
IOU —-交并比
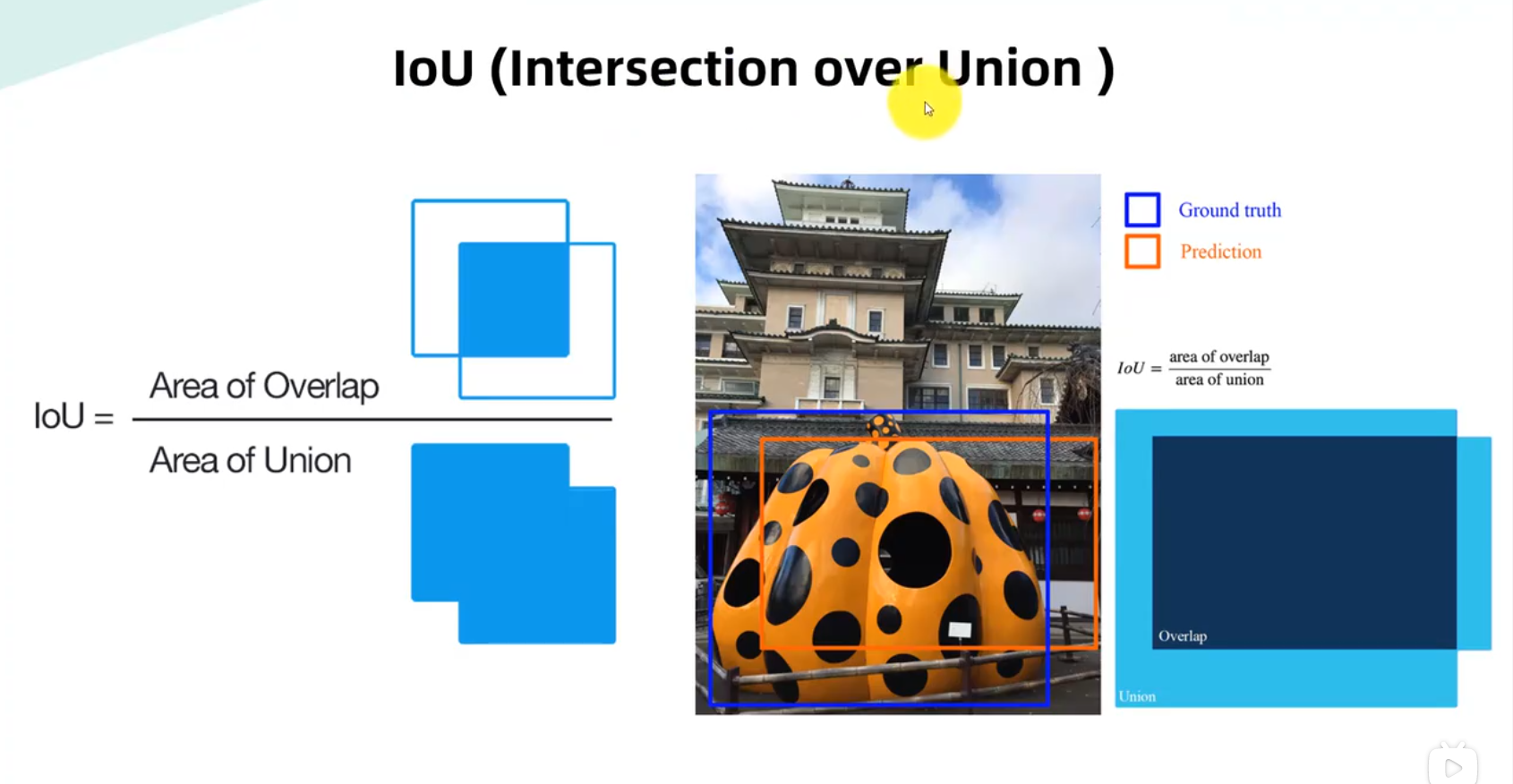
Lou为1意味着预测边界框和地面真实边界框完全重叠。
您可以为LOU设置阈值,以确定对象检测是否有效。
假设您将LOU设置为0.5,在这种情况下。
·如果LOU≥为0.5,则将目标检测归类为真阳性(TP)。
如果LOU<0.5,则为错误检测,并将其归类为假阳性(FP)。
当图像中存在地面真实且模型未能检测到目标时,分类。
作为假阴性(FN)。
真负片(TN):TN是我们没有预测到物体的图像的每一部分。
度量对于目标检测没有用处,因此我们忽略TN。

