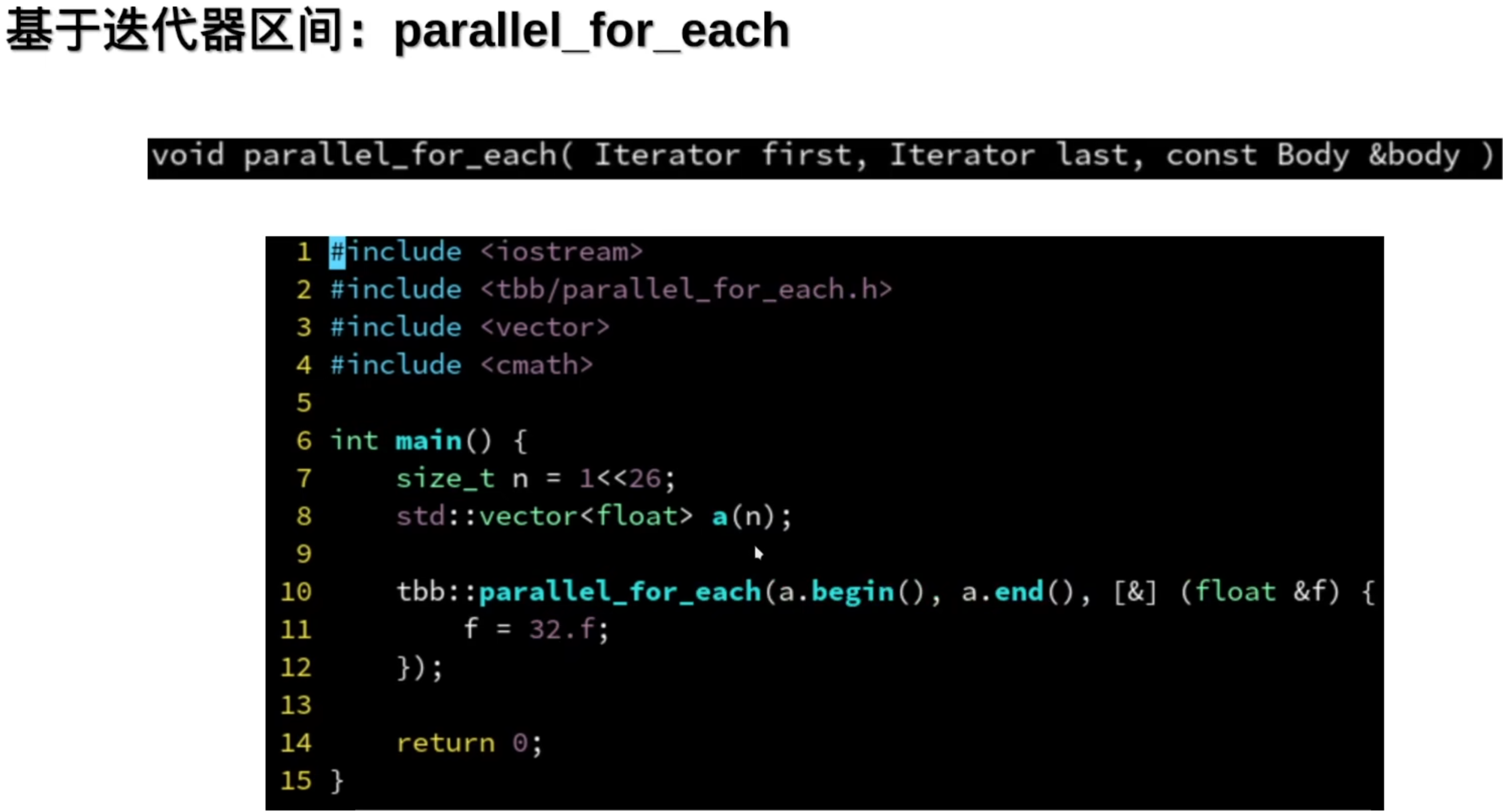
这个是不需要索引的时候可以用
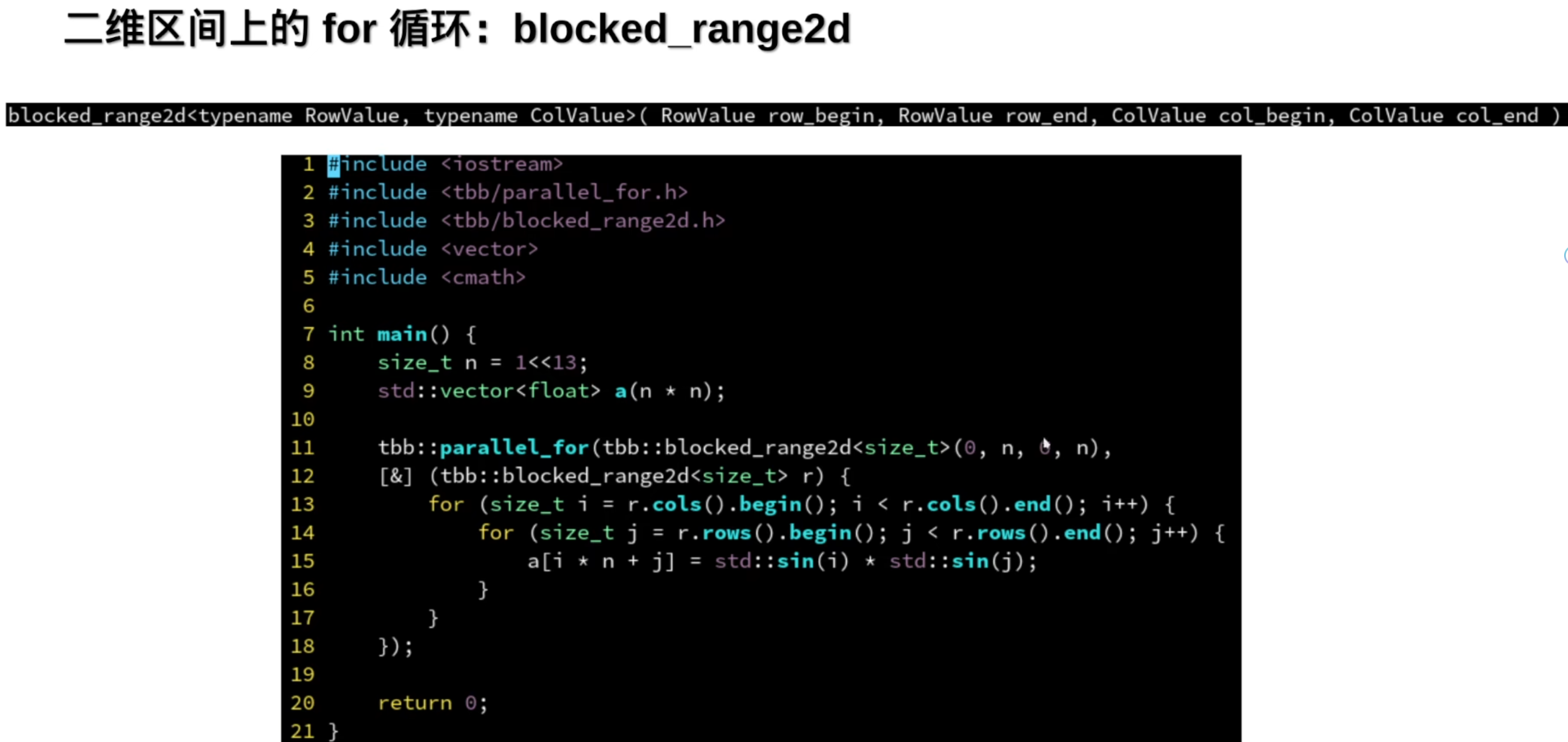
二维
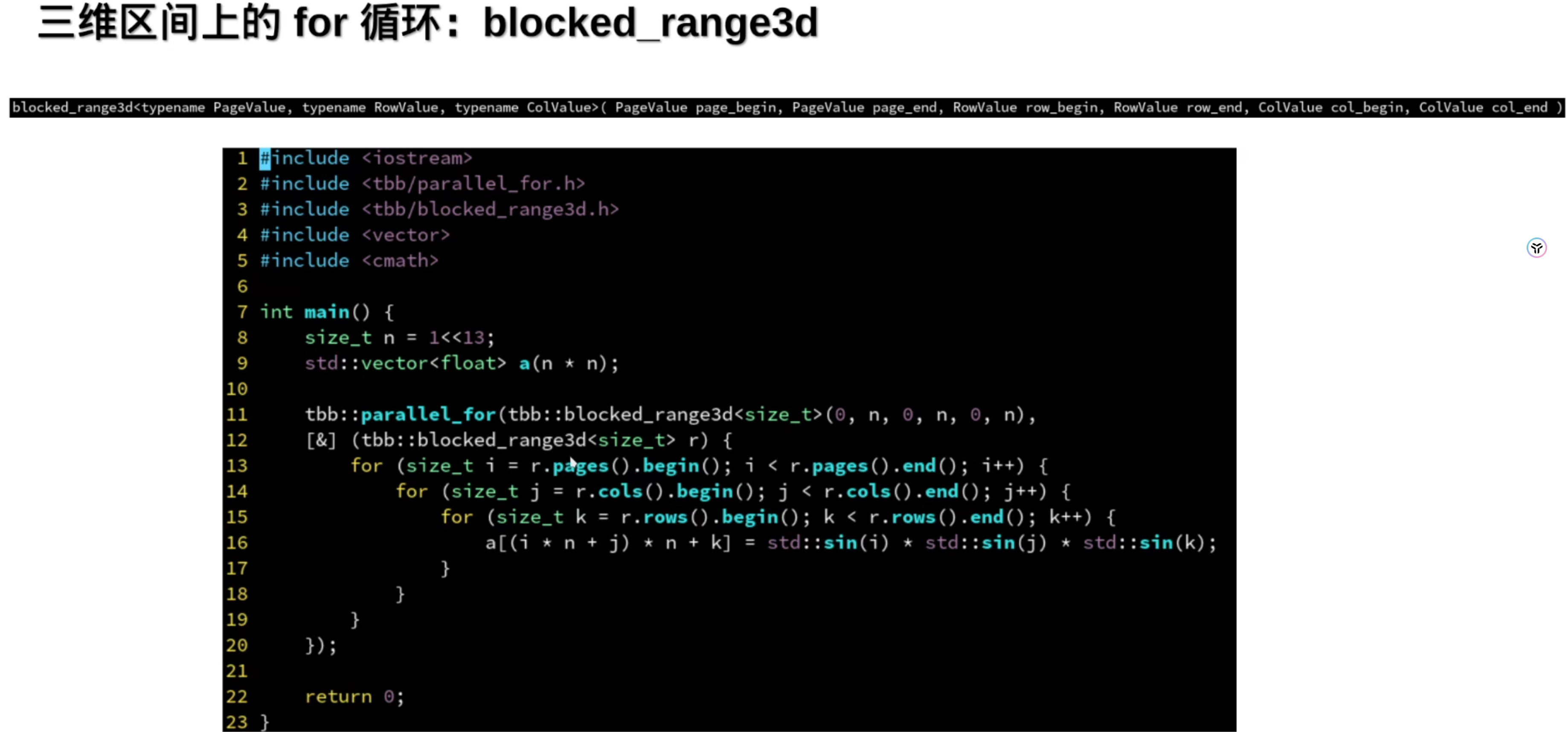
三维
2,缩并与扫描
并行缩并
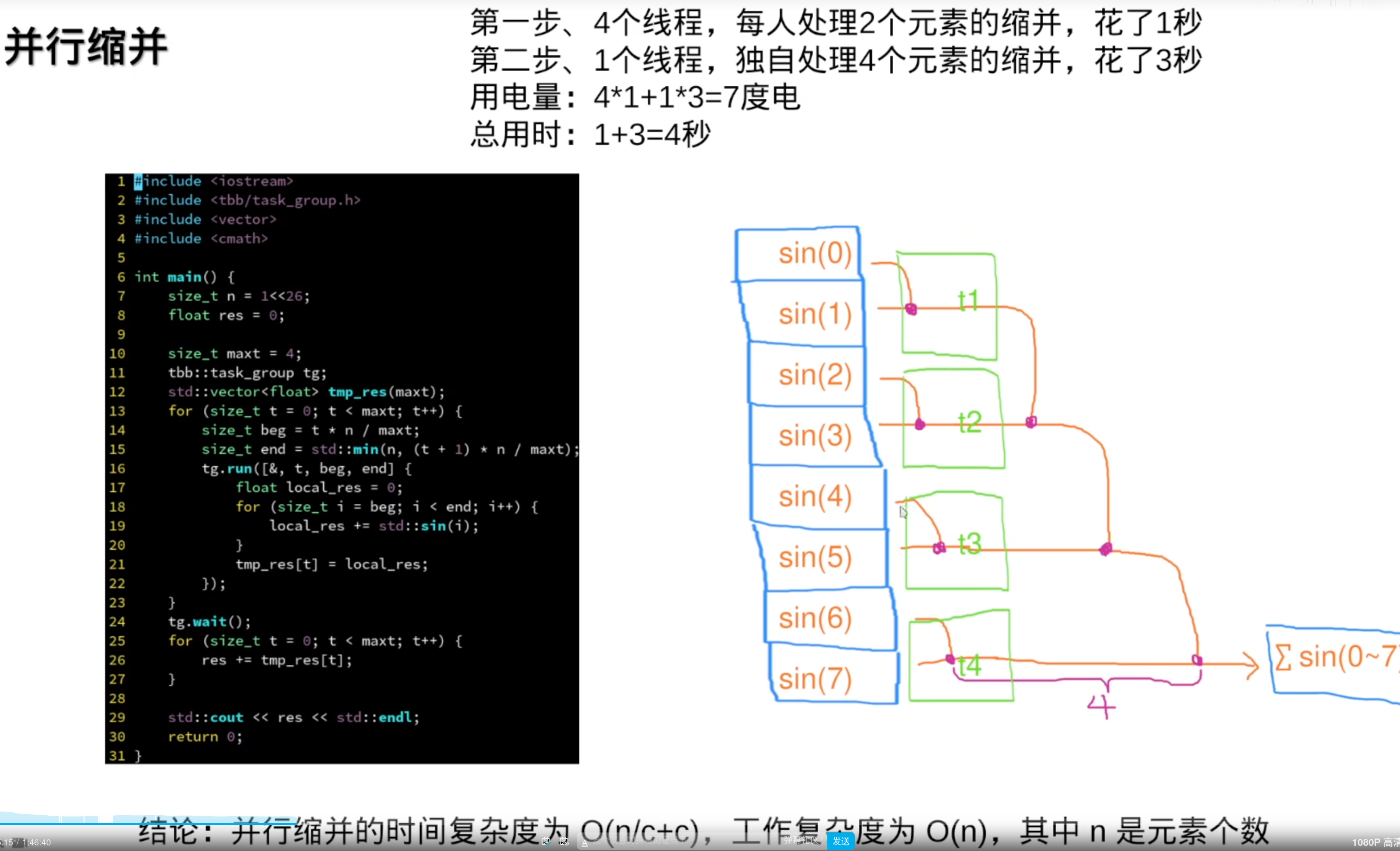
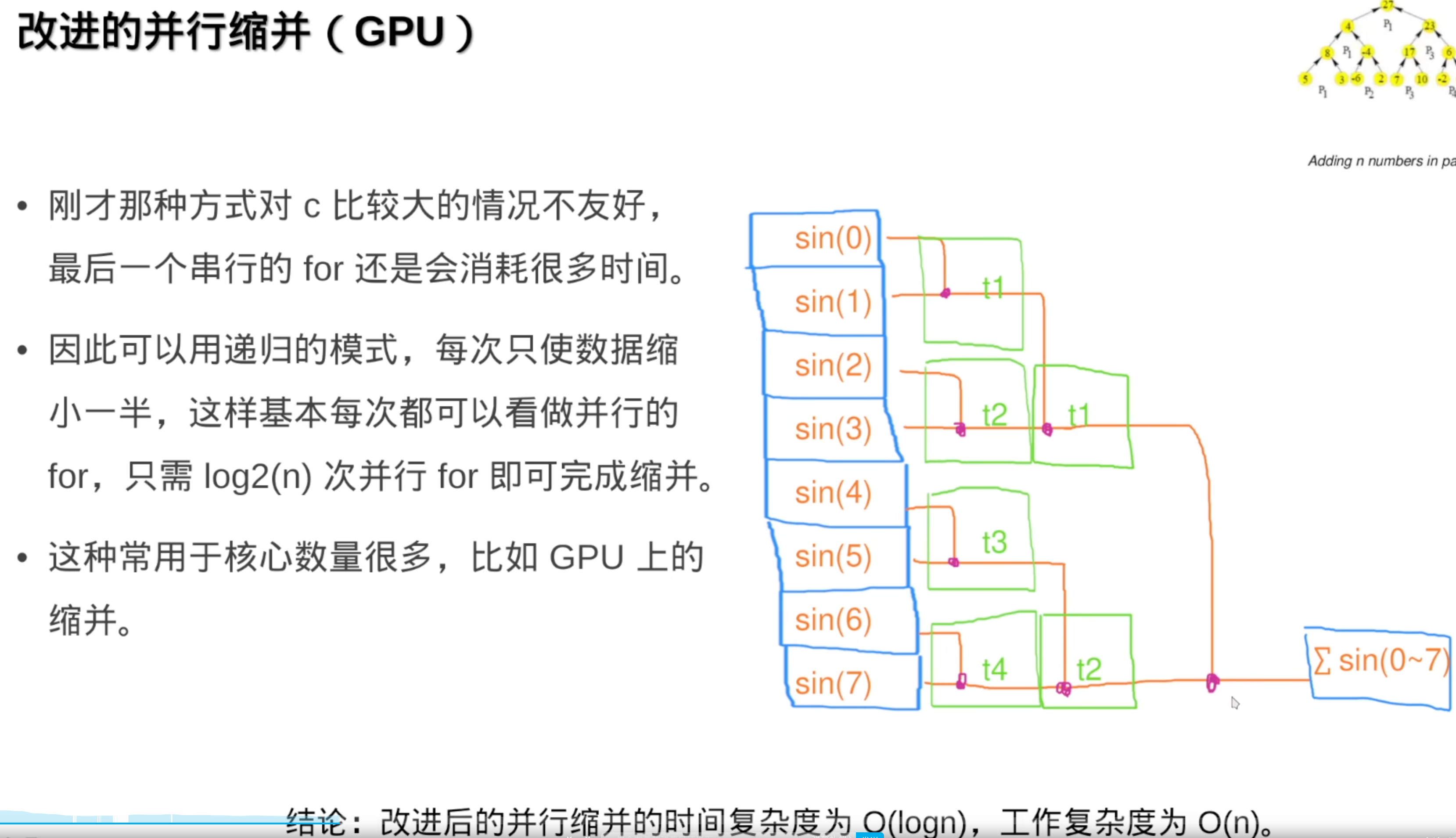

