在 Pandas 中,.apply() 是用于对 DataFrame 或 Series 中的元素应用指定函数的方法。
对于 DataFrame,.apply() 可以在行或列方向上应用函数。语法如下:
txt
DataFrame.apply(func, axis=0)func是要应用的函数,可以是一个已定义的函数,也可以是一个匿名函数(如 lambda 函数)。axis是指定应用函数的方向,默认为 0,表示按列应用函数;设置为 1 则表示按行应用函数。
对于 Series,.apply() 仅能在元素级别上应用函数,无需指定应用方向。语法如下:
txt
Series.apply(func)func是要应用的函数,可以是一个已定义的函数,也可以是一个匿名函数(如 lambda 函数)。
在上述代码中,.apply(lambda x: (x - x.mean()) / (x.std())) 就是将匿名函数 lambda x: (x - x.mean()) / (x.std()) 应用到 DataFrame 或 Series 中的每个元素上。结果是对 DataFrame 或 Series 中的每个元素进行标准化计算,并返回处理后的结果
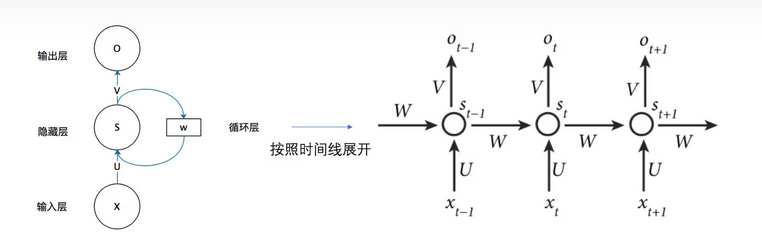
右–按照时间线展开图
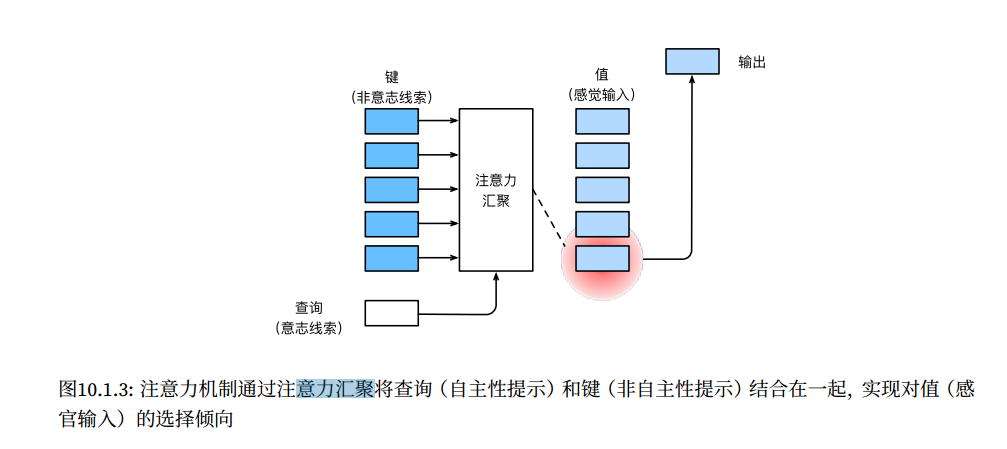
查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚;注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出。
torch.repeat_interleave() 函数是 PyTorch 中的一个张量操作函数,用于生成一个重复值的张量。它的详细解释如下:
txt
torch.repeat_interleave(input, repeats, dim=None)参数说明:
input:输入张量。repeats:重复次数,可以是一个整数、一个一维张量或一个与input张量形状相匹配的张量。dim(可选):指定重复操作的维度。
函数功能:
torch.repeat_interleave()函数将输入张量input按指定的重复次数repeats进行重复,并生成一个新的张量。
txt
https://zhuanlan.zhihu.com/p/659067322
sk-QxaDRZHsiyhtTFpB3JXHMkQ5fiK0AnEQZgM27mbiEIaIkF0G