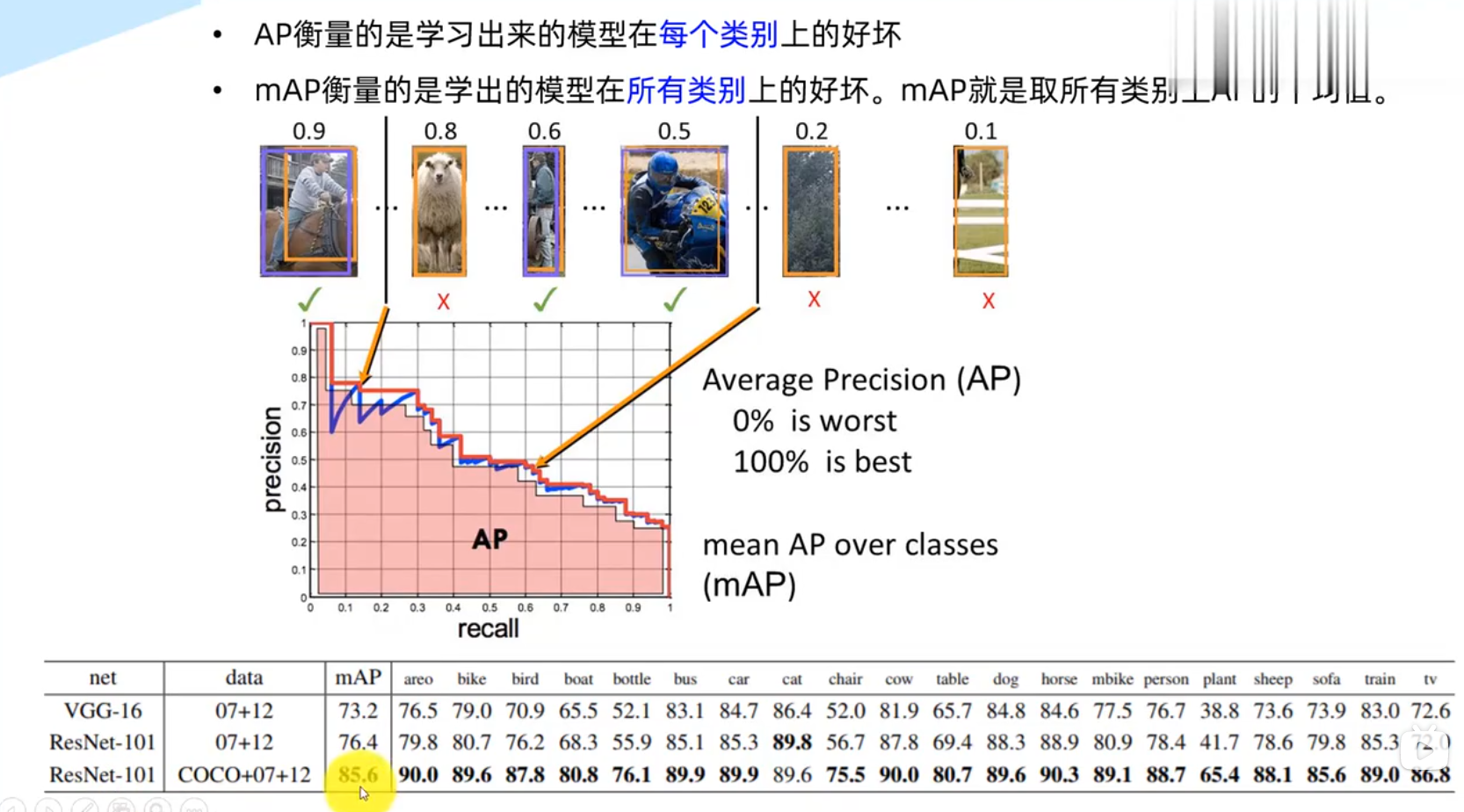
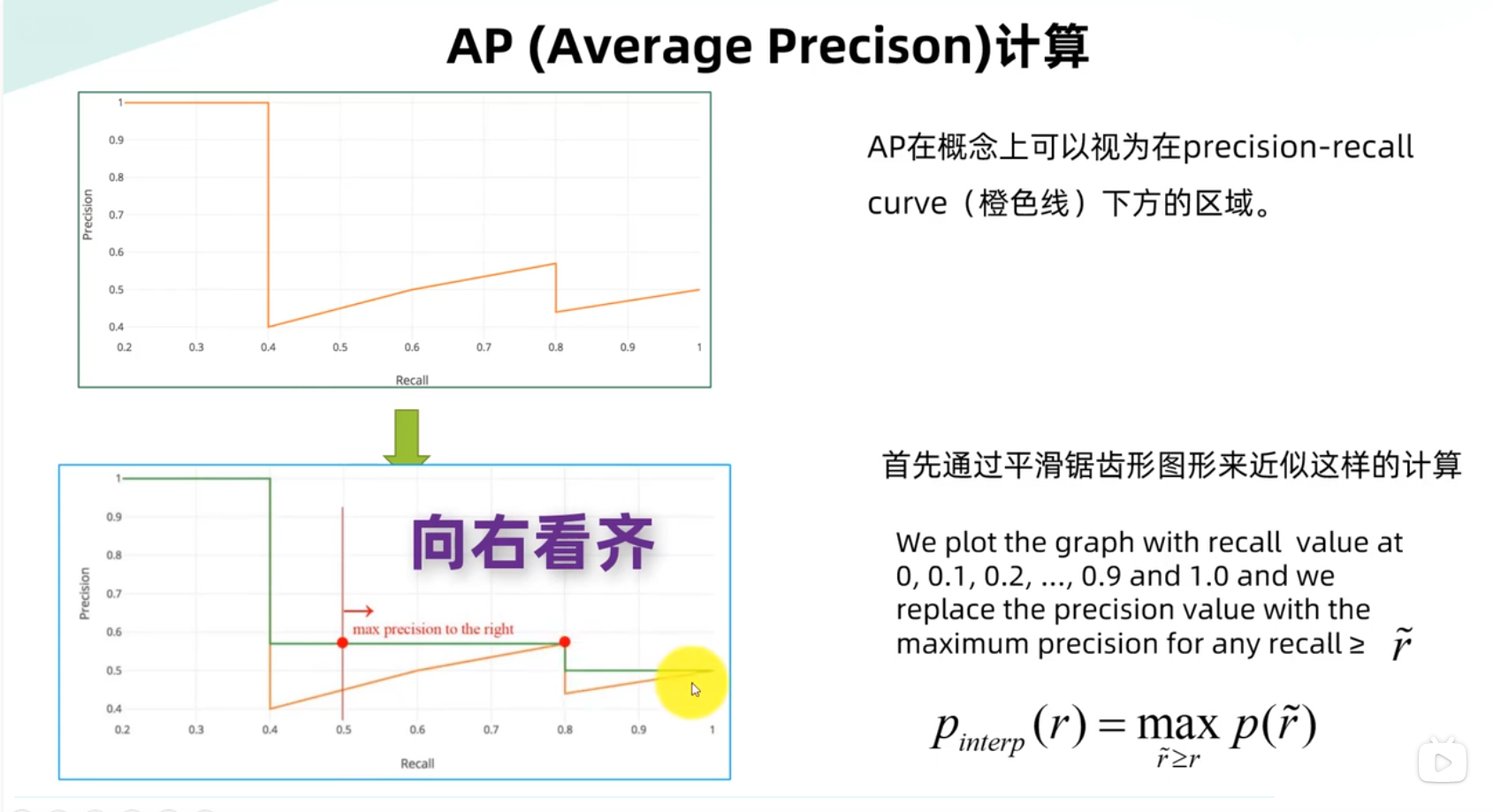
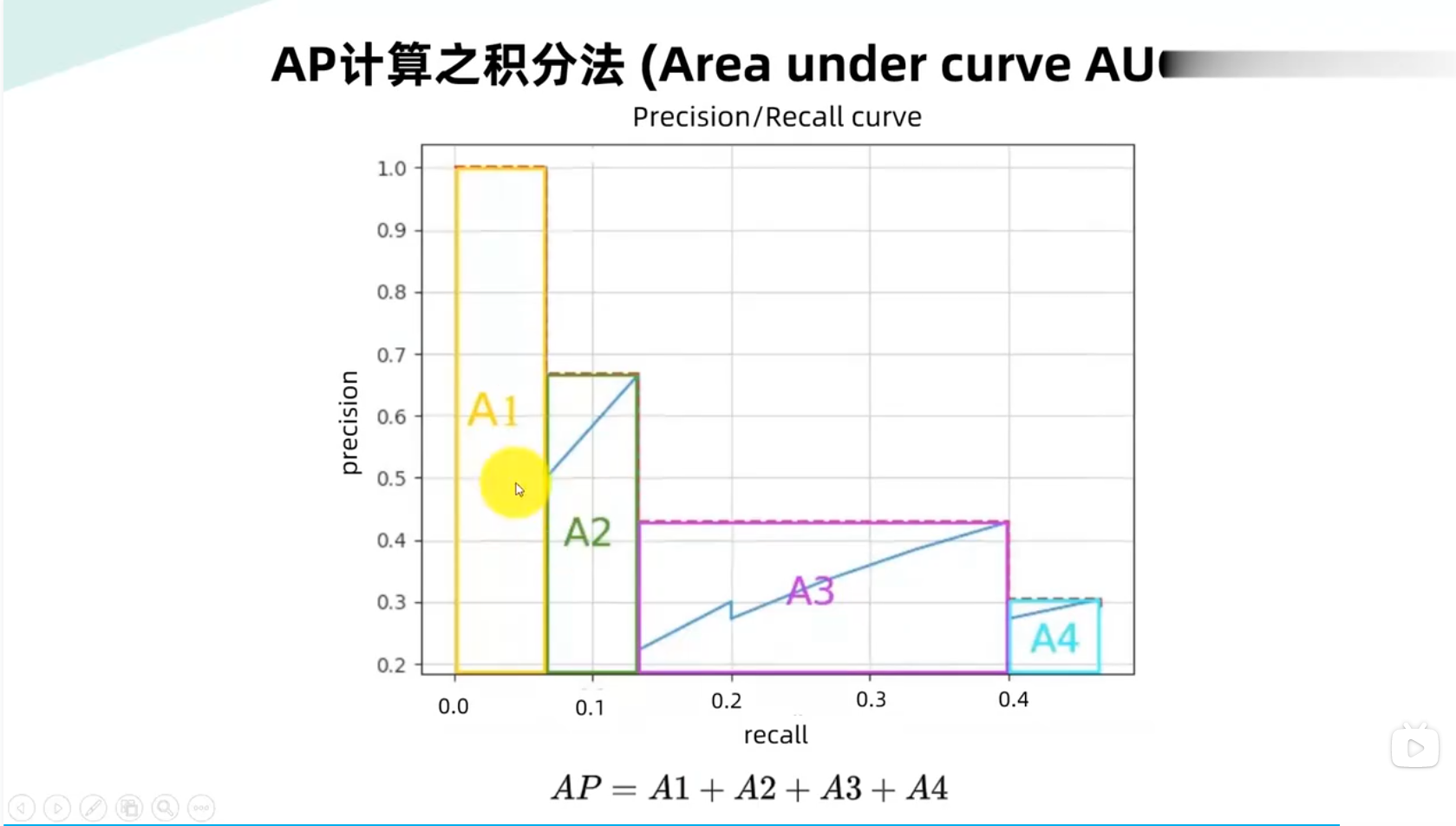
AP,MAP
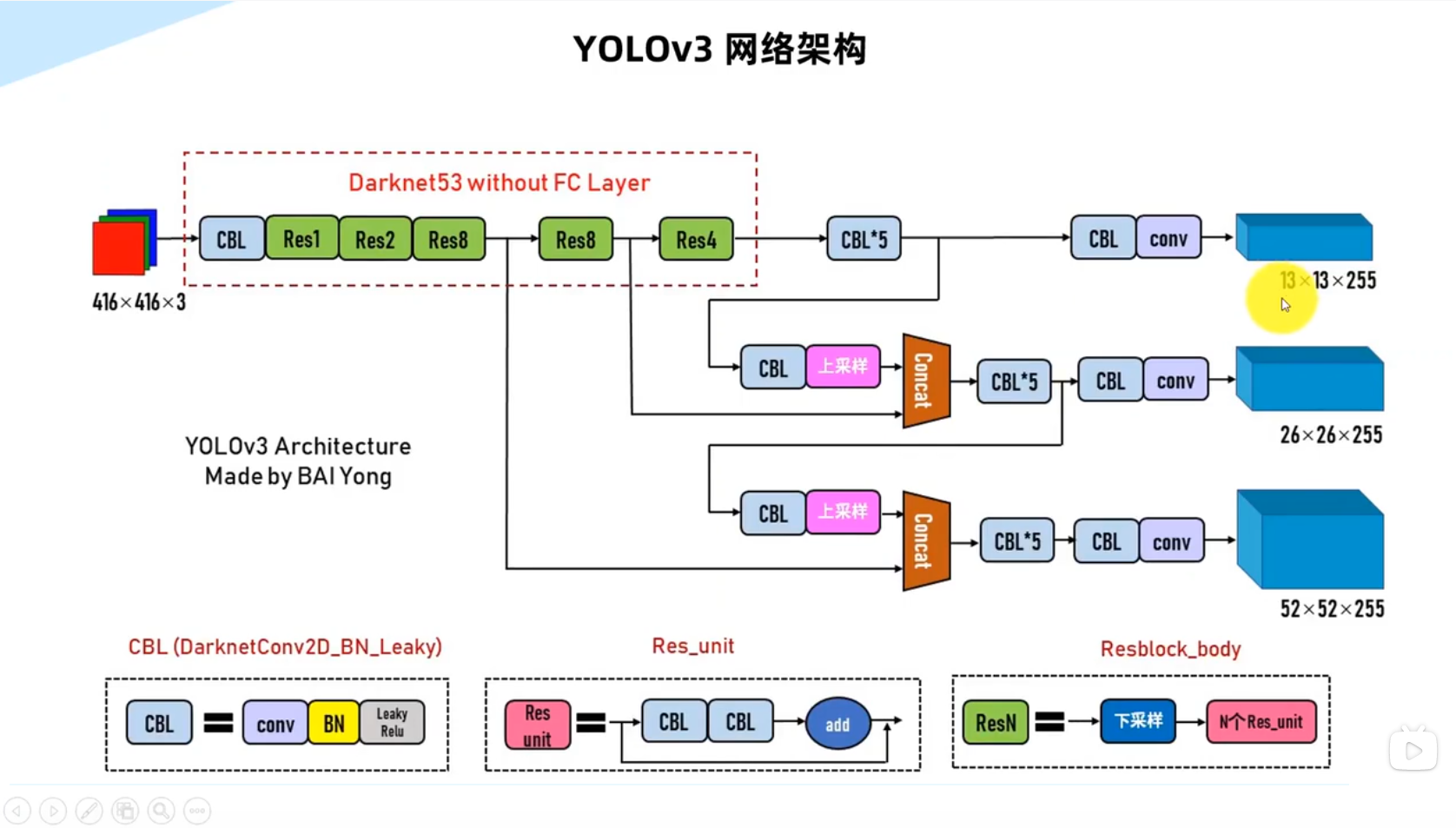
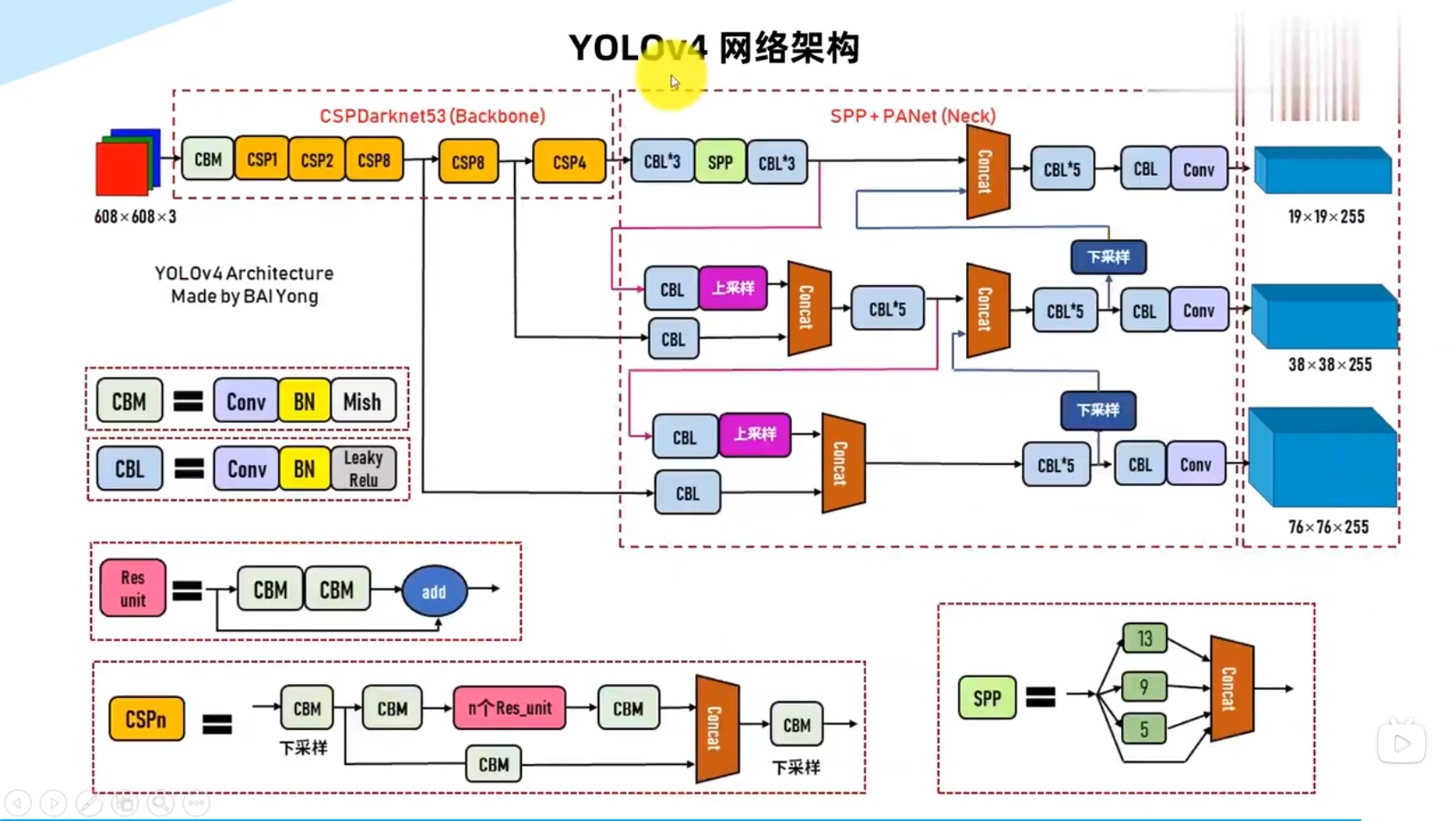
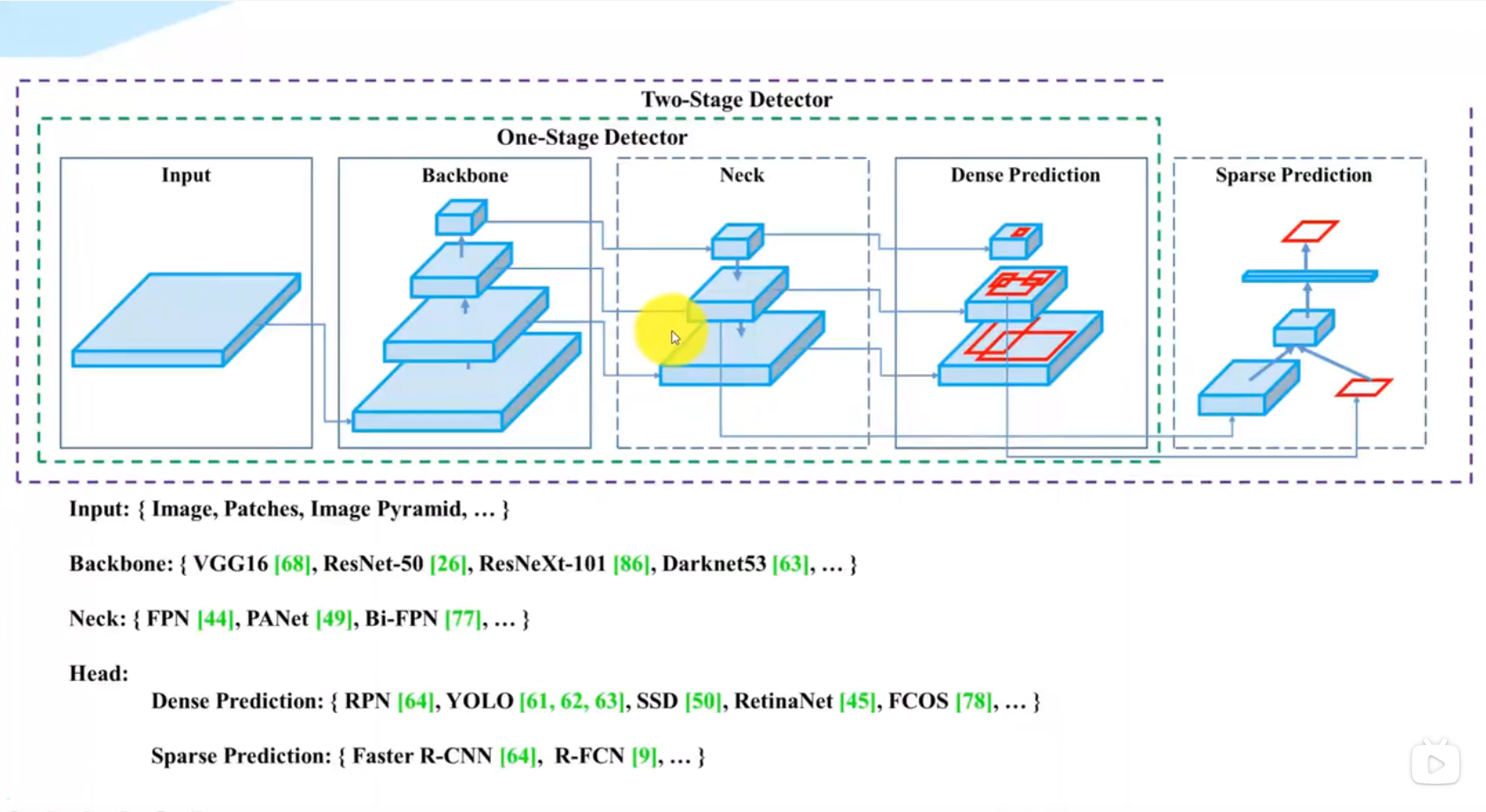
网络架构和组件
单阶段检测器:
yolov5:(没有划出专门的颈部Neck)