但是,任务是动态分配到线程上,也就是range会变化,精度就会变,为了性能结果会有不同。所以:

并行缩并的好处,相比于普通的串行缩并:

串行相加,很大的e指数加上一个很小的float数,误差很大(浮点数不能大加小(等于没加))
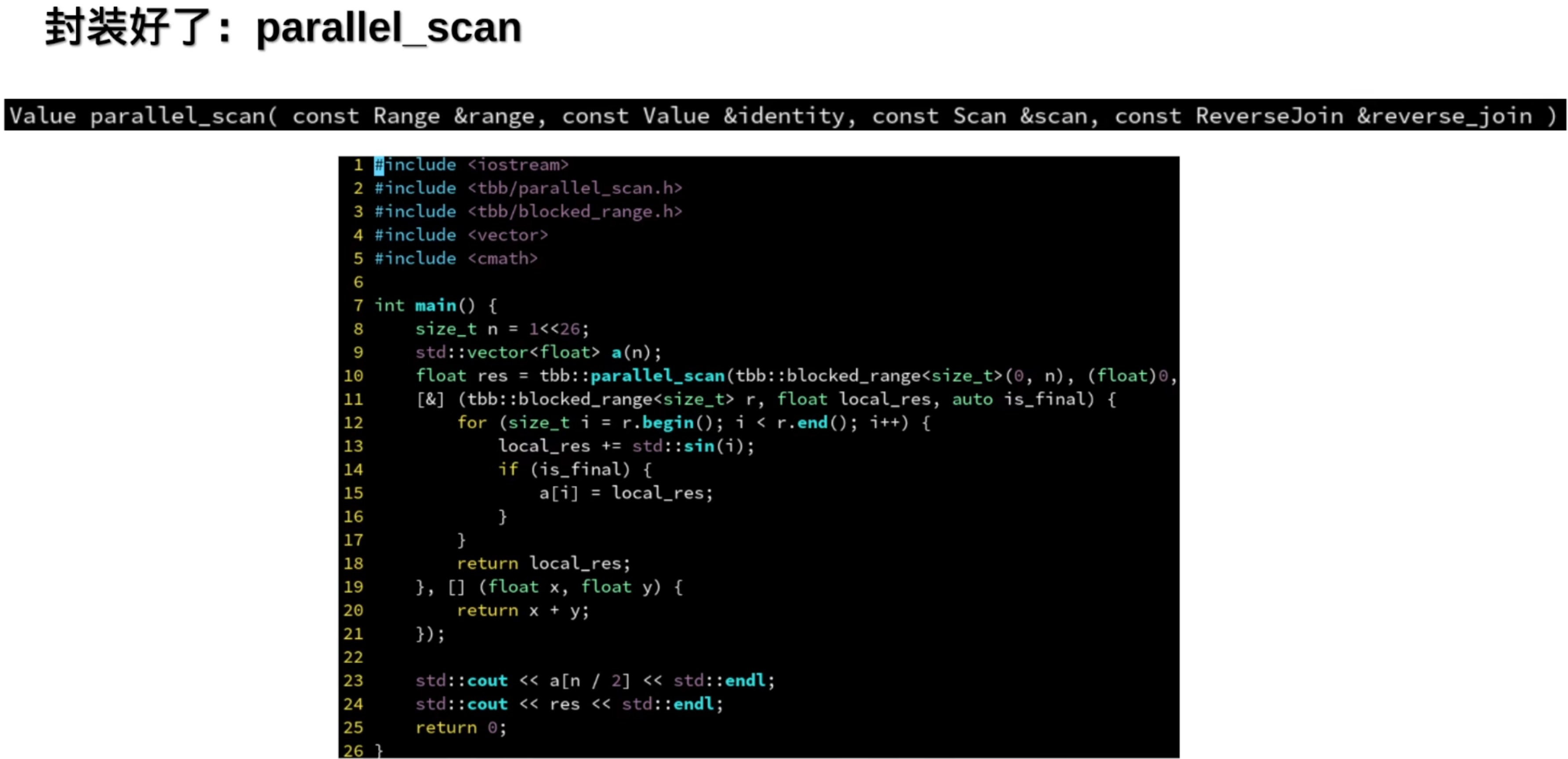
3.并行扫描
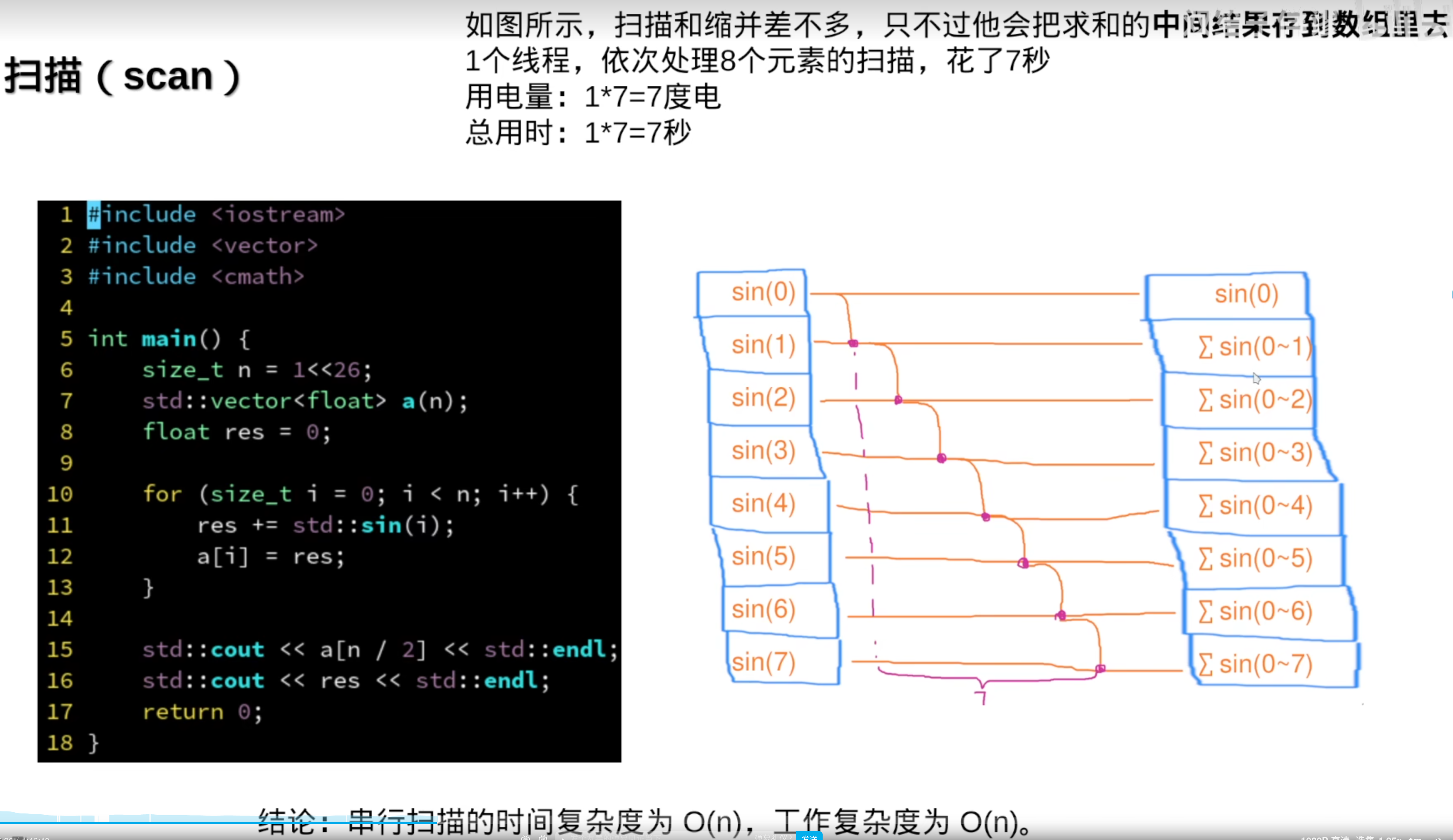
通常用于生成直方图

考试比较喜欢的考法是将这三种校正与“PID校正”校正结合起来,他们喜欢说PID校正,毕竟PD、PI、PID校正分别是超前、滞后、和滞后-超前校正的特殊情况。
$\text{最大超前角}\\varphi_m=\gamma^{\prime\prime}-\gamma+5°=45°-0°+5°=50°\a=\frac{1+\mathrm{sin}\varphi_m}{1-\mathrm{sin}\varphi_m}\approx8:,\quad10\mathrm{lg}a\approx9\mathrm{dB}$

文件扩展名 .tpp 通常表示 C++ 模板实现文件。它与 C++ 模板相关,主要用于存放模板类或函数的实现。
具体用途
模板定义分离:在 C++ 中,通常将模板的声明和实现分开。在头文件(
.hpp或.h)中,你可以声明一个模板,而在.tpp文件中实现该模板。这种做法有助于保持代码的组织性和可读性。包含在头文件中:为了使用
.tpp文件中的实现,通常会在相应的头文件中通过#include指令将其包含进来。
示例
假设你有一个简单的模板类 MyClass,可以这样组织文件:
MyClass.hpp
#ifndef MYCLASS_HPP
#define MYCLASS_HPP
template <typename T>
class MyClass {
public:
MyClass(T value);
void display();
private:
T data;
};
#include "MyClass.tpp" // 包含实现文件
#endif // MYCLASS_HPP
MyClass.tpp
#include "MyClass.hpp"
#include <iostream>
template <typename T>
MyClass<T>::MyClass(T value) : data(value) {}
template <typename T>
void MyClass<T>::display() {
std::cout << data << std::endl;
}
debug生成的代码没有经过优化
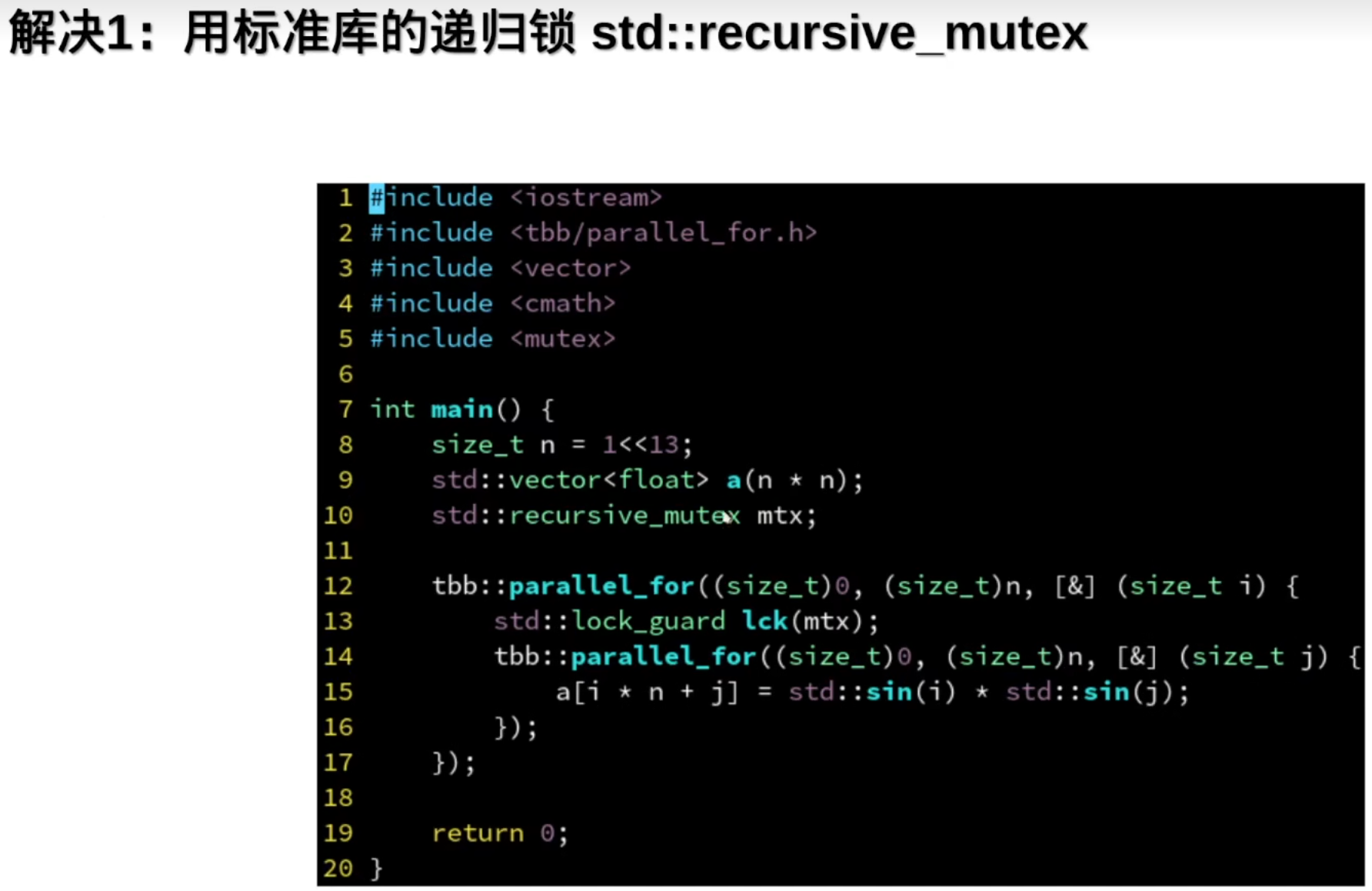
4.TBB的任务域与for循环的嵌套

指定任务域里使用的线程
并行嵌套for循环
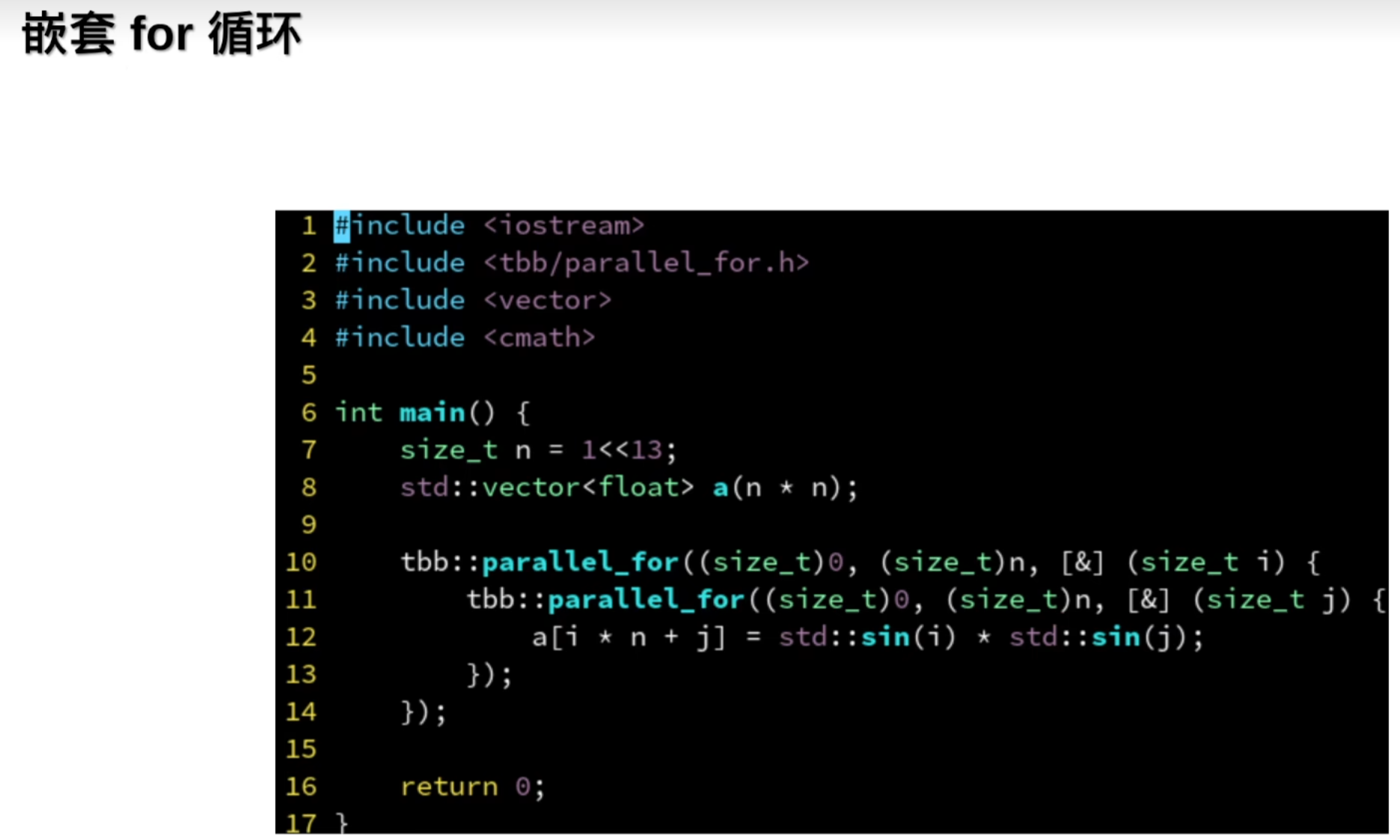
但是嵌套for循环会出现死锁问题:
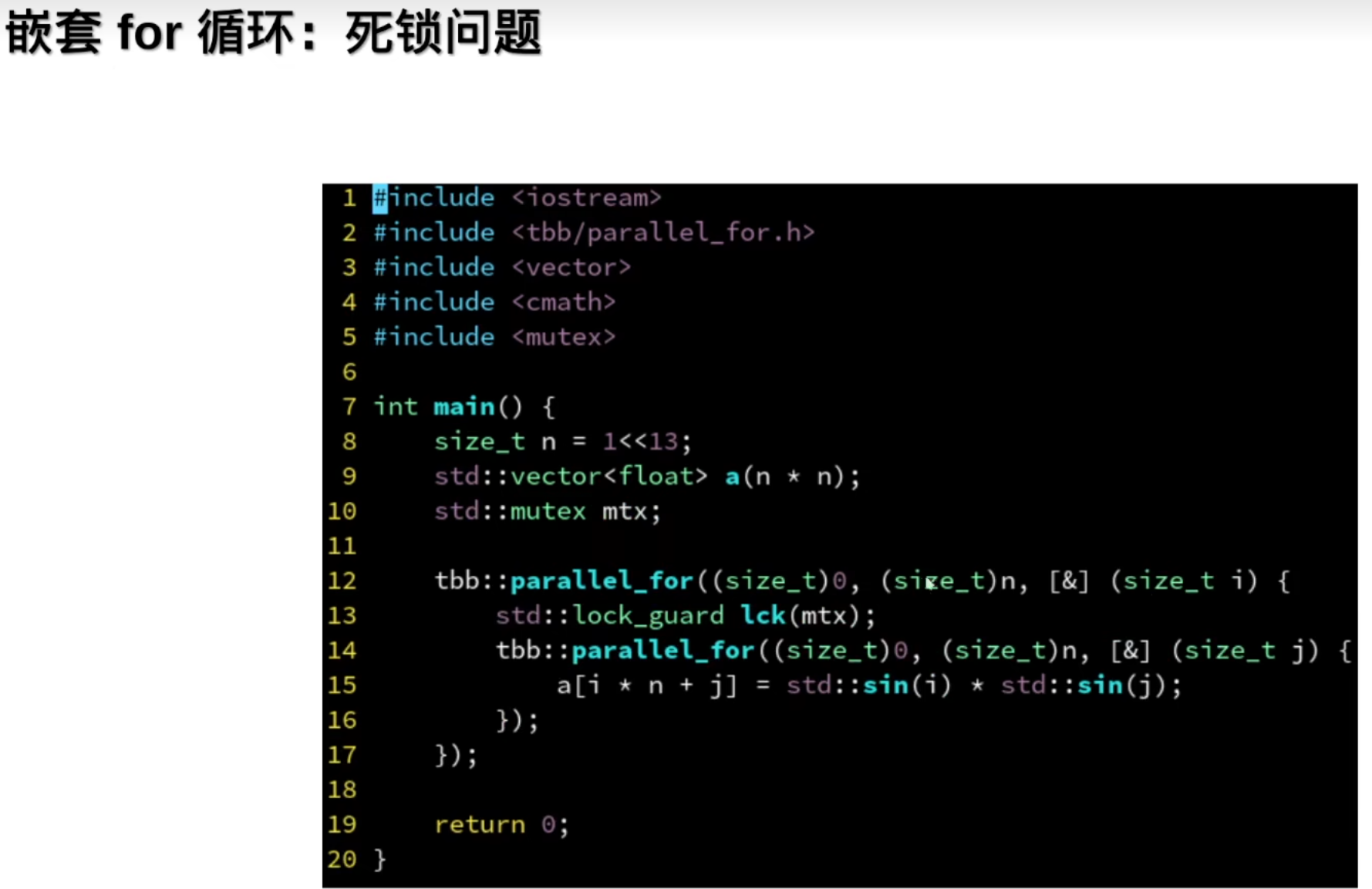
为啥:(性能优化:线程里的任务做完了,会去其他线程里取任务帮忙)

解决办法:

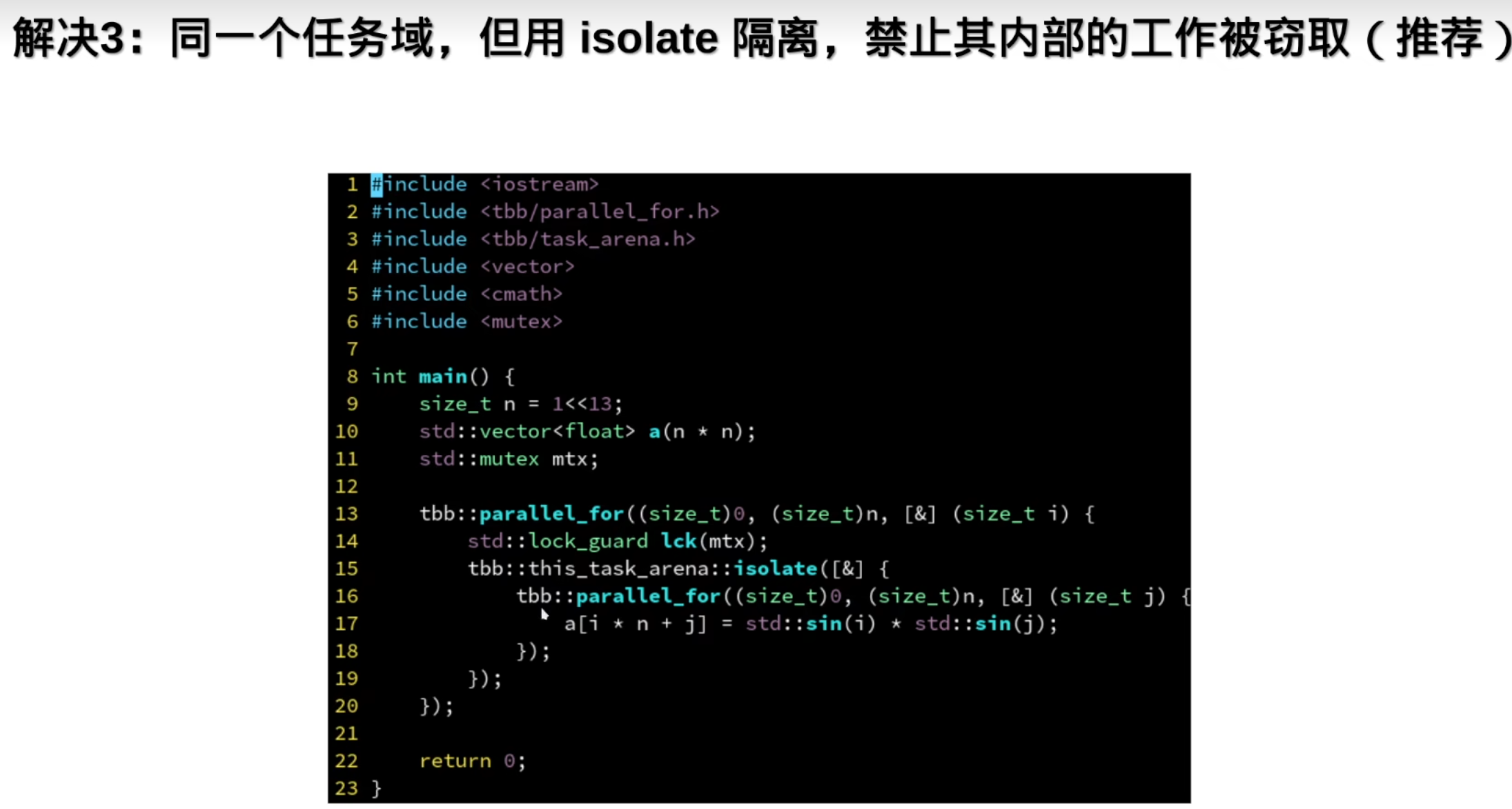
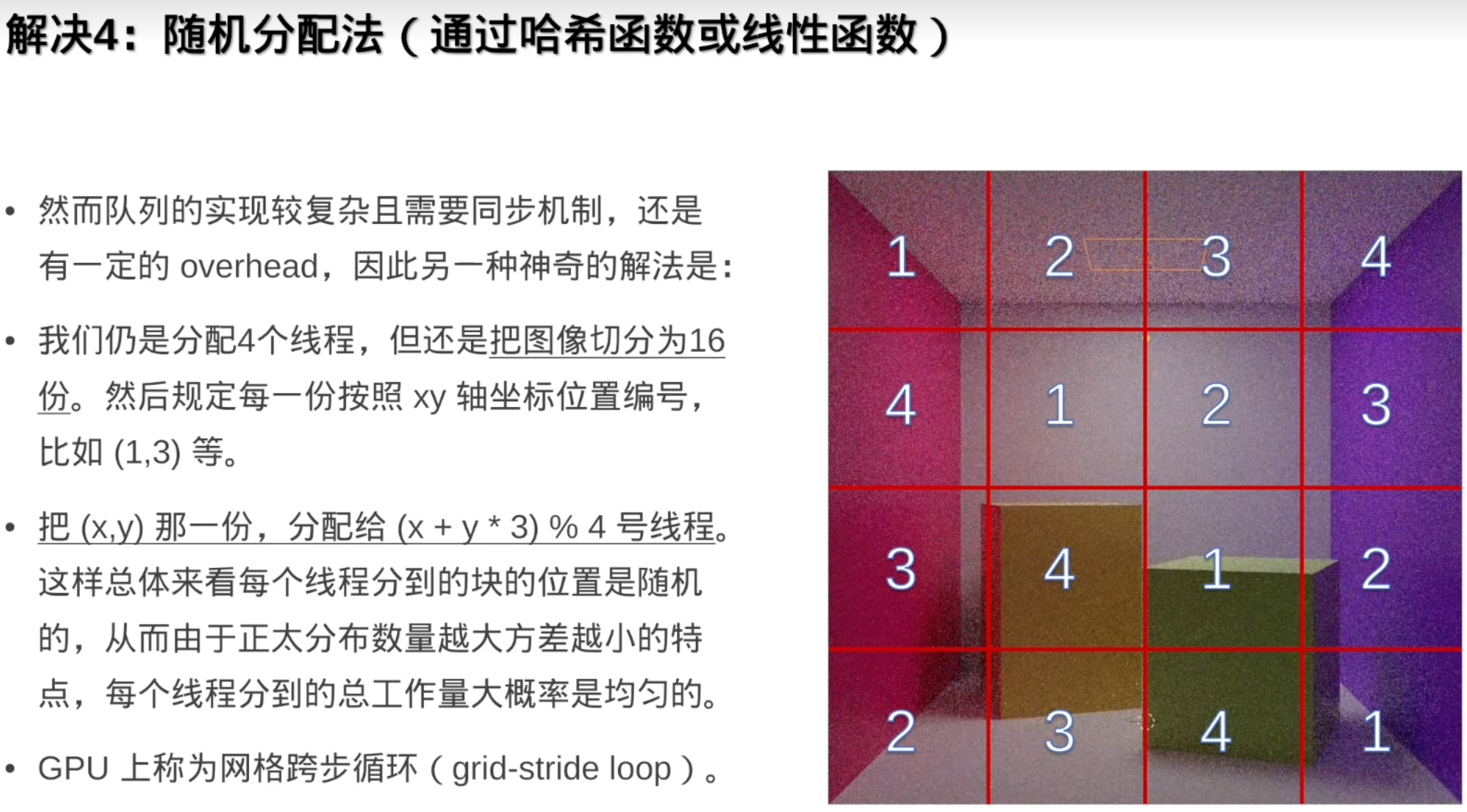
5.任务分配
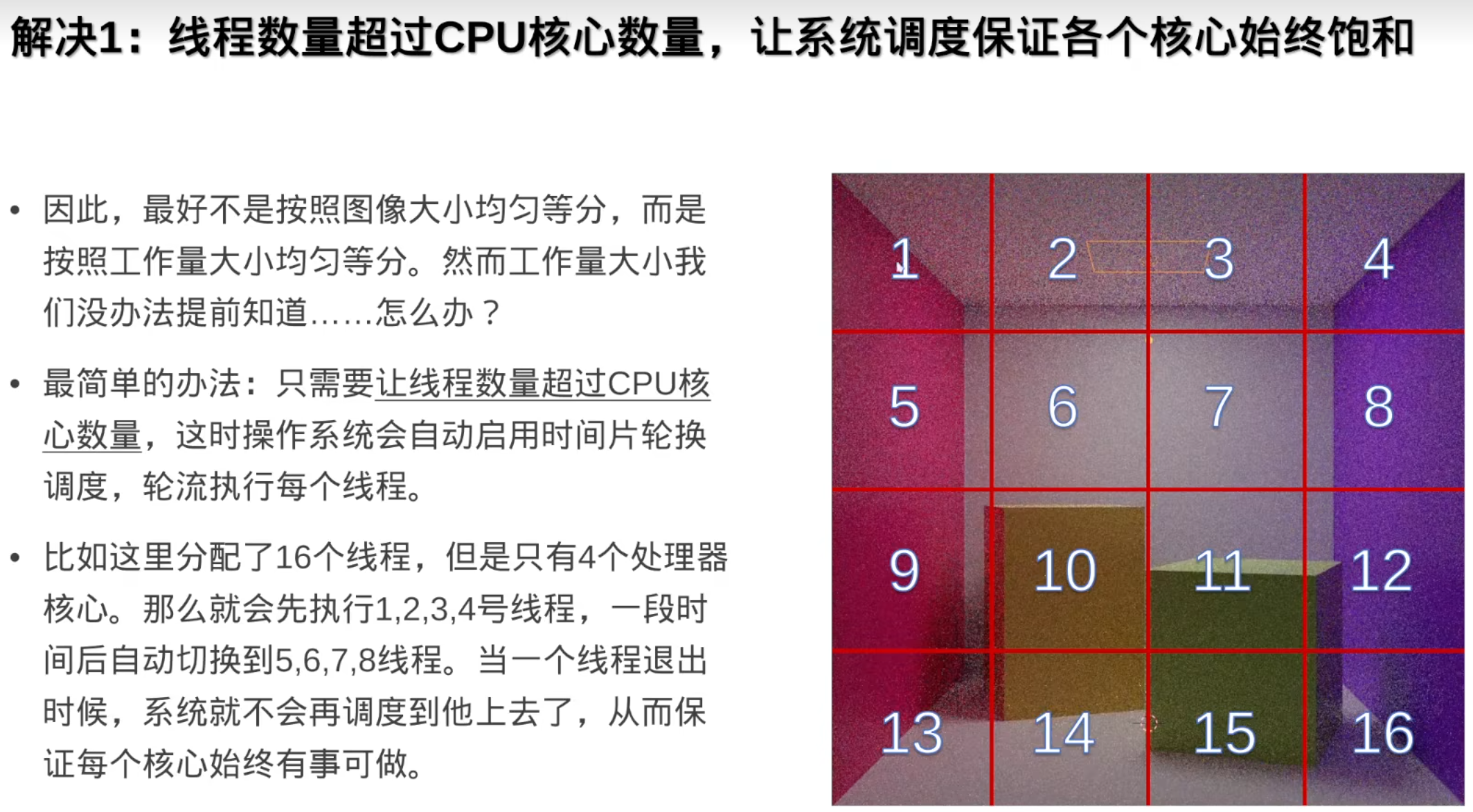
并行的时候怎样把一个任务均匀的分配到每个线程/核心(因为通常几个核心就开几个线程)呢:(线程和任务都不动)