git clone https://github.moeyy.xyz/https://github.com/ultralytics/yolov5.git
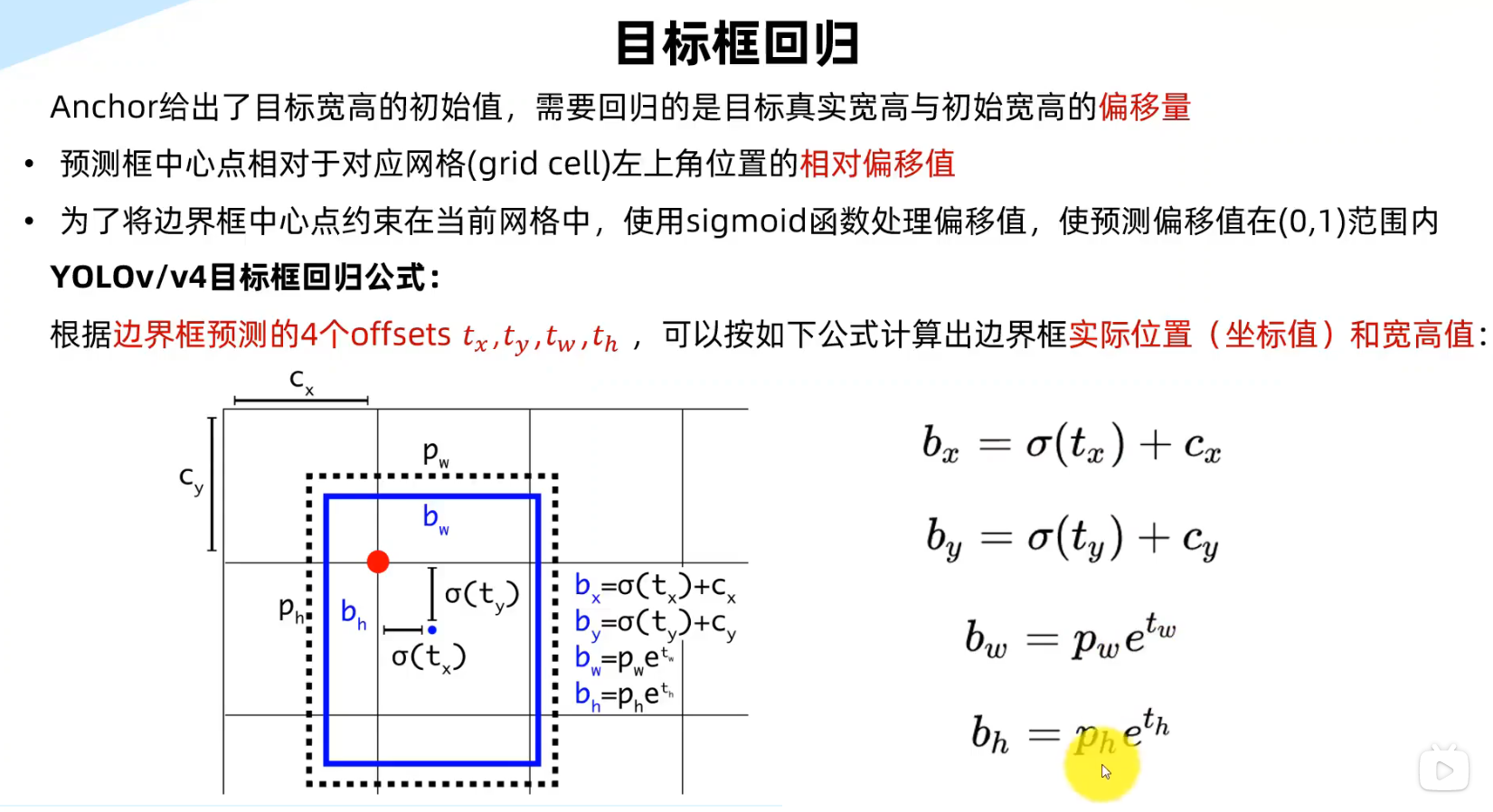
nc: 80:这个参数表示模型分类数量(number of classes),默认为 80,对应着 COCO 数据集。depth_multiple: 0.33:这个参数表示模型深度相对于基础版本的倍数。在 YOLOv5 中,有 S、M、L 和 X 四个版本,其中 S 为基础版本,即depth_multiple: 1.0,而 M、L 和 X 版本为在此基础上分别加深了一定的层数。而depth_multiple: 0.33表示在 S 版本的基础上,深度缩小了 3 倍,即变成了depth_multiple: 0.33× 3 = 0.99。width_multiple: 0.50:这个参数表示模型通道宽度相对于基础版本的倍数。与depth_multiple类似,S 版本的width_multiple是 1.0,而 M、L 和 X 版本则在此基础上分别扩大了一定的倍数。anchors:这是一个锚点数组,用于定义不同尺度下的 anchor boxes。YOLOv5 中使用了三个不同的尺度,每个尺度使用三个不同的 anchor boxes。这些锚点大小是相对于输入图像的,因此不同尺度下的大小会有所差别。backbone:这一部分定义了模型的骨干网络(backbone),包括卷积层、批归一化层和激活函数等。YOLOv5 使用了 CSPDarknet53 这个网络作为基础骨干网络,并在此基础上进行改进。具体而言,YOLOv5 增加了空间注意力机制和SPP模块,以增强特征表达能力。head:这一部分定义了模型的检测头(detection head),包括检测网络和分类网络。YOLOv5 中的检测网络采用了YOLOv3中的FPN结构,并在此基础上加入了PANet模块和SAM模块,以提高检测性能。
序列数据的不同采样方法(随机采样和顺序分区)会导致隐状态初始化的差异,原因如下:
- 随机采样: 在随机采样中,我们从序列数据中随机选择一个序列作为训练样本。这意味着每次训练时,我们都使用不同的序列作为输入。由于每个序列可能具有不同的上下文和语义信息,模型在每次训练时都需要重新适应不同的序列特征。因此,随机采样会导致隐状态的初始化与之前的训练批次存在一定差异。
- 顺序分区: 在顺序分区中,我们按顺序依次读取序列数据进行训练。这意味着模型在每个训练批次中都会接收到相邻的序列数据。由于相邻的序列通常具有相似的上下文和语义信息,模型可以利用之前批次的隐藏状态来帮助理解当前批次的序列。因此,顺序分区会导致隐状态的初始化与之前的训练批次存在一定的相关性。