效果不太好,不能让核心闲着,让核心上一直有线程在运行
解决:让线程数大于核心数(让线程动起来)
但是操作系统轮换是有开销(overhead)的,而且有可能破坏缓存一致性
解决:线程池(让任务动起来)
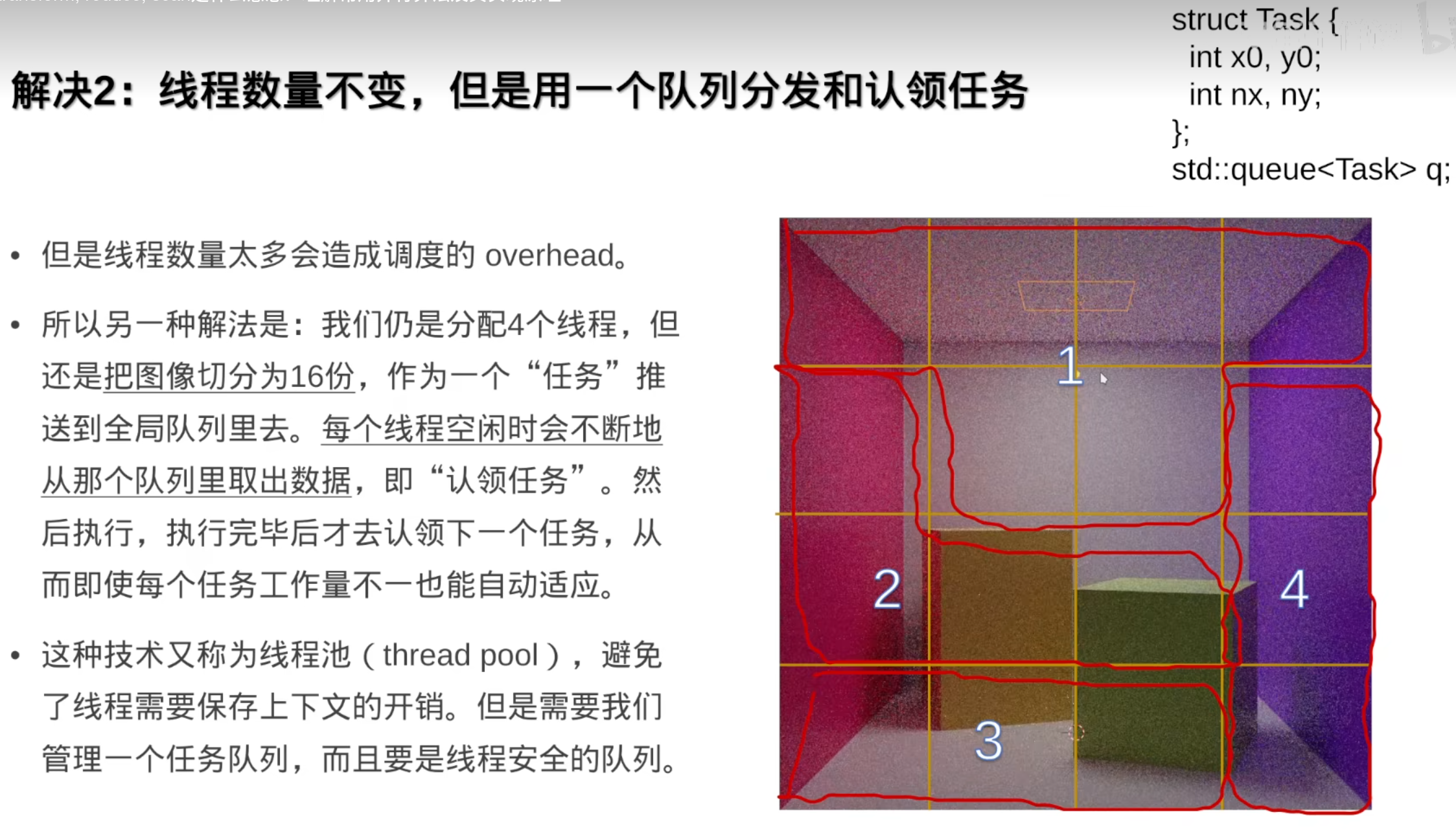
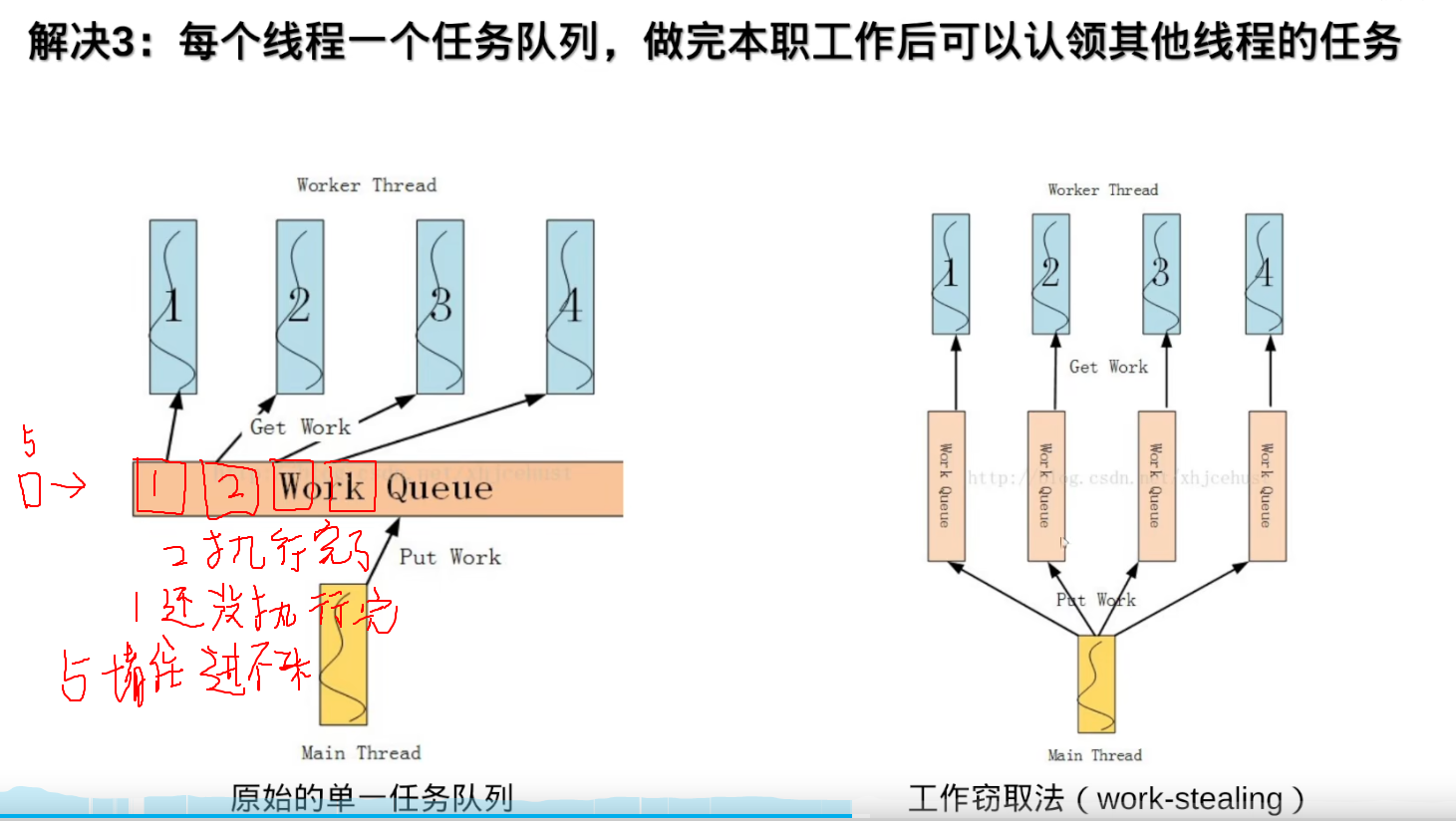
TBB的工作窃取法:
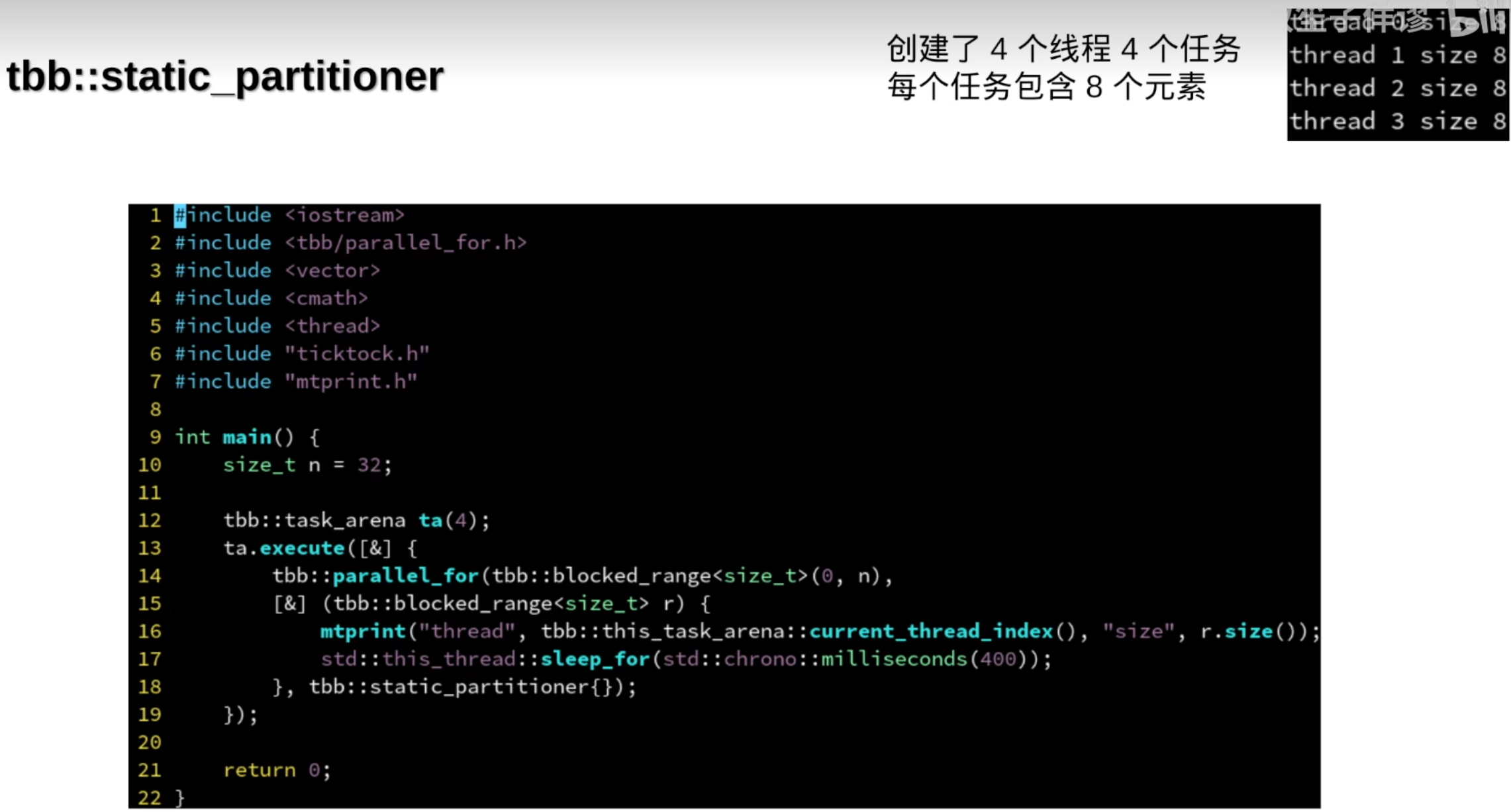
tbb::static_partitioner的线程与任务数量一致
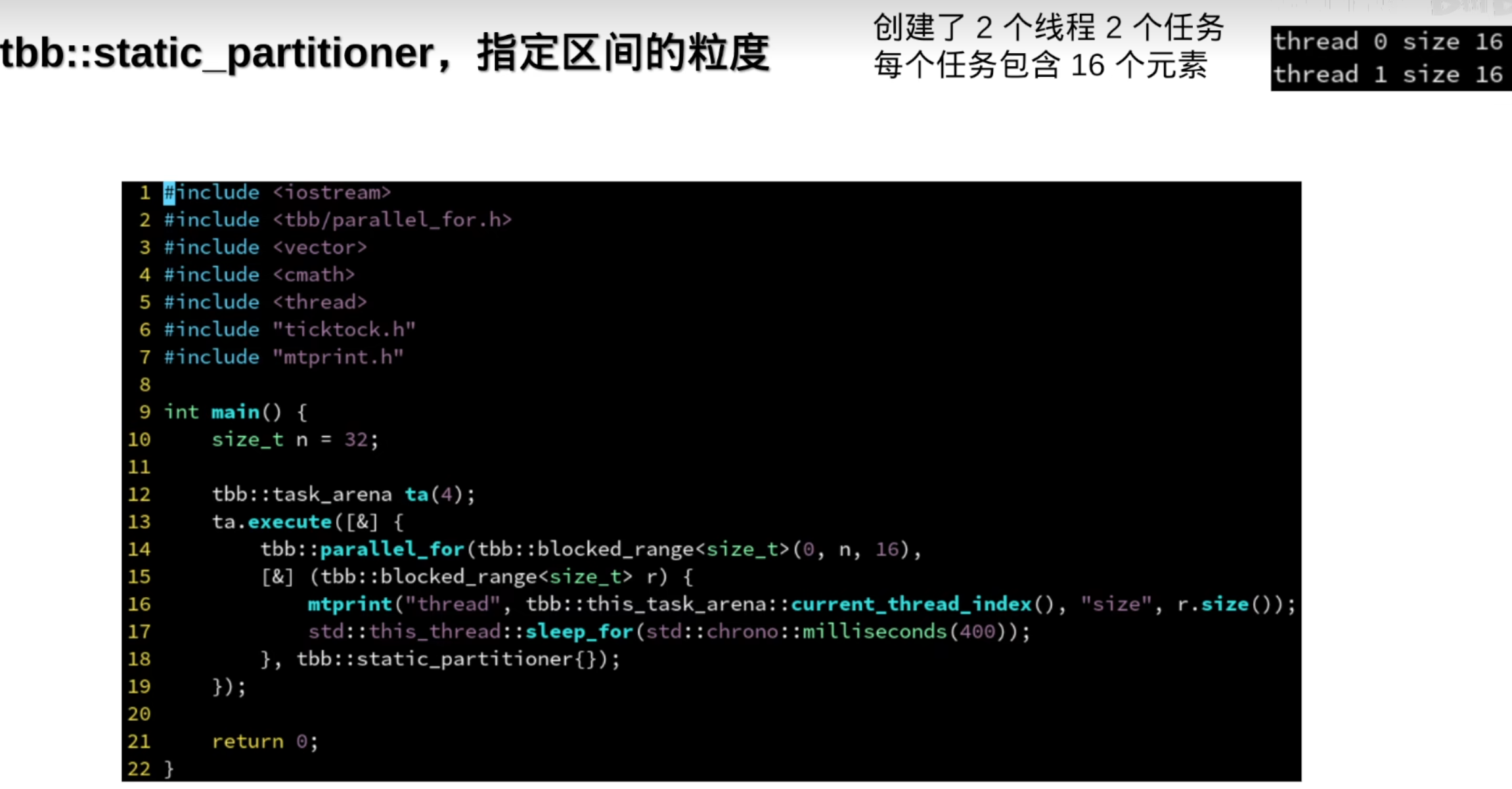
默认粒度(一个任务里的元素)是1
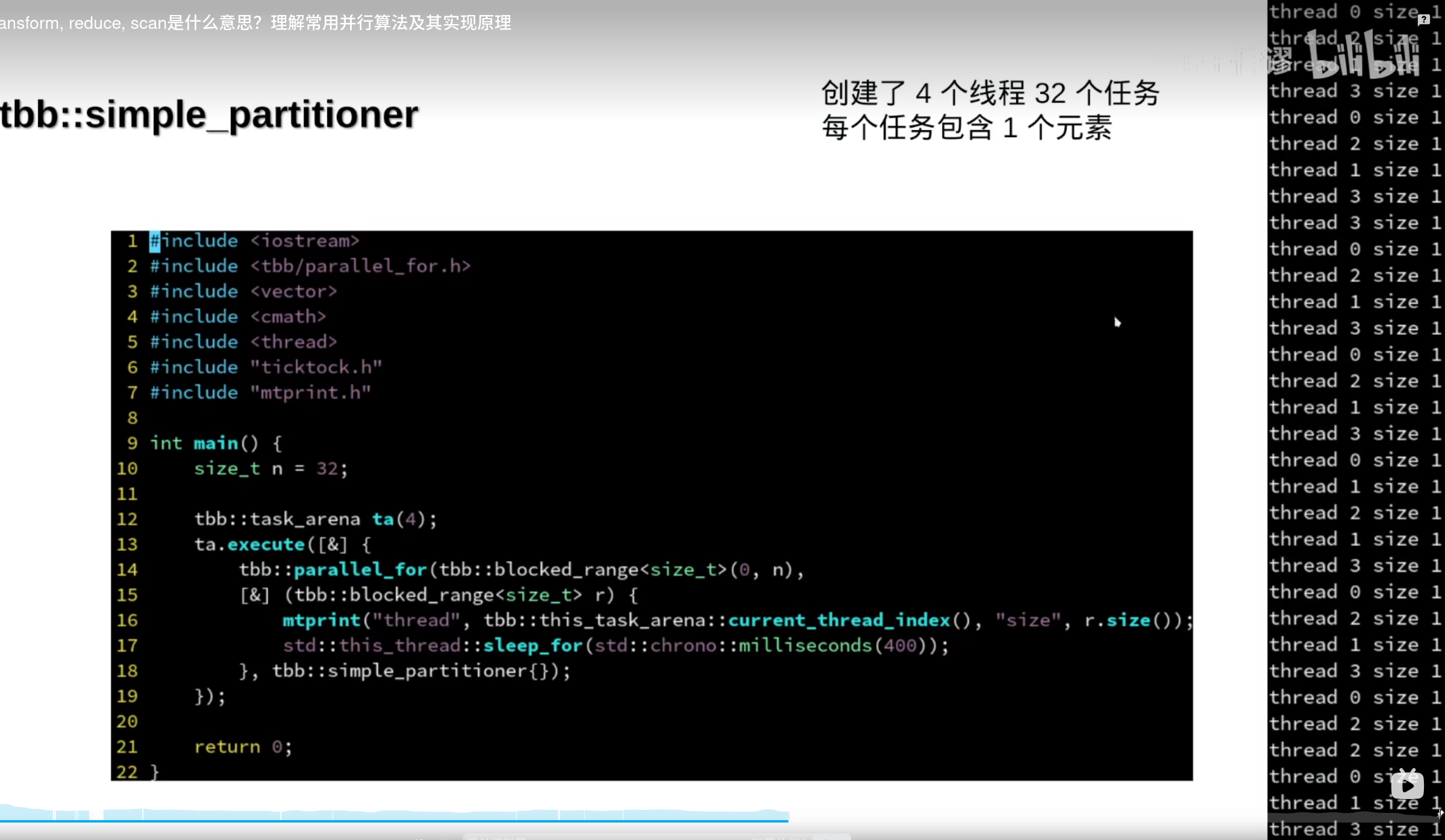