不同的隐状态初始化差异可能会对模型的训练和预测产生影响。随机采样可以增加数据的多样性,帮助模型更好地适应不同的序列特征。然而,随机采样可能也会引入一些噪声,导致训练过程更加不稳定。顺序分区可以利用相邻序列之间的相关性,帮助模型更好地捕捉到序列的上下文信息。然而,顺序分区可能会限制模型对不同序列特征的适应能力。
困惑度(perplexity)是自然语言处理中常用的一个评价指标,主要用于衡量语言模型的预测性能。困惑度越低,表示模型的预测能力越好。
在自然语言处理中,我们通常使用语言模型来计算文本序列的概率。给定一个文本序列 $W=w_1,w_2,…,w_n$,其概率可以表示为:
$$
P(W)=P(w_1)\times P(w_2|w_1) \times … \times P(w_n|w_1,w_2,…,w_{n-1})
$$
其中,$P(w_i|w_1,w_2,…,w_{i-1})$ 表示在已知前面 $i-1$ 个词的情况下,第 $i$ 个词的概率。语言模型的目标就是学习这种条件概率分布。在模型训练过程中,我们通常会使用最大似然估计法来估计模型参数。
困惑度是一个数值指标,表示用当前语言模型对一个测试集进行预测时所得到的困惑程度。具体而言,如果测试集包含 $N$ 个词,我们可以计算出每个词的概率 $P(w_i)$,然后将这些概率求倒数并取对数,即:
$$
\log \frac{1}{P(w_1)}+\log \frac{1}{P(w_2|w_1)}+…+\log \frac{1}{P(w_N|w_1,w_2,…,w_{N-1})}
$$
然后,我们可以将上述结果除以测试集中的词数 $N$,得到平均困惑度。具体而言,平均困惑度的计算公式如下:
$$
\text{Perplexity}=exp\left(-\frac{1}{N}\sum_{i=1}^{N}\log P(w_i)\right)
$$
例如,如果我们有一个包含100个句子的测试集,其中总共包含1000个词,我们可以使用语言模型来预测每个词的概率,并计算出平均困惑度。假设我们的模型预测准确率较高,平均每个词的概率为0.9,则平均困惑度为:
$$
exp\left(-\frac{1}{1000}\sum_{i=1}^{1000}\log 0.9\right) \approx 2.15
$$
这表示我们的模型对测试集中的文本序列进行预测时,每个词的平均困惑度为2.15。如果我们使用一个更好的语言模型,其困惑度可能会更低。
用困惑度来评价模型确保了不同长度的序列具有可比性
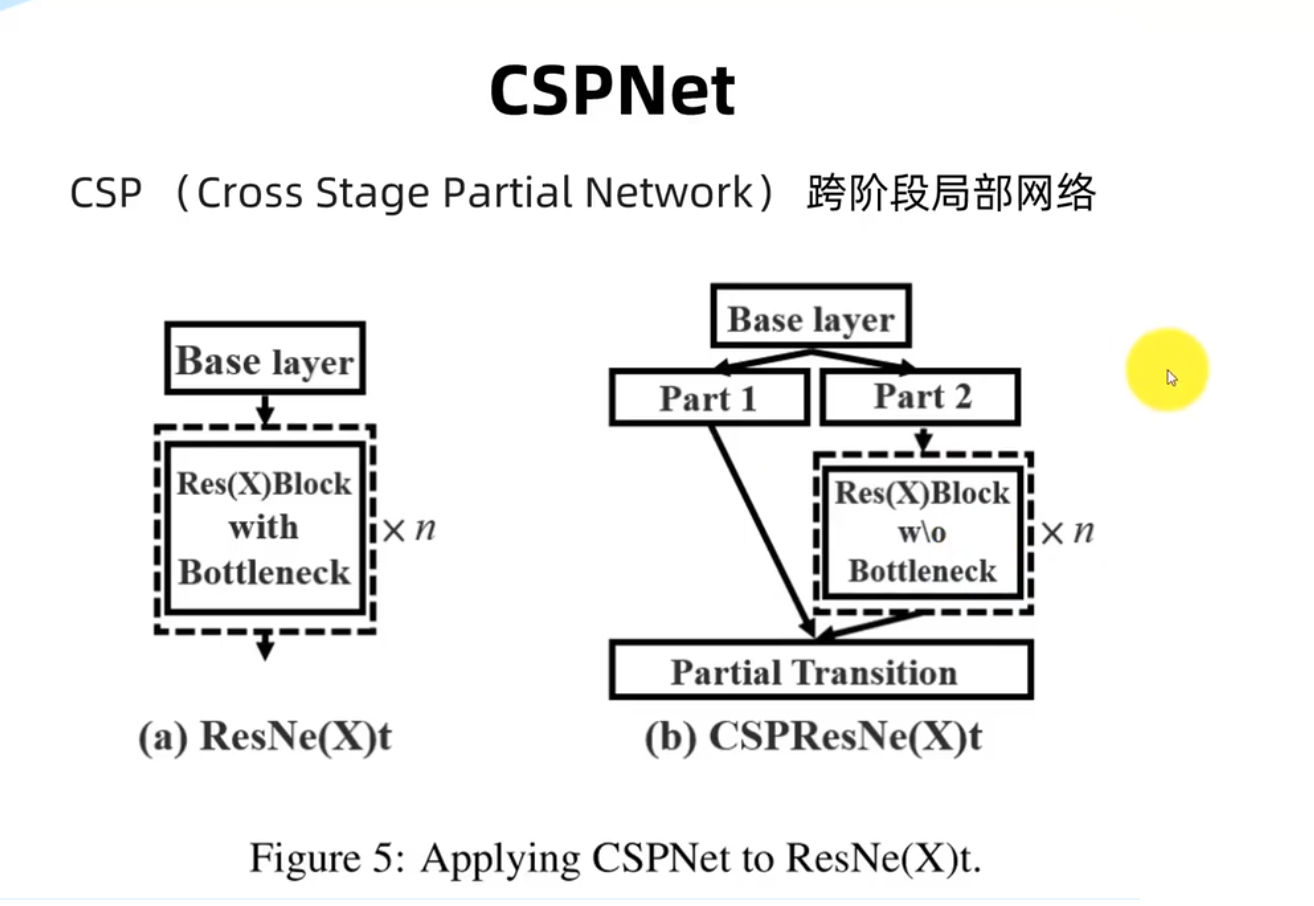
路径聚合网络模块
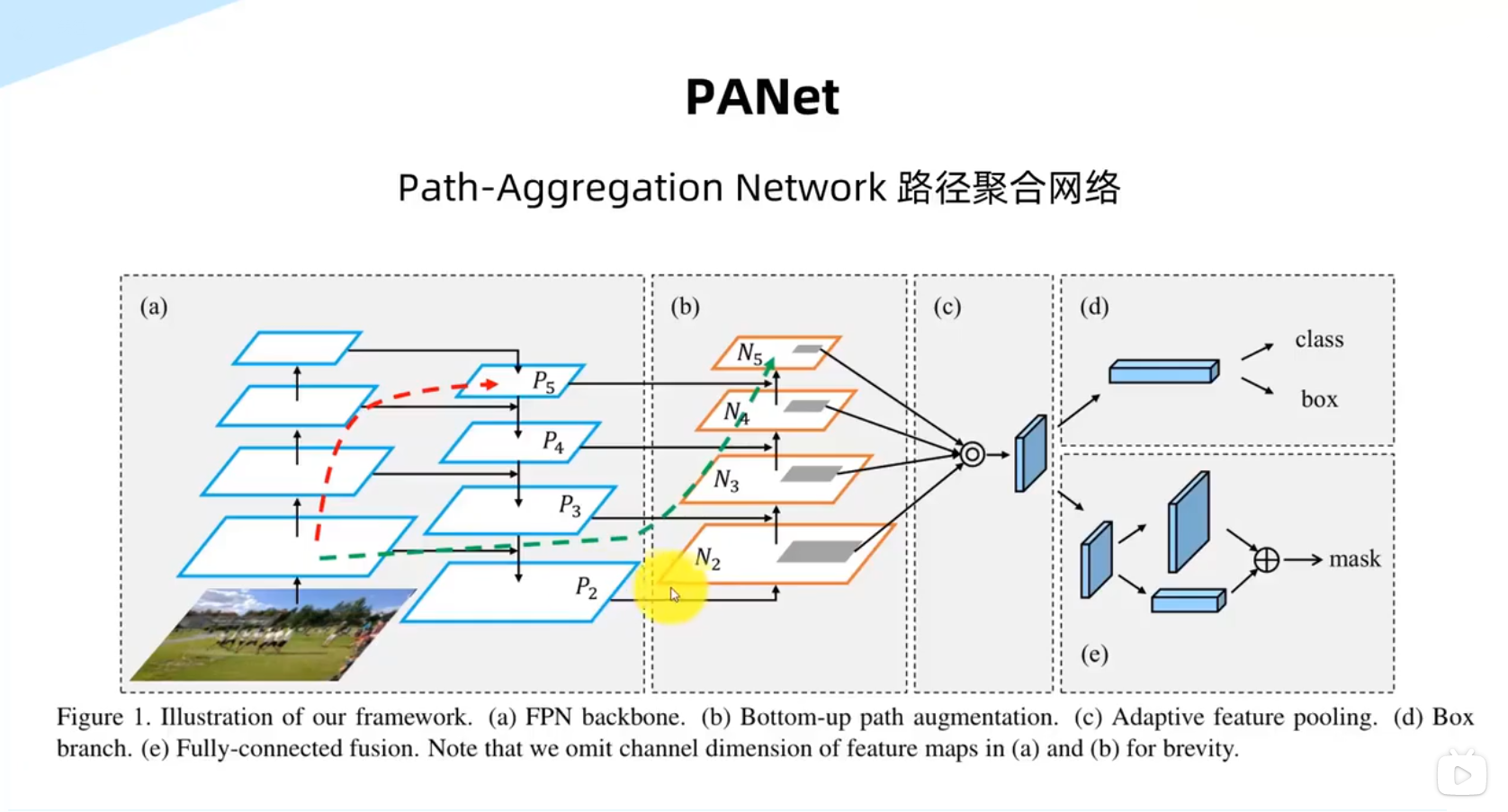
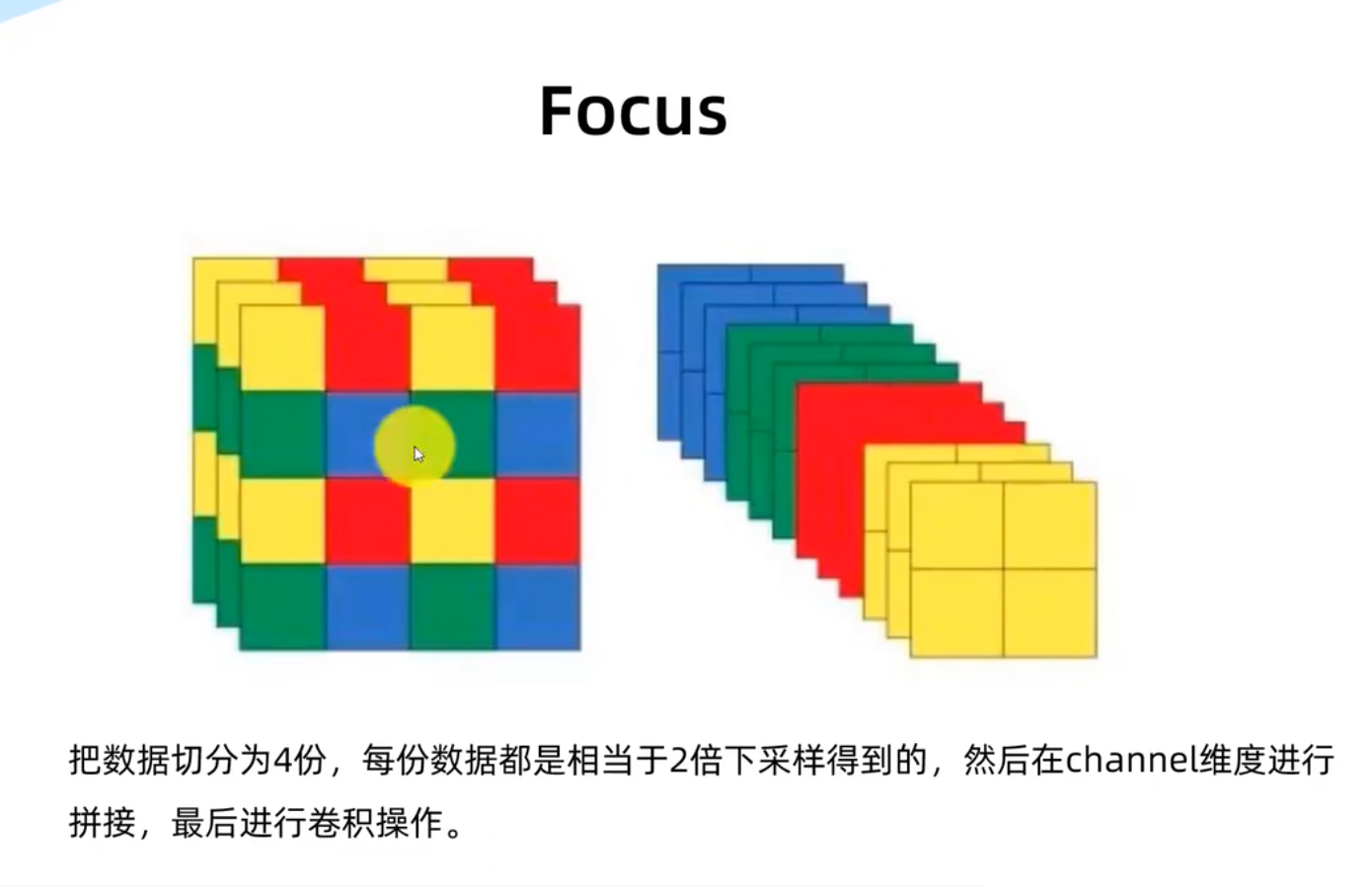
Focus处理模块
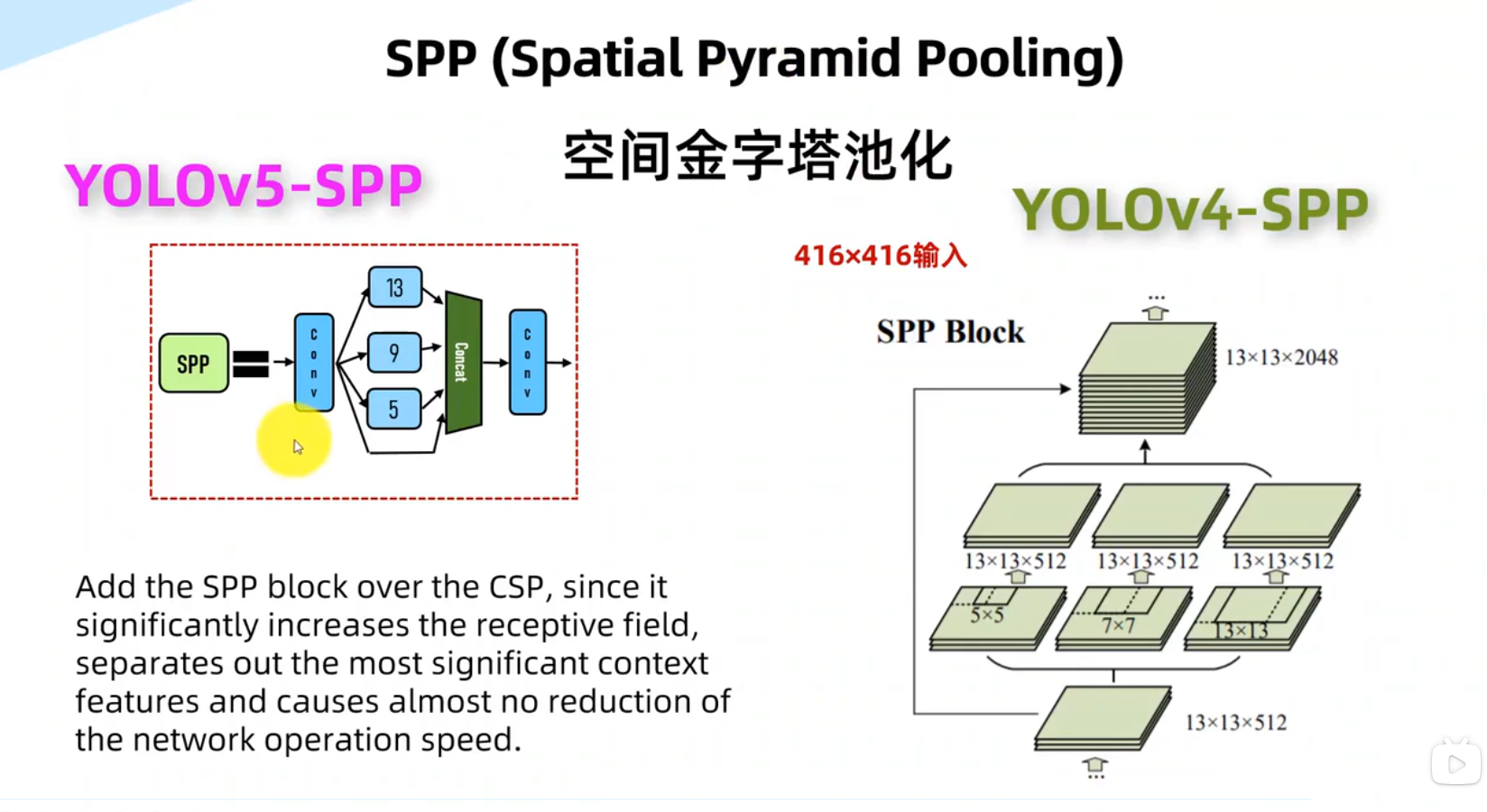
空间金字塔池化模块
跨阶段局部网络模块