tbb::static_partitioner
描述:将任务静态地分配给线程。
特性
:
- 在任务开始时就确定每个线程将处理哪些任务。
- 适合于任务量相对均匀且已知的情况。
- 不会在运行时重新平衡负载,因此可能导致某些线程空闲而其他线程忙碌。
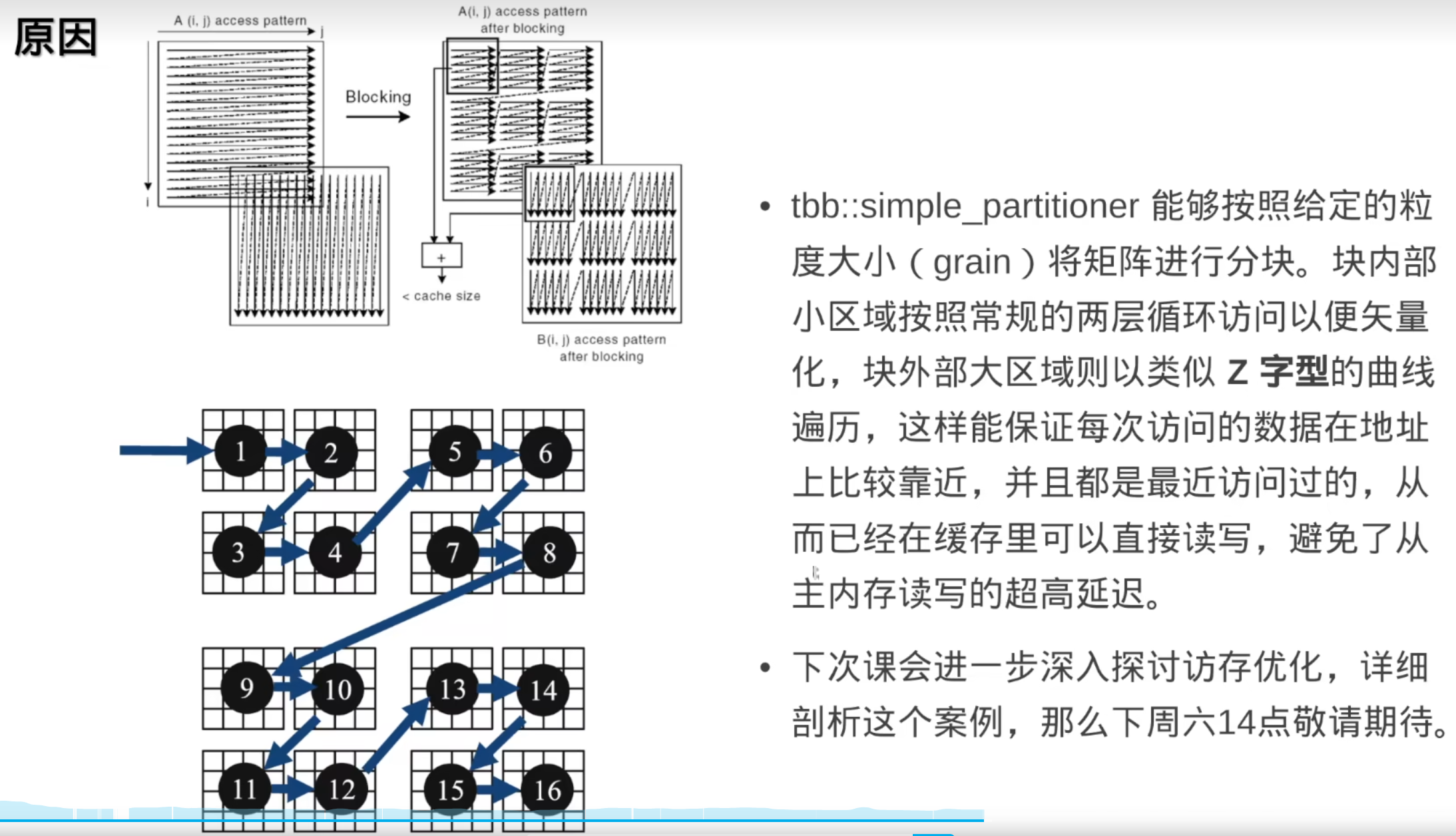
2. tbb::simple_partitioner
描述:提供一个简单的分区策略。
特性
:
- 任务被划分为较小的块,并且每个线程可以从待处理任务中获取一个块。
- 相对于
static_partitioner,simple_partitioner允许更好的负载平衡。 - 适用于任务量不均或动态变化的情况。
3. tbb::auto_partitioner
描述:动态调整任务分配以优化性能。
特性
:
- 在运行时监控线程的工作负载,并根据需要进行任务重新分配。
- 可以实现更好的负载均衡,特别是在任务执行时间不均匀的情况下。
- 适用于复杂的并行任务,能自动适应系统负载。
总结
- 静态分配(
static_partitioner)适用于可预测且均匀的任务;不适合动态负载。 - 简单分配(
simple_partitioner)在一定程度上改进了负载平衡,但仍然保持简单的结构。 - 自动分配(
auto_partitioner)最灵活,适合于动态和不均匀的工作负载,通过实时监测和调整提高整体性能。
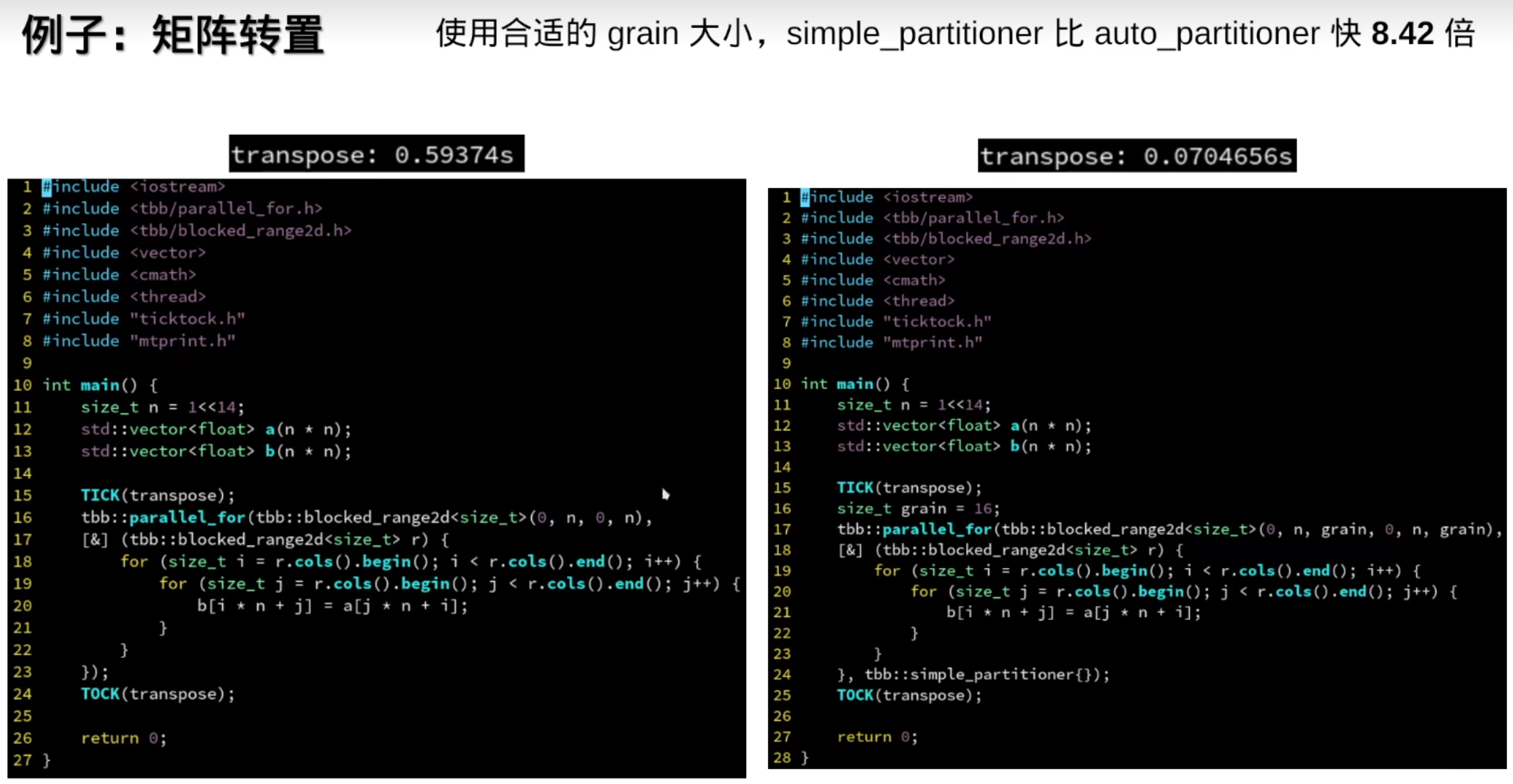
tbb::static_partitioner对循环体不均匀的情况效果不如tbb::simple_partitioner(操作系统调度)
越来越快


但是auto_partitioner一定比simple_partitioner快吗
6.并发容器
问题:

解决:


push_back()返回的是一个迭代器
用*获取迭代器指向的元素的引用,再用and(&)获取这个元素的指针
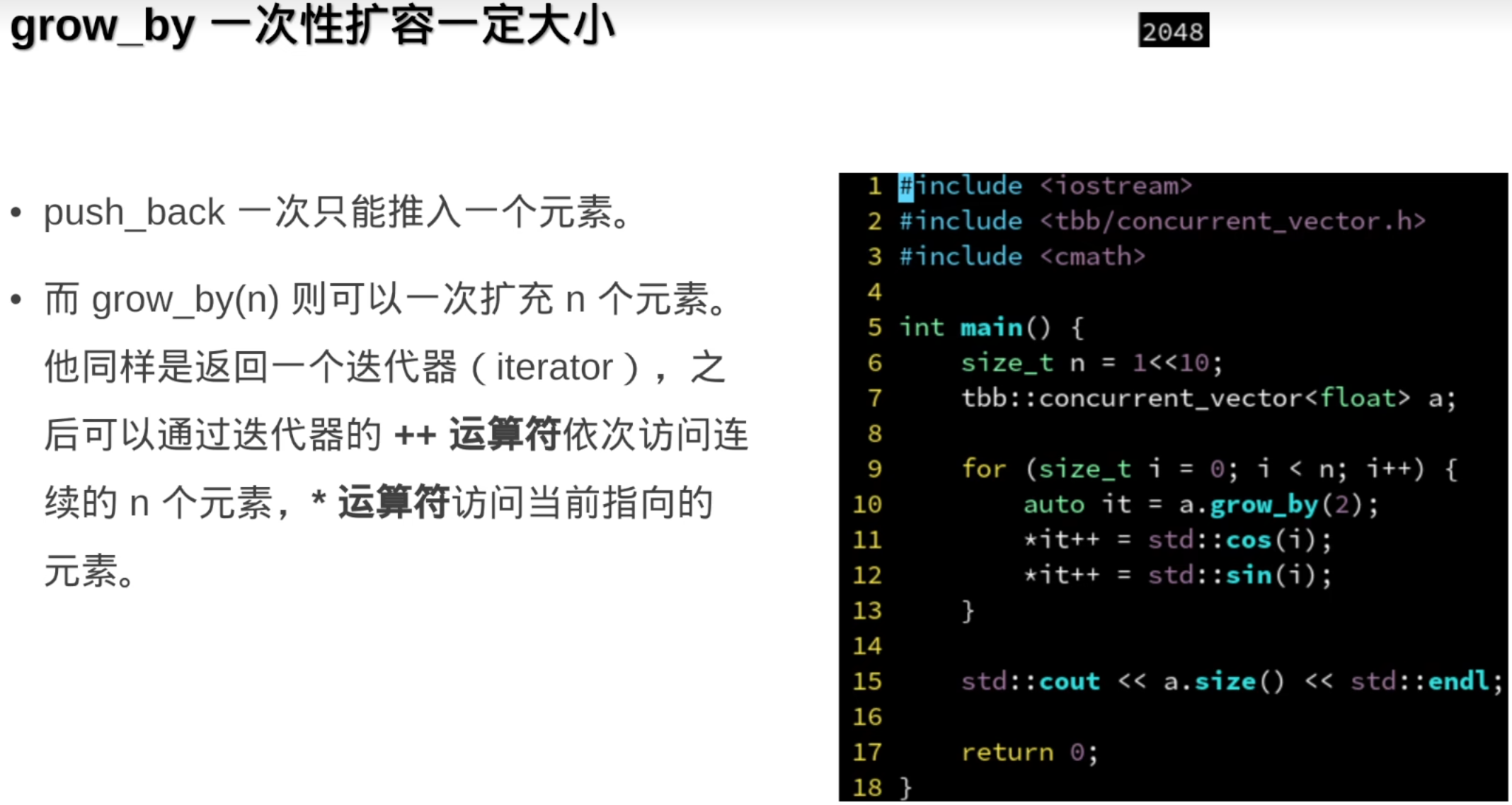
tbb::concurrent_vector还是一个多线程安全的容器

访问:随机访问效率不高

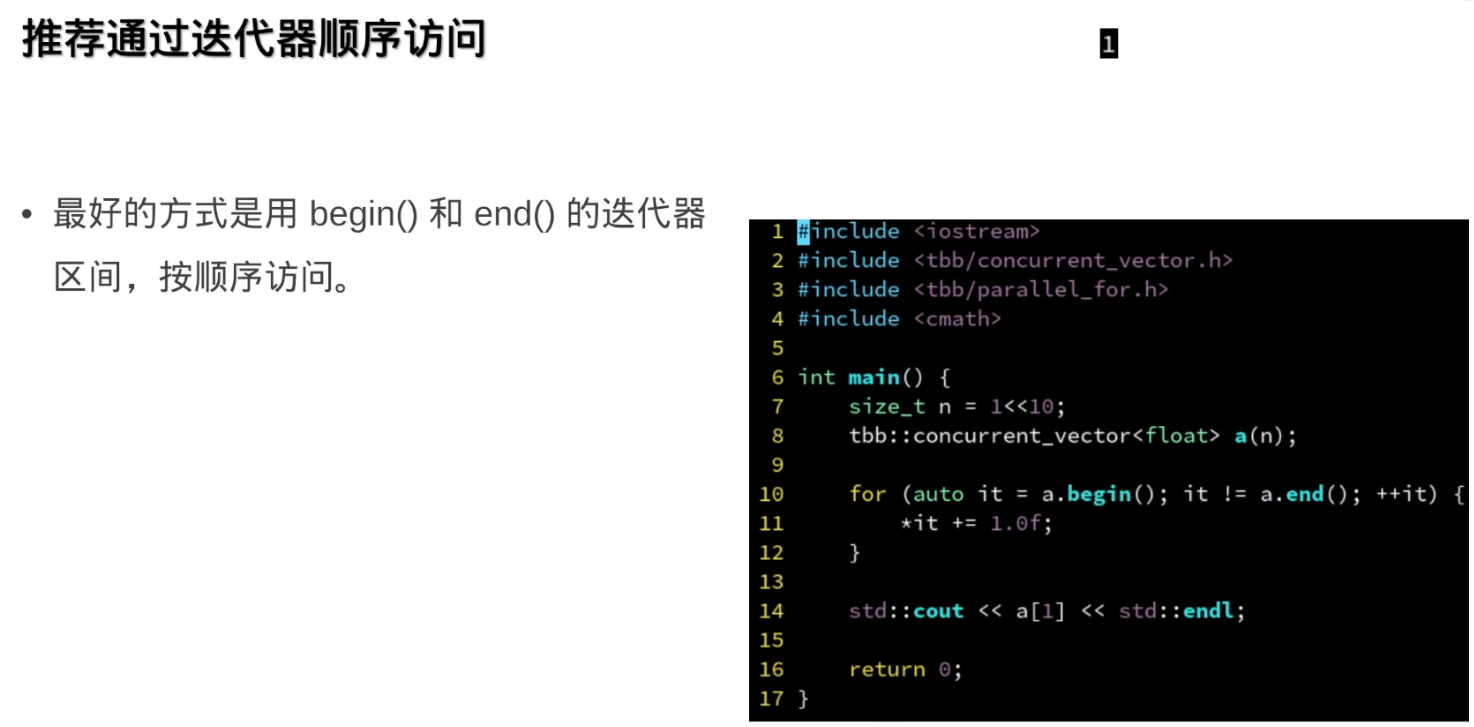
推荐顺序访问:

这些STL容器前加上concurrent就变成了多线程安全版
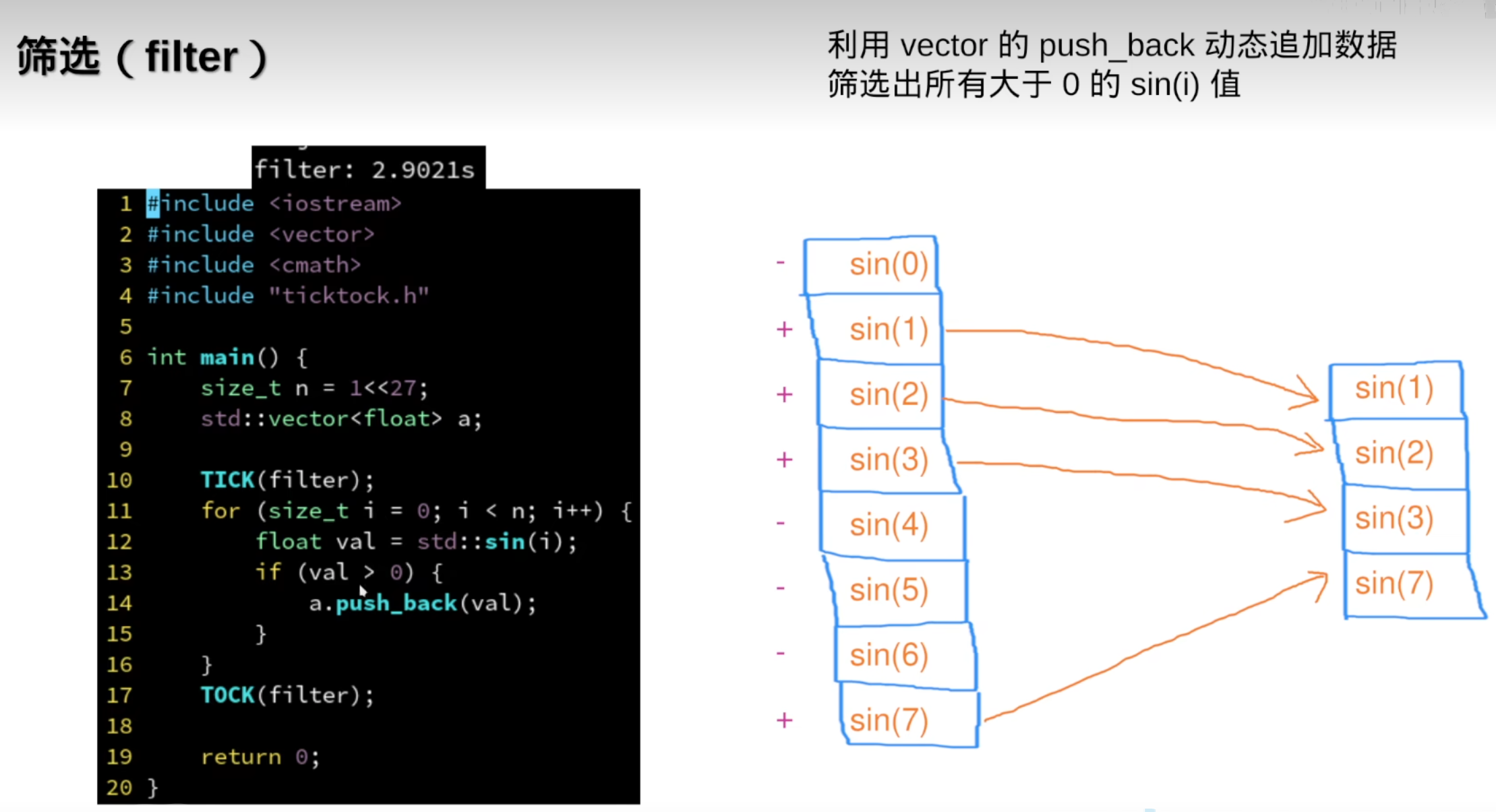
vector/concurrent_vector有一个常见的用法:用于并行筛选数据:
7.并行筛选
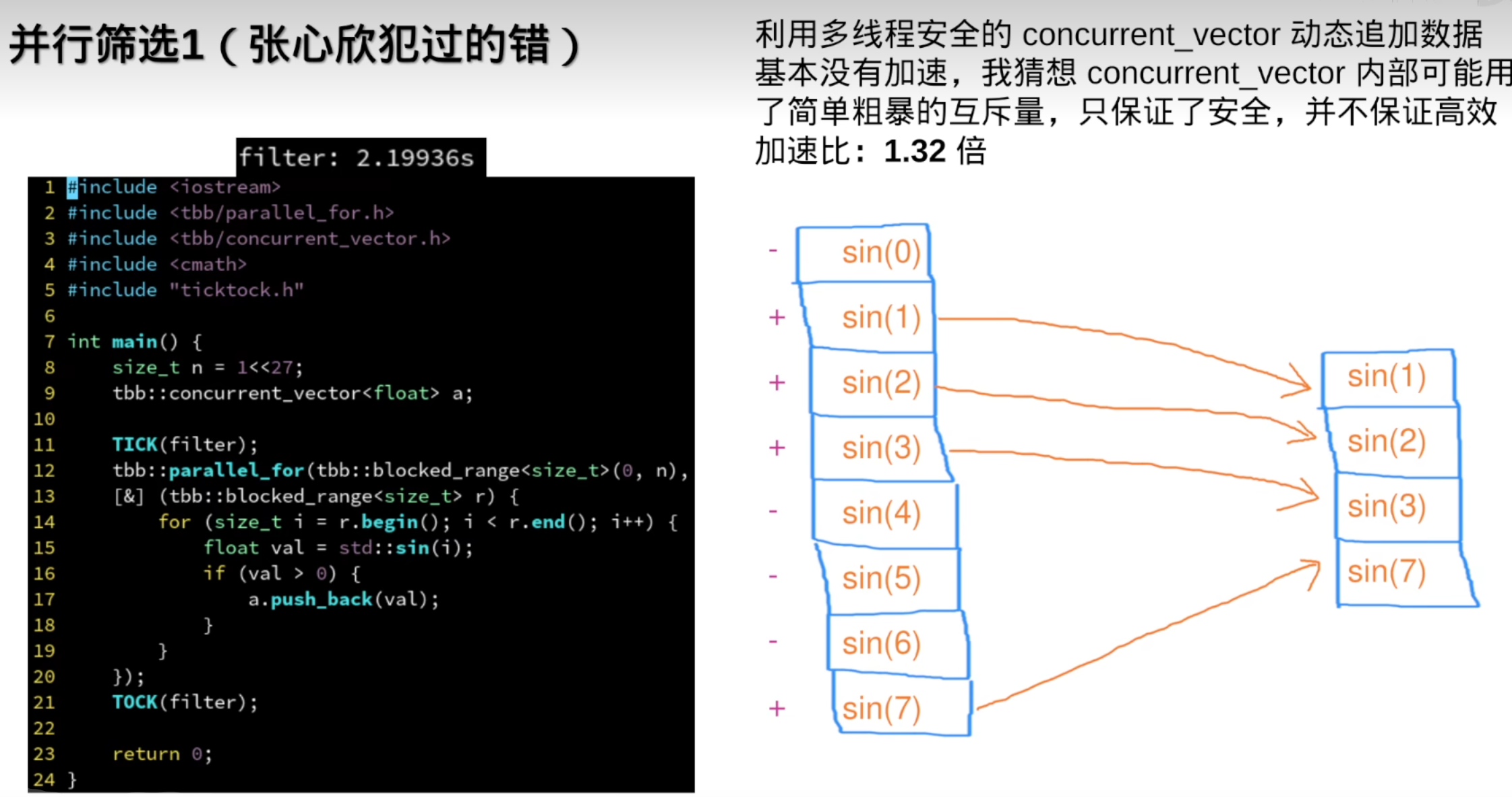