IoU、GIoU、DIoU、CIoU损失函数
IoU、GIoU、DIoU、CIoU损失函数
目标检测任务的损失函数由Classificition Loss和Bounding Box Regeression Loss两部分构成。目标检测任务中近几年来Bounding Box Regression Loss Function的演进过程,其演进路线是

一、IOU(Intersection over Union)
1. 特性(优点)
IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchor-based的方法。作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。
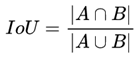
\1. 可以说它可以反映预测检测框与真实检测框的检测效果。
\2. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。**(**满足非负性;同一性;对称性;三角不等性)

2. 作为损失函数会出现的问题(缺点)
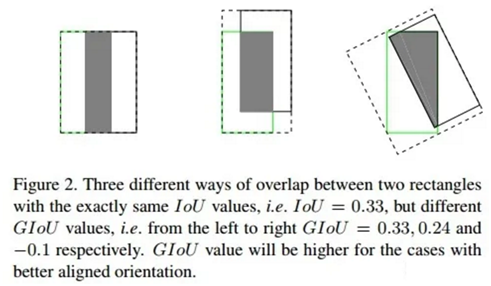
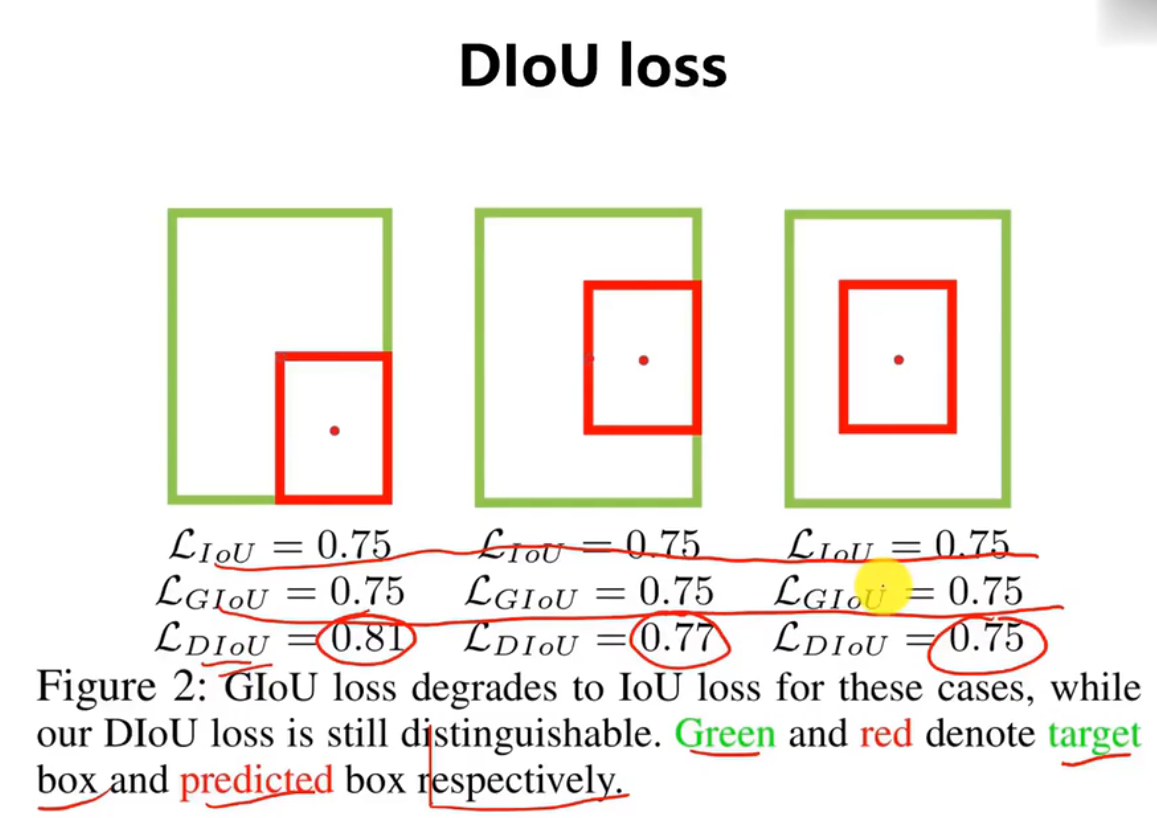
\1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
\2. IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
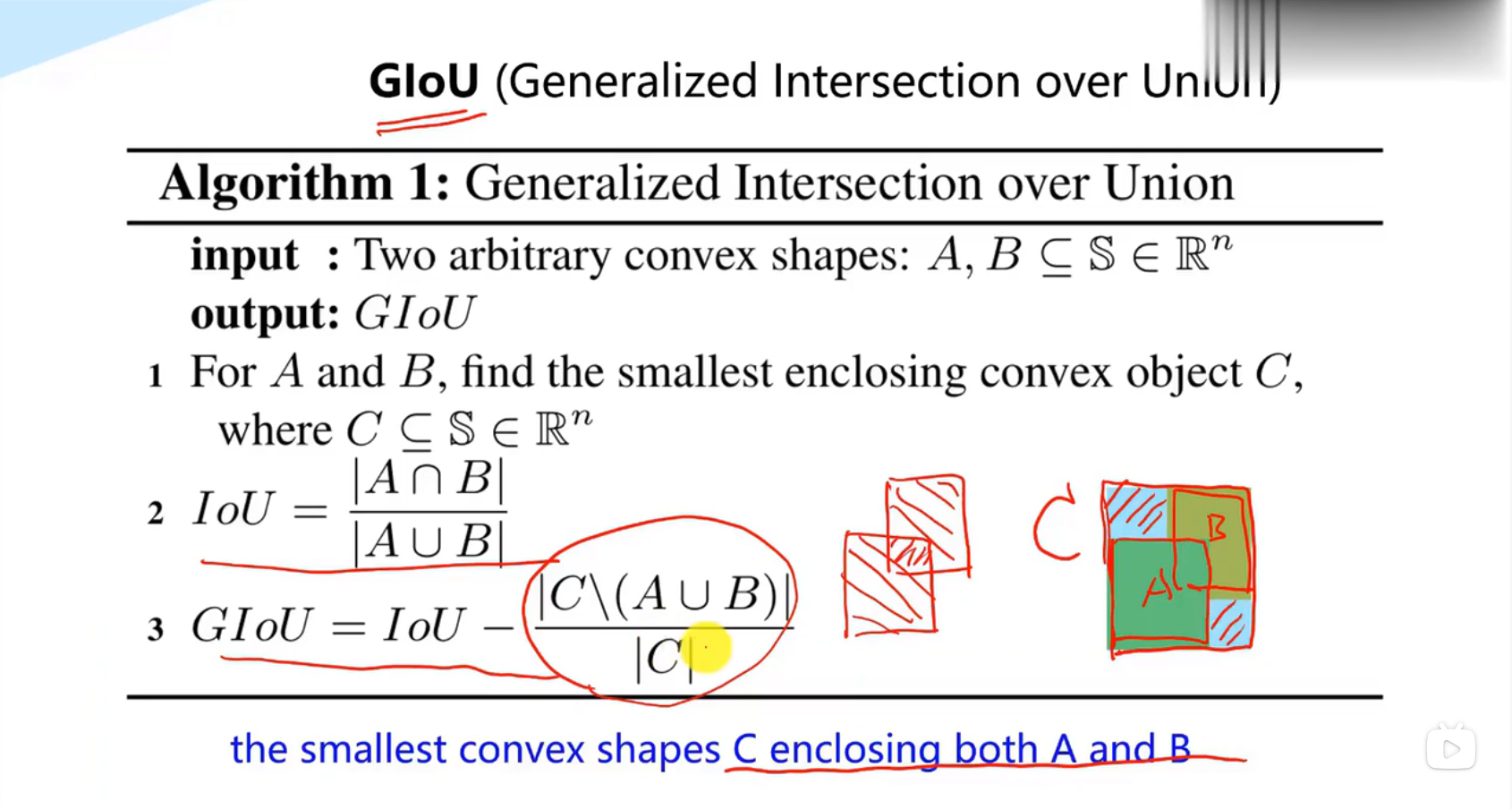
二、GIOU(Generalized Intersection over Union)
1****、来源
在CVPR2019中,论文
《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》
https:arxiv.org/abs/1902.09630
提出了GIoU的思想。由于IoU是比值的概念,对目标物体的scale是不敏感的。然而检测任务中的BBox的回归损失(MSE loss, l1-smooth loss等)优化和IoU优化不是完全等价的,而且 Ln 范数对物体的scale也比较敏感,IoU无法直接优化没有重叠的部分。

这篇论文提出可以直接把IoU设为回归的loss。
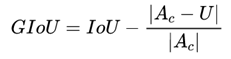
上面公式的意思是:先计算两个框的最小闭包区域面积_ _(通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
附:https://github.com/generalized-iou/g-darknet
2****、 特性[1]
与IoU相似,GIoU也是一种距离度量,作为损失函数的话, ,满足损失函数的基本要求
GIoU对scale不敏感
GIoU是IoU的下界,在两个框无线重合的情况下,IoU=GIoU
IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
与IoU只关注重叠区域不同,GIoU****不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。


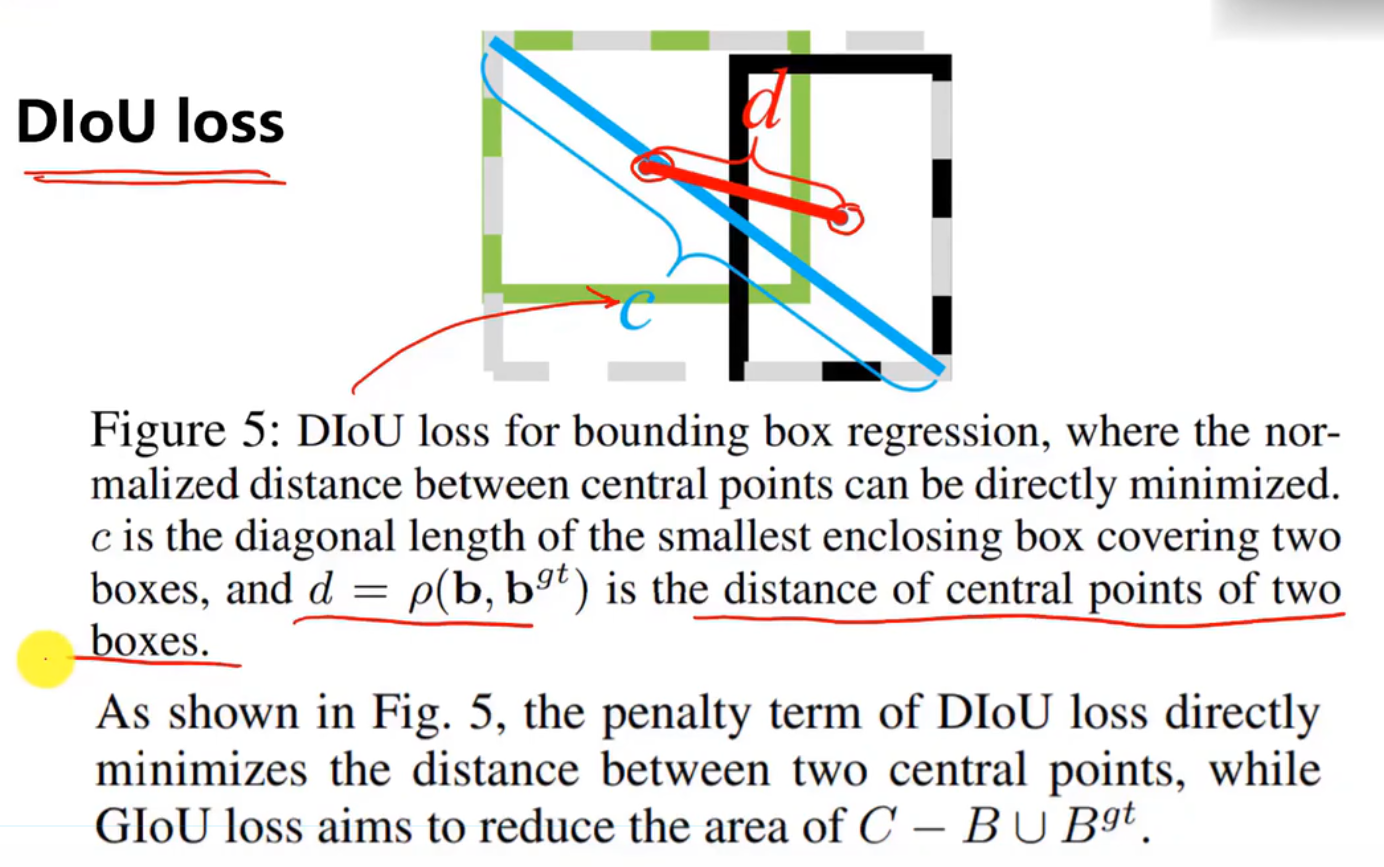
三、DIoU(Distance-IoU)[2]
**1,**来源
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。论文中
Distance-IoU
https://arxiv.org/pdf/1911.08287.pdf
基于IoU和GIoU存在的问题,作者提出了两个问题:
\1. 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度?
\2. 如何使回归在与目标框有重叠甚至包含时更准确、更快?
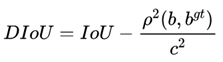
其中,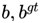 分别代表了预测框和真实框的中心点,
分别代表了预测框和真实框的中心点,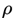 且代表的是计算两个中心点间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
且代表的是计算两个中心点间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。