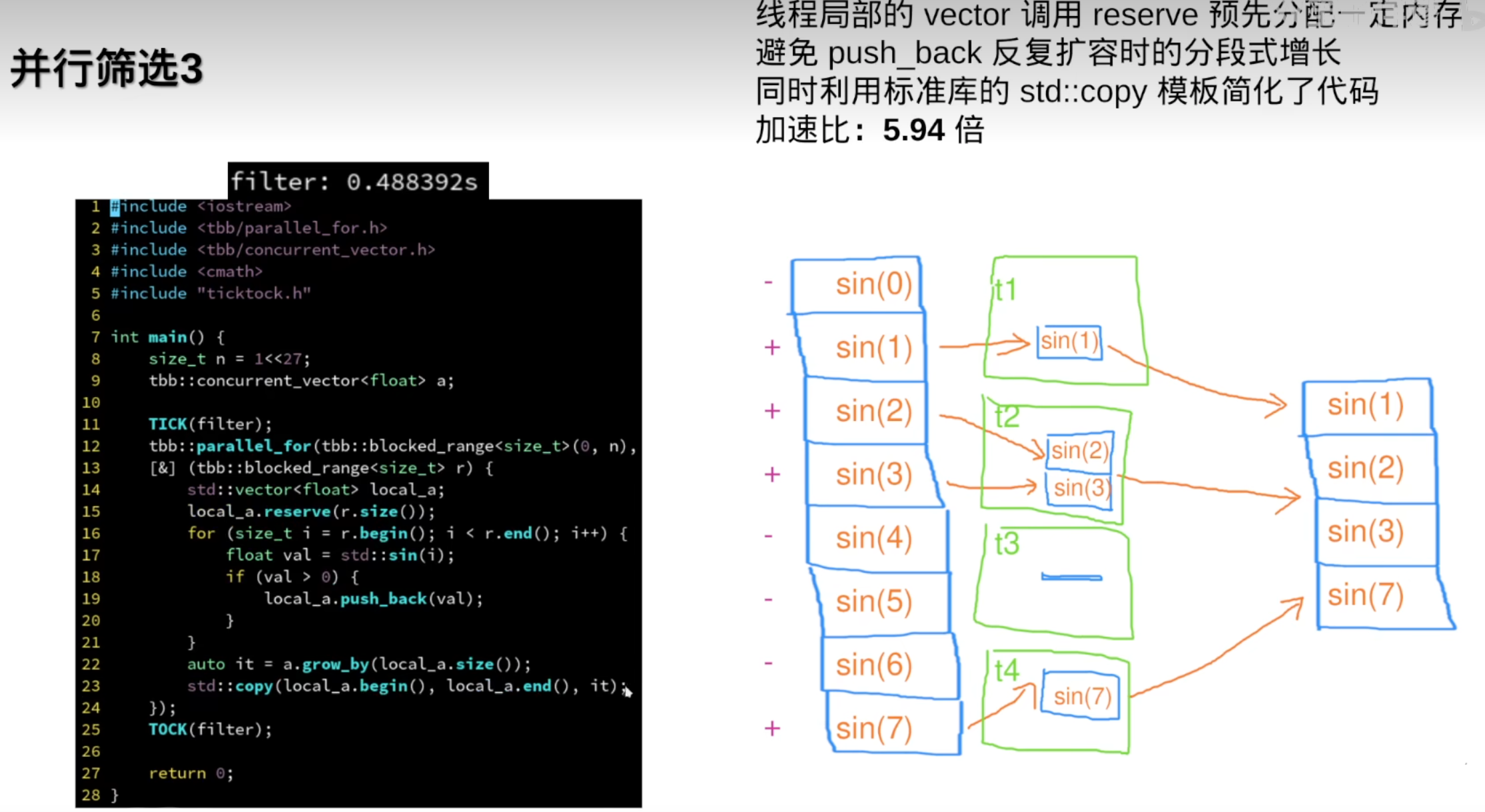
但需要连续数据时,还是需要std::vetor
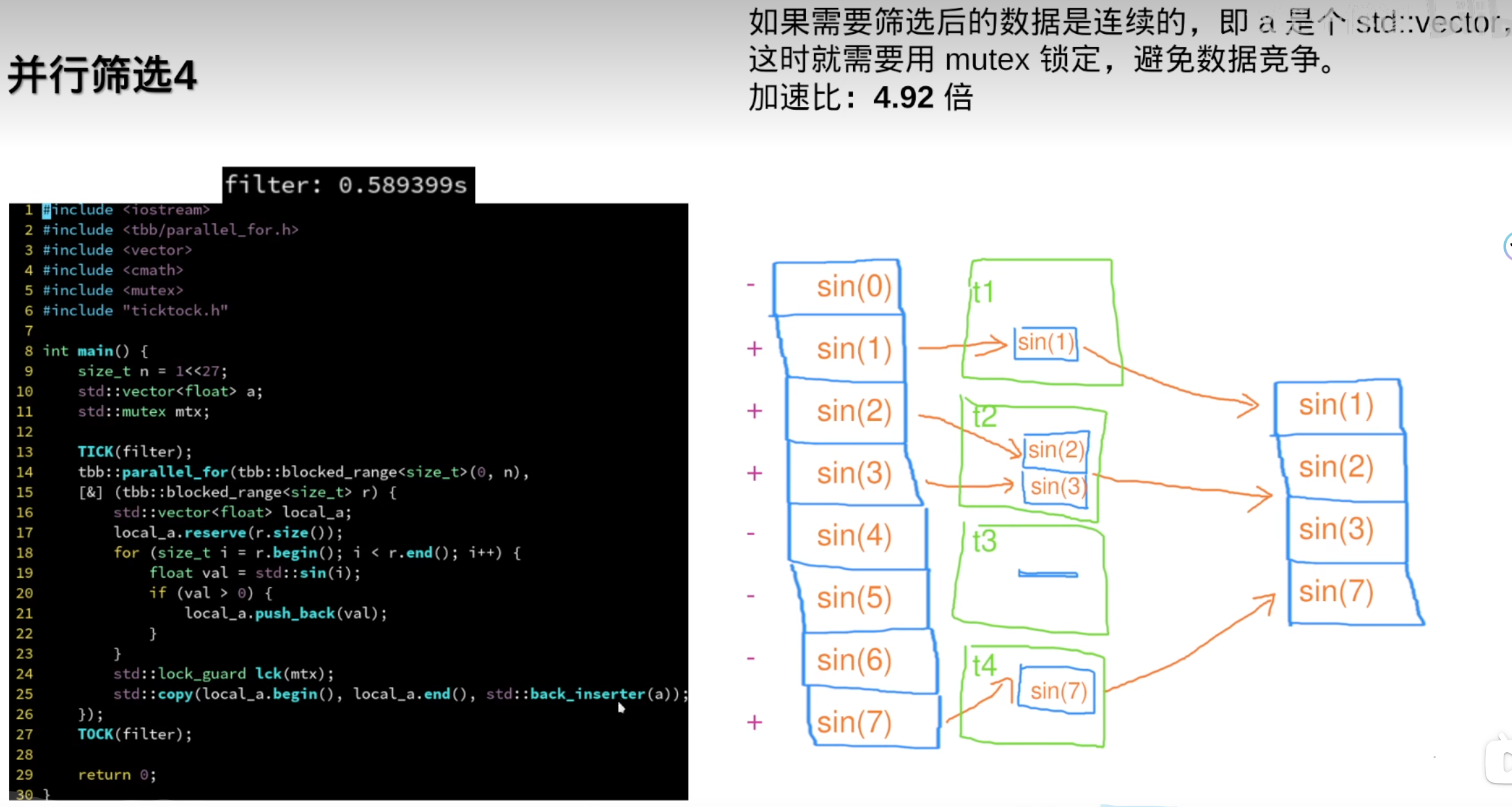
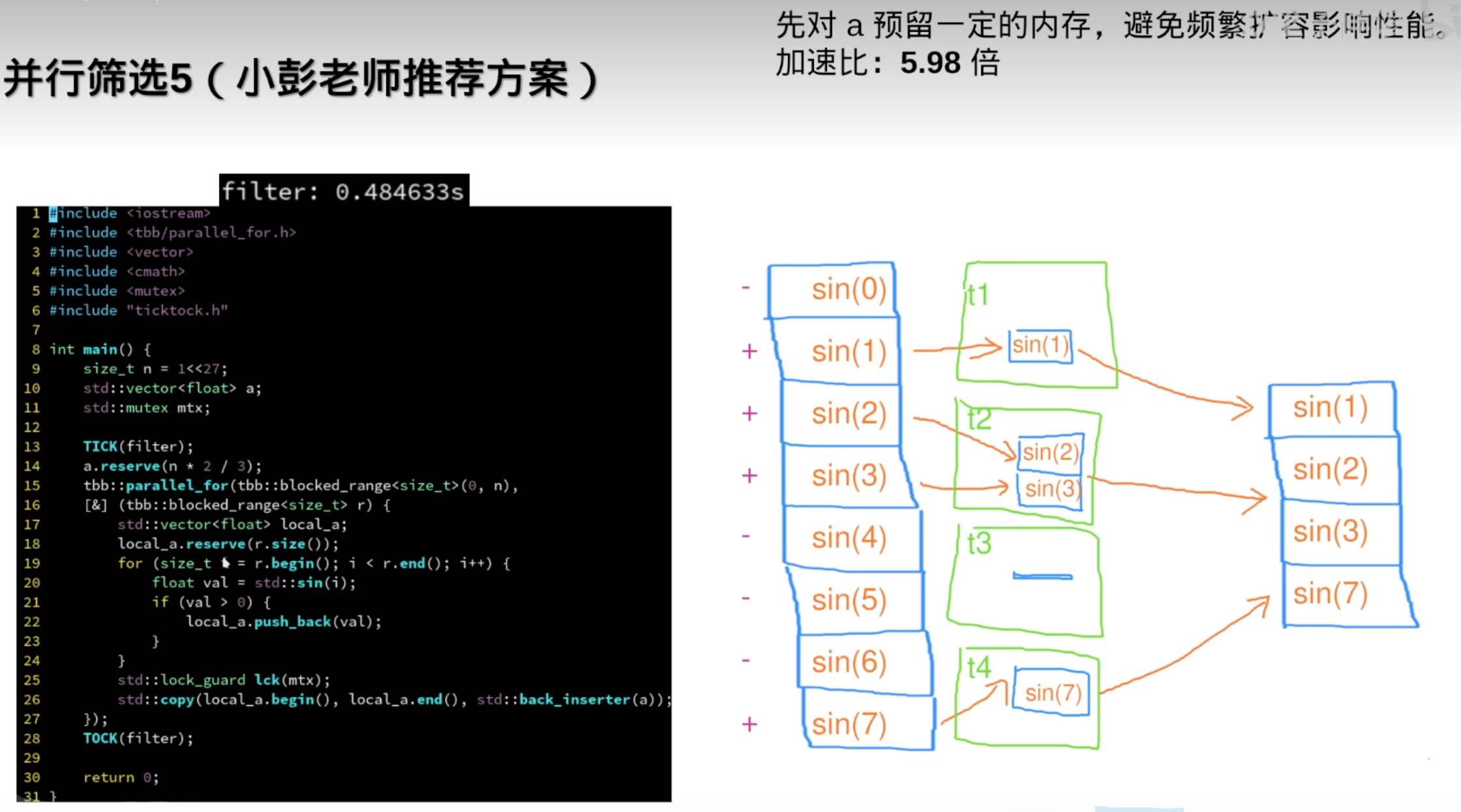
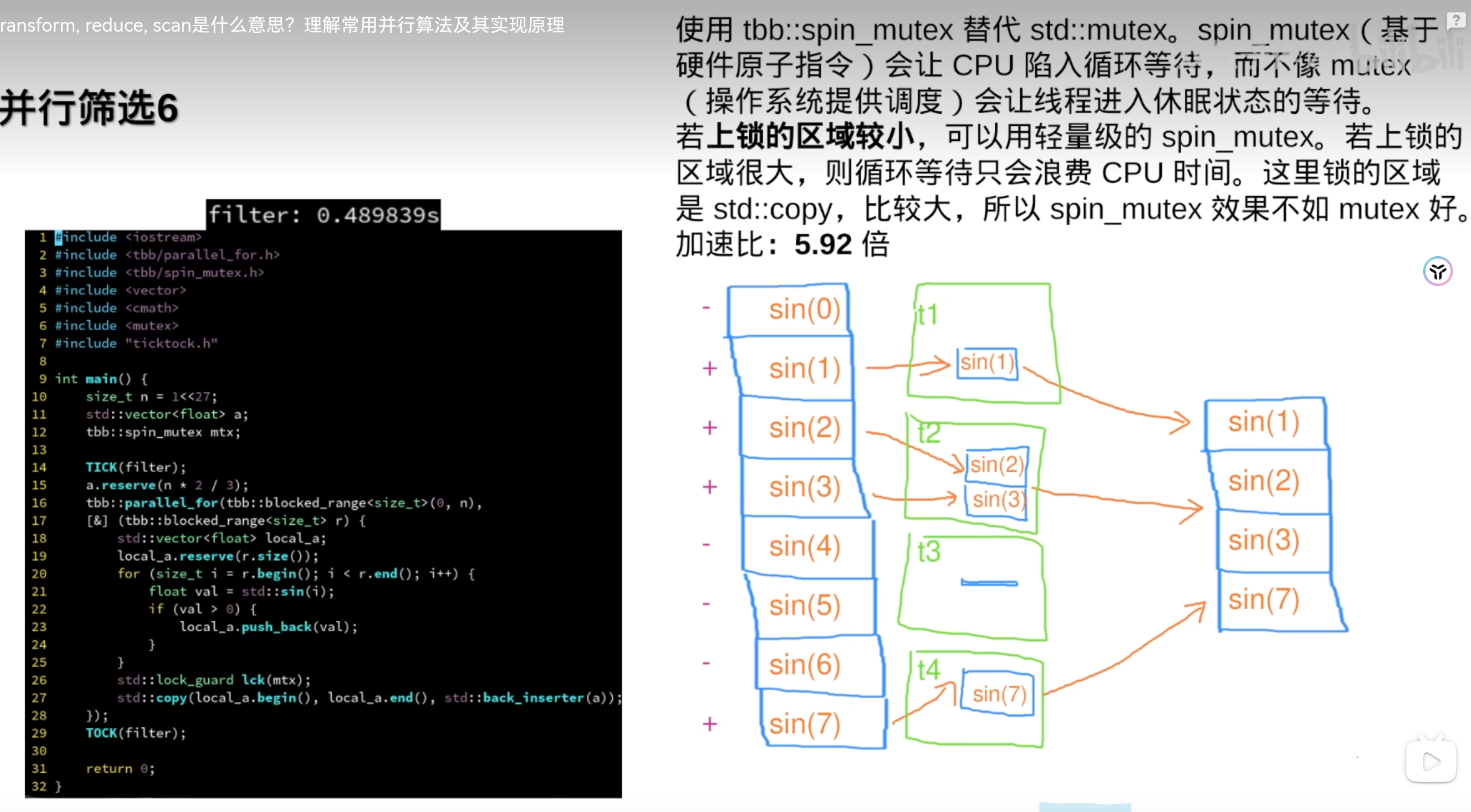
8.分治与排序
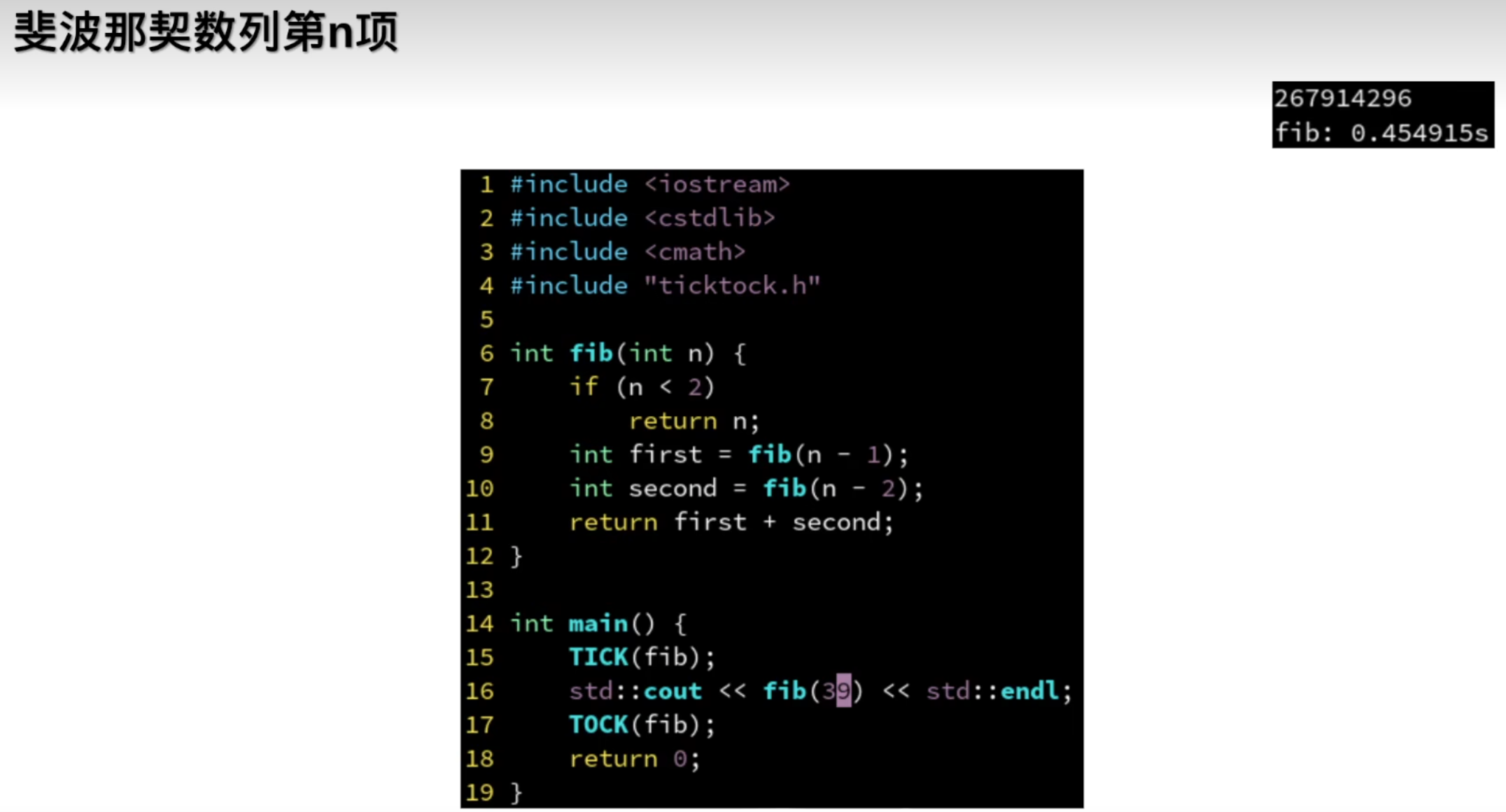
反而变慢了:
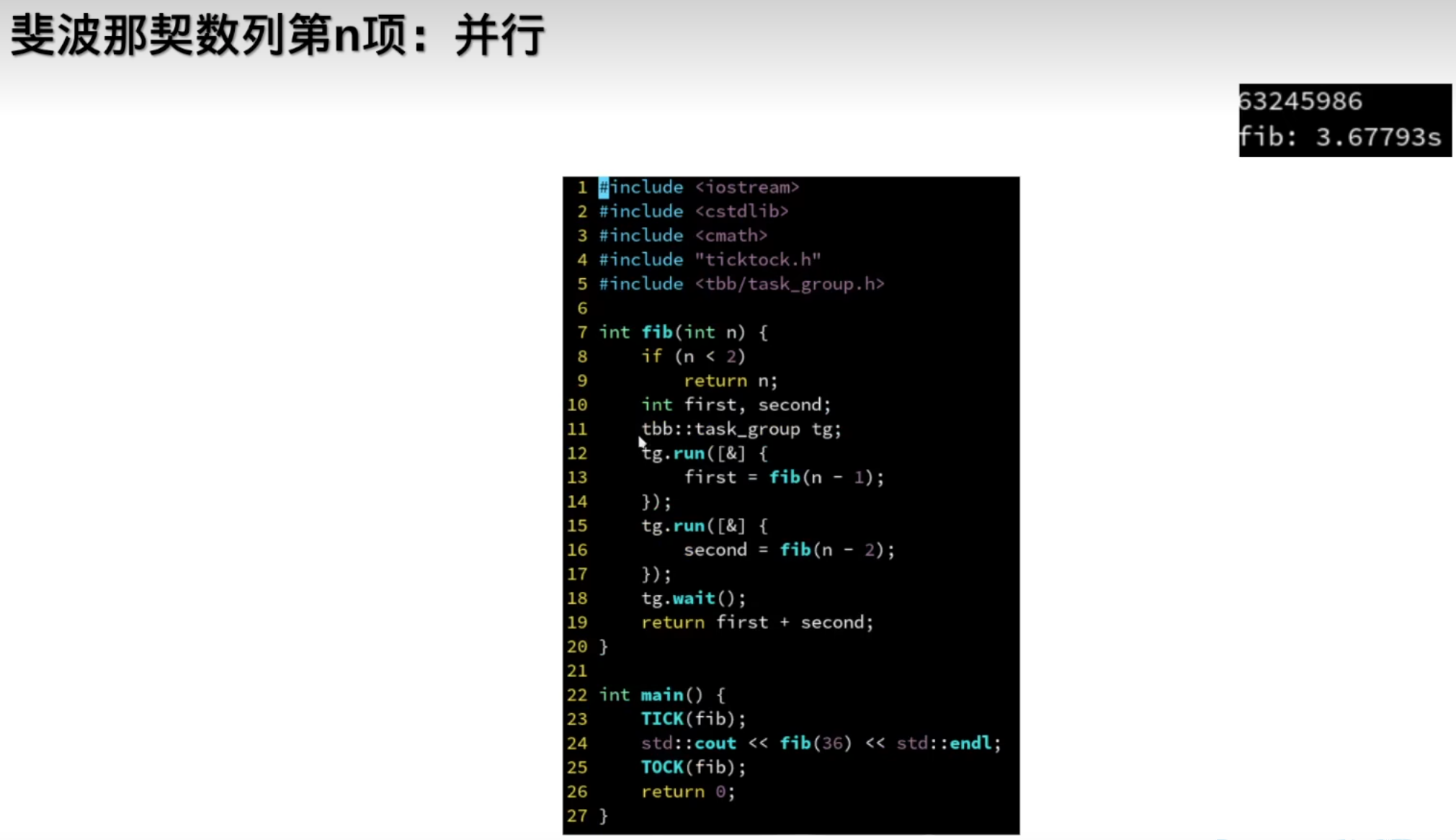
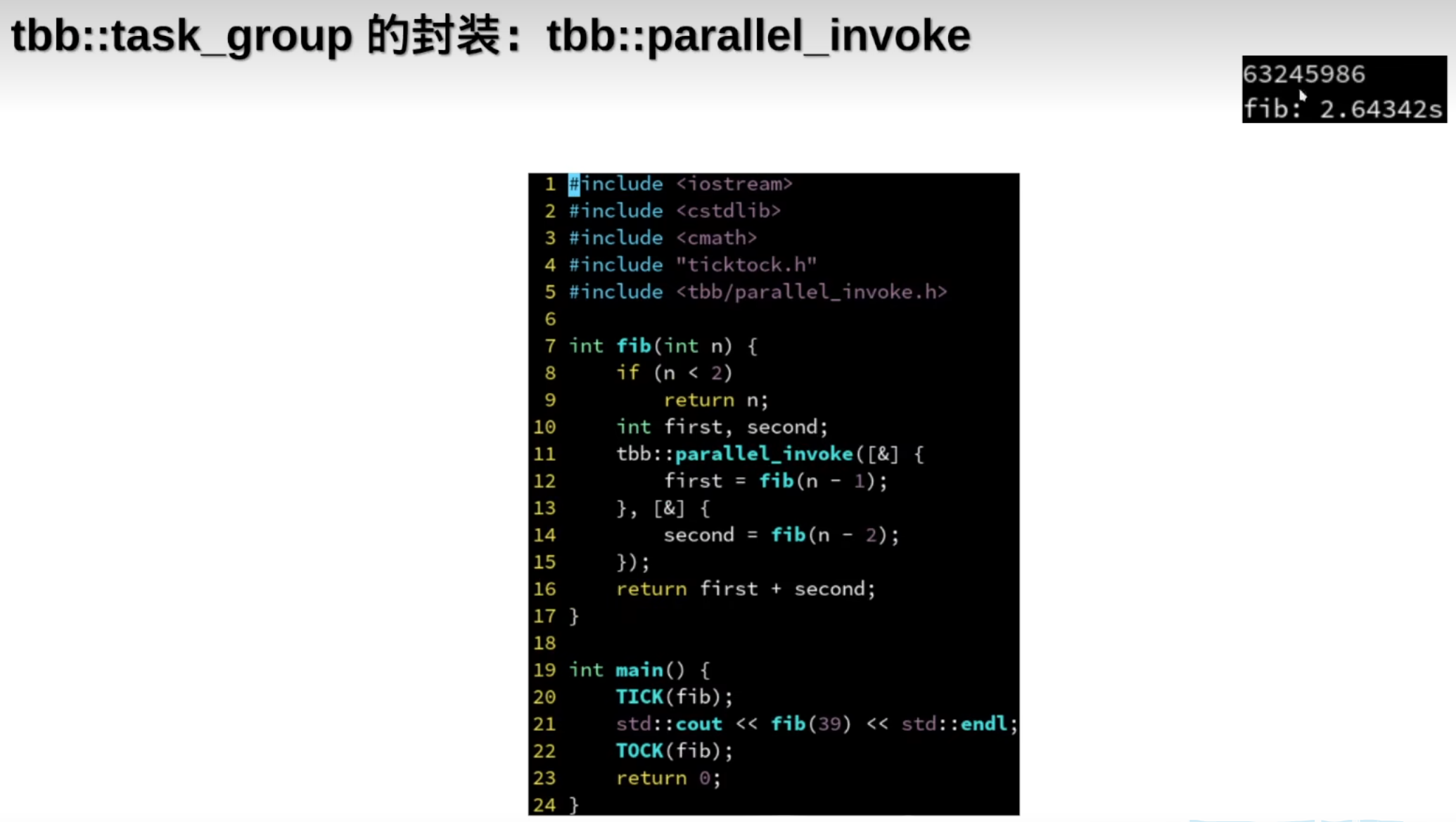
分治

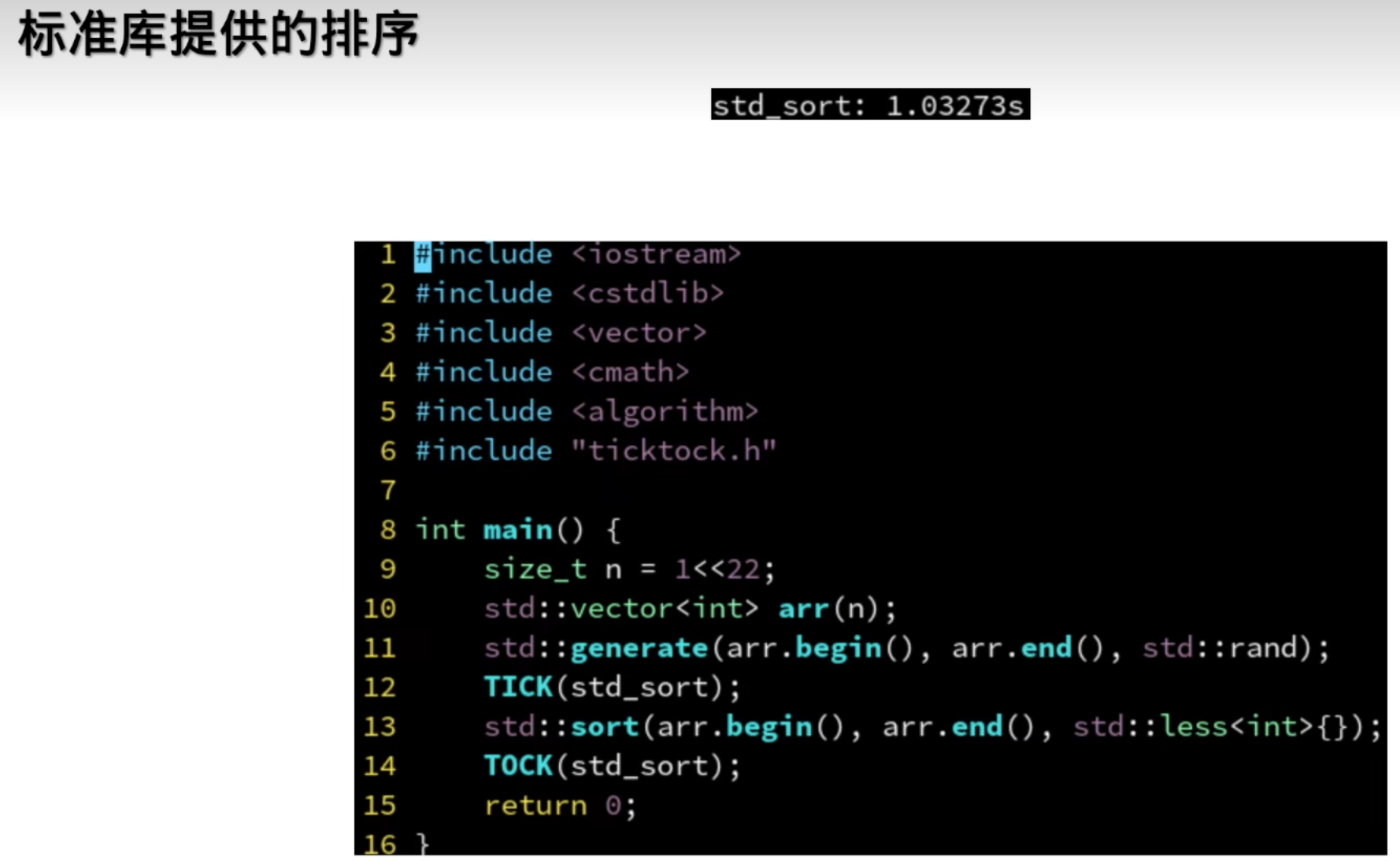
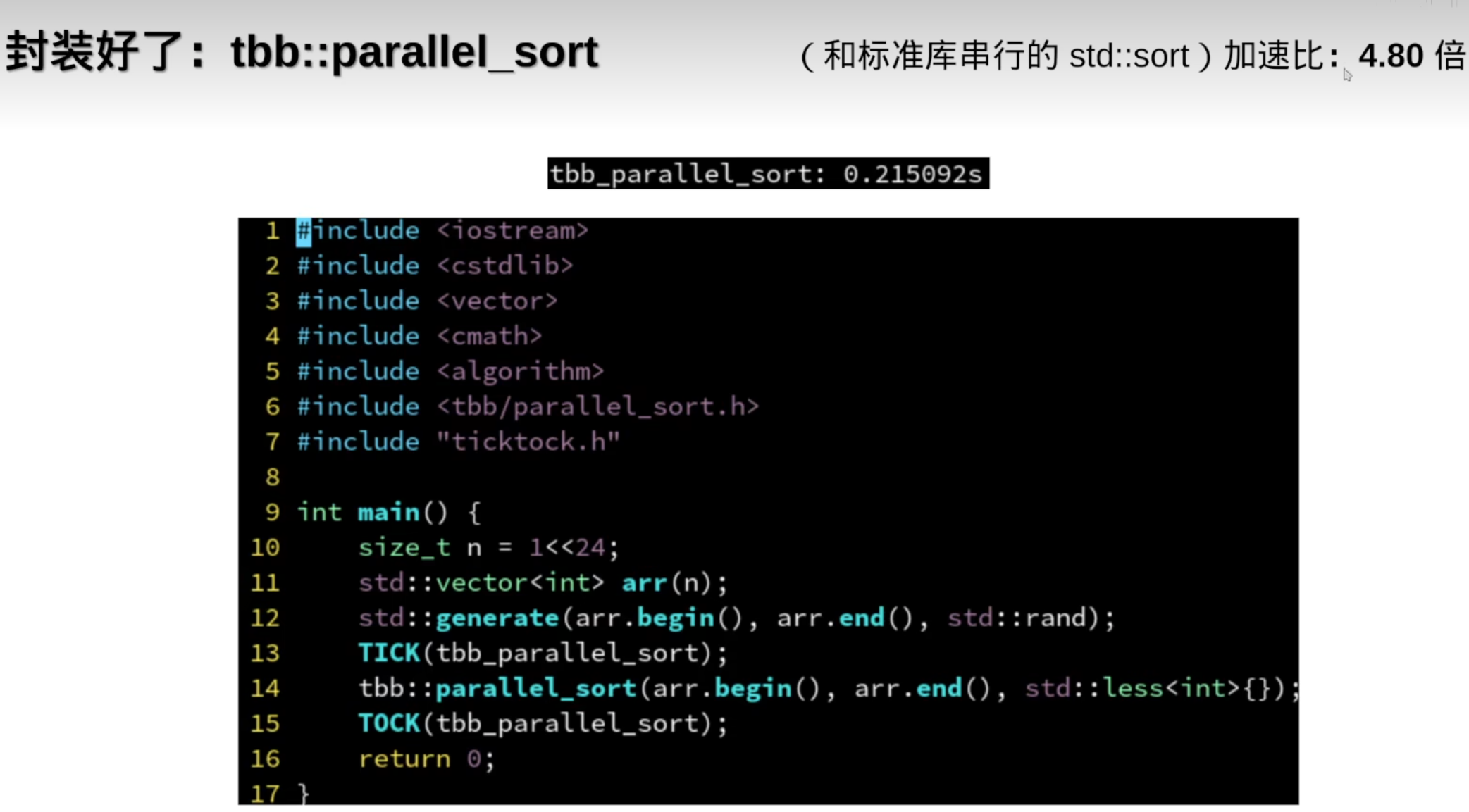
9.流水线并行
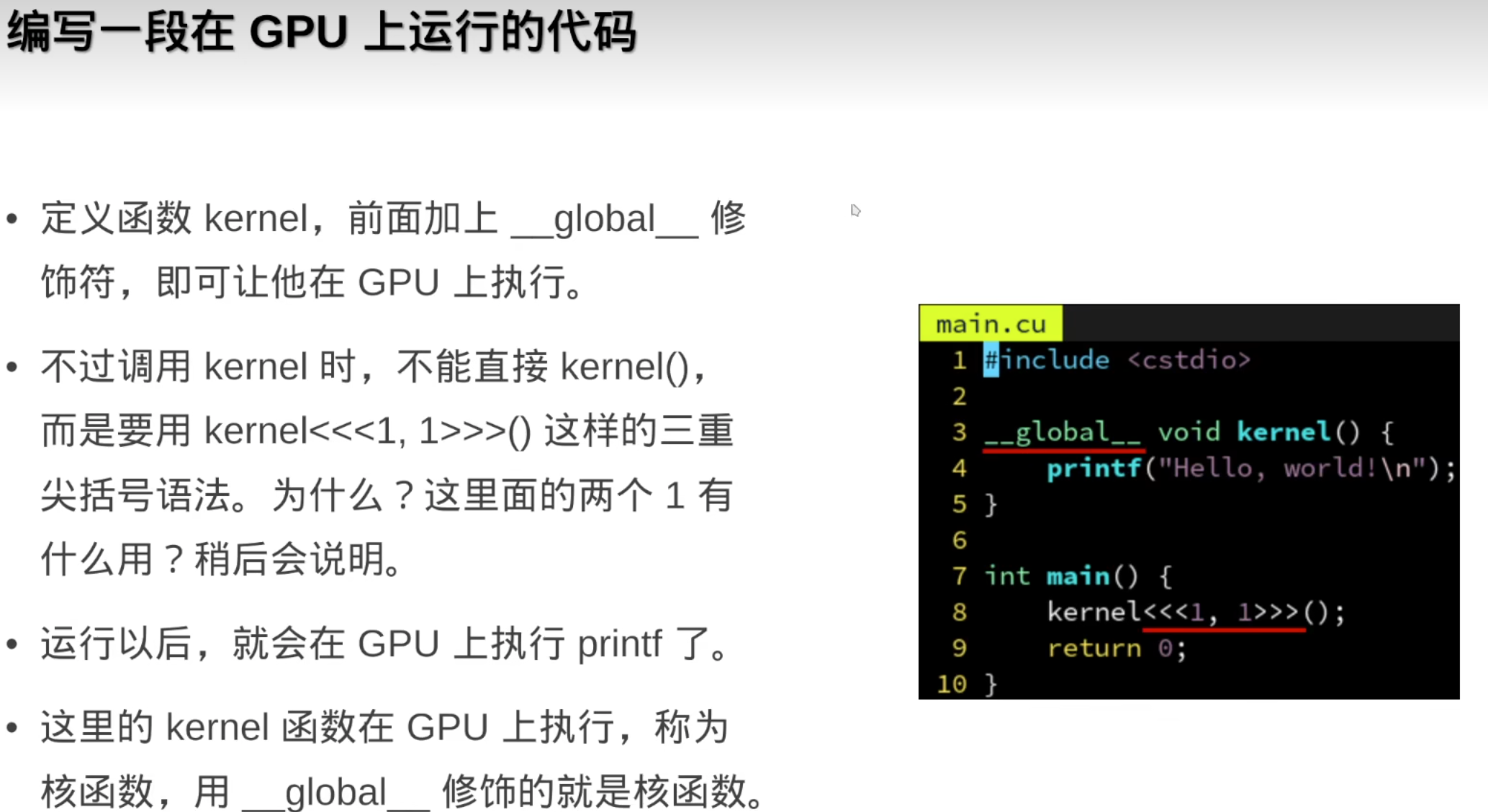
CUDA开启的GPU编程

类对象的声明
ThreadPool threadPool {}; 和 ThreadPool threadPool; 的主要区别在于初始化方式:
1. ThreadPool threadPool {};
- 列表初始化:使用了列表初始化(uniform initialization),这是 C++11 引入的一种语法。
- 安全性:这种方式可以防止窄化转换(例如,浮点数到整数的转换),因此更安全。
- 调用构造函数:会调用
ThreadPool类的默认构造函数。
2. ThreadPool threadPool;
- 默认构造:这是经典的对象定义语法,直接调用默认构造函数。
- 行为:如果
ThreadPool类没有定义任何构造函数,编译器会自动生成一个默认构造函数。 - 窄化问题:没有列表初始化的安全性,如果初始化涉及类型转换,可能会导致窄化。
总结
- 功能上:两者都用于创建
ThreadPool对象并调用默认构造函数。 - 安全性:
ThreadPool threadPool {};更安全,适用于需要避免潜在类型转换问题的场景。
不存在这样的写法:ThreadPool threadPool ();
加括号是错的,加花括号是安全的,推荐花括号
变量的声明
std::atomic_flag flag; 和 std::atomic_flag flag {}; 的效果是相同的,都会将 flag 初始化为未设置状态。不过,使用 {} 的形式更加显式,可能更符合现代C++的最佳实践。
new SimpleTask() 和 new SimpleTask 在功能上是等价的,都是创建一个 SimpleTask 对象并返回指向该对象的指针。
非常量左值引用问题
常量引用(const T&)可以绑定到临时对象,而非常量左值引用(T&)则不能。
glm::vec3 setPixel(size_t x,size_t y,glm::vec3 &pixel){
return pixels[width*y+x]=pixel;
}
film.setPixel(y,x,glm::vec3(0.5,0.4,0.3));
Non-const lvalue reference to type 'vec<...>' cannot bind to a temporary of type 'vec<...>'
或者
film.setPixel(y,x,{0.5,0.4,0.3});
Non-const lvalue reference to type 'glm::vec3' (aka 'vec<3, float, defaultp>') cannot bind to an initializer list temporary
改为:
glm::vec3 setPixel(size_t x,size_t y,const glm::vec3 &pixel){
return pixels[width*y+x]=pixel;
}