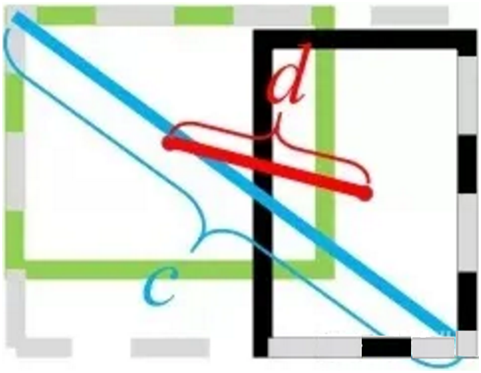
DIoU中对anchor框和目标框之间的归一化距离进行了建模
附:
YOLOV3 DIoU GitHub项目地址
https//github.com/Zzh-tju/DIoU-darknet
2****、优点
与GIoU loss类似,DIoU loss( )在与目标框不重叠时,仍然可以为边界框提供移动方向。
DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
实现代码:[3]


四、CIoU(Complete-IoU)
论文考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:

实现代码:[5]




L(IoU)=1-IoU,L(GIoU)=1-GIoU
penalty item 惩罚项




用1替换
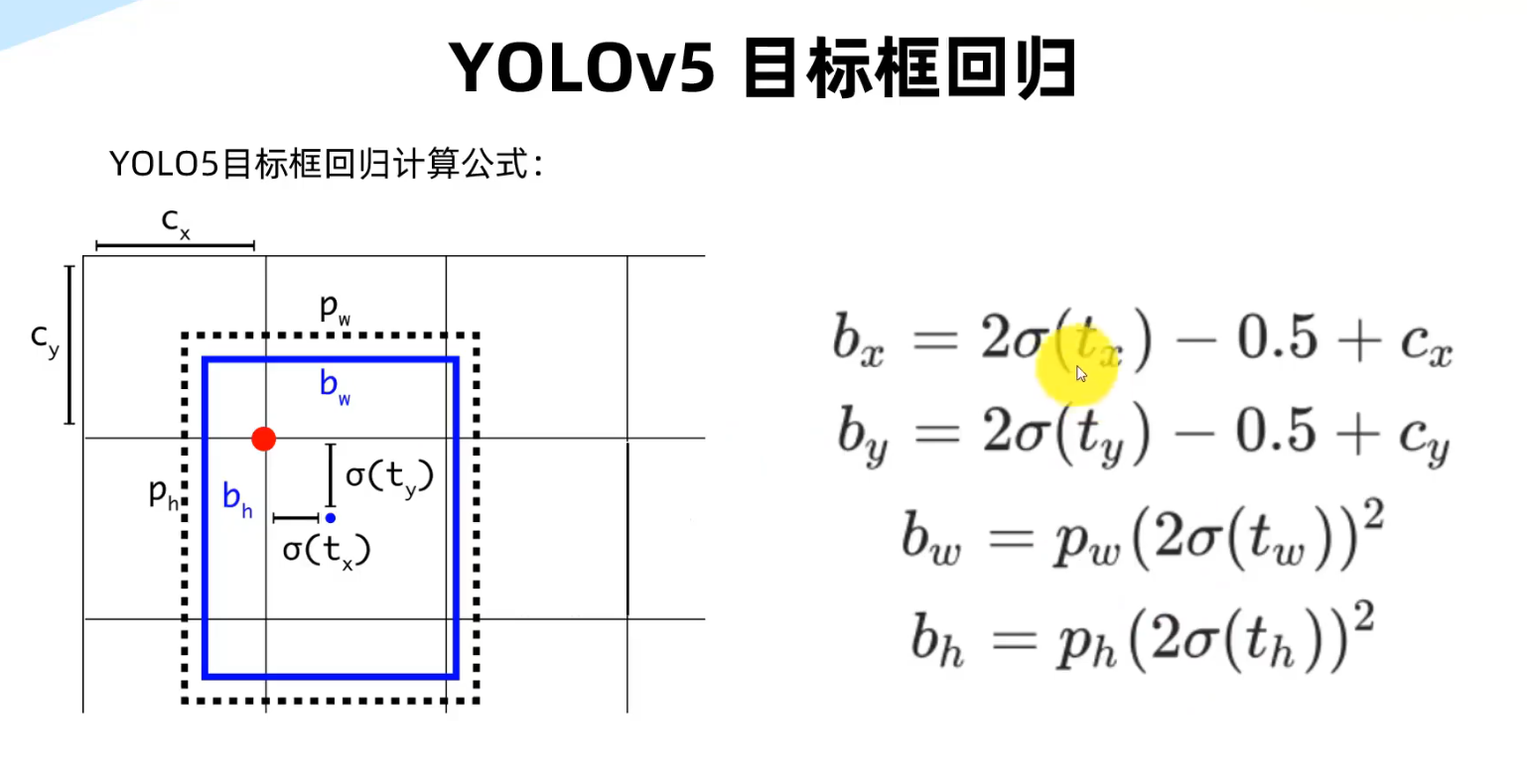
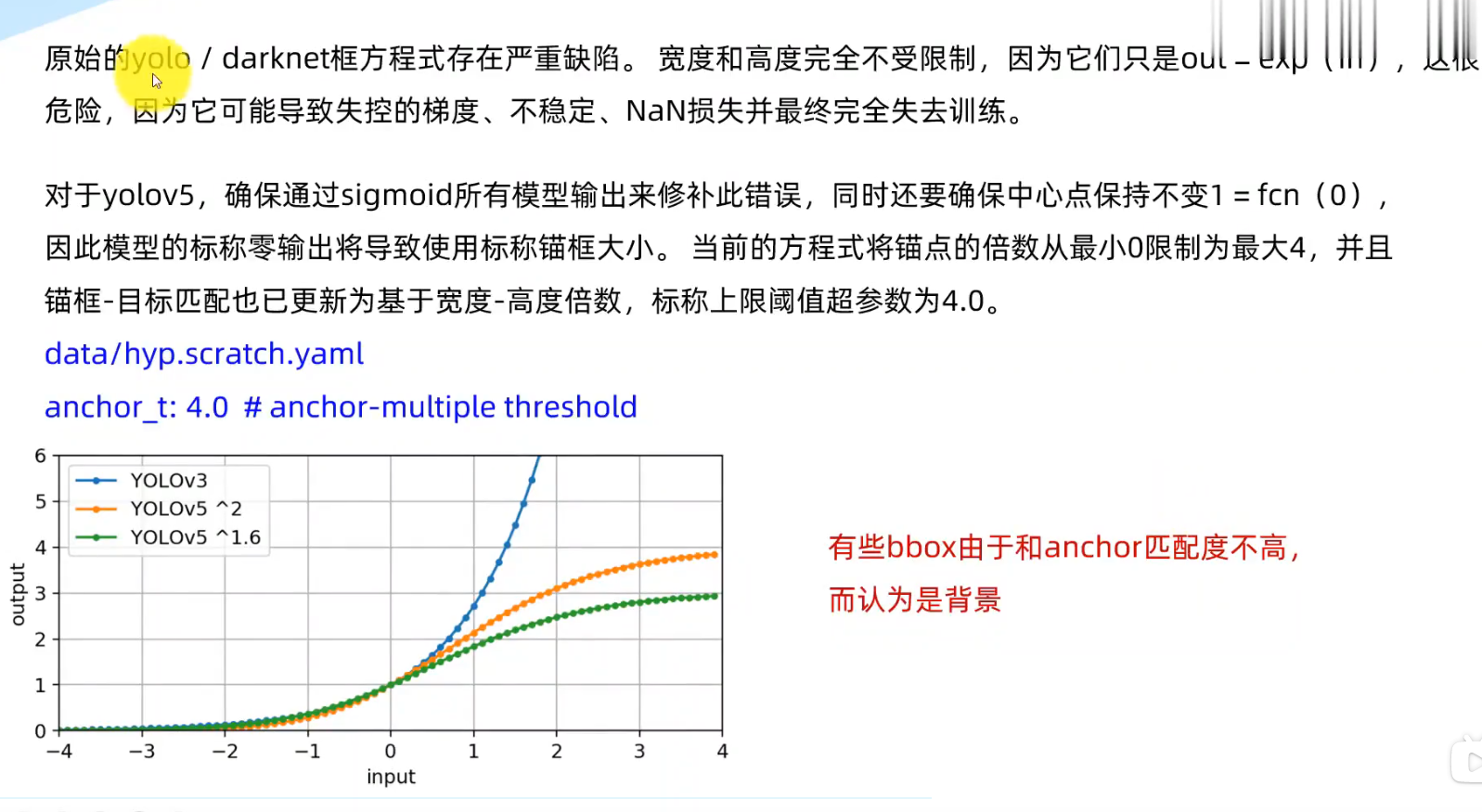
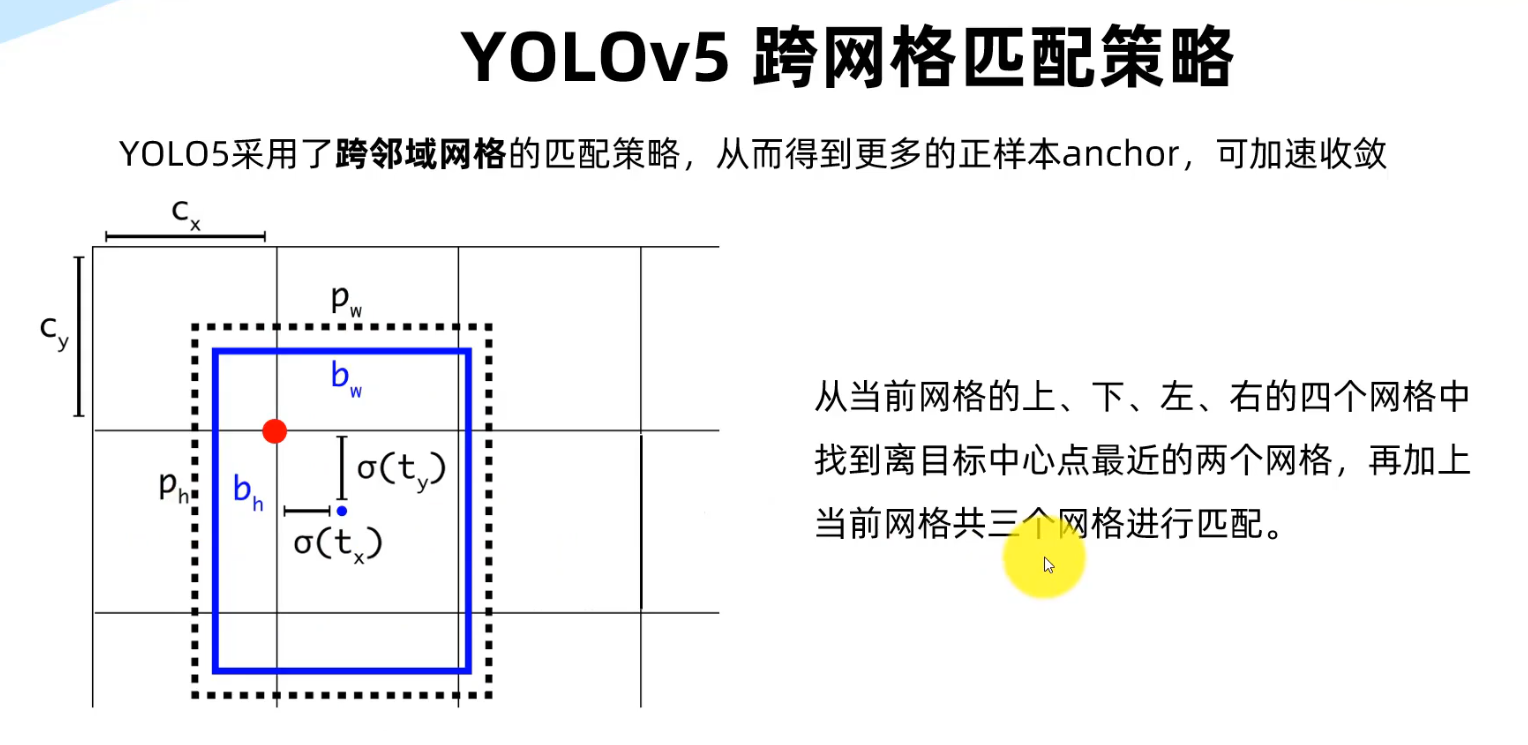
YOLO训练技巧
1.

2.
 余弦退火学习率调整的原理是根据余弦函数的形状动态地调整学习率。它通过将学习率从一个较大的初始值逐渐减小到一个较小的最小值来控制训练过程中的学习率变化。
余弦退火学习率调整的原理是根据余弦函数的形状动态地调整学习率。它通过将学习率从一个较大的初始值逐渐减小到一个较小的最小值来控制训练过程中的学习率变化。
具体实现步骤如下:
- 设置一个最大学习率和最小学习率的范围。
- 定义一个周期数(通常是训练的总迭代次数)。
- 对于每个训练迭代,计算当前周期数与总周期数之间的比例。
- 使用余弦函数来动态计算学习率,公式如下:
lr = lr_min + 0.5 * (lr_max - lr_min) * (1 + cos(epoch / T_total * pi))其中,lr表示当前学习率,epoch表示当前周期数,T_total表示总周期数,lr_max表示最大学习率,lr_min表示最小学习率。
- 将计算得到的学习率应用于优化器中进行权重更新。
使用余弦退火学习率调整可以在训练初期使用较大的学习率来快速收敛,然后逐渐减小学习率以细化模型的优化过程。这种方法在训练中期能够跳出局部最优解并找到更好的全局最优解,有助于提高模型的泛化性能和训练效果。
3.

4.

5.遗传算法
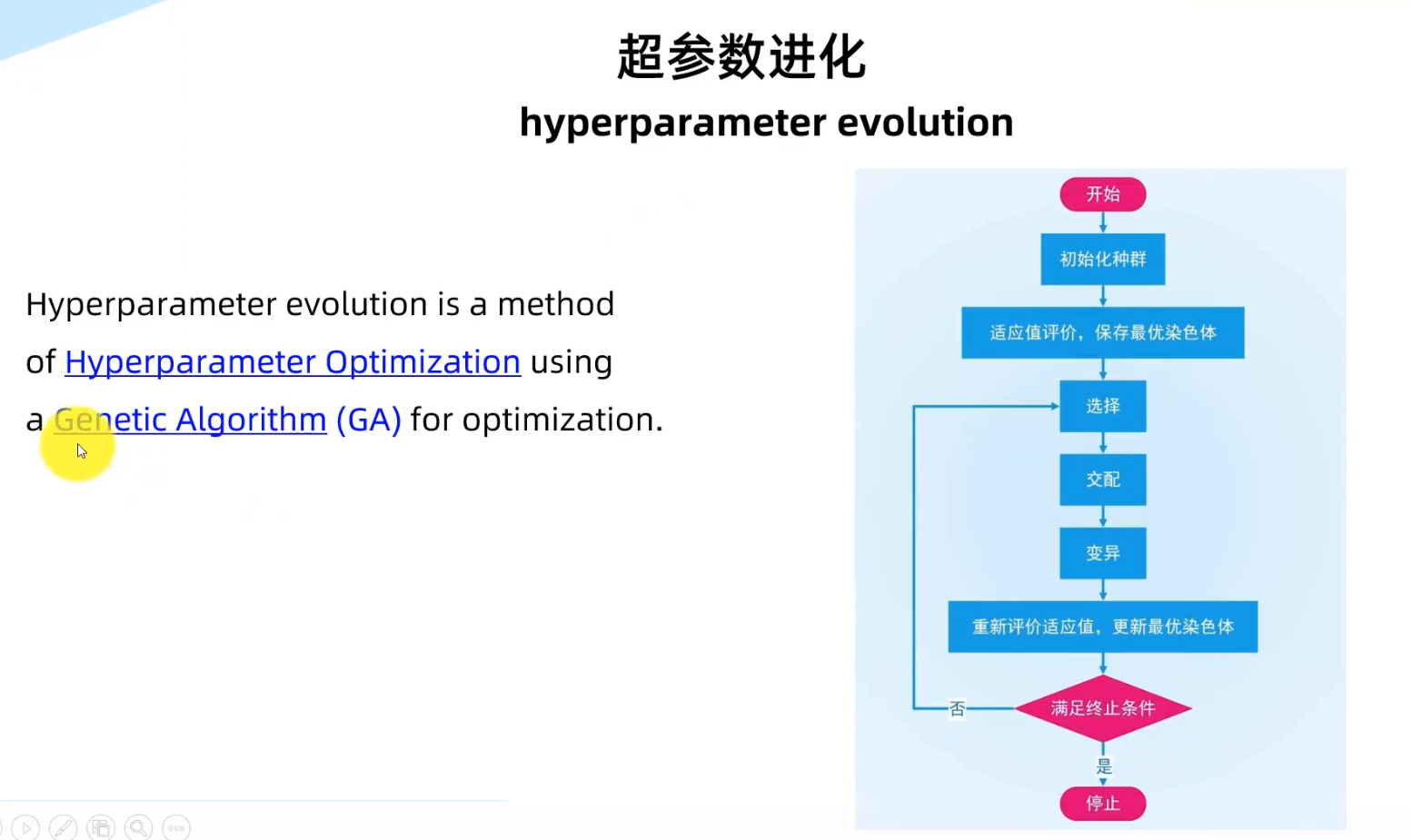
6.AMP

 7.
7.

激活函数
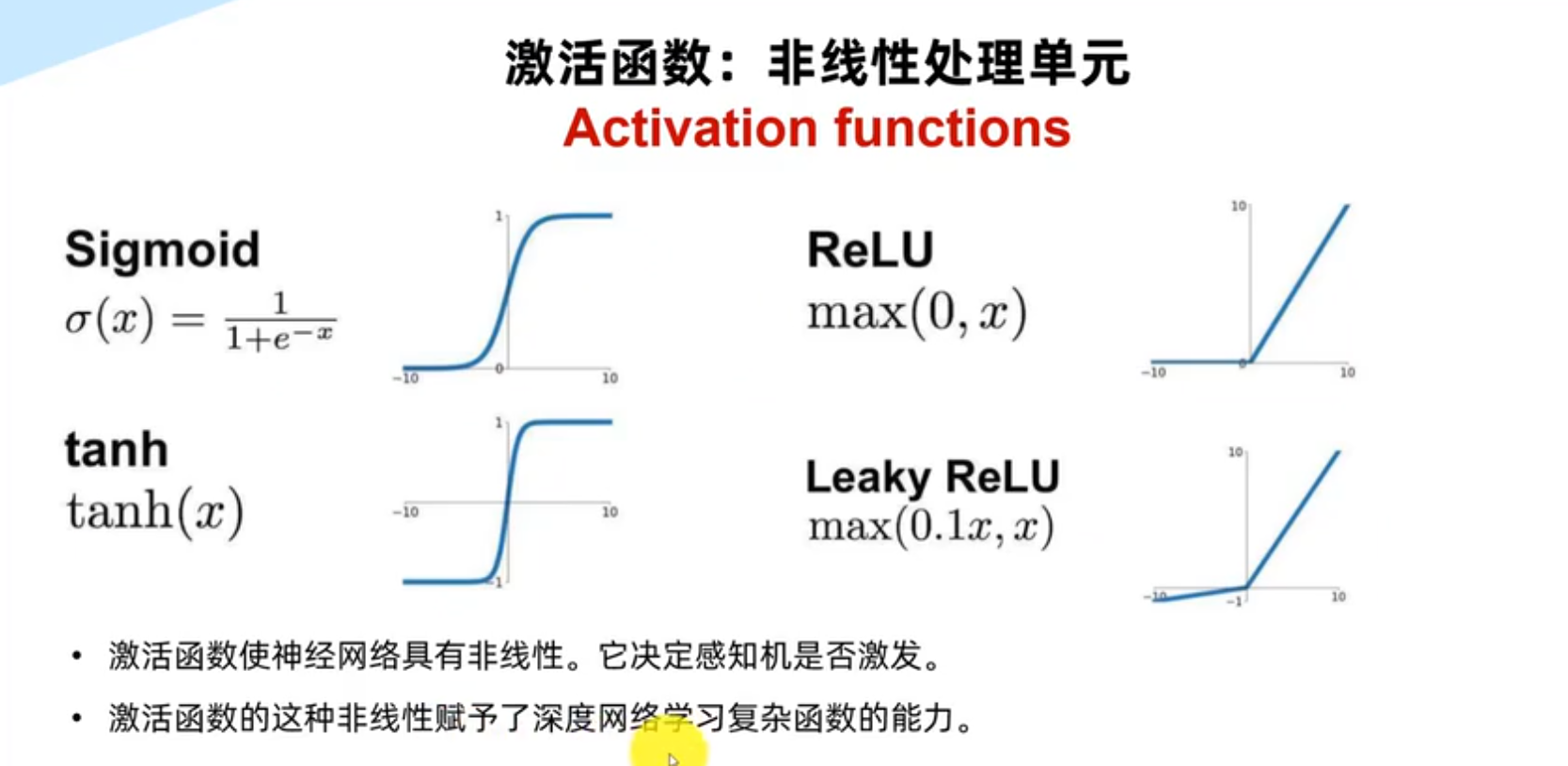
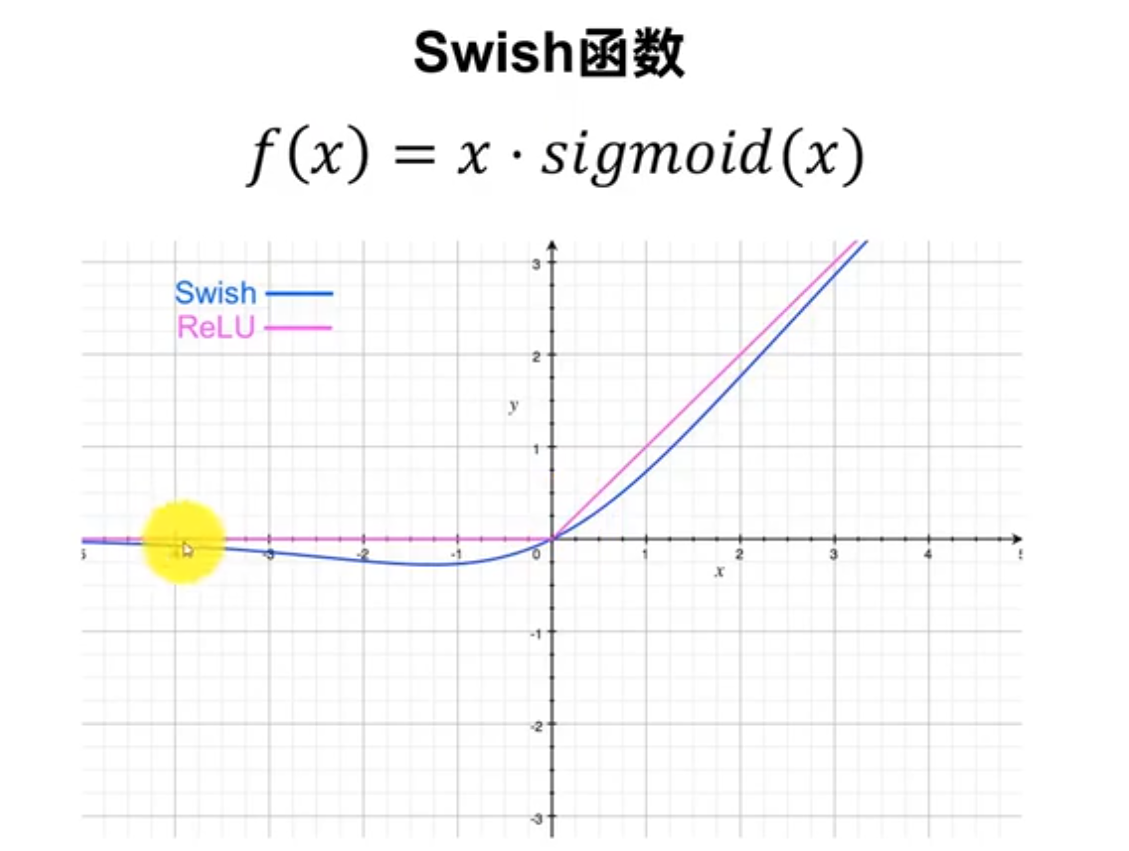
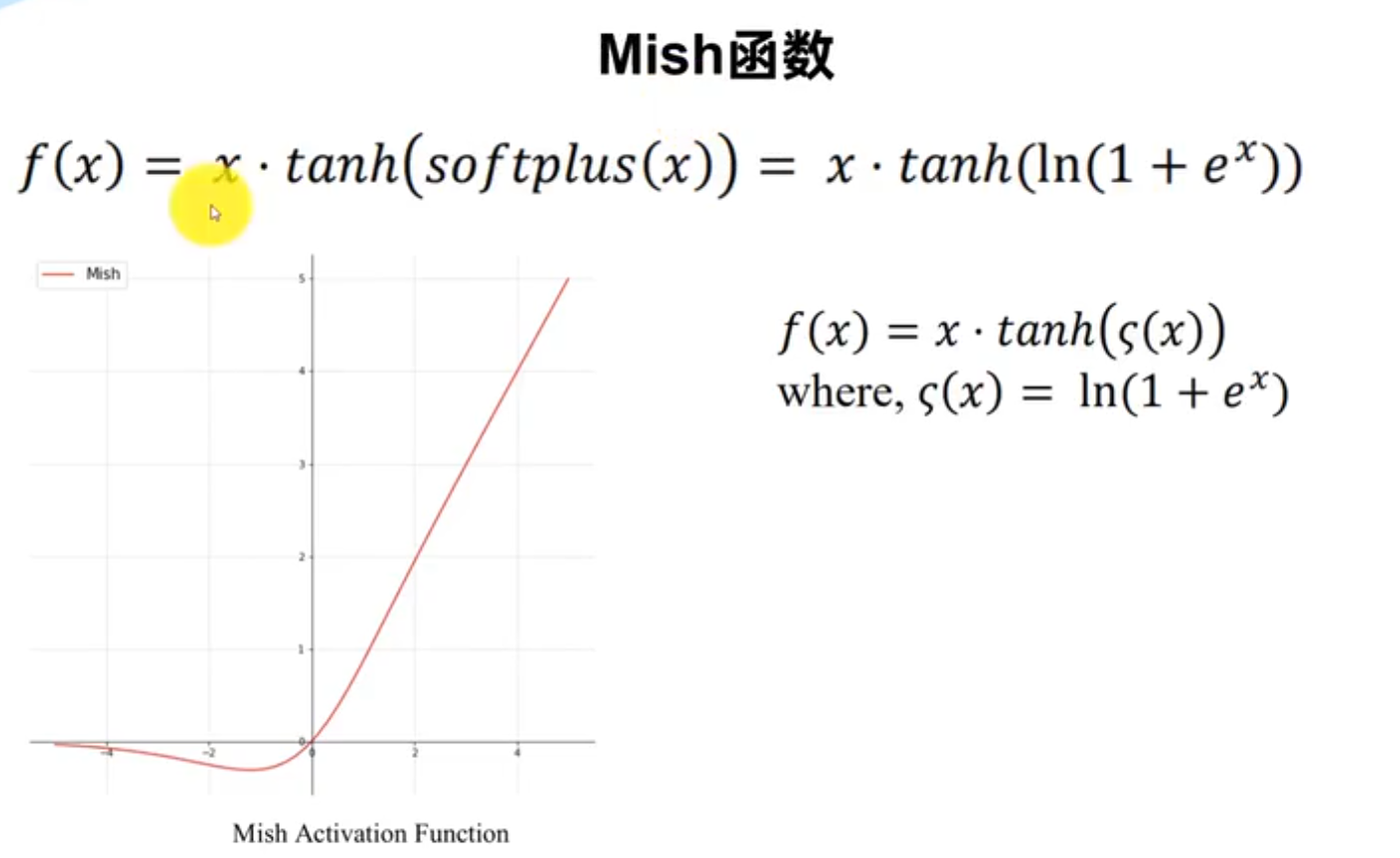

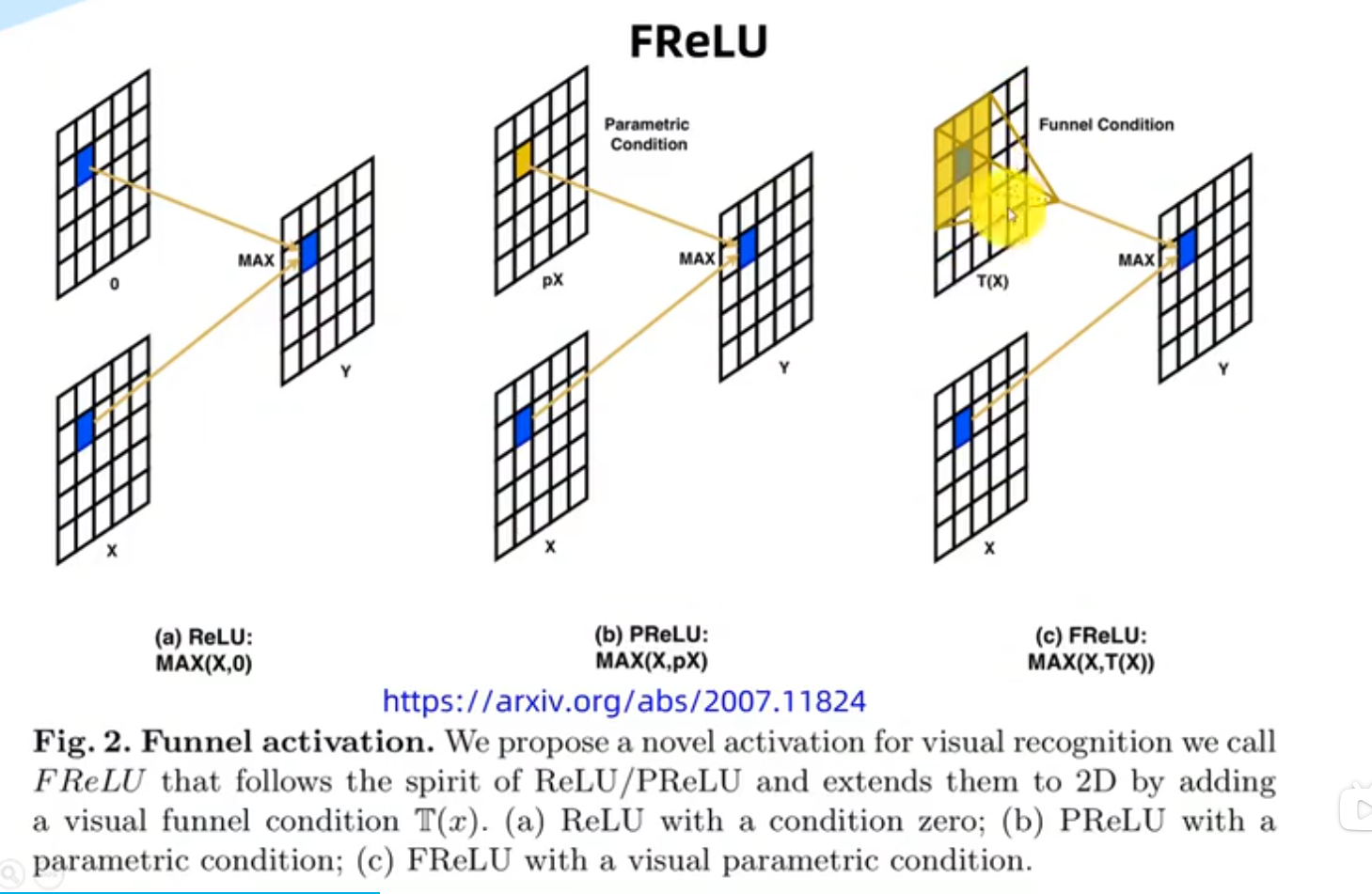
 优点:激活区域可以更多样
优点:激活区域可以更多样
因此,引入了各种方法来压缩神经网络,以使大型模型可以在边缘设备上部署。模型压缩方法可以分为3类:剪枝、量化和知识蒸馏。在剪枝中,移除模型中不重要的冗余参数,以获得稀疏/紧凑的模型结构。量化涉及使用低精度数据类型表示模型的激活和权重。最后,知识蒸馏是指利用大型准确模型作为教师来训练一个小型模型,使用教师模型提供的软标签来进行训练。
cmake_minimum_required(VERSION 3.10) project(yolov5) add_definitions(-std=c++11) add_definitions(-DAPI_EXPORTS) option(CUDA_USE_STATIC_CUDA_RUNTIME OFF) set(CMAKE_CXX_STANDARD 11) set(CMAKE_BUILD_TYPE Debug) # TODO(Call for PR): make cmake compatible with Windows set(CMAKE_CUDA_COMPILER /usr/local/cuda-12.2/bin/nvcc) enable_language(CUDA) # include and link dirs of cuda and tensorrt, you need adapt them if yours are different # cuda include_directories(/usr/local/cuda-12.2/include) link_directories(/usr/local/cuda-12.2/lib64) # tensorrt # TODO(Call for PR): make TRT path configurable from command line include_directories(/home/nvidia/TensorRT-8.2.5.1/include/) link_directories(/home/nvidia/TensorRT-8.2.5.1/lib/) include_directories(${PROJECT_SOURCE_DIR}/src/) include_directories(${PROJECT_SOURCE_DIR}/plugin/) file(GLOB_RECURSE SRCS ${PROJECT_SOURCE_DIR}/src/.cpp ${PROJECT_SOURCE_DIR}/src/.cu) file(GLOB_RECURSE PLUGIN_SRCS ${PROJECT_SOURCE_DIR}/plugin/*.cu) add_library(myplugins SHARED ${PLUGIN_SRCS}) target_link_libraries(myplugins nvinfer cudart) find_package(OpenCV) include_directories(${OpenCV_INCLUDE_DIRS}) add_executable(yolov5_det yolov5_det.cpp ${SRCS}) target_link_libraries(yolov5_det nvinfer) target_link_libraries(yolov5_det cudart) target_link_libraries(yolov5_det myplugins) target_link_libraries(yolov5_det ${OpenCV_LIBS}) add_executable(yolov5_cls yolov5_cls.cpp ${SRCS}) target_link_libraries(yolov5_cls nvinfer) target_link_libraries(yolov5_cls cudart) target_link_libraries(yolov5_cls myplugins) target_link_libraries(yolov5_cls ${OpenCV_LIBS}) add_executable(yolov5_seg yolov5_seg.cpp ${SRCS}) target_link_libraries(yolov5_seg nvinfer) target_link_libraries(yolov5_seg cudart) target_link_libraries(yolov5_seg myplugins) target_link_libraries(yolov5_seg ${OpenCV_LIBS}) 这是cmakeLists.txt文件 cmake .. 报错: zgh@zgh-Legion-Y7000P-IAH7:~/tensorrtx/yolov5/build$ cmake .. CMake Error at /usr/local/share/cmake-3.27/Modules/CMakeDetermineCUDACompiler.cmake:277 (message): CMAKE_CUDA_ARCHITECTURES must be non-empty if set. Call Stack (most recent call first): CMakeLists.txt:13 (enable_language) – Configuring incomplete, errors occurred!
2024/1/20 11:33:33
该错误提示是由于没有指定 CMAKE_CUDA_ARCHITECTURES 变量,需要在 CMakeLists.txt 中添加以下语句:
set(CMAKE_CUDA_ARCHITECTURES "60;61;70;75")其中,CMAKE_CUDA_ARCHITECTURES 指定了支持的 CUDA 架构版本号,这里的值可以根据你的 GPU 型号进行调整。
在添加上述语句后,再次运行 cmake .. 命令即可。
cmake_minimum_required(VERSION 3.5)
project(Ball_Det)
set(CMAKE_CXX_STANDARD 11)
set(Cudart_LIBS "/usr/local/cuda-12.2/targets/x86_64-linux/lib/libcudart.so")
set(CMAKE_CUDA_COMPILER /usr/local/cuda-12.2/bin/nvcc)
set(CMAKE_CUDA_ARCHITECTURES "80")
include_directories(/usr/local/cuda-12.2/include)
link_directories(/usr/local/cuda-12.2/lib64)
enable_language(CUDA)
find_package(CUDA REQUIRED)
find_package(k4a REQUIRED)
find_package(OpenCV REQUIRED)
include_directories(
Yolo
${OpenCV_INCLUDE_DIRS}
/usr/local/cuda12.2/include
${CMAKE_CURRENT_LIST_DIR}
)
add_library(
Yolo
Yolo/yolov5.cpp
)
cuda_add_library(myplugins SHARED ./Yolo/yololayer.cu)
add_executable(Ball_Det
Mask_Detection.cpp
Yolo/yolov5.cpp
main.cpp
Ball_Detection.cpp
Yolo/calibrator.cpp
)
target_link_libraries(
Ball_Det
nvinfer
cudart
myplugins
/usr/local/cuda12.2/lib64
${Cudart_LIBS}
${OpenCV_LIBS}
libk4a.so
)